






概要
Set集合存储元素原理分析
Set结构特点
- 元素唯一、无序、不重复、无索引
- HashSet:完整继承Set结构,无序、不重复、无索引
- LinkedHashSet:有序,不重复、无索引
- TreeSet:不重复、无索引、按照比较器排序(默认升序)
Set为什么无序?
原因是:
Set底层使用哈希算法来存储数据。
比如说:
我们底层数组长度是6
那么根据哈希算法,把当前对象的哈希值%6=得出对应索引。
HashSet<Apple> hash = new HashSet<>();
hash.add(apple1);
我们此时往HashSet集合当中存储了一个apple对象,假设他的哈希值是661
那么他对应存储的位置就是-> 661%6 = 1;
最终结果就是存储在“1”号位置上。
因此这种基于哈希算法,导致Set集合是无序的
那么就有人问:假如我们存入的两个对象经过哈希算法的值相等怎么办?
这就要从Set的数据结构说起
Set的数据结构
在JDK1.8之前,我们使用Set=数组+链表+(哈希算法)
在JDK1.8之后,我们使用Set=数组+链表+红黑树+(哈希算法)
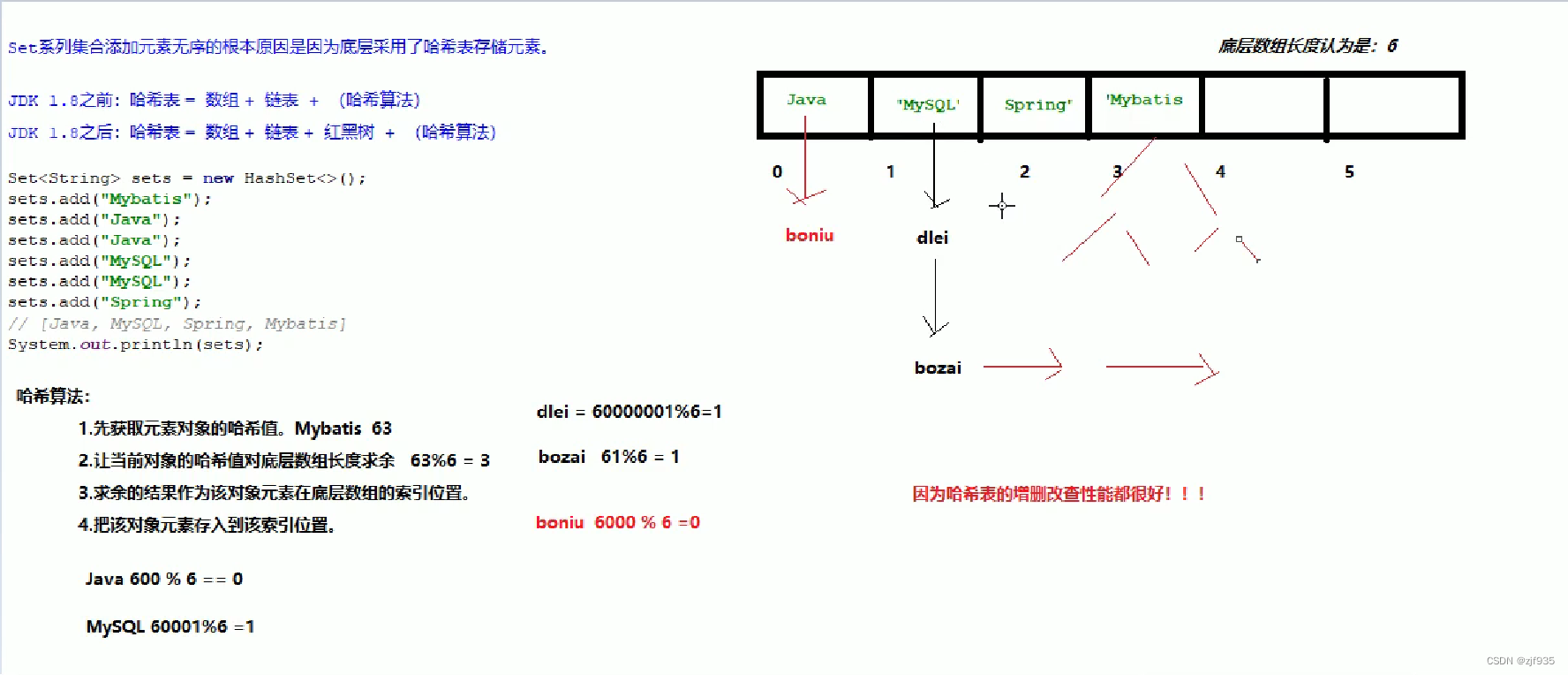
当元素的算法结果相同的时候,就会在当前节点下指向新元素的位置,是一个链表
这种数据结构的好处是,无论增删改查那种效率都很高!
有数组的查询快特点,也有链表的增删改特点。
当我们链表过长的时候(默认情况下>8)的时候,就会把链表转成一颗红黑树。
我们看下源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//底层是基于map实现的
点进去Node[]看看:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
这个数组包含了,哈希值、key、value、以及一个Node节点用于存储下一个节点。
那么既然链表过长会转成红黑树,红黑树怎么存储呢?
-使用哈希值代表大小来存储
Set为什么不重复?
Set在添加元素的时候
对于有值特性的元素,比如字符串,或者Integer类型能够直接判断是否重复
对于引用数据类型,set集合会让两个对象的hash值进行比较,如果不相同,则认为两个对象
不相同。
如果hash值相同,会去调用equals方法比较内容是否相同,如果相同则为重复,不相同不重复。
我们重写hashcode()和equals()方法的时候,重写的目的是为了让:
两个对象比较多时候内容一样,无论是hashcode值还是equals都会判断true(相同)
我们原本没有重写的方法,两个对象内容一样,hashcode值不一定一样。
如果希望Set集合认为两个对象只要内容一样就重复了,必须重写对象的hashCode和equals方法。
Set集合遍历方式
因为Set集合没有索引,因此只有三种遍历方式
1.forEach
2.迭代器
3.Java1.8出现的lambad















 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









