






一、Grafana+onealert报警
Prometheus 报警需要使用 alertmanager 这个组件,而且报警规则需要手动编写(对运维来说不友好)。所以我这里选用 grafana+onealert 报警。注意:实现报警前把所有机器时间同步再检查一遍
登陆http://www.onealert.com/→注册帐户→登入后台管理


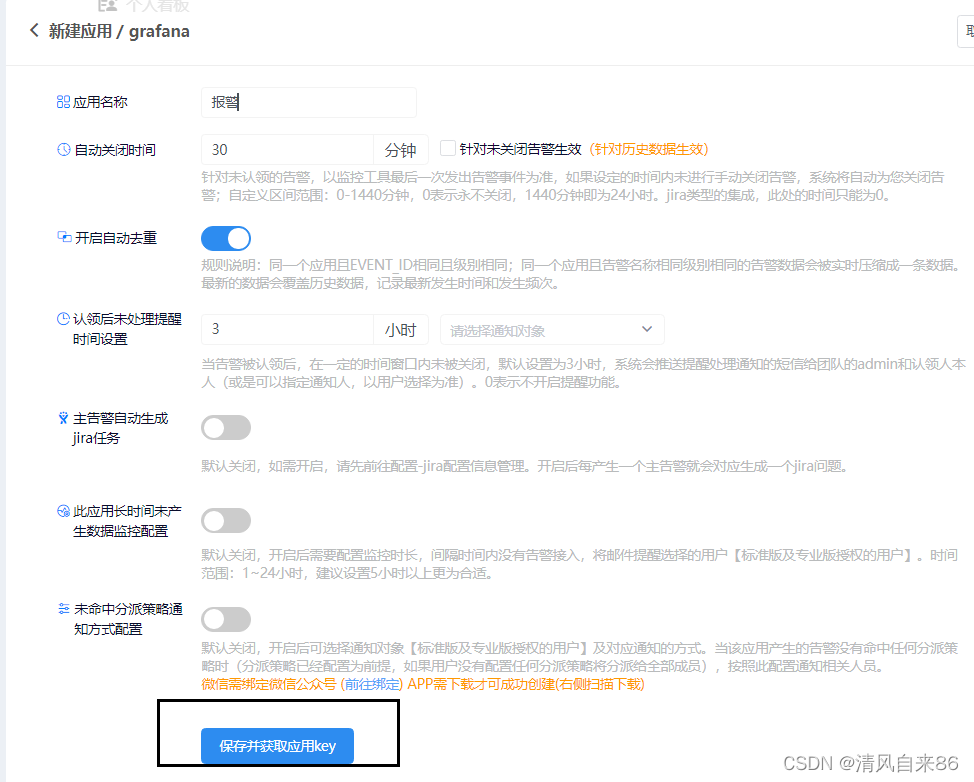
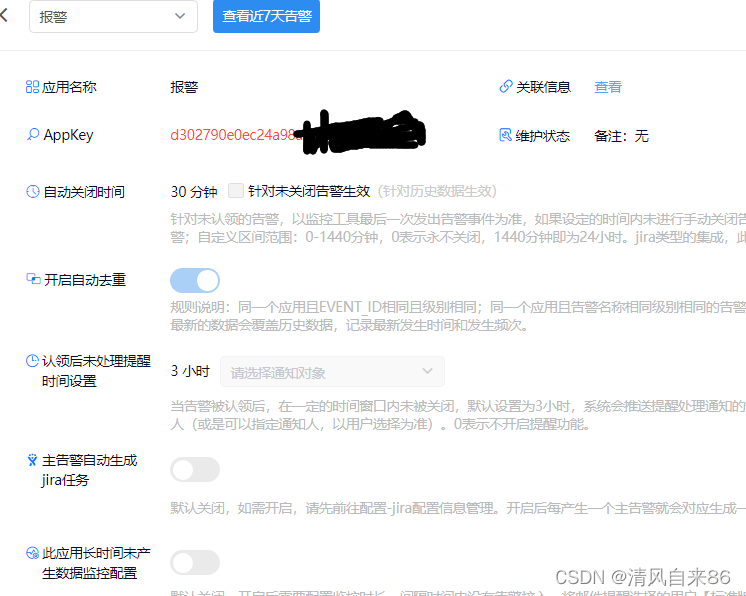
1、在Grafana中配置Webhook URL
① 在Grafana中创建Notification channel,选择类型为Webhook;
② 推荐选中Send on all alerts和Include image,Cloud Alert体验更佳;
③ 将第一步中生成的Webhook URL填入Webhook settings Url;
URL格式:
http://api.aiops.com/alert/api/event/grafana/v1/3ebae767310c43cdaa3cd680013d0f19/ (保存当前应用,即可获取完整webhook地址信息)④ Http Method选择POST;
⑤ Send Test&Save;
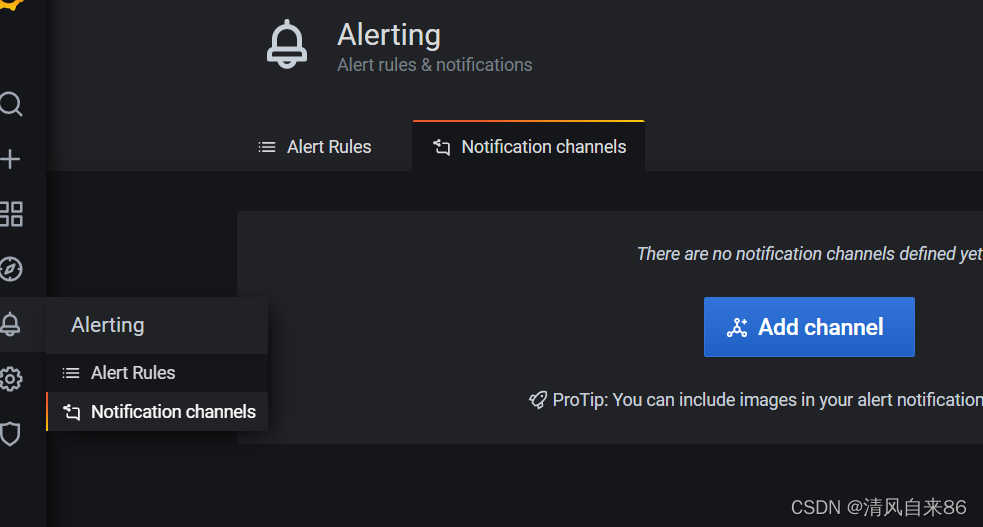
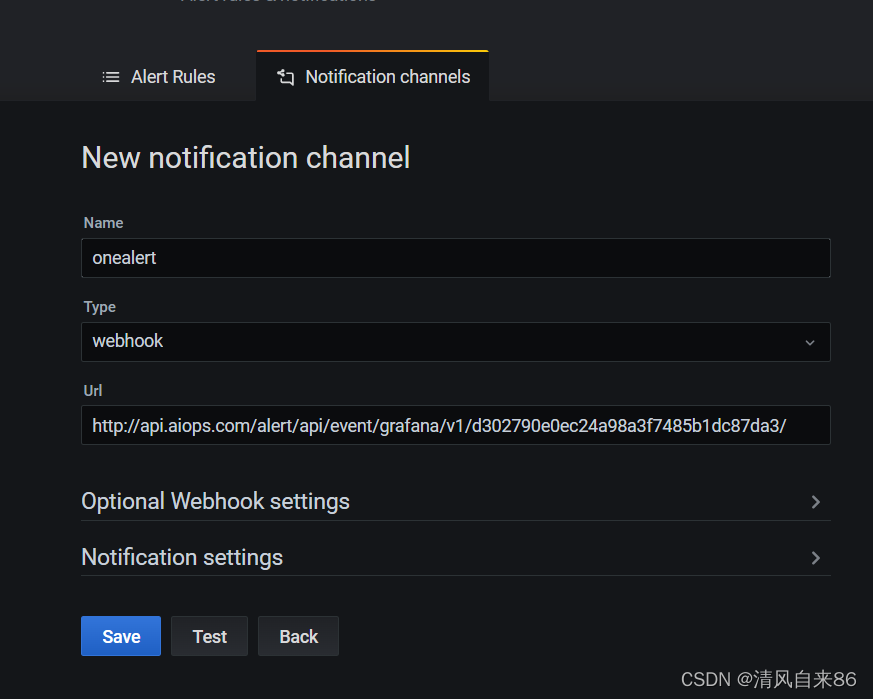
创建成功
2、测试cpu负载告警
现在可以去设置一个报警来测试了(这里以我们前面加的 cpu 负载监控来做测试)
#查看cpu占用率
(1- ((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance)) / (sum(increase(node_cpu_seconds_total[1m])) by(instance))))*100




测试报警
在被监控端下载一个stress测试工具
yum install -y epel*
yum install -y stress开始测试
















 1392
1392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









