







目录
一 JVM 中的内存区域划分
JVM 其实是一个Java 进程,Java 进程会从操作系统这里申请一大块区域,给 java 代码使用.申请的这一大块区域会进一步划分,给出不同的用途,其中有最核心的三个区域:
1. 堆 : new 出来的对象.(成员变量)
2. 栈 : 维护方法之间的调用关系.(局部变量)
3. 方法区/元数据区: 放的是类加载之后的类对象~~ (静态变量)
(Java文件被编译后,生成了.class文件,JVM此时就要去解读.class文件 ,被编译后的Java文件.class也被JVM解析为一个对象,这个对象就是 java.lang.Class .这样当程序在运行时,每个java文件就最终变成了Class类对象的一个实例。)
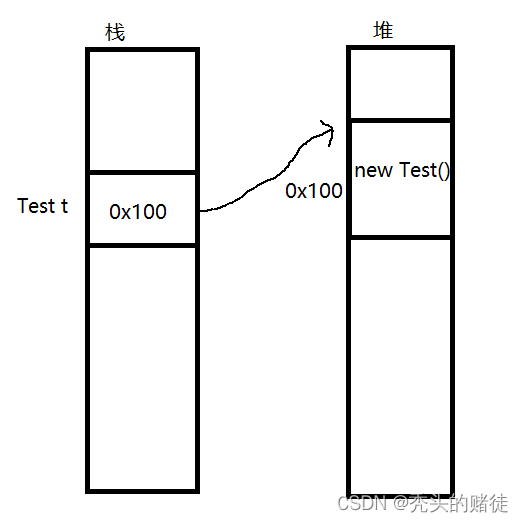
考题: 内置类型的变量是在栈上的, 引用类型的变量时在堆上
变量所在的位置和变量的类型是无关的. 例: Test t = new Test();
t 本身是一个引用类型,t 是一个局部变量,此时 t 是在栈上的;
new Test() 这个对象,对象的本体是在堆上的
内存区域划分图:
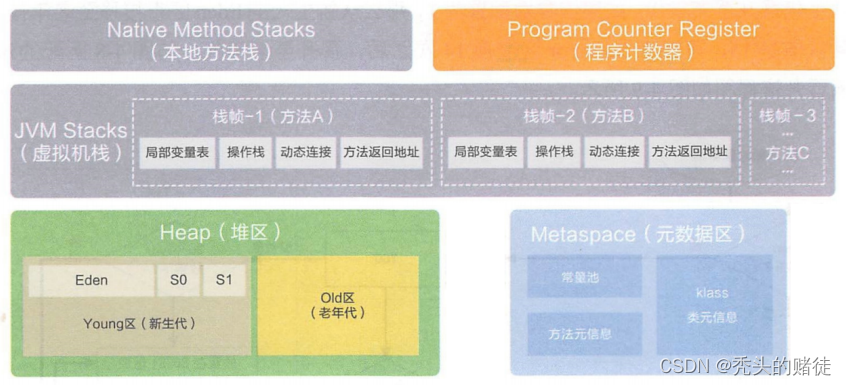
给个区域的作用:
1. 虚拟机栈,是给 java 代码使用的.
2. 本地方法栈, 是给 jvm 内部的本地方法使用的,(JVM 内部通过 C++ 代码实现的方法)
3. 程序计数器, 用途是纪录当前程序指定到哪个指令了, 简单的 long 类型的变量存了一个内存地址. 内存地址就是下一个要执行的 字节码 所在的地址
注: 堆和元数据区,在一个 jvm 进程中,只有一份. 栈(本地方法栈和虚拟机栈)和 程序计数器则是存在多份, 每个线程都有一份.
二 JVM 的类加载机制
类加载: 把 .class 文件,加载到内存, 得到类对象这样的过程.
类加载的五个步骤:
1. 加载
找到 .class 文件,并读取文件内容
双亲委派模型:
JVM 中, 加载类,需要用到一组特殊的模块,类加载器:
• BootStrap ClassLoader: 负责加载 Java 标准库中的类
• Extension ClassLoader: 负责加载一些非标准但是 Sun/Oracle 扩展的库的类
• Application ClassLoader: 负责加载项目中自己写的类以及第三方库中的类
当具体加载一个类的时候,需要先给定一个类的全限定名. 例: "java.lang.String"(字符串)
当加载时,首先是从Application ClassLoader 开始加载,但这个类并不能立刻开始搜索目录,首先需要它的父类去找(这三个类加载器是父子关系):

2. 验证
.class 文件有明确的数据格式(二进制文件)
3. 准备
给类对象分配内存空间
4. 解析
针对字符串常量进行初始化
字符串常量在 .class 文件中就存在了,但是由于它们还在文件中,只知道彼此之间的相对位置(偏移量),不知道在内存中的实际地址,只能使用特殊符号去占位.这时候的字符串常量就是符号引用
真正加载到内存中,就会把字符串填充到内存中的特定地址上,字符串常量之间的相对应位置还是一样的,但是这些字符串有了自己真正的内存地址,此时的字符串就是直接引用(java 中的普通的引用)
5. 初始化
针类对象进行初始化(初始化静态成员, 执行静态代码,类如果有父类,还要加载父类)
类加载这个动作,啥时候会触发?
并不是 jvm 一启动,就把所有的 .class 都加载了!! 整体是一个 "懒加载" 的策略(懒汉模式) 非必要,不加载
什么叫做"必要":
1. 创建了这个类的实例
2. 使用了这个类的静态方法/静态属性
3. 使用子类,会触发父类的加载
三 JVM 中的垃圾回收策略
JVM 中的内存有好几个区域,是释放那部分空间?
堆!!!(new 出来的对象)
程序计数器,就是一个单纯存地址的整数,不需要随着线程一起销毁,栈也是随着线程一起销毁,方法调用完毕,方法的局部变量自然随着出栈操作就销毁了,元数据区/方法区,存的类对象,很少会"卸载"
GC 中主要分成两个阶段:
1. 找, 确认谁是垃圾
java 中使用一个对象,只能通过引用来访问,如果一个对象,没有引用指向它,此时这个对象一定是无法被使用的(此时就是垃圾),如果一个对象不想用了,但是这个引用可能还指向着,此时就不是垃圾.
java中只是单纯通过引用没有指向这个操作,来判定垃圾的
具体来说,java 怎样知道一个对象是否有引用指向呢?
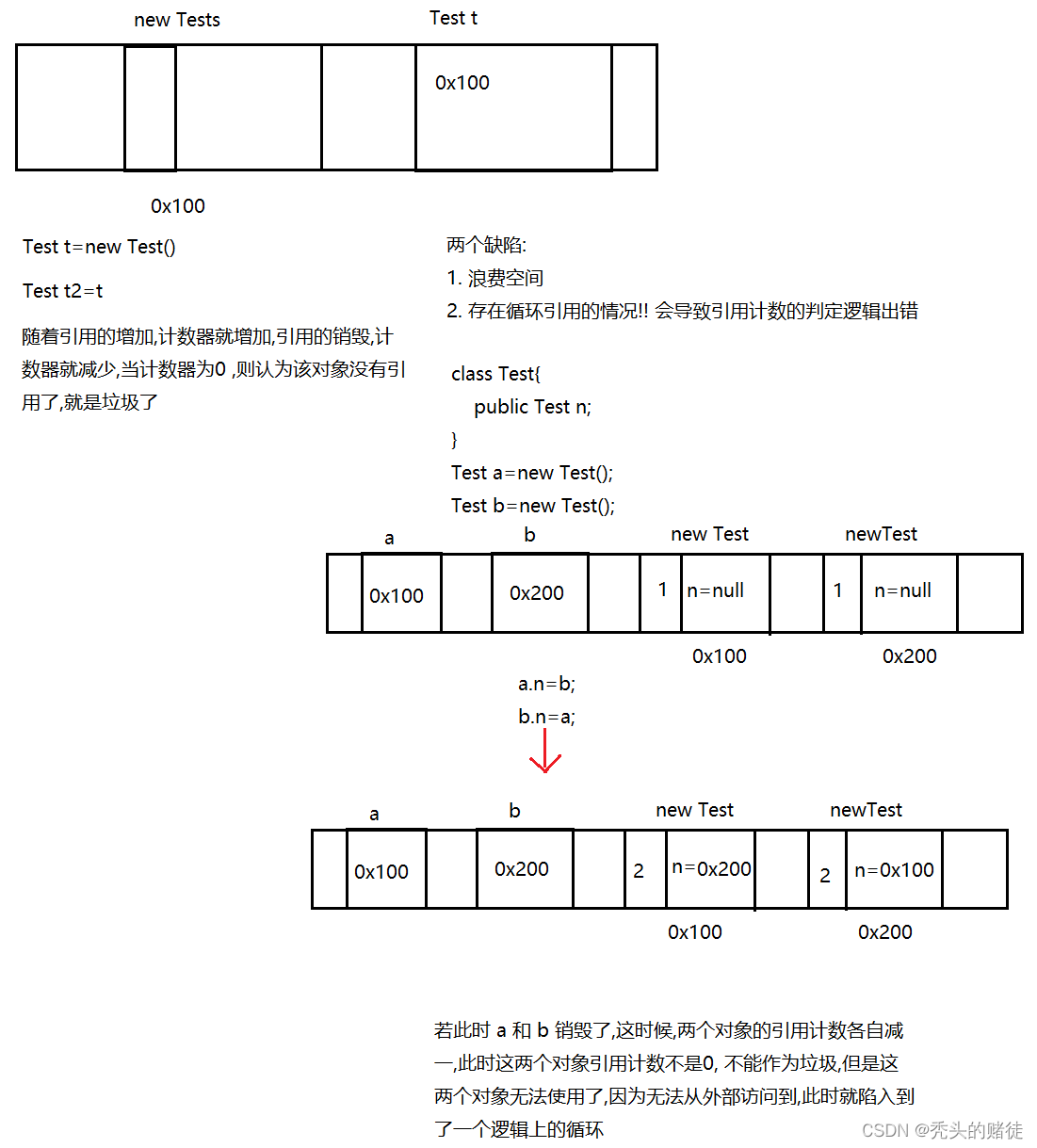
1. 引用计数: 给对象安排一个额外空间,保存一个整数,表示该对象有几个引用指向
(java 实际上没有使用这个方案, Python, PHP 采用了)
2. 可达性分析 :
可达性分析关键要点,就是需要有"起点"(gcroots):
1) 栈上局部变量(每个栈的每个局部变量,都是起点)2) 常量池中引用的对象
3) 方法区中,静态成员引用的对象
可达性分析,就是从所有的 gcroots 的起点出发,看看该对象里又通过引用能访问哪些对象(类似于二叉树).顺藤摸瓜,把所有可以访问的对象都遍历一遍(遍历的同时把对象标记成"可达").剩下的自然是"不可达"
优点: 可达性分析,克服了引用计数的两个缺点,但是也有自己的缺点.
缺点:
1. 消耗更多的时间,因此某个对象成了垃圾,也不一定能第一时间发现,因为扫描的过程中,需要消耗时间
2. 在进行可达性分析的时候,要顺藤摸瓜,一旦这个过程中,当前代码中的对象的引用关系发生变化了(当对象变成垃圾并没有被扫描出来),就麻烦了.因此,为了更准确的完成"顺藤摸瓜"这个过程,需要让其他的业务线程停止工作.就引出了 STW(stop the world)问题.
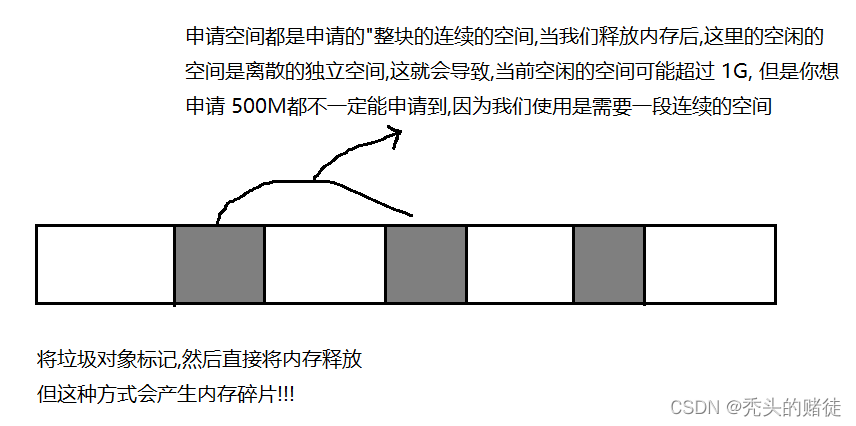
2. 释放,把垃圾对象的内存给释放掉
三种典型策略:
1.标记清除:
2. 复制算法
把整个内存够空间,分成成两段,一次只用一半
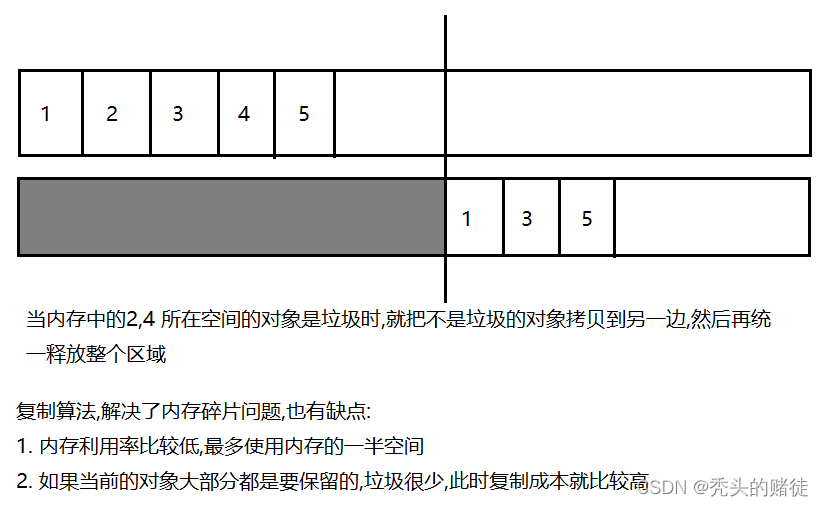 3. 标记整理
3. 标记整理
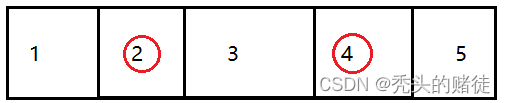
当2 和4 是垃圾,将3复制到2 中,将 5复制到 三的位置,然后释放内存.
优缺点
1. 能够解决内存碎片化问题
2. 搬运的开销太大
4. 分代回收
由于上述三种方法都不能很好的解决内存释放,因此实际上 JVM 的实现思路,是结合了上述几种的方法,针对不同的情况,使用不同的策略.
当我们new 一个对象时,年龄为0,每经过一轮扫描(可达性分析),没被标记成垃圾,年龄加一,针对不同的年龄对象采取了不同的回收策略
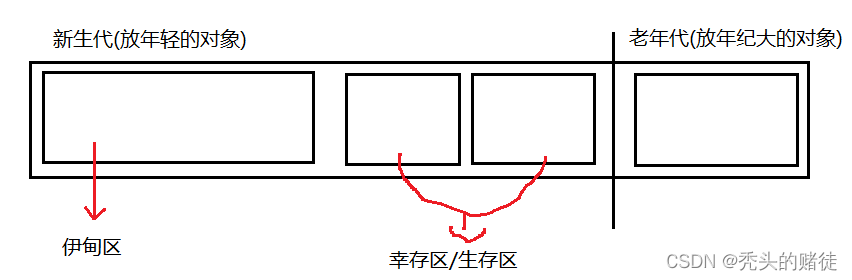
1. 新创建的对象,放到伊甸区. 当垃圾回收扫描到伊甸区之后, 绝大部分对象都会在第一轮 gc 中被干掉, 大部分对象时活不过一岁的(经验规律)
2. 如果伊甸区的对象,熬过第一轮 GC ,就会通过复制算法,拷贝到生存区,生存区分成两半(大小均等),一次只使用一半. 垃圾回收扫描伊甸区对象,也是发现垃圾就淘汰,不是垃圾的,通过复制算法,复制到生存区的另一半
3. 当这个对象在生存区,熬过若干轮 gc 之后,年龄增长到一定程度了,就会通过复制算法拷贝到老年代
4. 进入老年代的对象,年龄都很大了,再消亡的概率比前面新生代的对象小不少,针对老年代的 gc 的扫描频次就会降低很多. 如果老年代中发现某个对象是垃圾了,使用标记整理的方式清除
5. 特殊情况: 如果对象非常大,直接进入老年代,(大对象进行复制算法,成本比较高,而且大对象也不会很多)















 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









