







前言
该文章为学习使用,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!如有侵权,请私信联系作者删除~
需求
目标网站:
aHR0cHM6Ly93d3cuemhpaHUuY29tL3RvcGljLzE5NTU1NTEzL2hvdA==
接口:
aHR0cHM6Ly93d3cuemhpaHUuY29tL2FwaS92NC9jb21tZW50X3Y1L2Fuc3dlcnMvMjc5MTIwNDY2Ny9yb290X2NvbW1lbnQ=
正文
全局搜索某乎关键字、然后在JS里面有2处地方,全部选中然后下断点调试
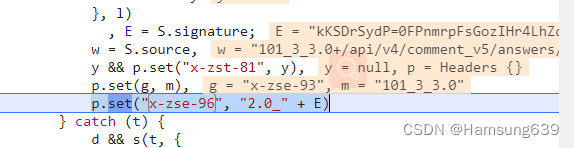
可以看出:
x-zse-96 = “2.0_” + E
E = S.signature
再往上看
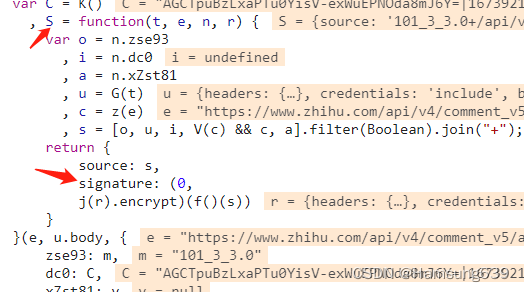
所以signature = j®.encrypt(f()(s))
s = ‘101_3_3.0+/api/v4/comment_v5/answers/2867180344/root_comment?order_by=score&limit=20&offset=+AGCTpuBzLxaPTu0YisV-exWuEPNOda8mJ6Y=|1673921615’
f()(s) 是一个标准的MD5加密算法(替换一下加密参数即可知)

可以看到每次数据都不一样,应该是有一个随机值,需要hook随机数的返回。
Math.random = function(){
return 0.50
};
控制台注入后在测试数据就一样了
j( r).encrypt 进入这个方法,,跳到了一个D方法。可以看出是一个webpack。把这个方法所在的模块扣出来
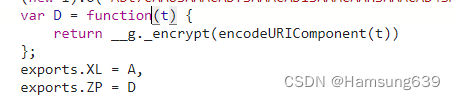

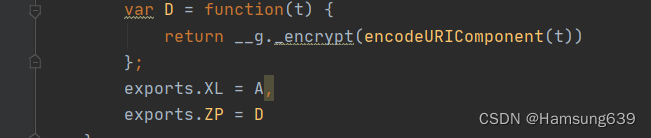
可以看到末尾导出了ZP = D,而我们D方法正式我们的加密方法。这个模块也没有看到引用了其它模块,因此就不需要去导入加载器了,把模块里面的代码扣出来
在浏览器去跑一下是可以正常运行的,接下来就是补相应的环境
在头部加上jsdom的代码
const{JSDOM}=require("jsdom");
const dom=new JSDOM("<!DOCTYPE html><p>Hello world</p>");
window=dom.window;
document=window.document;
navigator=window.navigator;
location=window.location;
history=window.history;
screen=window.screen;
这个结果和样本明显不一样,说明还缺少了其他环境没有补到,,这个时候就需要使用自动吐环境,对前面的环境变量上代理,看看还用到了什么属性和方法
对于JS逆向来说,我们扣完代码的目的就是调用目标网站的加/解密函数或某个值的算法,一般情况下我们把他的算法扣下来能够直接执行,但是如果检测了浏览器指纹,那就比较难了,只能够去深入分析进行补环境。
一般的补环境的是通过运行程序后的undefined报错去一点一点分析,一点一点的去补一些环境,是非常掉头发的。
所以我们使用 Proxy 对全局遍历window、document、navigator等常见环境检测点进行代理,拦截代理对象的读取、函数调用等操作,并通过控制台输出,这样的话我们就能够实现检测环境自吐的功能,后续我们再针对吐出来的环境统一的进行补环境,这样就会方便的多。
window = new Proxy(window, {
set(target, property, value, receiver) {
console.log("设置属性set window", property, typeof value);
return Reflect.set(...arguments);
},
get(target, property, receiver) {
console.log("获取属性get window", property, typeof target[property]);
return target[property]
}
});
document = new Proxy(document, {
set(target, property, value, receiver) {
console.log("设置属性set document", property, typeof value);
return Reflect.set(...arguments);
},
get(target, property, receiver) {
console.log("获取属性get document", property, typeof target[property]);
return target[property]
}
});
navigator = new Proxy(navigator, {
set(target, property, value, receiver) {
console.log("设置属性set navigator", property, typeof value);
return Reflect.set(...arguments);
},
get(target, property, receiver) {
console.log("获取属性get navigator", property, typeof target[property]);
return target[property]
}
});
location = new Proxy(location, {
set(target, property, value, receiver) {
console.log("设置属性set location", property, typeof value);
return Reflect.set(...arguments);
},
get(target, property, receiver) {
console.log("获取属性get location", property, typeof target[property]);
return target[property]
}
});
history = new Proxy(history, {
set(target, property, value, receiver) {
console.log("设置属性set history", property, typeof value);
return Reflect.set(...arguments);
},
get(target, property, receiver) {
console.log("获取属性get history", property, typeof target[property]);
return target[property]
}
});
screen = new Proxy(screen, {
set(target, property, value, receiver) {
console.log("设置属性set screen", property, typeof value);
return Reflect.set(...arguments);
},
get(target, property, receiver) {
console.log("获取属性get screen", property, typeof target[property]);
return target[property]
}
});
第一次跑:
代理停在了这个地方

需要Hook一下,这里是无法直接赋值的,添加以下代码:
var object_tostring = Object.prototype.toString
Object.prototype.toString = function (){
let _xxx = object_tostring.call(this, arguments);
// console.log(this)
if(this.constructor.name == 'Document'){
return '[object HTMLDocument]'
}
return _xxx
}
第二次跑:

在jsdom给它一个初始化的值

第三次跑:
报这个错:

需要npm install canvas --save
第四次跑:
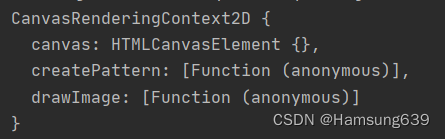
在控制台看看

同样需要再Hook一下,在刚刚hook的地方加一个else if

第五次跑:
代理停在了这里

我们在浏览器window._resourceLoader 是一个undefined
而这里是一个object
第六次跑:

同上,window._sessionHistory=undefined
第七次跑:
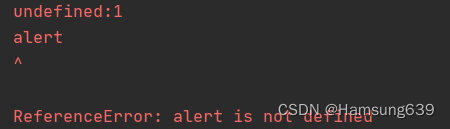
补上:
alert = window.alert
第八次跑:

同样需要hook一下
var Function_tostring = Function.prototype.toString
Function.prototype.toString = function (){
let _sss = Function_tostring.call(this, arguments);
console.log(this)
console.log(_sss,'sssss')
if(this.name === 'Window'){
return 'function Window() { [native code] }'
}
return _sss
}
此时返回的结果已经和浏览器的一样了
补充:此处抓包的接口仅为某个问题的评论
过程中貌似没有用到x-zst-81
后面就是一些参数的拼接了,此处就不展开讲了。
最后
欢迎联系作者交流更多
















 1455
1455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









