







sort:命令可以对文件中的数据进行排序
语法:sort [选项] 文件
-u:对排序后认为相同的行只留其中一行(去重)
-d:按字典顺序,比较时仅字母、数字、空格和制表符有意义
-f:将小写字母与大写字母同等对待(不区分大小写)
-r:按逆序输出排序结果
-c:检查给定文件是否已排序,如果它们没有排序,则打印一个出错信息,并以状态值1退出
#1 2 1 a a
sort -u sort.txt #1 2 a
#1 2 1 a a
sort -d sort.txt # 1 1 2 a a
#1 2 1 a A
sort -uf sort.txt # 1 2 a
#1 2 1 a A
sort -r sort.txt #A a 2 1 1
#1 2 1 a A

uniq:将重复行从输出文件中删除
使用uniq命令可以将文件内的重复行数据从输出文件中删除,只留下每条记录的唯一值
注:uniq只会比较相邻的数据是否是重复值 一般配合 sort 排序使用
语法:uniq [选项] 文件
-c:显示输出中在每一行行首加上本行在文件中出现的次数
-d:只输出重复的行
-D:显示重复的行
-u:只显示文件中不重复的行 类似 sort -u
-i:在比较的时候不区分大小写 类似 sort -f
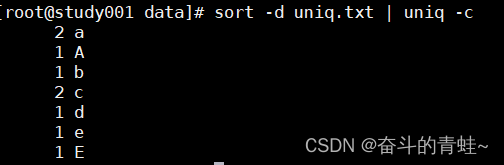
#a b c a d c A E e
sort -d uniq.txt | uniq -c
#a b c a d c A E e
sort -d uniq.txt | uniq -d
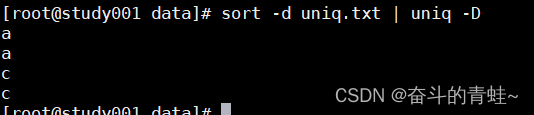
#a b c a d c A E e
sort -d uniq.txt | uniq -D
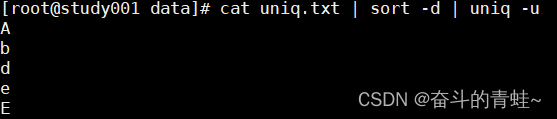
#a b c a d c A E e
cat uniq.txt | sort -d | uniq -u
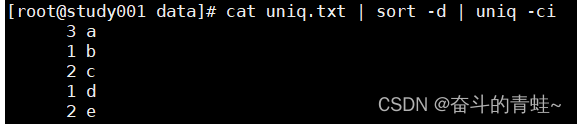
#a b c a d c A E e
cat uniq.txt | sort -d | uniq -ci

cut:从文件每行中显示出选定的字节,字符或字段(域)
使用cut命令可以从文件的每一行中输出选定的字节,字符或字段(域),只能使用-b,-c 或 -f选项中的一个,每一列表都是专门为了一个类别做出的,或者可以用逗号隔开要同时显示的不同类别输入顺序将作为读取顺序,,每个仅能输入一次
语法 [选项] 文件
-b<列表>:只选中指定的这些字节
-c<列表>:只选中指定的这些字符
-d<分隔符>:使用指定分界符代替制表符作为区域分界
-f<列表> :指定文件中设想被定界符,(缺省情况下为制表符)隔开的字段的列表
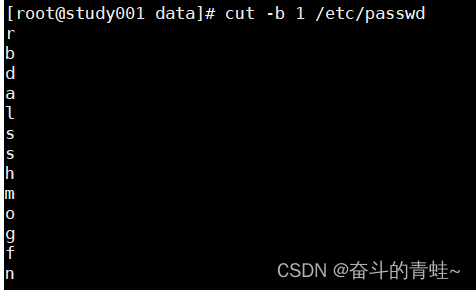
cut -b 1 /etc/passwd(1表示 是第一个字节)
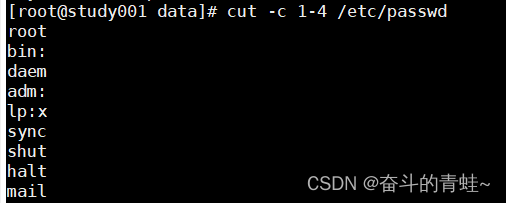
cut -c 1-4 /etc/passwd(1-4 表示1-4个字节)
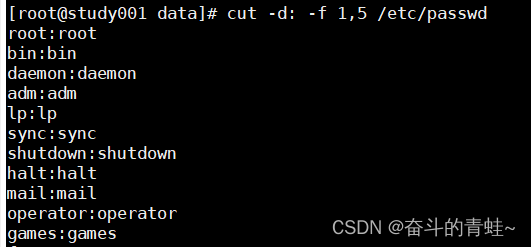
cut -d: -f 1,5 /etc/passwd(1,5 表示 按照:分割 第一位 和 第五位)
comm :逐行比较两个已排过序的文件
语法:comm 选项 文件1 文件2
-1:不输出文件1 特有的行
-2:不输出文件2 特有的行
-3:不输出两个文件共有的行
comm -1 sort.txt uniq.txt (相等于只输出文件2)
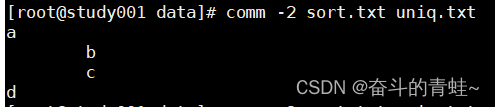
comm -2 sort.txt uniq.txt(相等于只输出文件1)
comm -3 sort.txt uniq.txt(文件1和文件2 相较而言 都没有的)
comm -12 sort.txt uniq.txt (文件1和文件2 都有的)



diff :逐行比较两个文本文件,列出其不同之处
它能比comm命令完成更复杂的检查,对给出的文件进行系统的检查,并显示出两个文件中所有不同的行,不要求事先对文件进行排序
语法 :diff 选项 文件1 文件2
-i:文件内容忽略大小写
-w:忽略所有的空白
-a:所有的文件都视为文本文件来逐行比较
diff sort.txt uniq.txt (第一行和第四行不同)
















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









