






常见问题
1、Redis、ES、Neo4J、MongoDB中都存储了什么数据?
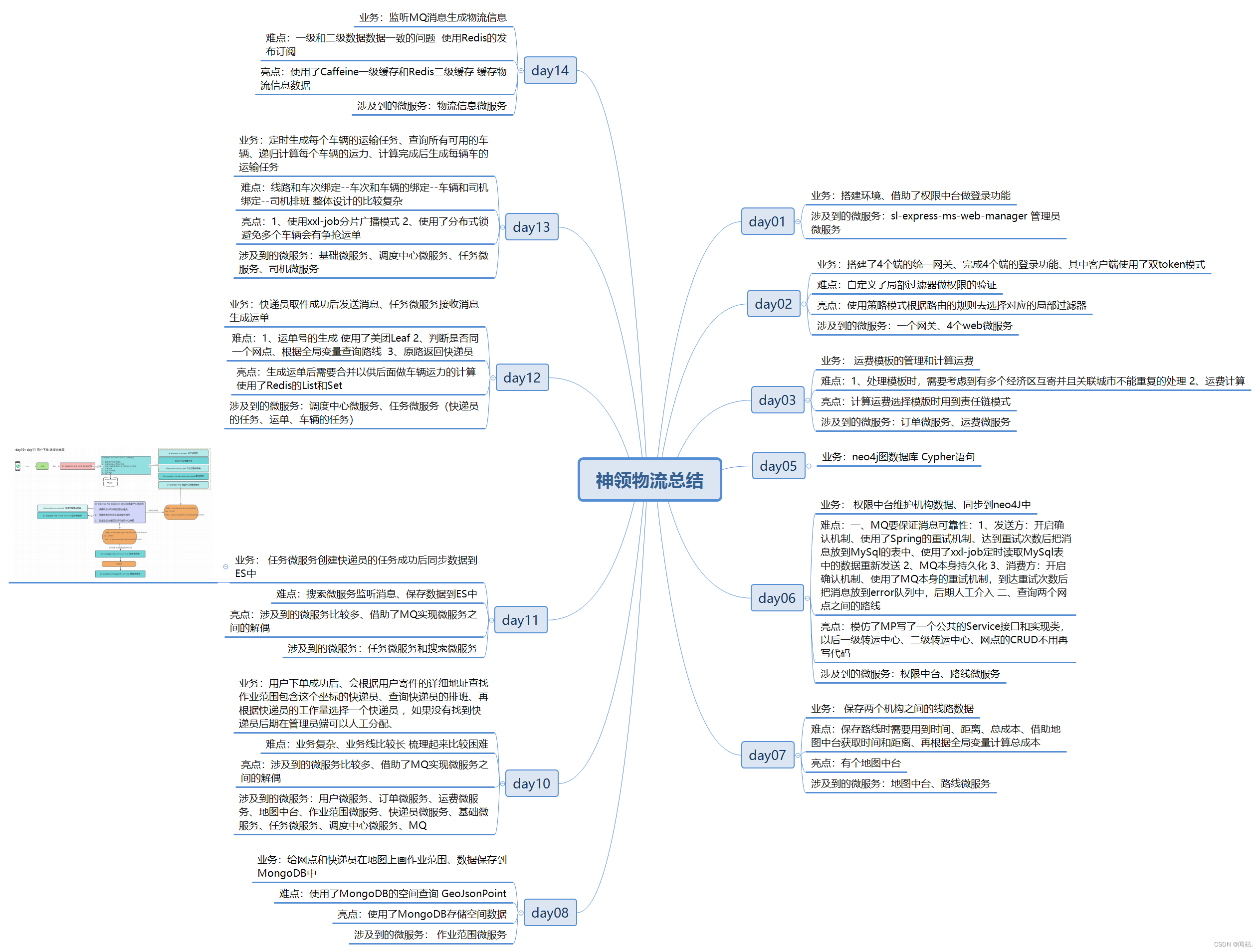
Redis:
验证码(value)
refresh_token(value)
运费模板(hash)
全局配置-成本设置(干线、支线、接驳路线)(hash)
全局配置-调度配置(提前N小时发任务+转运节点最少|成本最低)(value)
合并运单(List和Set)
物流信息(value)
ES:
快递员的取派件任务
Neo4j:
机构和路线 机构:一级转运中心 二级分拣中心 网点 路线:名称、距离、成本
MongoDB:
网点和快递员的作业范围
物流信息
2、哪里用到分布式事务?哪里用到分布式锁?哪里用到分布式任务?
分布式事务:
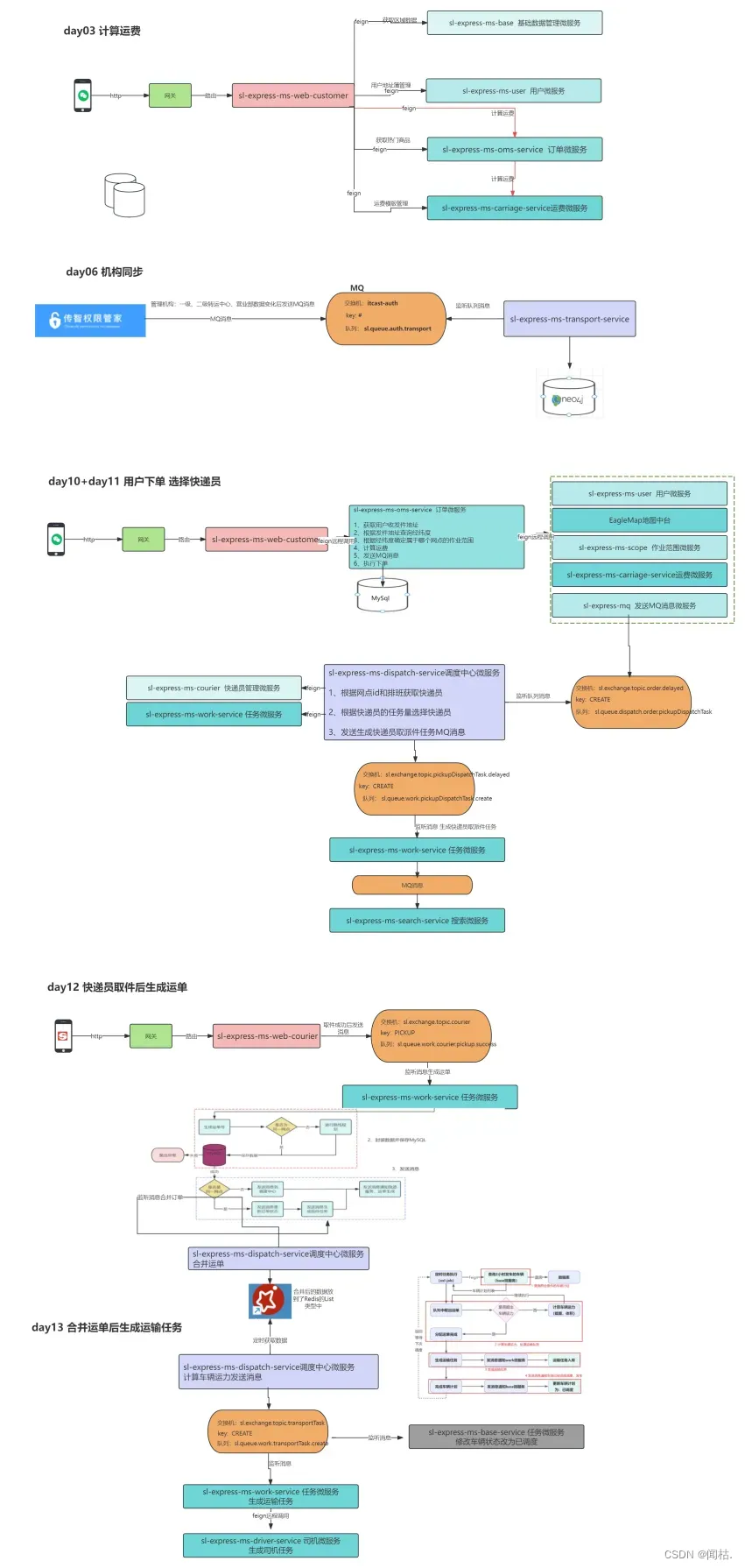
1、快递员微服务 快递员取件成功后 调用任务微服务修改取派件任务的状态 调用订单微服务修改订单的状态
2、司机微服务 司机入库后 调用任务微服务修改运输任务的状态、调用任务微服务修改运单的状态
分布式锁:
1、司机入库: 只能有一个司机操作,任务已经完成的话,就不需要进行流程流转,只要完成司机自己的作业单即可
2、计算车辆运力时: 为了相同目的地的运单尽可能的分配在一个运输任务中,所以需要在读取数据时进行锁定,一个车辆处理完成后再开始下一个车辆处理
分布式任务:
1、处理发送失败的MQ消息
2、车辆调度(合并运单后计算车辆的运力)
3、项目中都涉及到了哪些设计模式?
处理Spring的那些设计模式外,我们自己写过:1、责任链模式 2、策略模式
4、开发遇到的问题或者bug?怎么解决的?
1、快递分配任务时,要选择一个任务量最少得快递员,任务量的查询是通过MySql查询得到的,但是如果是延迟任务时由于MySql的表更新不及时,导致查询到的工作量不准确
解决方案是:用Redis的Zset结构存储每个快递员的工作量,Zset本身可以排序、所以直接可以根据工作量顺序排序取第一个就是工作量最少的,分配给这个快递员后再zset中加1
2、一级Caffeine和二级缓存Redis不一致 ,解决方案:Redis的发布订阅
3、我们所有的枚举类code的值当时都是integer类型,但是有一个同事在定义枚举类的时候code的类型他写成了byte类型,导致在使用的时候没有注意,一直没有查到我想要的数据、找了好长时间的bug才发现是数据类型不一样 。
5、开发人员有多少?开发时间?并发量?数据量?
开发人员:java程序员最多的时候有20个,我离职的时候还有7个
产品经理 1个 前端:2个 测试:2个 运维:2个
开发时间:6-10个月
并发量:To C 2-30 To B 谈不上并发
数据量:每天的订单量 2-3W ToB 2-3K















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









