










关注后可自取代码
一、爬取的目标网站:豆瓣读书 Top 250
二、网站结构如下
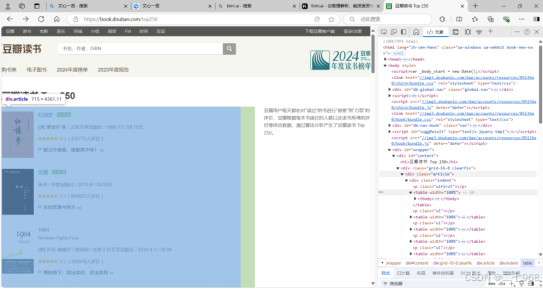
三、首先在目标页面找的要爬取信息的位置
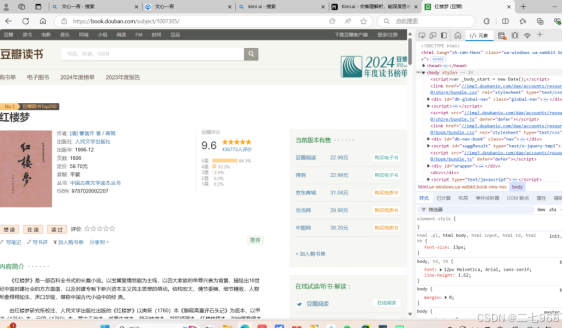
四、爬取数据。
目标数据内容包括top250书籍的书名,作者,豆瓣链接,译者,出版社,出版日期,书籍的价格,评分和一句话评语。
1.导入需要的库
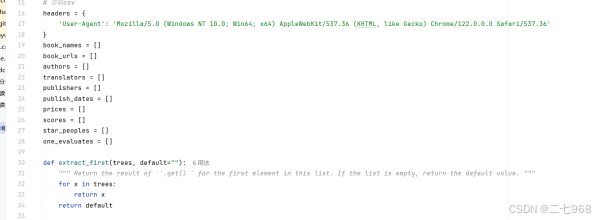
2.设置字段对爬取的信息进行存储
定义了一些空列表,用于存储爬取的书籍信息,包括书名、URL、作者、译者、出版社、出版日期、价格、评分、评分人数和一句话评价。
定义了一个辅助函数extract_first,用于从列表中提取第一个非空元素,如果列表为空,则返回默认值。
3.爬取数据
def parse(url):
""" 爬取页面数据
@param url: 爬取的起始页面
@return: None
"""
print(f"开始爬取:{url}") # 打印当前正在爬取的页面URL
page_source = requests.get(url, headers=headers).text # 发送HTTP请求,获取页面内容
tree = etree.HTML(page_source) # 使用lxml解析HTML内容
# 获得数据:XPath选择器定位到包含书籍信息的表格
tables = tree.xpath('//div[@id="content"]/div/div[1]/div/table')
for table in tables:
top = table.xpath(".//td[@valign='top']")[-1] # 获取表格中最后一列,包含书名等信息
# 书名 豆瓣链接、作者、译者、出版社、出版日期、价格、评分、评分人数、一句话评价
book_name = extract_first(top.xpath("./div/a/text()")).strip() # 获取书名
url = extract_first(top.xpath("./div/a/@href")).strip() # 获取书籍的豆瓣链接
info = extract_first(top.xpath("./p[@class='pl']/text()")).strip() # 获取书籍的详细信息,包括作者、译者、出版社等
author = None
translator = None
publish = None
publish_date = None
price = None
# 根据信息的格式不同,进行不同的解析
infos = info.split("/")
if len(infos) == 5:
author = infos[0]
translator = infos[1]
publish = infos[2]
publish_date = infos[3]
price = infos[4]
elif len(infos) == 4:
author = infos[0]
publish = infos[1]
publish_date = infos[2]
price = infos[3]
elif len(infos) == 6: # 有2个价格的情况
author = infos[0]
translator = infos[1]
publish = infos[2]
publish_date = infos[3]
price = str(infos[4]) + "/" + str(infos[5])
elif len(infos) == 3: # 没有作者和译者的情况
publish = infos[0]
publish_date = infos[1]
price = infos[2]
else:
print(f"未匹配到的格式 书名={book_name}", infos)
# 提取评分、评分人数和一句话评价
score = extract_first(top.xpath("./div[@class='star clearfix']/span[@class='rating_nums']/text()")).strip()
star_people = extract_first(top.xpath("./div[@class='star clearfix']/span[@class='pl']/text()")).strip()
star_people_num = re.search("\d+", star_people).group() # 提取评分人数中的数字
one_evaluate = extract_first(top.xpath("./p[@class='quote']/span/text()")).strip()
# 将提取的信息添加到列表中
book_names.append(book_name)
book_urls.append(url)
authors.append(author)
translators.append(translator)
publishers.append(publish)
publish_dates.append(publish_date)
prices.append(str(price))
scores.append(str(score))
star_peoples.append(str(star_people_num))
one_evaluates.append(one_evaluate)
# 判断是否有下一页,并继续爬取
next_page = tree.xpath("//div[@class='paginator']/span[@class='next']")[0]
a = next_page.xpath("./a")
if a:
a_href = a[0].xpath("./@href")[0] # 获取下一页的链接
parse(a_href) # 递归调用parse函数,爬取下一页数据
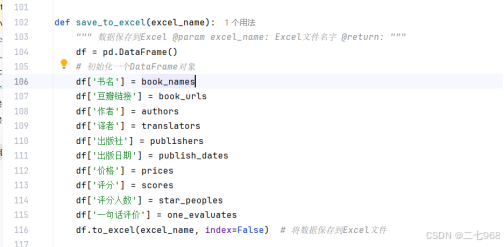
4.将数据保存到excel表格中
这个函数接受一个参数 excel_name,它是要保存的Excel文件的名称。函数内部首先创建了一个空的pandas DataFrame对象,然后将爬取的书籍信息(书名、豆瓣链接、作者等)作为列添加到这个DataFrame中。最后,使用 to_excel 方法将DataFrame保存为一个Excel文件,文件名由 excel_name 参数指定。index=False 参数表示在保存时不包括DataFrame的行索引。
5.对数据进行可视化分析

生成图表
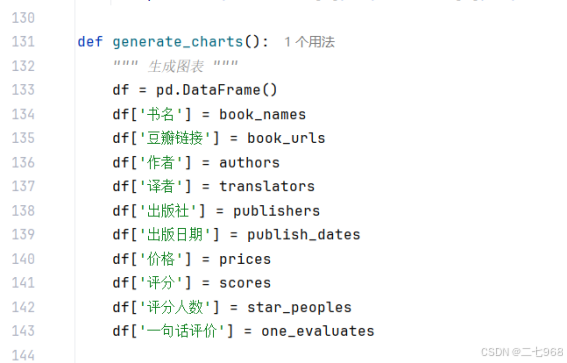
书籍评分分布进行统计这个函数没有接受任何参数。它首先创建了一个空的 DataFrame 对象,并将之前爬取的书籍信息(书名、豆瓣链接、作者等)作为列添加到这个 DataFrame 中。接着,使用 matplotlib 库的 figure 函数设置图表的大小,然后使用 seaborn 库的 histplot 函数绘制评分的直方图,其中 bins=10 表示将评分分成10个区间,kde=False 表示不显示核密度估计曲线。
函数设置了图表的标题、x轴和y轴的标签,并使用 savefig 方法将图表保存为名为 '评分分布图.png' 的图片文件。最后,使用 show 方法显示图表。

6.进行词云统计
这个函数用于生成词云图,它没有接受任何参数。函数内部首先将所有爬取的一句话评价拼接成一个长字符串,然后使用 jieba.cut 方法进行中文分词,将字符串分割成单独的词语。接下来,使用 WordCloud 类创建一个词云对象,指定字体路径(font_path)为 'simhei.ttf' 以支持中文显示,并设置背景颜色为白色(background_color='white')。最后,调用 generate 方法生成词云,并将分词后的结果作为输入。

五、完整代码如下:(尊重代码成果,请点赞关注后自行复制)
import tkinter as tk
from tkinter import messagebox
import requests
from bs4 import BeautifulSoup
import sqlite3
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from openpyxl import Workbook
import os
# 第三方库加载函数(实际上这些库已经在代码顶部导入了,这里只是为了展示如何在GUI中处理)
def load_libraries():
# 这里可以添加任何初始化或检查库是否成功加载的代码
print("Libraries loaded successfully.")
# 爬取网站信息函数
def crawl_website():
url = "https://book.douban.com/top250?start=0"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'lxml')
# 这里应该添加解析HTML并提取数据的代码
# 由于示例限制,这里只打印一个简短的消息
print("Website crawled successfully.")
# 假设我们已经有了一个数据字典列表data_list
# 每个字典代表一本书的信息
data_list = [] # 这里应该填充数据
return data_list
# 将信息保存到sqlite数据库表中
def save_to_sqlite(data_list):
conn = sqlite3.connect('douban_books.db')
c = conn.cursor()
c.execute('''CREATE TABLE IF NOT EXISTS books
(id INTEGER PRIMARY KEY,
title TEXT,
author TEXT,
rating REAL,
# 其他字段...
)''')
for data in data_list:
c.execute("INSERT INTO books (title, author, rating) VALUES (?, ?, ?)",
(data['title'], data['author'], data['rating']))
conn.commit()
conn.close()
print("Data saved to SQLite database successfully.")
# 将信息保存到Excel表中
def save_to_excel(data_list):
df = pd.DataFrame(data_list)
df.to_excel('douban_books.xlsx', index=False)
print("Data saved to Excel file successfully.")
# 生成词云
def generate_wordcloud(data_list):
text = ' '.join([data['title'] + ' ' + data['author'] for data in data_list])
wordcloud = WordCloud(font_path='simhei.ttf', # 确保有中文字体文件
width=800, height=400, background_color='white').generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
# 如果需要保存词云图片
# plt.savefig('wordcloud.png')
# GUI函数
def create_gui():
root = tk.Tk()
root.title("豆瓣读书TOP250爬虫")
# 加载库按钮
load_lib_btn = tk.Button(root, text="加载库", command=load_libraries)
load_lib_btn.pack(pady=10)
# 爬取数据按钮
crawl_btn = tk.Button(root, text="爬取数据", command=lambda: save_data_after_crawling(save_to_sqlite))
crawl_btn.pack(pady=10)
# 保存到SQLite按钮(这里为了演示,直接调用爬取并保存的函数)
save_sqlite_btn = tk.Button(root, text="保存到SQLite", command=lambda: save_data_after_crawling(save_to_sqlite))
save_sqlite_btn.pack(pady=10)
# 保存到Excel按钮
save_excel_btn = tk.Button(root, text="保存到Excel", command=lambda: save_data_after_crawling(save_to_excel))
save_excel_btn.pack(pady=10)
# 生成词云按钮
wordcloud_btn = tk.Button(root, text="生成词云", command=lambda: generate_wordcloud_after_crawling())
wordcloud_btn.pack(pady=10)
root.mainloop()
# 爬取数据并保存的函数(封装了爬取和保存的逻辑)
def save_data_after_crawling(save_func):
try:
data_list = crawl_website()
save_func(data_list)
messagebox.showinfo("成功", "数据保存成功!")
except Exception as e:
messagebox.showerror("错误", f"数据保存失败:{str(e)}")
# 生成词云并保存的函数(需要先爬取数据)
def generate_wordcloud_after_crawling():
try:
# 这里假设我们已经有一个全局变量或文件来存储爬取的数据
# 由于示例限制,我们重新爬取一次(实际应用中应避免这样做)
data_list = crawl_website()
generate_wordcloud(data_list)
except Exception as e:
messagebox.showerror("错误", f"生成词云失败:{str(e)}")
# 确保有中文字体文件(用于词云)
if not os.path.exists('simhei.ttf'):
# 这里可以提供一个下载链接或让用户自行下载中文字体文件
raise FileNotFoundError("缺少中文字体文件simhei.ttf,请下载后放在当前目录下。")
# 运行GUI
create_gui()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









