







一、Java 基础
1. JDK 和 JRE 有什么区别?
JDK:Java Development Kit 的简称,java 开发工具包,提供了 java 的开发环境和运行环境。
JRE:Java Runtime Environment 的简称,java 运行环境,为 java 的运行提供了所需环境。
具体来说 JDK 其实包含了 JRE,同时还包含了编译 java 源码的编译器 javac,还包含了很多 java 程序调试和分析的工具。简单来说:如果你需要运行 java 程序,只需安装 JRE 就可以了,如果你需要编写 java 程序,需要安装 JDK。
2. == 和 equals 的区别是什么?
== 解读
对于基本类型和引用类型 == 的作用效果是不同的,如下所示:
基本类型:比较的是值是否相同;
引用类型:比较的是引用是否相同;
代码示例:
Stringx="string";
Stringy="string";
Stringz=newString("string");
System.out.println(x==y); // true
System.out.println(x==z); // false
System.out.println(x.equals(y)); // true
System.out.println(x.equals(z)); // true
代码解读:因为 x 和 y 指向的是同一个引用,所以 == 也是 true,而 new String()方法则重写开辟了内存空间,所以 == 结果为 false,而 equals 比较的一直是值,所以结果都为 true。
equals 解读
equals 本质上就是 ==,只不过 String 和 Integer 等重写了 equals 方法,把它变成了值比较。看下面的代码就明白了。
首先来看默认情况下 equals 比较一个有相同值的对象,代码如下:
class Cat {
public Cat(String name) {
this.name = name;
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Cat c1 = new Cat("王磊");
Cat c2 = new Cat("王磊");
System.out.println(c1.equals(c2)); // false
输出结果出乎我们的意料,竟然是 false?这是怎么回事,看了 equals 源码就知道了,源码如下:
public boolean equals(Object obj) {
return (this == obj);
}
原来 equals 本质上就是 ==。
那问题来了,两个相同值的 String 对象,为什么返回的是 true?代码如下:
String s1 = new String("老王");
String s2 = new String("老王");
System.out.println(s1.equals(s2)); // true
同样的,当我们进入 String 的 equals 方法,找到了答案,代码如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
原来是 String 重写了 Object 的 equals 方法,把引用比较改成了值比较。
总结 :== 对于基本类型来说是值比较,对于引用类型来说是比较的是引用;而 equals 默认情况下是引用比较,只是很多类重新了 equals 方法,比如 String、Integer 等把它变成了值比较,所以一般情况下 equals 比较的是值是否相等。
3. 两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
不对,两个对象的 hashCode()相同,equals()不一定 true。
代码示例:
String str1 = "通话";
String str2 = "重地";
System.out.println(String.format("str1:%d | str2:%d", str1.hashCode(),str2.hashCode()));
System.out.println(str1.equals(str2));
执行的结果:
str1:1179395 | str2:1179395
false
代码解读:很显然“通话”和“重地”的 hashCode() 相同,然而 equals() 则为 false,因为在散列表中,hashCode()相等即两个键值对的哈希值相等,然而哈希值相等,并不一定能得出键值对相等。
4. final 在 java 中有什么作用?
final 修饰的类叫最终类,该类不能被继承。
final 修饰的方法不能被重写。
final 修饰的变量叫常量,常量必须初始化,初始化之后值就不能被修改。
5. java 中的 Math.round(-1.5) 等于多少?
等于 -1,因为在数轴上取值时,中间值(0.5)向右取整,所以正 0.5 是往上取整,负 0.5 是直接舍弃。
6. String 属于基础的数据类型吗?
String 不属于基础类型,基础类型有 8 种:byte、boolean、char、short、int、float、long、double,而 String 属于对象。
整型:byte(8)(占一个字节)、short(16)、int(32)、long(64)
浮点型:float(32)、double(64)
布尔型:boolean(8)
字符型:char(16)
7. java 中操作字符串都有哪些类?它们之间有什么区别?
操作字符串的类有:String、StringBuffer、StringBuilder。
String 和 StringBuffer、StringBuilder 的区别在于 String 声明的是不可变的对象,每次操作都会生成新的 String 对象,然后将指针指向新的 String 对象,而 StringBuffer、StringBuilder 可以在原有对象的基础上进行操作,所以在经常改变字符串内容的情况下最好不要使用 String。
StringBuffer 和 StringBuilde r 最大的区别在于,StringBuffer 是线程安全的,而 StringBuilder 是非线程安全的,但 StringBuilder 的性能却高于 StringBuffer,所以在单线程环境下推荐使用 StringBuilder,多线程环境下推荐使用 StringBuffer。
8. String str="i"与 String str=new String("i")一样吗?
不一样,因为内存的分配方式不一样。String str="i"的方式,java 虚拟机会将其分配到常量池中;而 String str=new String("i") 则会被分到堆内存中。
9. 如何将字符串反转?
使用 StringBuilder 或者 stringBuffer 的 reverse() 方法。
示例代码:
// StringBuffer reverse
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("abcdefg");
System.out.println(stringBuffer.reverse()); // gfedcba
// StringBuilder reverse
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("abcdefg");
System.out.println(stringBuilder.reverse()); // gfedcba
10. String 类的常用方法都有那些?
indexOf():返回指定字符的索引。
charAt():返回指定索引处的字符。
replace():字符串替换。
trim():去除字符串两端空白。
split():分割字符串,返回一个分割后的字符串数组。
getBytes():返回字符串的 byte 类型数组。
length():返回字符串长度。
toLowerCase():将字符串转成小写字母。
toUpperCase():将字符串转成大写字符。
substring():截取字符串。
equals():字符串比较。
11. 抽象类必须要有抽象方法吗?
不需要,抽象类不一定非要有抽象方法。
示例代码:
abstract class Cat {
public static void sayHi() {
System.out.println("hi~");
}
}
上面代码,抽象类并没有抽象方法但完全可以正常运行。
12. 普通类和抽象类有哪些区别?
普通类不能包含抽象方法,抽象类可以包含抽象方法。
抽象类不能直接实例化,普通类可以直接实例化。
13. 抽象类能使用 final 修饰吗?
不能,定义抽象类就是让其他类继承的,如果定义为 final 该类就不能被继承,这样彼此就会产生矛盾,所以 final 不能修饰抽象类,如下图所示,编辑器也会提示错误信息:
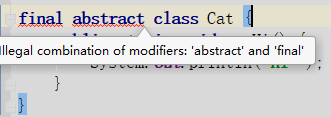
14. 接口和抽象类有什么区别?
实现:抽象类的子类使用 extends 来继承;接口必须使用 implements 来实现接口。
构造函数:抽象类可以有构造函数;接口不能有。
main 方法:抽象类可以有 main 方法,并且我们能运行它;接口不能有 main 方法。
实现数量:类可以实现很多个接口;但是只能继承一个抽象类。
访问修饰符:接口中的方法默认使用 public 修饰;抽象类中的方法可以是任意访问修饰符。
15. java 中 IO 流分为几种?
按功能来分:输入流(input)、输出流(output)。
按类型来分:字节流和字符流。
字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输入输出数据。
16. BIO、NIO、AIO 有什么区别?
BIO:Block IO 同步阻塞式 IO,就是我们平常使用的传统 IO,它的特点是模式简单使用方便,并发处理能力低。
NIO:New IO 同步非阻塞 IO,是传统 IO 的升级,客户端和服务器端通过 Channel(通道)通讯,实现了多路复用。
AIO:Asynchronous IO 是 NIO 的升级,也叫 NIO2,实现了异步非堵塞 IO ,异步 IO 的操作基于事件和回调机制。
17. Files的常用方法都有哪些?
Files.exists():检测文件路径是否存在。
Files.createFile():创建文件。
Files.createDirectory():创建文件夹。
Files.delete():删除一个文件或目录。
Files.copy():复制文件。
Files.move():移动文件。
Files.size():查看文件个数。
Files.read():读取文件。
Files.write():写入文件。
二、容器
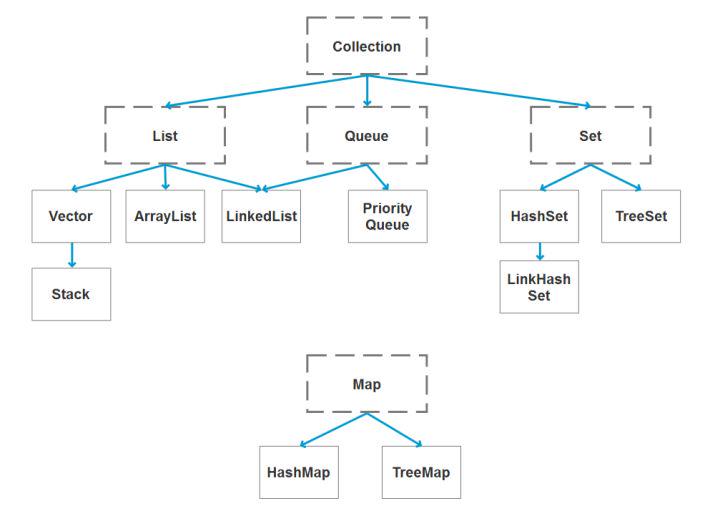
18. java 容器都有哪些?
常用容器图录:
19. Collection 和 Collections 有什么区别?
java.util.Collection 是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
20. List、Set、Map 之间的区别是什么?
list:有序可重复 set:无序不可重复

链表与数组的主要区别(1)数组的元素个数是固定的,查找元素利用下标定位;时间复杂度o(1);而组成链表的结点个数可按需要增减;
时间复杂度o(n);
(2)插入,删除用链表比数组好;
(3) 数组静态分配内存,链表动态分配内存;
(4) 数组在内存中连续,链表不连续;
(5) 数组元素在栈区,链表在堆区;
21. HashMap 和 Hashtable 有什么区别?
hashMap去掉了HashTable 的contains方法,但是加上了containsValue()和containsKey()方法。
hashTable是同步的,而HashMap是非同步的,效率上比hashTable要高。
hashMap允许空键值,而hashTable不允许。
HashTable的每个方法都用synchronized修饰,因此是线程安全的,但同时读写效率很低
22. 如何决定使用 HashMap 还是 TreeMap?
对于在Map中插入、删除和定位元素这类操作,HashMap是最好的选择。然而,假如你需要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,也许向HashMap中添加元素会更快,将map换为TreeMap进行有序key的遍历。
23. 说一下 HashMap 的实现原理?
jdk1.8 数组+链表+红黑树来实现并允许使用null值和null键
HashMap的扩容机制:
HashMap的默认容量为16,默认的负载因子为0.75,当HashMap中元素个数超过容量乘以负载因子的个数时,就创建一个大小为前一次两倍的新数组,再将原来数组中的数据复制到新数组中。当数组长度到达64且链表长度大于8时,链表转为红黑树。
HashMap存取原理:
(1)计算key的hash值,然后进行二次hash,根据二次hash结果找到对应的索引位置
(2)如果这个位置有值,先进性equals比较,若结果为true则取代该元素,若结果为false,就使用高低位平移法将节点插入链表(JDK8以前使用头插法,但是头插法在并发扩容时可能会造成环形链表或数据丢失,而高低位平移发会发生数据覆盖的情况)
24. 说一下 HashSet 的实现原理?
HashSet底层由HashMap实现
HashSet的值存放于HashMap的key上
HashMap的value统一为PRESENT
25. ArrayList 和 LinkedList 的区别是什么?
最明显的区别是 ArrrayList底层的数据结构是数组,支持随机访问,而 LinkedList 的底层数据结构是双向循环链表,不支持随机访问。使用下标访问一个元素,ArrayList 的时间复杂度是 O(1),而 LinkedList 是 O(n)。
26. 如何实现数组和 List 之间的转换?
List转换成为数组:调用ArrayList的toArray方法。
数组转换成为List:调用Arrays的asList方法。
//List转数组
ArrayList<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
System.out.println(list);
String[] array = list.toArray(new String[0]);
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
//数组转list
String[] array1 = new String[]{"aa","bb","cc"};
ArrayList<String> strings = new ArrayList<>();
for (String s : array1) {
strings.add(s);
}
System.out.println(strings);
27. ArrayList 和 Vector 的区别是什么?
Vector是同步的,而ArrayList不是。然而,如果你寻求在迭代的时候对列表进行改变,你应该使用CopyOnWriteArrayList。
ArrayList比Vector快,它因为有同步,不会过载。
ArrayList更加通用,因为我们可以使用Collections工具类轻易地获取同步列表和只读列表。
28. Array 和 ArrayList 有何区别?
Array可以容纳基本类型和对象,而ArrayList只能容纳对象。
Array是指定大小的,而ArrayList大小是固定的。
Array没有提供ArrayList那么多功能,比如addAll、removeAll和iterator等。
29. 在 Queue 中 poll()和 remove()有什么区别?
poll() 和 remove() 都是从队列中取出一个元素,但是 poll() 在获取元素失败的时候会返回空,但是 remove() 失败的时候会抛出异常。
30. 哪些集合类是线程安全的?
vector:就比arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用。在web应用中,特别是前台页面,往往效率(页面响应速度)是优先考虑的。
statck:堆栈类,先进后出。
hashtable:就比hashmap多了个线程安全。
enumeration:枚举,相当于迭代器。
31. 迭代器 Iterator 是什么?
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。
32. Iterator 怎么使用?有什么特点?
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
33. Iterator 和 ListIterator 有什么区别?
Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
ListIterator实现了Iterator接口,并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引,等等。
三、多线程
35. 并行和并发有什么区别?
并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。
并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。
在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群。
所以并发编程的目标是充分的利用处理器的每一个核,以达到最高的处理性能。
36. 线程和进程的区别?
简而言之,进程是程序运行和资源分配的基本单位,一个程序至少有一个进程,一个进程至少有一个线程。进程在执行过程中拥有独立的内存单元,而多个线程共享内存资源,减少切换次数,从而效率更高。线程是进程的一个实体,是cpu调度和分派的基本单位,是比程序更小的能独立运行的基本单位。同一进程中的多个线程之间可以并发执行。
进程间的通信方式:管道(pipe);命名管道(FIFO);消息队列;共享存储;信号量;套接字;信号。
37. 守护线程是什么?
守护线程(即daemon thread),是个服务线程,准确地来说就是服务其他的线程。
38. 创建线程有哪几种方式?
①. 继承Thread类创建线程类
定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
创建Thread子类的实例,即创建了线程对象。
调用线程对象的start()方法来启动该线程。
public class MyThread extends Thread {
@Override
public void run() {
System.out.println("通过集成 Thread 类实现线程");
}
}
// 如何使用
new MyThread().start()
②. 通过实现Runnable接口创建线程类(无返回值)
定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
调用线程对象的start()方法来启动该线程。
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("通过实现 Runnable 方式实现线程");
}
}
// 使用
// 1、创建MyRunnable实例
MyRunnable runnable = new MyRunnable();
//2.创建Thread对象
//3.将MyRunnable放入Thread实例中
Thread thread = new Thread(runnable);
//4.通过线程对象操作线程(运行、停止)
thread.start();
③. 通过Callable和Future创建线程(有返回值)
创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
使用FutureTask对象作为Thread对象的target创建并启动新线程。
调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return new Random().nextInt();
}
// 使用方法
// 1、创建线程池
ExecutorService service = Executors.newFixedThreadPool(10);
// 2、提交任务,并用 Future提交返回结果
Future< Integer > future = service.submit(new MyCallable());
}
39. 说一下 Runnable 和 Callable 有什么区别?
有点深的问题了,也看出一个Java程序员学习知识的广度。
Runnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;
Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。
40. 线程有哪些状态?
线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
创建状态。在生成线程对象,并没有调用该对象的start方法,这是线程处于创建状态。
就绪状态。当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
运行状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。
阻塞状态。线程正在运行的时候,被暂停,通常是为了等待某个时间的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。
死亡状态。如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪
41. sleep() 和 wait() 有什么区别?
sleep():方法是线程类(Thread)的静态方法,让调用线程进入睡眠状态,让出执行机会给其他线程,等到休眠时间结束后,线程进入就绪状态和其他线程一起竞争cpu的执行时间。因为sleep() 是static静态的方法,他不能改变对象的机锁,当一个synchronized块中调用了sleep() 方法,线程虽然进入休眠,但是对象的机锁没有被释放,其他线程依然无法访问这个对象。
wait():wait()是Object类的方法,当一个线程执行到wait方法时,它就进入到一个和该对象相关的等待池,同时释放对象的机锁,使得其他线程能够访问,可以通过notify,notifyAll方法来唤醒等待的线程。
42. notify()和 notifyAll()有什么区别?
如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。也就是说,调用了notify后只有一个线程会由等待池进入锁池,而notifyAll会将该对象等待池内的所有线程移动到锁池中,等待锁竞争。
优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
43. 线程的 run()和 start()有什么区别?
每个线程都是通过某个特定Thread对象所对应的方法run()来完成其操作的,方法run()称为线程体。通过调用Thread类的start()方法来启动一个线程。
start()方法来启动一个线程,真正实现了多线程运行。这时无需等待run方法体代码执行完毕,可以直接继续执行下面的代码; 这时此线程是处于就绪状态, 并没有运行。 然后通过此Thread类调用方法run()来完成其运行状态, 这里方法run()称为线程体,它包含了要执行的这个线程的内容, Run方法运行结束, 此线程终止。然后CPU再调度其它线程。
run()方法是在本线程里的,只是线程里的一个函数,而不是多线程的。 如果直接调用run(),其实就相当于是调用了一个普通函数而已,直接待用run()方法必须等待run()方法执行完毕才能执行下面的代码,所以执行路径还是只有一条,根本就没有线程的特征,所以在多线程执行时要使用start()方法而不是run()方法。
44. 创建线程池有哪几种方式?
①. newFixedThreadPool(int nThreads)
创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程规模将不再变化,当线程发生未预期的错误而结束时,线程池会补充一个新的线程。
②. newCachedThreadPool()
创建一个可缓存的线程池,如果线程池的规模超过了处理需求,将自动回收空闲线程,而当需求增加时,则可以自动添加新线程,线程池的规模不存在任何限制。
③. newSingleThreadExecutor()
这是一个单线程的Executor,它创建单个工作线程来执行任务,如果这个线程异常结束,会创建一个新的来替代它;它的特点是能确保依照任务在队列中的顺序来串行执行。
④. newScheduledThreadPool(int corePoolSize)
创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
public class demo4 {
public static void main(String[] args) {
//固定线程池(控制线程最大并发数)
//ExecutorService pool = Executors.newFixedThreadPool(2);
//单个线程池
//ExecutorService pool = Executors.newSingleThreadExecutor();
//可变线程池
//ExecutorService pool = Executors.newCachedThreadPool();
//延迟连接池
ScheduledExecutorService pool = Executors.newScheduledThreadPool(2);
Thread t1 = new MyThread();
Thread t2 = new MyThread();
Thread t3 = new MyThread();
Thread t4 = new MyThread();
Thread t5 = new MyThread();
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
//使用延迟执行风格
pool.schedule(t4,1, TimeUnit.SECONDS);
pool.schedule(t5,1, TimeUnit.SECONDS);
pool.shutdown();
}
//重写方法ctrl+0
static class MyThread extends Thread {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"正在运行。。。");
}
}
}
线程池的7大参数:
参数一:核心线程数
参数二:最大线程数,在我们通过线程池获取线程数<=最大线程数时,只会使用核心线程数中的线程,比如上面这个参数,核心线程数为2,最大线程数为5,当我们从线程池中获取的线程数<=5时,只会使用2个核心线程数去交替完成
参数三:超时等待时间
参数四:超时等待时间的单位
参数五:阻塞队列,使用数组或者链表都可以,参数为3,可以理解为如果我们一次性从线程池获取线程数>最大线程数+阻塞队列大小,就需要使用到四大拒绝策略
参数六:线程工厂
参数七:拒绝策略
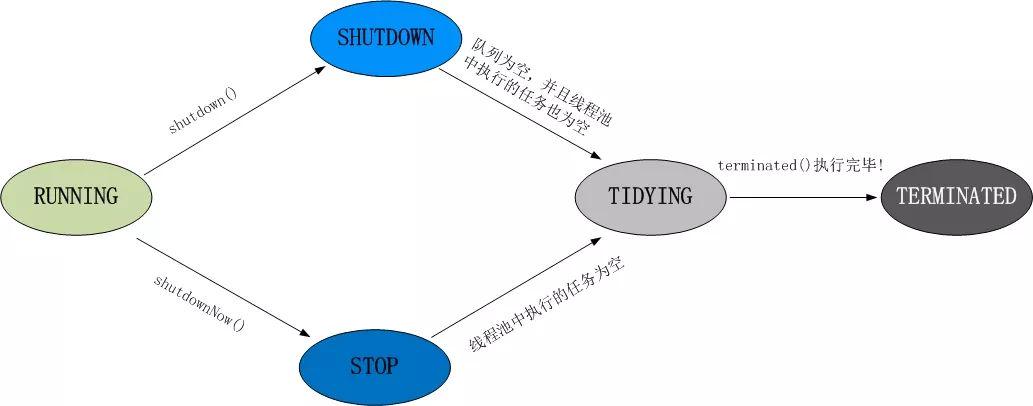
45. 线程池都有哪些状态?
线程池有5种状态:Running、ShutDown、Stop、Tidying(整理)、Terminated(终止)。
线程池各个状态切换框架图:
46. 线程池中 submit()和 execute()方法有什么区别?
execute只能提交Runnable类型的任务,无返回值。submit既可以提交Runnable类型的任务,也可以提交Callable类型的任务,
submit有返回值,类型为Future;而execute没有
submit方便Exception处理
47. 在 java 程序中怎么保证多线程的运行安全?
线程安全在三个方面体现:
原子性:提供互斥访问,同一时刻只能有一个线程对数据进行操作,(atomic,synchronized);
可见性:一个线程对主内存的修改可以及时地被其他线程看到,(synchronized,volatile);
有序性:一个线程观察其他线程中的指令执行顺序,由于指令重排序,该观察结果一般杂乱无序,(happens-before原则)。
禁止指令重排。
48. 多线程锁的升级原理是什么?
在Java中,锁共有4种状态,级别从低到高依次为:无状态锁,偏向锁,轻量级锁和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级。
锁升级的图示过程:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









