






目录
一、DNS协议
DNS是一整套从域名映射到IP地址的系统,也叫做域名解析服务,端口号为53。
我们生活中访问网站都会使用url,或者说是网址。
比如,我打开百度,该网站的url为https://www.baidu.com,其中www.baidu.com就叫做域名,表示我访问的是百度的服务器。
在编写网络通信代码的时候,我们都在使用IP地址,甚至在整个网络通信的协议栈中我们也看不到和域名有关的任何东西。
所以,网络通信就是通过IP地址实现的,而不是域名。域名需要转换成IP地址,然后才能进行通信,这也就是DNS协议的工作。
对于网络的使用者而言,IP地址是一长串数字,它的记忆是十分反人类的。而使用域名就会好很多,不管是拼音还是英语单词,都会更好记忆。
所以DNS协议负责建立域名和IP地址的映射关系,在用户需要访问某网站时,域名字符串会根据映射转换为IP地址,从而实现网络通信。
最初,在每个人的主机上都有一个hosts文件,该文件专门用于存放域名和IP地址的映射关系,现在这个文件也依旧存在在我们的主机上。
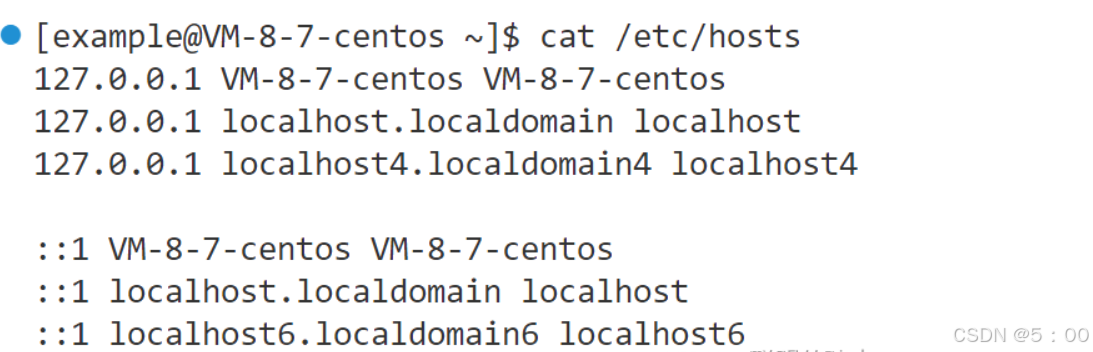
最初,互联网中的主机还很少,互联网信息中心(SRI-NIC)会管理这个hosts文件的内容。如果一个新计算机要接入网络,或者某个计算机IP变更,都需要到信息中心申请变更hosts文件。其他计算机也需要定期下载最新版本的hosts文件才能正确上网。
随着网络的快速发展,hosts文件的更新越来越快,内容也越来越多,不断下载新版本文件的弊端越来越明显。
所以DNS系统就诞生了。
DNS是一个组织的系统管理机构,维护系统内的每个主机的IP和域名的对应关系,该机构就像CA机构一样,具有权威性。
如果新计算机接入网络,需要将这个信息注册到数据库中。
用户输入域名的时候,会自动将URL的信息通过UDP发送到DNS的服务器,由DNS服务器检索数据库,得到对应的IP地址,返回给用户。
其实在我国曾经也有过中文的域名解析协议,曾经以插件的形式伴随着早期网民,它的名字叫3721.大家有兴趣可以看看有关的故事,了解我们现在使用的搜索引擎和一些互联网企业的发展历史。
有了一个权威机构提供域名解析服务,域名命名规则也出现了,以www.baidu.com为例。
-
com: 一级域名,表示这是一个企业域名,同级的还有net(网络提供商),org(非盈利组织) 等。
-
baidu:二级域名,一般是公司名或者组织的名称。
-
www:只是一种习惯用法,写不写都可以。直接输入baidu.com也可以访问百度的服务器。
二、ICMP协议
ICMP协议是一个网络层协议,它能确认IP数据包是否成功到达目标地址。如果数据没有发送成功,会通知发送端IP数据包被丢弃的原因。
ICMP协议基于IP协议工作,所以它属于网络层协议。
ICMP只能搭配IPv4使用,如果使用IPv6,需要使用对应的ICMPv6协议。
如图所示,主机A向主机B发送数据,数据经过多次局域网转发后到了路由器2,路由器2为了获取主机B的MAC地址,发送ARP请求,但是主机B电源关闭,路由器2发送多次请求都收不到主机B的ARP应答。
此时路由器2就会返回一个Destination Unreachable数据包给主机A,主机A收到以后就知道了数据传送错误的原因了。
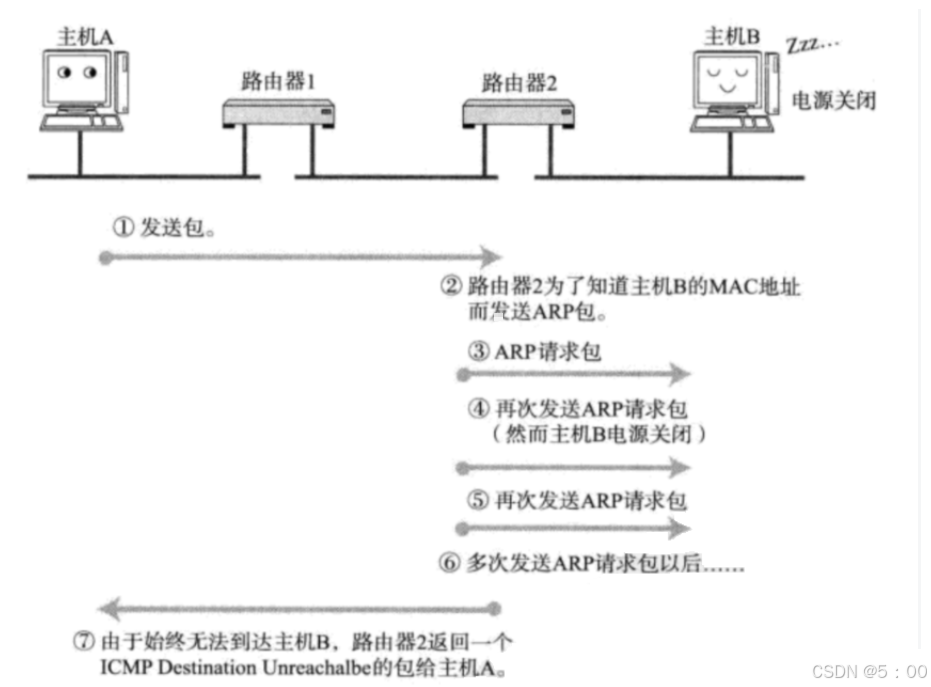
这种功能在我们之前的协议中是没有的,虽然TCP能触发超时重传,但传输错误的原因是找不到的。虽然对于网络使用者来说,不知道传输失败的原因也不影响使用,但是对于网络管理员来说,他们需要知道错误的原因,才能修复网络,此时ICMP协议就派上用场了。
ICMP也有自己的协议格式(了解即可)
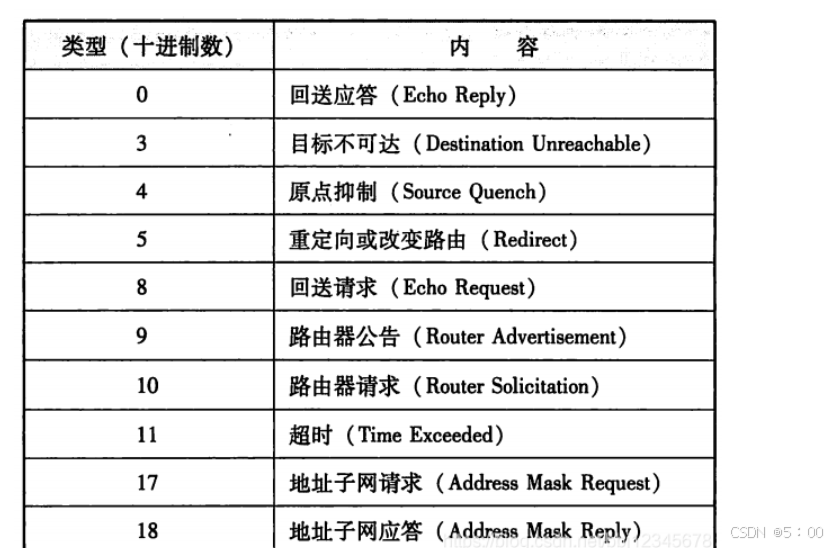
ICMP报文大致分为两类,一类是通知出错原因,一类是用于诊断查询。

下图便是ICMP常见代码和代码所代表的内容。
三、ping
我们在验证一个机器的网络是否连接成功时,通常都会使用ping。
下图就是我在Windows的cmd上对www.baidu.com使用ping命令的结果,当然这个命令也可以在Linux上执行。
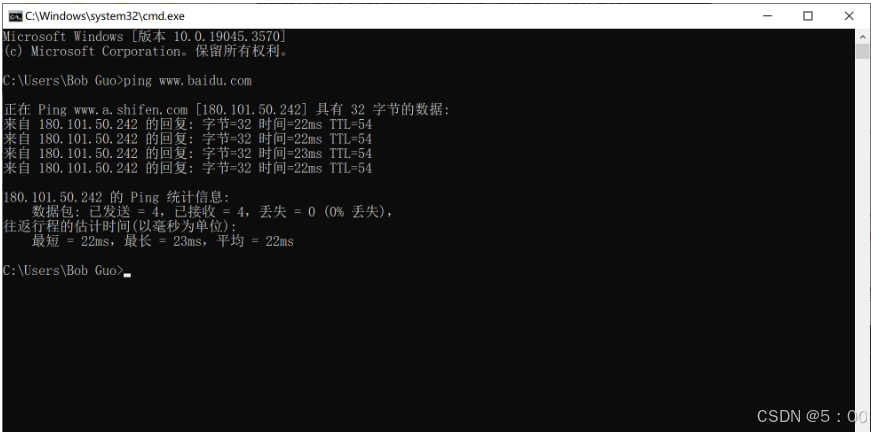
要注意,ping命令的对象是域名,而不是url,只有域名可以通过DNS解析成IP地址。
ping命令有以下特点:
ping命令不仅能验证网络的连通性,而且也会统计响应的时间和TTL(IP协议中的生存时间,也就是跳数)。
ping命令会先发送一个IMCP的Echo Request给对端,对端接收到之后会返回一个IMCP的Echo Reply。
ping命令是通过ICMP协议实现的,是网络层的协议,而端口号属于传输层的概念,平命令根本没有向上达到传输层,所以它没有端口号。
如图所示,traceroute+域名的指令,可以查询当前主机到目标主机之前经历了多少路由器,这也是基于ICMP协议实现的。
这个命令只能在Linux中使用,可以看到我的数据发到百度服务器的每一跳节点的信息。

四、NAT与NAPT技术
NAT技术我们在之前的IP协议博客中已经讲过了。
NAT技术可以在数据从内网向公网传输时,将源IP替换为当前节点的WAN口IP,从而保证数据可在公网的主机中间传递。
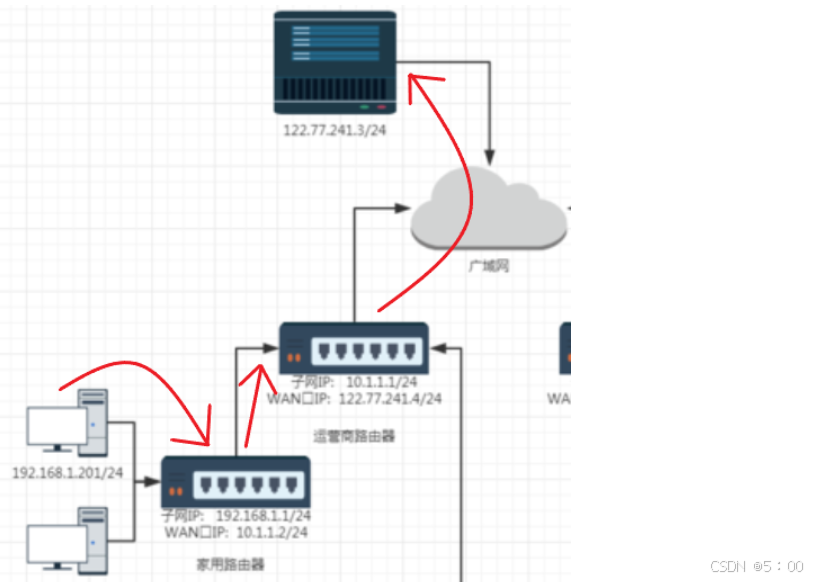
如果局域网中有多台客户端主机都访问同一个服务器,甚至每台主机上有多个进程在访问这个服务器。所有的请求数据包都可以通过NAT路由器发送给服务器,服务器也都会处理这些收到的请求,并通过运营商路由器公网IP发回数据。
但是运营商服务器接收的所有数据的IP报头中,目的IP必定是当前路由器的WAN口IP,源IP肯定是服务器的公网IP。
那运营商路由器怎么知道各个数据该发给哪个家用路由器呢?
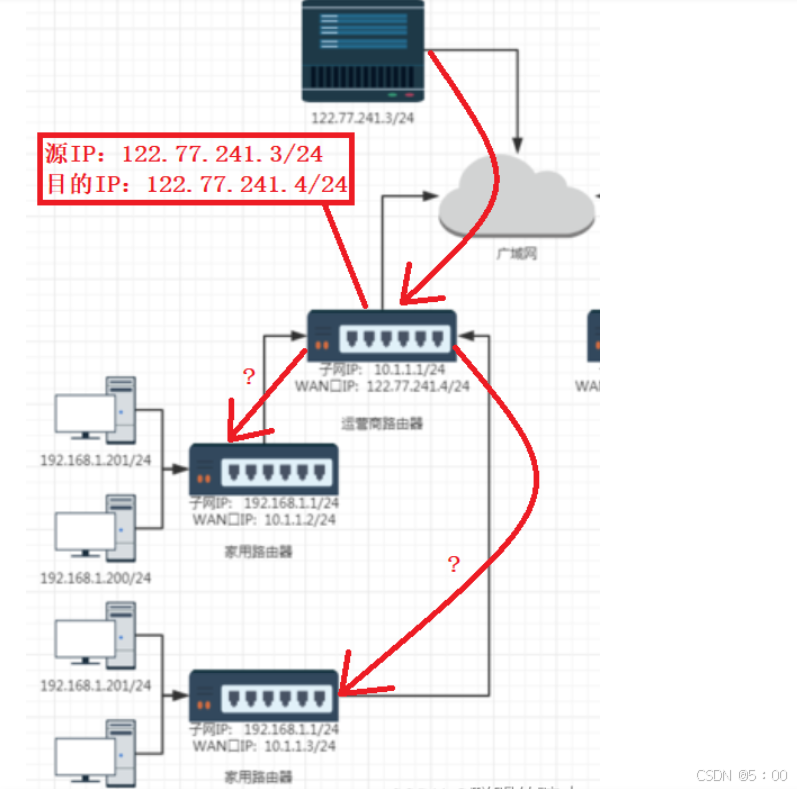
NAPT技术
(1)四元组的唯一性
由于局域网中一个IP地址可以标识一台唯一的主机,而且一台主机上的每个端口号又能标识一个唯一的进程。
所以说,IP和端口号的组合就能指定某个局域网内某个主机上的某个进程。
每一份经网络传输的数据中都会存在源IP、目的IP、源端口和目的端口。
所以,我们拿出这四个数据构建一个四元组(这个四元组是我们构建的,实际每个数据都在报头中)。
在一个局域网内,一个四元组可以明确地标识一份数据由哪个主机的哪一个进程发送,最终由哪一个主机的哪一个进程接收,也就是说,四元组标识了数据传递的方向。
我们前面也说过,IP和端口号的组合就能指定某个局域网内某个主机上的某个进程。大多数情况下,服务器和主机都不在一个局域网内。而数据又会经过路由器不断转发到它的上一层或下一层网络的路由器。
在每个局域网中,节点间都能使用一个四元组将数据转发到同局域网的另一个节点上,不同局域网中的四元组又是不一样的。
所以,我们是否可以在节点路由器将数据传输到另一个局域网的的时候,替换当前网络下使用的四元组,使其可以标明数据在另一个局域网内的发送方向。这样不就能做到数据在网络间从一个进程到另一个进程的发送了吗?
NAPT的工作便是如此,它会建立一个互为键值的四元组转换表,在数据进入不同的网段时,对应的四元组就会被替换进报文的数据内,以达到在另一个局域网内数据也能在不同主机进程间传递。
(2)数据的传输过程
这样说,还是有些不清晰。我们以数据从运营商路由器向公网和局域网内的收发为例,观察数据的传输过程
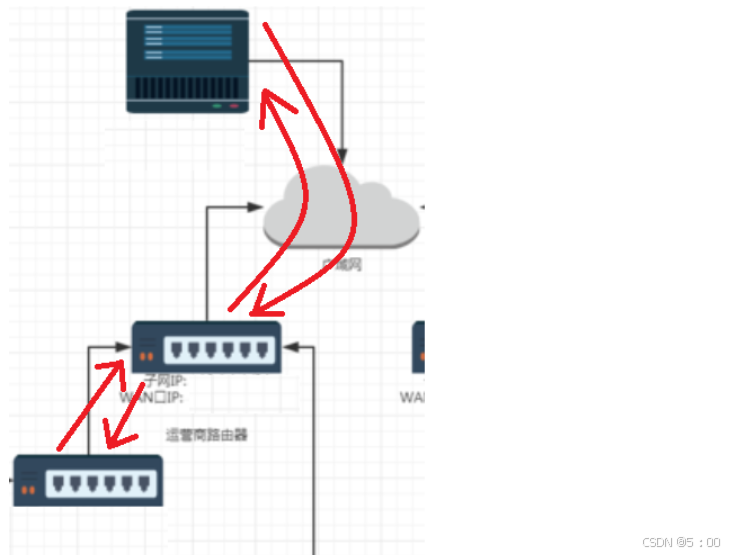
首先,数据从家用路由器传递到运营商路由器。
假设家用路由器发送给运营商路由器一个数据,它的源IP和源端口为10.0.0.10:1025,目的IP和目的端口为163.221.120.9:80。这个四元组能够标识家用路由器和运营商路由器所在的局域网内数据传输的始末位置,所以这个数据被接收到了。
接着,数据从运营商路由器传递到服务器。
服务器将它收到的数据的源IP和源端口10.0.0.10:1025,目的IP和目的端口163.221.120.9:80构建一个四元组,储存为在映射表中。
此时,运营商服务器知道该数据要发给公网服务器,所以它也构建一个四元组。源IP和源端口为202.244.174.37:1025,目的IP和目的端口为163.221.120.9:80。它用这个四元组内的数据替换原来报头里的四个数据。这样,这个四元组能够标识家用路由器和运营商路由器所在的公网内数据传输的始末位置,所以这个数据也能被服务器接收到。
然后,服务器构建一个新的报文传回给运营商路由器。
服务器构建新报文,内部的四元组数据中,源IP和源端口为163.221.120.9:80,目的IP和目的端口为202.244.174.37:1025。这个四元组标识了公网中数据的传递始末位置,数据可以被运营商服务器接收。
最后,运营商服务器将数据发到家用路由器。
运营商服务器接收到服务器发来的数据。路由器在映射表中查找,发现这个数据的四元组信息能找到对应元素。
此时,运营商路由器就将公网中的四元组替换为局域网中的四元组,再次进行发送。此时,在局域网中,四元组的唯一性被保证,家用服务器也能接收到数据。
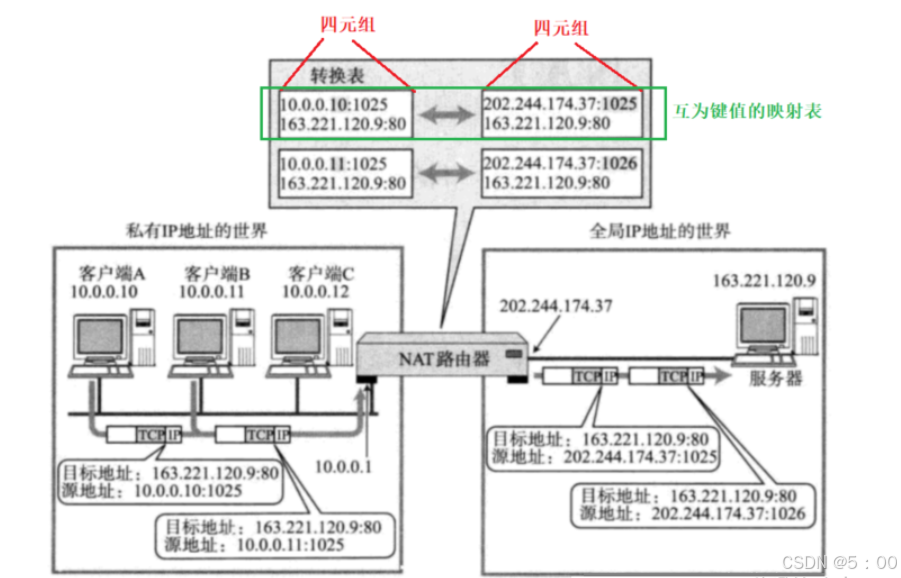
路由器通常情况下都带有NAT功能,否则无法完成内网和公网的IP地址转换问题,四元组的映射关系转换表也是由路由器自动维护的。
假设使用TCP协议,当连接建立时,路由器中就会生成这对通信双方的映射表项,断开连接后也会删除这个表项。
(3)NAPT的缺陷
由于NAPT技术依赖映射转换表与上下层网络通信,所以它有下面的不足:
-
因为只有内网中的客户端给服务发送数据时,四元组的映射关系才会建立,服务器无法从公网主动给内网中的客户端发数据。换句话说,就是内网中的客户端必须先发数据给公网中的服务器,然后服务器才能向客户端发数据。
-
转换表的生成、管理和销毁需要一定的开销,路由器会有一定的负担。
-
通信过程中,一旦NAT设备出现异常,所有的TCP连接都会因出现问题而断开。
虽然NAT与NAPT技术确实由一定的问题,但其优势远大于不足。
五、代理服务器
1.正向代理和反向代理
代理模式分为正向代理和反向代理,二者有一定的区别。
举个例子,假如你在太原上大学,想买天津的十八街麻花。由于你每天还有课,不方便去天津买,而你正好有一个老同学在天津上大学。
那你就可以让他帮你去买,然后再给寄你。这个过程中,你同学扮演的就是正向代理的角色。过了一段时间,很多人都知道了这些好麻花是你的同学代购的,所以很多人也都去找你的同学买。而你的同学觉得来一单就去一次鼓楼的十八街总店太麻烦了,所以他就买了很多麻花囤起来。只要有订单来了,直接将家里的货发出去就好了。此时你同学扮演的就是反向代理的角色。
上面的例子虽然比较形象,但是放到网络上可能就不太好理解。我们在网络上再观察一下:
对正向代理而言:
假设你用学校的校园网去看电影《战狼2》,你的客户端向腾讯视频服务器发起请求。首先,你的请求会被学校的代理服务器先拦截下来,然后代理服务器会替你向腾讯视频服务器发起请求。
腾讯视频服务器收到代理服务器的请求后,将对应的电影资源响应给代理服务器。
代理服务器会做两件事,先将这个电影的响应缓存到代理服务器中,再将收到的响应转发给你的客户端。
你觉得挺好看,所以给你同学也推荐了这个电影。
你的同学也会用腾讯视频看这个电影,当他的客户端发起请求后,同样会被代理服务器拦截。
然后学校的代理服务器发现本地已经缓存了这部电影,所以学校的代理服务器就直接将电影的资源返回给客户端了。代理服务器也不会再向腾讯视频的服务器发起请求了。
由于你同学只经过了一次请求和响应,所以你的同学拿到电影资源的速度比比快得多,因为学校的代理服务器离你们更近。
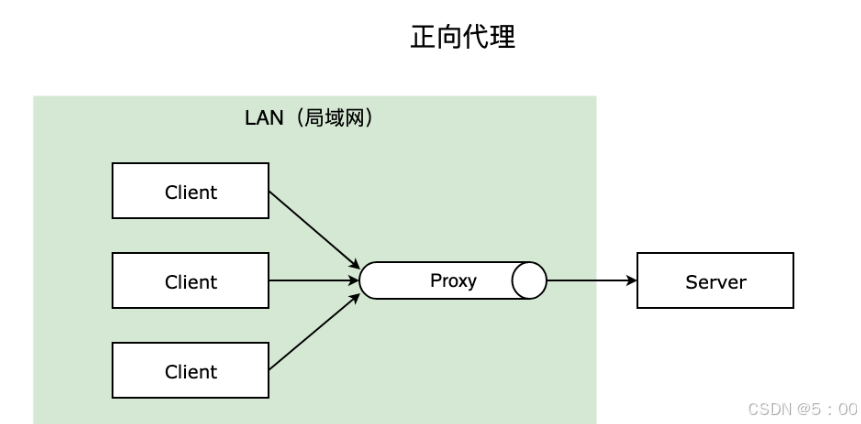
对反向代理而言:
对于我们常用的APP,比如QQ、微信、淘宝、京东之类的。在同一时刻会有很多人同时访问它们的服务器,所以一台机器肯定是不够用的,为我们服务的是一个拥有大量机器的服务器机群。
比如说,当多个请求发送给淘宝服务器时,请求并不由机群中的某台服务器直接接收,而是由淘宝的反向代理服务器先接收。
然后,反向代理服务器会利用均衡策略,将他接收到的大量请求分发到机群内不同的服务器,保证请求压力平均分摊给每一台服务器。
这样的现象称为负载均衡。比如,Nginx就是一种用于实现负载均衡,支持大量线程并发访问的服务器。
这也解释了我们之前讲IP协议时,我们只会向一个公网内的主机发送数据的原因。而且对于用户而言,具体哪台服务器为你提供服务并不重要,只要用户能访问淘宝就可以了。
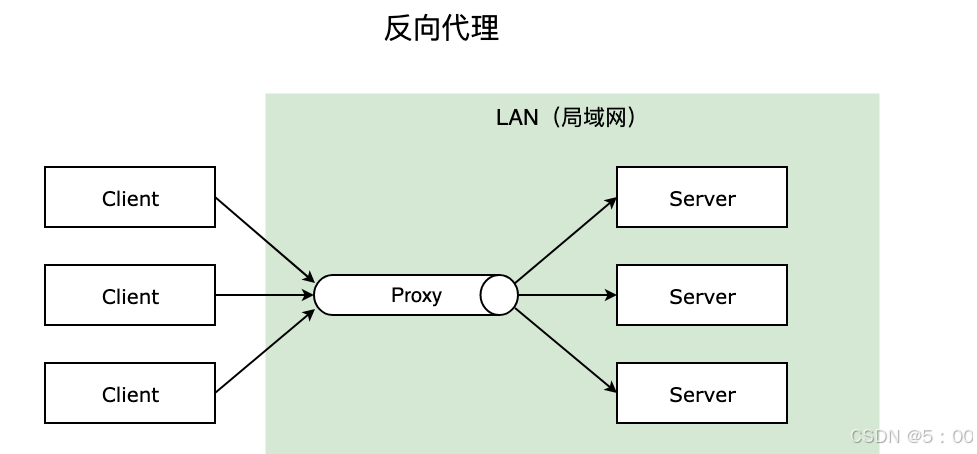
你可以简单理解为数据离用户近,代理服务器可以自己处理一部分请求,就是正向代理;数据离用户远,代理服务器只负责数据转发,而不负责请求处理,就是反向代理。

















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









