








一. 为什么 Redis 比较块
- 基于内存:Reids 是一种基于内存的数据存储系统,所有的数据都存储在内存中。相比传统的磁盘存储系统,内存访问速度更快,这使得 Redis 能够在毫秒级别快速地读取和写入数据。
- 单线程模型:Redis 使用单线程模型来处理客户端请求。这可能听起来似乎效率不高,但实际上,这种设计有助于避免多线程的竞争条件和锁开箱。Redis 通过非阻塞的方式处理多个客户端请求,每个请求的执行时间很短,因此单线程下,Redis 能够处理大量的并发请求。
- 高效的数据结构:Redis 提供了高效的数据结构,如哈希表、有序集合等。这些数据结构的实现都经过了优化,使得 Redis 在处理这些数据结构的操作时非常高效。
- Redis 使用了非阻塞 I/O 模型,这意味这当进行磁盘读写或者网络通信时,Reids 不会等待数据的返回,而是继续处理其他请求。这样可以充分利用 CPU 的时间,提高整体的吞吐量。
二. Redis 可以实现什么功能?
- 会话存储:保存用户的登录信息。
- 存储普通缓存:例如详情页等数据的缓存信息存储。
- 实现分布式锁:Redis 可以非常方便的实现微服务下的分布式锁,Reids 天然就支持分布式服务
- 简单的消息队列:Redis 自身提供的发布订阅模式,可以用来实现简单的消息队列。
三. Redis 常用的数据类型有哪些
- String(字符串):常见使用场景是存储 Session 信息、存储缓存信息(如详情页的缓存)、存储整数信息,可以使用 incr 实现整数的+1,和使用 decr 实现整数 -1。
- List(列表类型):常见的使用场景是实现简单的消息队列、存储某项列表数据。
- Hasn (哈希表):常见使用场景是存储 Session 信息、存储商品的购物车,购物车非常适合用哈希字典表示,使用人员唯一编号作为字典的key,value 值可以存储商品的id 和 数量等信息。
- Set(集合):一个无序并唯一的键值集合,它的常见使用场景是实现关注功能,比如关注我的人和我关注的人,使用集合存储,可以保证人员会不重复。
- Sorted Set(有序集合):相比于 Set 集合类型多了一个排序的属性 score(分值),它的常见使用场景是可以用来存储排名信息、关注列表功能,这样就可以根据关注实现排序展示。、
四. 有序列表的底层是如何实现的?
当数据比较少时,有序集合是压缩列表 ziplist(字节数组,更节省空间) 实现的,反之则为跳跃表 skiplist 实现的。
使用压缩列表存储必须满足以下两个条件:
- 有序集合保存的元素个数小于 128 个;
- 有序集合保存的所有元素成员的长度都必须小于 64 字节。
如果不能满足以上任何一个要求,有序集合将会使用跳跃表 skiplist 结构进行存储
五. 跳跃表
5.1 什么是跳跃表
它通过添加多层链表的方式,提供了一种以空间换时间的方式来加速查找。
跳跃表由一个带有多层节点的链表组成,每一层都是原始链表的一个子集。最底层是一个完整的数据链表,包含所有的元素。每个更高层级都是下层级的子集,通过添加额外的指针来跳过一些元素。这些额外的指针称为 “跳跃指针”,它们允许快速访问更远的节点,从而减少了查找所需的比较次数。跳跃表的平均查找时间复杂度为 O(log n),其中 n 是元素的数量。这使得它比普通的有序链表具有更快的查找性能,并且与平衡二叉搜索树(如红黑树)相比,实现更为简单。
简单的跳跃表如下图所示:

5.2 跳跃表的查询流程
5.3 跳跃表的添加流程
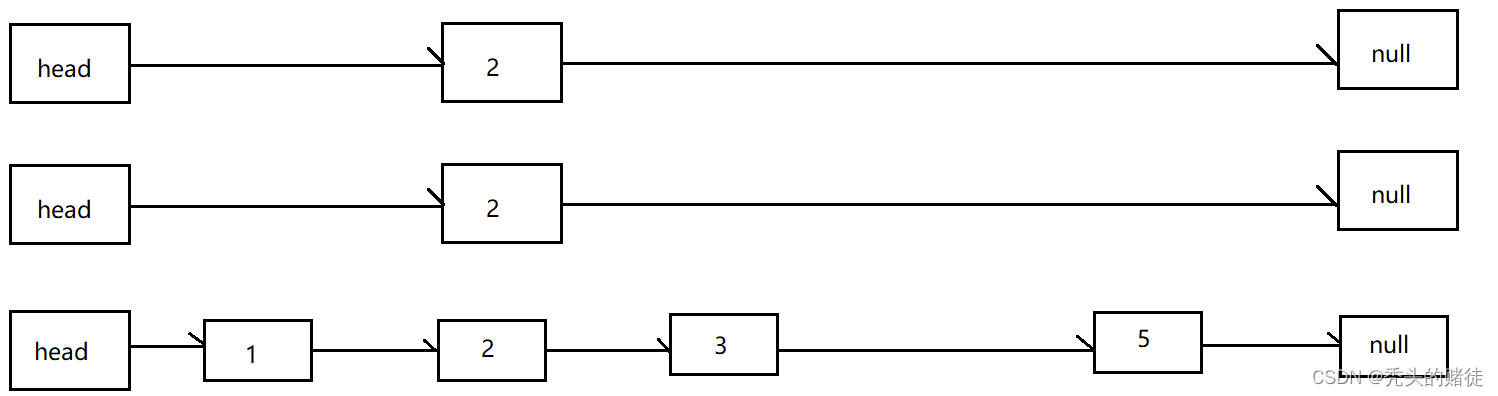
节点的随机数:所谓的节点随机数就是在每次添加节点之前,会先生成当前节点的随机层数,根据生成的随机层数来决定将当前节点存在几层链表中。

插入2(随机层数为3),会依次从下到上生成:
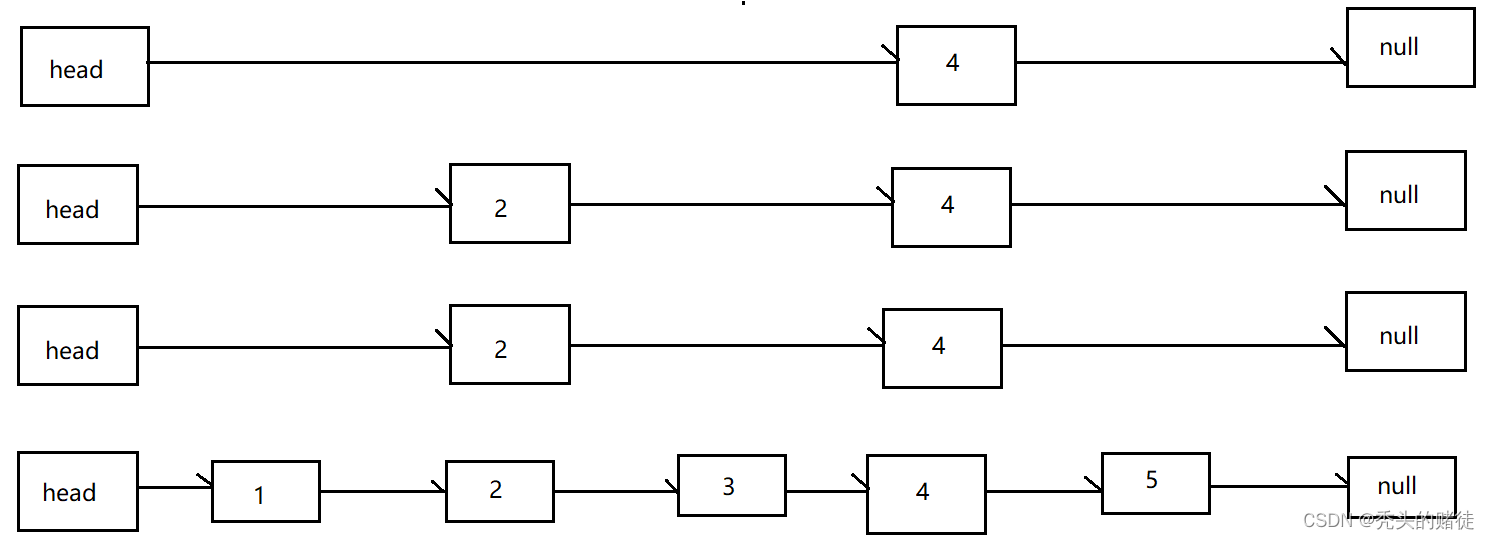
插入4(随机层数为4),会依次从下到上生成:
六. Redis 的 key 的过期策略是怎么实现的
1. 定期删除:Redis 会定期地(默认每秒钟检查 10 次)随机抽取一部分设置了过期时间的键,检查它们是否过期,如果过期则删除。该策略可以通过配置文件中的 hz 参数进行调整。
2. 惰性删除:当访问一个键时,Redis 会先检查该键是否过期,如果过期则删除。这意味着过期键可能会在访问时被删除,而不是在过期时立即删除
redis 并没有采取定时器的方式来实现key删除,如果有多个key过期,也可以通过一个定时器来高效/节省cpu的前提下来处理多个key
- 基于优先级队列:把添加过期时间的key 放入到优先级队列中,根据过期时间建立小根堆,指定过期时间早的,先出队列。队首元素,就是最早的要过期的key。此时定时器中只要分配一个线程,让这个线程去检查对首元素,看是否过期即可,如果队首元素还没过期,后续元素一定没过期,此时,扫描线程不需要便利所有key,只盯住这一个队首元素即可,另外在扫描线程检查队首元素过期时间的时候,也不能检查的太频繁。可以根据当前时间和队首元素,设置一个等待时间,等时间差不多了,系统再唤醒这个线程
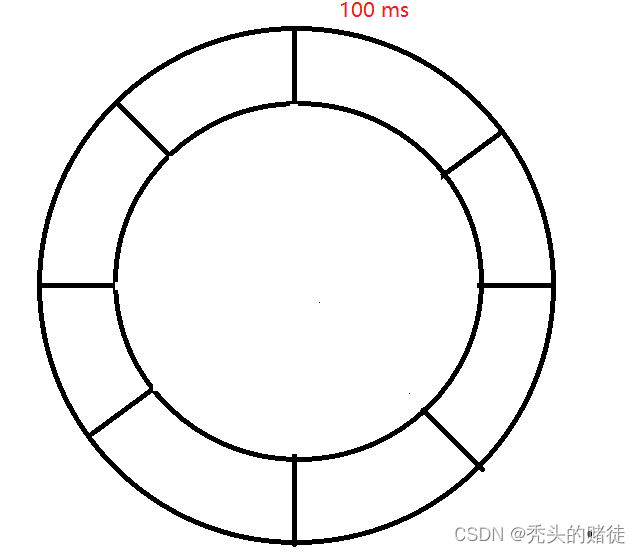
- 基于时间轮:根据过期时间,除以时间轮的粒度(每格多长时间),来确认当前key 放置哪个格子中,每个格子中维护一个链表,当时间轮执行到哪个格子中,会遍历当前格子中的链表,确定哪些key是过期需要删除的
七. reids 的应用场景
7.1 string
作为缓存 ,储存高频被使用的数据,提高读写性能和相应速度,减少对后端数据库的压力
作为计数器,实现快速计数、查询缓存的功能,同时数据可以异步处理或者落地到其他数据源。记录视频的播放次数、文章的阅读量
存储session,实现会话共享:
使用原生字符串类型,每个属性一个键:1 set user:1:name TOM 2 set user:1:age 23 3 set user:1:city Beijing优点:实现简单,针对个别属性变更很灵活
缺点: 占用过多的键,内存占用量较大,同时用户信息在redis 中比较分散,缺少内聚性,所以这种方案基本没有实用性
序列化字符串类型,例如 JSON 格式set user:1 "name:zhangsan,gender:boy,age:11"优点:针对总是以整体作为操作的信息比较合适,编程也简单。同时,如果序列化方案选择合适,内存的使用效率很高。
缺点:序列化和反序列需要一定开销,同时如果总是操作个别属性则非常不灵活。手机验证码:验证码获取,一分钟不能超过5次
String 发送验证码(phoneNumber) { key = "shortMsg:limit:" + phoneNumber; // 设置过期时间为 1 分钟(60 秒) // 使⽤ NX,只在不存在 key 时才能设置成功 bool r = Redis 执⾏命令:set key 1 ex 60 nx if (r == false) { // 说明之前设置过该⼿机的验证码了 long c = Redis 执⾏命令:incr key if (c > 5) { // 说明超过了⼀分钟 5 次的限制了 // 限制发送 return null; } } // 说明要么之前没有设置过⼿机的验证码;要么次数没有超过 5 次 String validationCode = ⽣成随机的 6 位数的验证码(); validationKey = "validation:" + phoneNumber; // 验证码 5 分钟(300 秒)内有效 Redis 执⾏命令:set validationKey validationCode ex 300; // 返回验证码,随后通过⼿机短信发送给⽤⼾ return validationCode ; } // 验证⽤⼾输⼊的验证码是否正确 bool 验证验证码(phoneNumber, validationCode) { validationKey = "validation:" + phoneNumber; String value = Redis 执⾏命令:get validationKey; if (value == null) { // 说明没有这个⼿机的验证码记录,验证失败 return false; } if (value == validationCode) { return true; } else { return false; } }
7.2 hash
作为缓存,存储用户信息
上述string 时,说过可以存储用户信息:
hmset user:1 name James age 23 city Beijing优点:简单、直观、灵活。尤其是对信息的布局变更或者获取操作
缺点:需要控制哈希在 ziplist 和 hashtable 两种内部编码的转换,可能会造成内存的较大消耗。
7.3 list
实现简单的消息队列、存储某项列表数据。















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









