






目录
11、Thread类中的start()和run()方法有什么区别
14、StringBuffer StringBuilder String区别
Java基础篇
1、Java集合
Set:无序、不可重复的集合
List:有序、可重复的集合(类似数组、但长度可变)
Queue:代表用队列来实现集合
Map:具有映射关系的集合(键值对中的key不能重复)
2、Hashtable和HashMap的区别
HashMap不是线程安全的,HashTable是线程安全
HashMap允许空(null)的键和值(key),HashTable则不允许
HashMap性能优于Hashtable
3、Java基本数据类型
byte(字节) 1(8位)
shot(短整型) 2(16位)
int(整型) 4(32位)
long(长整型) 8(32位)
float(浮点型) 4(32位)
double(双精度) 8(64位)
char(字符型) 2(16位)
boolean(布尔型) 1位
4、线程和进程的区别
- 本质区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位。
- 包含关系:一个进程至少有一个线程,线程是进程的一部分。
- 资源开销:每个进程都有独立的地址空间,进程之间的切换会有较大的开销;线程可以看做轻量级的进程,同一个进程内的线程共享进程的地址空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
- 影响关系:一个进程崩溃后,在保护模式下其他进程不会被影响,但是一个线程崩溃可能导致整个进程被操作系统杀掉,所以多进程要比多线程健壮。
5、常用设计模式
- 单例模式:在有些系统中,为了节省内存资源、保证数据内容的一致性,对某些类要求只能创建一个实例,这就是所谓的单例模式。
- 工厂模式:定义一个创建产品对象的工厂接口,将产品对象的实际创建工作推迟到工厂类当中。满足创建型模式中所要求的“创建与使用相分离”特点。
- 简单工厂:我们把创建的对象称为“产品”,把创建产品的对象为“工厂”。如果要创建的产品不多,只要一个工厂类就可以完成,这种模式叫“简单工厂模式”。
- 代理模式:在有些情况下,一个客户不能或者不想直接访问另一个对象,这时需要找一个中介帮忙完成某项任务,这个中介就是代理对象。
6、类加载器
顾名思义,类加载器(class loader)用来加载 Java 类到 Java 虚拟机中。一般来说,Java 虚拟机使用 Java 类的方式如下:Java 源程序(.java 文件)在经过 Java 编译器编译之后就被转换成 Java 字节代码(.class 文件)。
类加载器负责读取 Java 字节代码,并转换成 java.lang.Class类的一个实例。每个这样的实例用来表示一个 Java 类。通过此实例的 newInstance()方法就可以创建出该类的一个对象。实际的情况可能更加复杂,比如 Java 字节代码可能是通过工具动态生成的,也可能是通过网络下载的。
7、静态变量和实例变量的区别
静态变量存储在方法区,属于类所有.实例变量存储在堆当中,其引用存在当前线程栈
java创建对象的几种方式
采用new
通过反射
采用clone
通过序列化机制
前2者都需要显式地调用构造方法. 造成耦合性最高的恰好是第一种,因此你发现无论什么框架,只要涉及到解耦必先减少new的使用
8、Java四种引用
强引用,软引用,弱引用,虚引用.不同的引用类型主要体现在GC上:
强引用:如果一个对象具有强引用,它就不会被垃圾回收器回收。即使当前内存空间不足,JVM也不会回收它,而是抛出 OutOfMemoryError 错误,使程序异常终止。如果想中断强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样一来的话,JVM在合适的时间就会回收该对象
软引用:在使用软引用时,如果内存的空间足够,软引用就能继续被使用,而不会被垃圾回收器回收,只有在内存不足时,软引用才会被垃圾回收器回收。
弱引用:具有弱引用的对象拥有的生命周期更短暂。因为当 JVM 进行垃圾回收,一旦发现弱引用对象,无论当前内存空间是否充足,都会将弱引用回收。不过由于垃圾回收器是一个优先级较低的线程,所以并不一定能迅速发现弱引用对象
虚引用:顾名思义,就是形同虚设,如果一个对象仅持有虚引用,那么它相当于没有引用,在任何时候都可能被垃圾回收器回收。
9、深拷贝和浅拷贝的区别
浅拷贝:被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。换言之,浅拷贝仅仅复制所考虑的对象,而不复制它所引用的对象。
深拷贝:被复制对象的所有变量都含有与原来的对象相同的值,而那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。换言之,深拷贝把要复制的对象所引用的对象都复制了一遍。
10、static的用法
两个基本的用法:静态变量和静态方法.也就是被static所修饰的变量/方法都属于类的静态资源,类实例所共享.
除了静态变量和静态方法之外,static也用于静态块,多用于初始化操作:
此外static也多用于修饰内部类,此时称之为静态内部类.
最后一种用法就是静态导包,即import static.import static是在JDK 1.5之后引入的新特性,可以用来指定导入某个类中的静态资源,并且不需要使用类名.资源名,可以直接使用资源名
11、Thread类中的start()和run()方法有什么区别
start()方法被用来启动新创建的线程,而且start()内部调用了run()方法,这和直接调用run()方法的效果不一样。当你调用run()方法的时候,只会是在原来的线程中调用,没有新的线程启动,start()方法才会启动新线程。
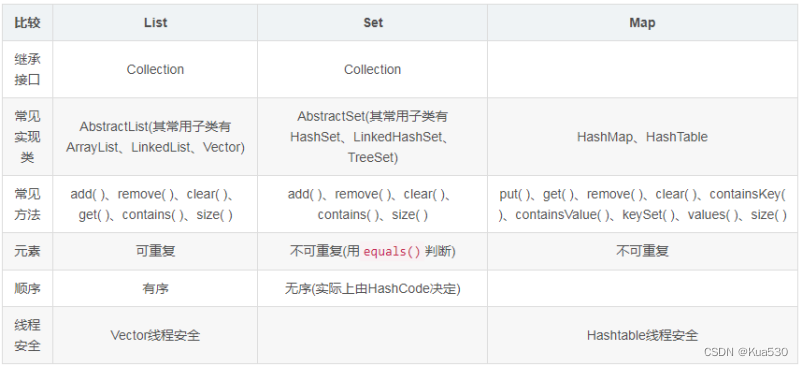
12、List、Set、Map区别
1.List(列表):List的元素以线性方式存储,可以存放重复对象。List主要有以下两个实现类:ArrayList : 长度可变的数组,可以对元素进行随机的访问,向ArrayList中插入与删除元素的速度慢。 LinkedList: 采用链表数据结构,插入和删除速度快,但访问速度慢。
2.Set(集合):Set中的对象不按特定(HashCode)的方式排序,并且没有重复对象。Set主要有以下两个实现类:HashSet按照哈希算法来存取集合中的对象,存取速度比较快。TreeSet实现了SortedSet接口,能够对集合中的对象进行排序。
3.Map(映射):Map是一种把键对象和值对象映射的集合,它的每一个元素都包含一个键对象和值对象。 Map主要有以下两个实现类:HashMap基于散列表实现,其插入和查询<K,V>的开销是固定的,可以通过构造器设置容量和负载因子来调整容器的性能。LinkedHashMap:类似于HashMap,但是迭代遍历它时,取得<K,V>的顺序是其插入次序,或者是最近最少使用(LRU)的次序。TreeMap:TreeMap基于红黑树实现。查看<K,V>时,它们会被排序。TreeMap是唯一的带有subMap()方法的Map,subMap()可以返回一个子树。
13、HashMap原理
底层实现:HashMap底层整体结构是一个数组,数组中的每个元素又是一个链表。每次添加一个对象(put)时会产生一个链表对象(Object类型),Map中的每个Entry就是数组中的一个元素(Map.Entry就是一个<Key,Value>),它具有由当前元素指向下一个元素的引用,这就构成了链表。
存储原理:当向HsahMap中添加元素的时候,先根据HashCode重新计算Key的Hash值,得到数组下标,如果数组该位置已经存在其他元素,那么这个位置的元素将会以链表的形式存放,新加入的放在链头,最先加入的放在链尾,如果数组该位置元素不存在,那么就直接将该元素放到此数组中的该位置。
去重原理:不同的Key算到数组下标相同的几率很小,新建一个<K,V>放入到HashMap的时候,首先会计算Key的数组下标,如果数组该位置已经存在其他元素,则比较两个Key,若相同则覆盖写入,若不同则形成链表。
读取原理:从HashMap中读取(get)元素时,首先计算Key的HashCode,找到数组下标,然后在对应位置的链表中找到需要的元素。
扩容机制:当HashMap中的元素个数超过数组大小*loadFactor(默认值为0.75)时,就会进行2倍扩容(oldThr << 1)。
14、StringBuffer StringBuilder String区别
String 字符串常量 不可变 使用字符串拼接时是不同的2个空间
StringBuffer 字符串变量 可变 线程安全 字符串拼接直接在字符串后追加
StringBuilder 字符串变量 可变 非线程安全 字符串拼接直接在字符串后追加
Java高级篇
1、JVM的特性
JVM工作原理和特点主要是指操作系统装入JVM是通过jdk中Java.exe来完成,通过下面4步来完成JVM环境.
创建JVM装载环境和配置
装载JVM.dll
初始化JVM.dll并挂界到JNIENV(JNI调用接口)实例
调用JNIEnv实例装载并处理class类。
2、JVM内存分配
方法区(线程共享):各个线程共享的一个区域,用于存储虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然 Java 虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却又一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
运行时常量池:是方法区的一部分,用于存放编译器生成的各种字面量和符号引用。
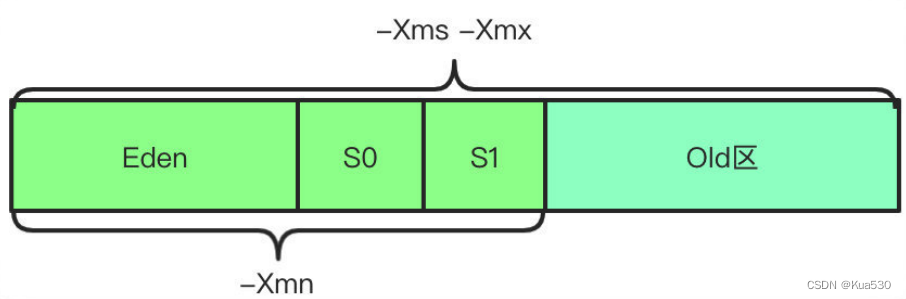
堆内存(线程共享):所有线程共享的一块区域,垃圾收集器管理的主要区域。目前主要的垃圾回收算法都是分代收集算法,所以 Java 堆中还可以细分为:新生代和老年代;再细致一点的有 Eden 空间、From Survivor 空间、To Survivor 空间等,默认情况下新生代按照8:1:1的比例来分配。根据 Java 虚拟机规范的规定,Java 堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘一样。
程序计数器: Java 线程私有,类似于操作系统里的 PC 计数器,它可以看做是当前线程所执行的字节码的行号指示器。如果线程正在执行的是一个 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是 Native 方法,这个计数器值则为空(Undefined)。此内存区域是唯一一个在 Java 虚拟机规范中没有规定任何 OutOfMemoryError 情况的区域。
虚拟机栈(栈内存):Java线程私有,虚拟机展描述的是Java方法执行的内存模型:每个方法在执行的时候,都会创建一个栈帧用于存储局部变量、操作数、动态链接、方法出口等信息;每个方法调用都意味着一个栈帧在虚拟机栈中入栈到出栈的过程;
本地方法栈 :和Java虚拟机栈的作用类似,区别是该区域为 JVM 提供使用 native 方法的服务
3、Java的内存模型
Java 虚拟机规范中试图定义一种 Java 内存模型(Java Memory Model, JMM)来屏蔽掉各层硬件和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。
Java 内存模型规定了所有的变量都存储在主内存(Main Memory)中。每条线程还有自己的工作内存(Working Memory),线程的工作内存中保存了被该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在主内存中进行,而不能直接读写主内存中的变量。不同的线程之间也无法直接访问对方工作内存中的变量,线程间的变量值的传递均需要通过主内存来完成,线程、主内存、工作内存三者的关系
4、Java堆栈的区别
JVM 中堆和栈属于不同的内存区域,使用目的也不同。栈常用于保存方法帧和局部变量,而对象总是在堆上分配。栈通常都比堆小,也不会在多个线程之间共享,而堆被整个 JVM 的所有线程共享。
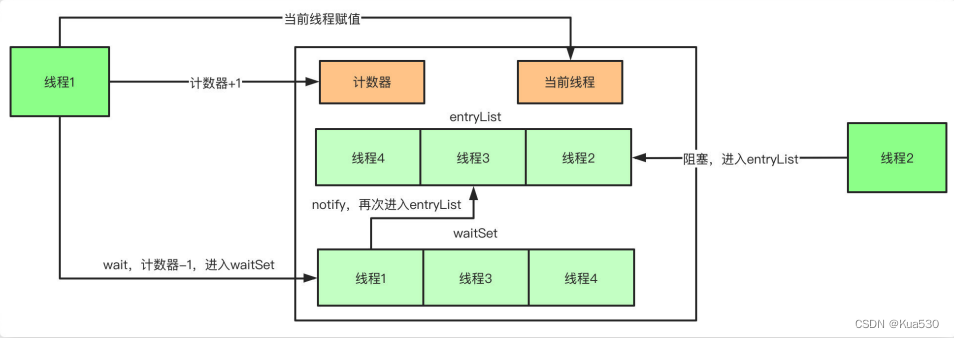
5、synchronized原理
6、线程池原理
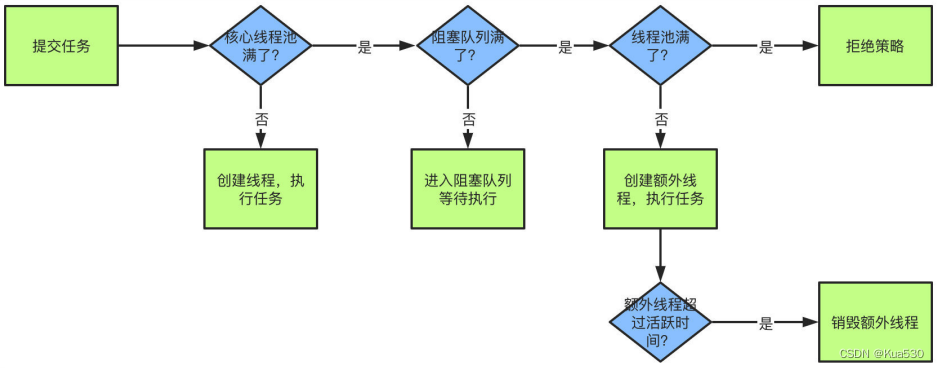
7、拒绝策略
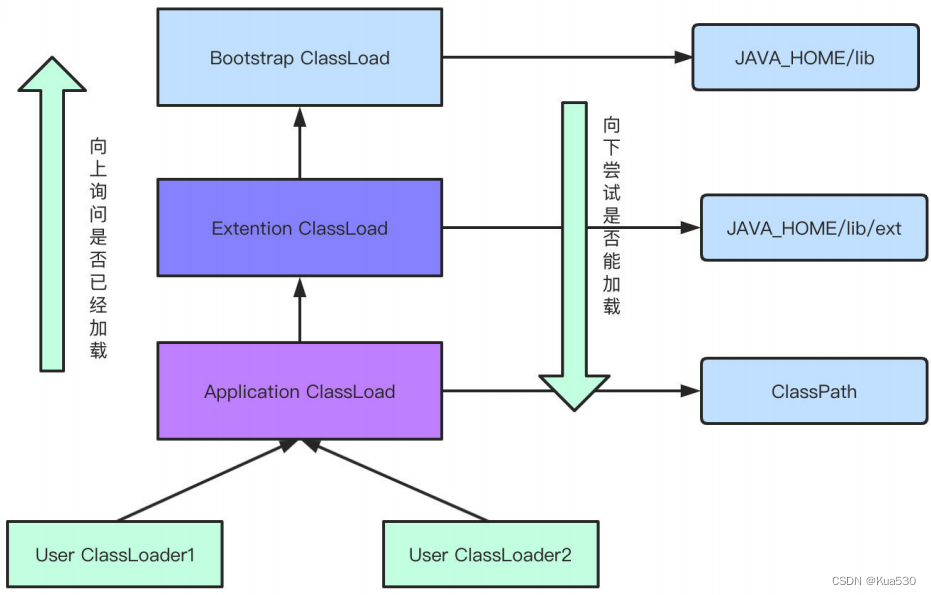
8、双亲委派模型
9、有哪些垃圾回收算法
10、垃圾回收器
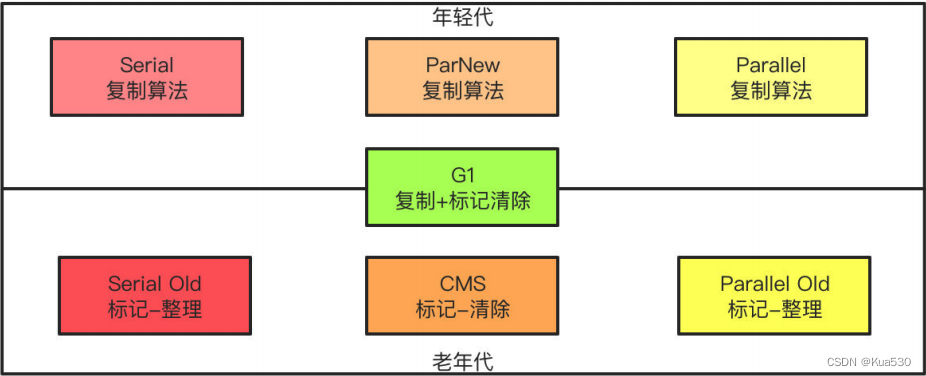
11、JVM调优
Java框架篇
1、spring中用到的设计模式
2、IOC和AOP
IOC 叫做控制反转,指的是通过Spring来管理对象的创建、配置和⽣命周期,这样相当于把控制权交给了Spring,不需要⼈⼯来管理对象之间复杂的依赖关系,这样做的好处就是解耦。在Spring⾥⾯,主要提供了 BeanFactory 和 ApplicationContext 两种 IOC 容器,通过他们来实现对 Bean 的管理。
3、SpringAOP和AspectjAOP区别
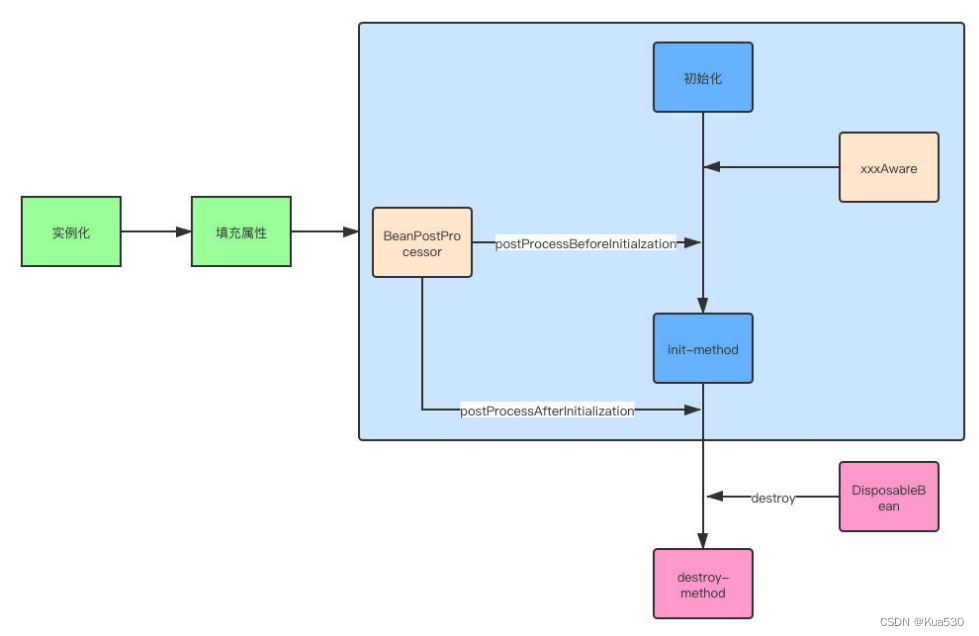
4、SpringBean的生命周期
5、Spring怎么解决循环依赖的
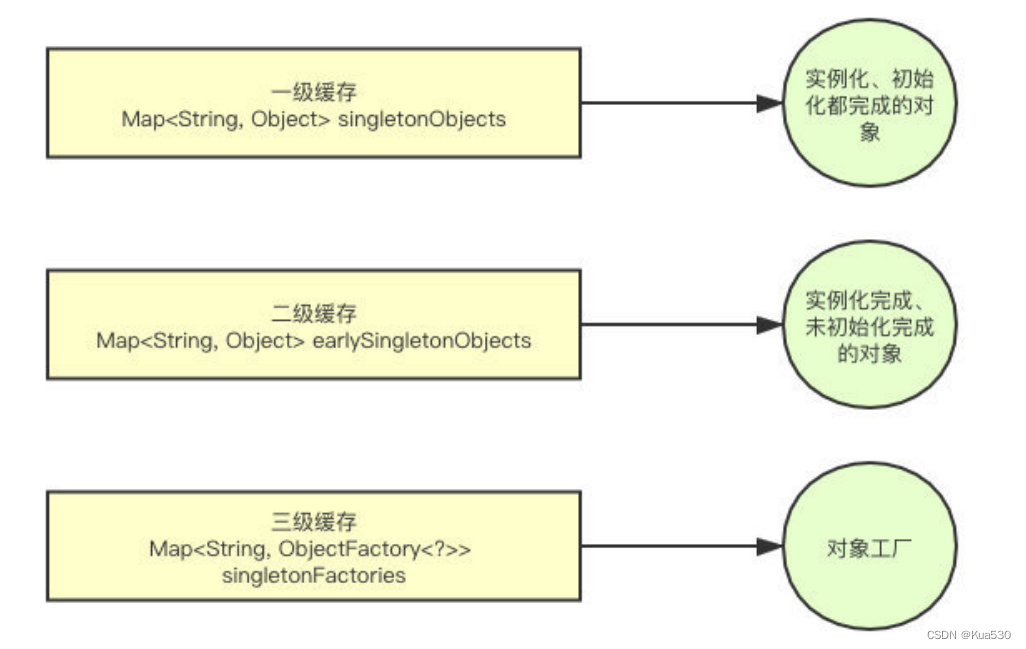




为什么要三级缓存?二级不行吗

6、Spring事务传播机制
7、SpringMVC请求流程
1、用户发送请求至前端控制器DispatcherServlet。
2、DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3、处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet。
4、DispatcherServlet调用HandlerAdapter处理器适配器。
5、HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
6、Controller执行完成返回ModelAndView。
7、HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
8、DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9、ViewReslover解析后返回具体View。
10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
12、DispatcherServlet响应用户。
8、Spring的事务
1、什么是spring事务?
spring事务是指一组SQL语句的集合,集合中有多条SQL语句,可以是insert、update、select、delete,希望这些SQL语句执行是一致的,作为一个整体执行。要么都成功,要么都失败。
2、事务的特点(ACID)
1)原子性(Atomicity):事务是一个原子操作,由一系列动作组成。事务的原子性确保动作要么全部完成,要么完全不起作用。
2)一致性(Consistency):一旦事务完成(不管成功还是失败),系统必须确保它所建模的业务处于一致的状态,而不会是部分完成部分失败。在现实中的数据不应该被破坏。
3)隔离性(Isolation):可能有许多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏。
4)持久性(Durability):一旦事务完成,无论发生什么系统错误,它的结果都不应该受到影响,这样就能从任何系统崩溃中恢复过来。通常情况下,事务的结果被写到持久化存储器中。
2、什么时候想到使用事务?
1)当操作设计多个表,或者是多个SQL语句的insert、update、delete。需要保证这些语句都是成功才能完成功能,或者都失败是符合要求的。(要么都成功,要么都失败)
2)事务在java开发中如何运用?事务放在service类的业务方法中,因为业务方法会调用多个dao,执行多条SQL语句。
4、处理spring事务:管理事务的是事务管理器和其实现类。spring的事务是一个统一的模型。
1)指定要使用的事务管理器实现类,使用<bean>
2)指定哪些类,哪些方法需要加入事务的功能
3)指定方法需要的事务的隔离级别、传播行为、超时时间。
5、管理事务管理器有两个方法:
1)注解式事务管理:
spring框架用aop实现给业务方法增加事务的功能,使用 @Transactional 注解增加事务。@Transactional注解是spring自己的注解。放在 public 方法的上面,表示当前这个方法具有事务,可以给注解的属性赋值,来表示具体的隔离级别、传播行为、异常信息等等。
实现步骤:1、声明事务管理器对象。2、开启事务注解驱动,告诉spring,使用注解的方式管理事务。spring使用aop机制,创建@Transactional所在的类代理对象,给方法加入事务功能。3、在目标方法(需要增加事务功能的)方法上面加入@Transactional注解。
- 声明式事务管理:
大型项目中有很多类,方法,需要大量的配置事务,使用aspectj框架功能,在spring配置文件中声明类,方法需要的事务。这种方式业务方法和事务配置完全分离。
实现步骤:都是在xml配置文件中实现的。1、要使用的是aspectj框架,加入依赖。2、声明事务管理器对象。3、声明方法需要的事务类型(配置方法的事务属性:隔离级别、传播行为、超时)。4)配置AOP:指定哪些类需要创建代理对象。
9、mybatis #{} 和 ${} 的区别
1、${}是字符串替换,#{}是预处理。
2、Mybatis在处理${}时,就是把${}直接替换成变量的值。而Mybatis在处理#{}时,会对sql语句进行预处理,将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值。
3、使用#{}可以有效的防止SQL注入,提高系统安全性。
10、mybatis一二级缓存
1、一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
2、二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置。
3、对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear 掉并重新更新,如果开启了二级缓存,则只根据配置判断是否刷新。
11、mybatis动态sql
Mybatis动态sql可以在Xml映射文件内,以标签的形式编写动态sql。执行原理是根据表达式的值 完成逻辑判断 并动态拼接sql的功能。
Mybatis提供了9种动态sql标签:trim、where、set、foreach、if、choose、when、otherwise、bind。
12、springboot自动配置
启动类@SpringBootApplication注解由@SpringBootConfiguration,@EnableAutoConfiguration,@ComponentScan三个注解组成,三个注解共同完成自动装配:
- @SpringBootConfiguration 注解标记启动类为配置类。
- @ComponentScan 注解实现启动时扫描启动类所在的包以及子包下所有标记为bean的类由IOC容器注册为bean。
- @EnableAutoConfiguration通过 @Import 注解导入 AutoConfigurationImportSelector类,然后通过AutoConfigurationImportSelector 类的 selectImports 方法去读取需要被自动装配的组件依赖下的spring.factories文件配置的组件的类全名,并按照一定的规则过滤掉不符合要求的组件的类全名,将剩余读取到的各个组件的类全名集合返回给IOC容器并将这些组件注册为bean。
13、springcloud核心组件
- Spring Cloud Eureka:服务注册与发现
- Spring Cloud Zuul:服务网关
- Spring Cloud Ribbon:客户端负载均衡
- Spring Cloud Feign:声明性的Web服务客户端
- Spring Cloud Hystrix:断路器
- Spring Cloud Config:分布式统一配置管理















 2135
2135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









