







作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:大家是否曾想过购买券商或咨询机构的股票分析报告?或者动过自己动手编写某只股票分析报告的念头?我也是投资者,深知手动搜集和处理大量数据的的繁琐。所以今天我来分享一个方法:用Python自动编写报告。接下来我将带您一步步学习如何用Python和FMP API轻松实现股票数据的自动化获取和分析。让投资分析更高效、简单!
在这个只谈论人工智能的世界里,更不能忽视 AI+自动化的力量,尤其是对于独立投资者来说,他们可能没有时间大规模研究个股,也不知道如何与同行业的竞争对手进行比较。虽然许多网站和应用程序都能为您实现这一目标,但通常都要付出一定的代价,而且您无法完全按照自己的意愿进行定制。在本文中,我将指导读者如何使用 Python 和金融建模准备 API 中的数据来生成给定股票的分析报告。
一、获取数据
我们将利用我在 Python 中构建的 SP500 类来获取数据。因为这将是我们如何为本项目导入数据的核心。为了方便起见,我还在下面链接的文章中附上了该类的完整代码,以及你在编写代码时需要的所有库!
文章:《金融达人必备:教你用Python轻松简化数据分析流程!》
我们将为这个项目导入大量数据,这需要一些时间。一旦我们的 SP500 类拥有了所有数据,我们生成报告的可能性将变得无穷无尽。请注意 time.sleep() 方法。我添加该方法是因为您可能需要暂停导入数据的过程,这取决于您的 FMP 订阅允许多少次 API 调用。
api_key = 'your_api_key_here'
sp500_data_instance = SP500data(api_key = api_key)
sp500_data_instance.get_symbols()
sp500_data_instance.fetch_price_data()
time.sleep(45)
sp500_data_instance.fetch_profile_data()
time.sleep(45)
sp500_data_instance.fetch_dividend_data_concurrent()
time.sleep(45)
sp500_data_instance.fetch_income_statement_data_annual_concurrent()
time.sleep(45)
sp500_data_instance.fetch_balance_sheet_data_annual_concurrent()
time.sleep(45)
sp500_data_instance.fetch_key_metrics_data_annual_concurrent()二、报告编写
既然数据已经导入,我们就可以开始准备报告了,但首先让我们了解一下报告的核心内容。
2.1 报告组成
首先,我们将在简介部分介绍报告所涉及的公司、正式描述、当前市值、行业和部门,最后是其最新年度财务报告(10K)的链接。
接下来,我们将介绍一些有关收入的基本趋势。这将介绍公司过去 10 年的收入、净利润和每股收益。
最后,我们将介绍我最喜欢的几个关键指标的趋势:市盈率、市净率、资产负债率、流动比率和利息保障比率。通过这些指标,可以了解公司目前的估值以及债务管理情况。请注意,我们还可以包括其他一些指标。
2.2 数据准备
大部分繁重的工作已经完成;现在,我们必须提取我们想要的特定股票的信息。我们要仔细研究特斯拉(TSLA)。首先,我们利用下面的脚本提取基本信息。查看 format_large_number() 函数。提取市值时,会以字符串形式返回。该函数将以 X 万、X 亿或 X 万亿的形式返回市值数字,使其更具可读性。
symbol = 'TSLA'
name = sp500_data_instance.company_profile_df[sp500_data_instance.company_profile_df['symbol'] == symbol]['companyName'].values[0]
market_cap = sp500_data_instance.company_profile_df[sp500_data_instance.company_profile_df['symbol'] == symbol]['mktCap'].values[0]
market_cap = f'{market_cap:,}'
industry = sp500_data_instance.company_profile_df[sp500_data_instance.company_profile_df['symbol'] == symbol]['industry'].values[0]
sector = sp500_data_instance.company_profile_df[sp500_data_instance.company_profile_df['symbol'] == symbol]['sector'].values[0]
description = sp500_data_instance.company_profile_df[sp500_data_instance.company_profile_df['symbol'] == symbol]['description'].values[0]# Function to format large numbers
def format_large_number(number):
# Ensure the number is converted to an integer or float if it's a string
number = float(number.replace(',', '')) if isinstance(number, str) else number
if number >= 1_000_000_000_000:
return f"{number / 1_000_000_000_000:.1f} trillion"
elif number >= 1_000_000_000:
return f"{number / 1_000_000_000:.1f} billion"
elif number >= 1_000_000:
return f"{number / 1_000_000:.1f} million"
else:
return str(number)
market_cap = format_large_number(market_cap)接下来,我们将提取 TSLA 历史利润表和关键指标的数据。我们还需要至少 10 年的数据,以了解任何可能的趋势。FMP 还在这些端点中包含指向美国证券交易委员会文件的链接。我还添加了逻辑来捕捉这些数据。
lookback = 10
annual_income_statement_data = sp500_data_instance.income_statement_data_annual[symbol].sort_values(by='date').tail(lookback)
annual_key_metric_data = sp500_data_instance.key_metrics_data_annual[symbol].sort_values(by='date').tail(lookback)
link_to_filings = annual_income_statement_data['link'].tail(1)[0]一图胜千言,我制作了另一个 Python 类,名为 VizFin(),而不是手动为我们想要提取的指标创建多个图表。该类将使用我们的一个财务报表数据帧,并根据我们指定的指标创建一个折线图。它还会将图表保存到我们的工作目录中,以便我们以后创建文档时引用。结合循环,我们可以轻松快速地创建所有需要的图表。
class VizFin():
def __init__(self):
self.chart_path = None
def viz_fin_data(self,df,x,y,symbol):
# Use Seaborn styling
sns.set_theme(style="darkgrid")
# Create figure and axis
plt.figure(figsize=(10, 6))
# Plot the data with a line and markers
plt.plot(df[x], df[y], marker='o', linestyle='-', color='#2C7BB6', linewidth=2, markersize=8)
# Adding title and labels with larger fonts
plt.title(f'{y} trend', fontsize=16, fontweight='bold')
# Rotate x-axis labels plt.xticks(rotation=45, fontsize=10) plt.yticks(fontsize=10)
# Add gridlines with lighter color for aesthetics
plt.grid(True, which='major', linestyle='--', linewidth=0.5, color='gray')
# Add a subtle background color
plt.gca().set_facecolor('#F5F5F5')
# Add a small margin around the plot
plt.tight_layout()
self.chart_path = f'{symbol}_{y}_chart.png'
plt.savefig(self.chart_path, bbox_inches='tight') # 'bbox_inches="tight"'
def show_plot(self):
plt.show()
is_items = ['revenue','netIncome','eps']
income_statement_charts = []
for i in is_items:
viz_object = VizFin()
viz_object.viz_fin_data(annual_income_statement_data,'date',i,symbol=symbol)
path = viz_object.chart_path
income_statement_charts.append(path)
km_items = ['peRatio','pbRatio','debtToAssets','currentRatio','interestCoverage']
km_charts = []
for km in km_items:
viz_object = VizFin()
viz_object.viz_fin_data(annual_key_metric_data,'date',km,symbol=symbol)
path = viz_object.chart_path
km_charts.append(path)2.3 创建文档
最后,我们可以开始构建文档了。首先,我们将创建一个 Document() 对象。docx 库非常直观。我们将主要使用 add_heading() 和 add_paragraph() 方法来添加以下部分。在 add_heading() 方法中,我们可以指定标题的级别,这样标题就可以按大小分层。我们还将使用 add_picture() 方法添加图表。
# Create a new Word Document
doc = Document()
# Add a title
doc.add_heading(f'Financial Analysis of {name}', 0)
# Company Profile
doc.add_heading('Company Profile', level=1)
doc.add_paragraph(description)
# Add a line item for Market Cap with bold
p = doc.add_paragraph()
run = p.add_run("Market Cap: ")
run.bold = True # Make "Market Cap:" bold
p.add_run(market_cap) # Add the value without bold
# Add a line item for Sector with bold
p = doc.add_paragraph()
run = p.add_run("Sector: ")
run.bold = True # Make "Sector:" bold
p.add_run(sector) # Add the value
# Add a line item for Industry with bold
p = doc.add_paragraph()
run = p.add_run("Industry: ")
run.bold = True # Make "Industry:" bold
p.add_run(industry) # Add the value
# Add a line item for the SEC Filings
p = doc.add_paragraph()
run = p.add_run("Link to Filings: ")
run.bold = True
p.add_run(link_to_filings)
# Trends
doc.add_heading('Trends', level=1)
## Income Statement
doc.add_heading('Income Statement', level=2)
for chart_path in income_statement_charts:
doc.add_picture(chart_path, width=Inches(6))
## Key Metrics
doc.add_heading('Key Metrics', level=2)
for chart_path in km_charts:
doc.add_picture(chart_path, width=Inches(6))
# Save the document
doc.save('financial_profile_report.docx')三、阅读报告
接下来,我们将进入项目中最激动人心的环节。让我们一起来看看自动生成的报告如何揭示特斯拉的最新动态。虽然这份报告相对简单,但我的初衷是展示如何利用基础的Python技能来轻松定制报告。同时,不妨思考一下这个项目的扩展潜力。只需短短几秒钟,你就能轻松切换到另一只股票,并生成一份详尽的综合分析报告,甚至将其整理成文档。
让我们来看看文件的第一部分。这部分提供了公司概况,包括公司性质、市值规模、行业/部门,最后是最新年度报表的链接。具体到特斯拉,我们可以了解到其两大主要业务包括电动汽车和能源发电。

下一节介绍收入趋势,包括总体收入、净利润和每股收益。请注意,我将文件编辑成了 "书 "的版式。这三个简单而有效的收入指标可以显示公司销售额的增长情况、盈利能力的保持情况以及为股东带来的收益是多是少。简单看一下就会发现,这三个指标都显示销售额在持续增长的同时保持了利润率,并增加了回报给股东的价值。
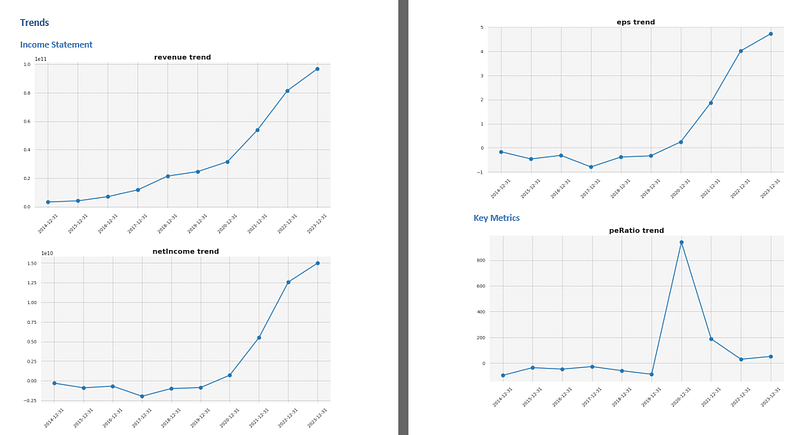
最后一部分展示了我在文章前面提到的一些关键指标。如前所述,这些指标显示了公司目前的估值情况以及公司债务的管理情况。总体而言,这种观点表明,在过去几年中,特斯拉的盈利和账面价值要高得多,现在似乎已经恢复到 "正常 "水平。从债务角度看,特斯拉似乎越来越善于管理债务。债务占资产的比例一直在下降,特斯拉履行短期债务的能力在过去几年里也变得更加高效。
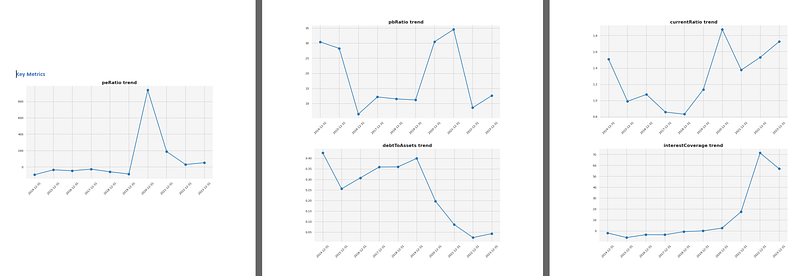
如果您需要将报告转化成中文或者其他语言的版本,可以调用网上各种翻译API或者LLM来实现,我就不在本文中赘述了。
四、观点总结
我希望这篇文章能启发您思考自己的研究和分析方法,以及如何将它们整合并调整为一个单一的来源,就像我在这个项目中完成的那样。这份报告的分析内容极少,但仍然揭示了大量有价值的见解。这为我们提供了多种可能性。我鼓励读者利用这个项目并加以扩展,以满足您的研究和分析需求!
- 自动化对于提高独立投资者的效率至关重要:自动化可以减少手动研究个股所需的时间,并允许投资者根据自己的需求定制报告。
- Python和FMP API是构建自动化股票分析报告的有力工具:通过编写Python代码和使用FMP提供的API,可以轻松获取股票数据并进行分析。
- 数据可视化对于理解和展示股票趋势至关重要:文中的
VizFin()类用于生成图表,帮助用户直观地理解公司的财务表现和关键指标的变化。 - 报告的构建应该是模块化和可扩展的:通过编写可重用的代码和函数,可以轻松地为不同的股票生成报告,并根据需要添加新的分析维度。
- 根据自己的需求来扩展和定制报告:我提供的是一个基础框架,鼓励您在此基础上进行创新和扩展,以满足自己的股票研究和分析需求。
谢您阅读到最后,希望本文能给您带来新的收获。祝您投资顺利!如果对文中的内容有任何疑问,请给我留言,必复。
本文内容仅限技术探讨和学习,不构成任何投资建议。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











