







R语言入门学习笔记(二)
前言
我们已经学习了R语言的基础操作界面以及主要R元素(函数、R包等)。接下来,我们将具体学习R对象(向量、矩阵、数组、列表、数据框)的相关知识。了解R对象将有利于系统了解R语言处理以及存储数据的形式。其中,还会介绍属性与强制转换的概念,这对于更深入了解所有R对象的特征有所帮助。
一、R向量
1.原子型向量
原子型向量是最简单的包含数据的向量,在R中表示为几个单独数据的组合。比如,c(1, 2, 3)就表示了一个原子型向量,其中的元素为数字1,2,3。R中,可以将一组数据使用c函数组合起来从而形成一个原子型向量。
注意:可以使用is.vector()检验对象是否为原子型向量,可以使用length()检测向量的长度。
2.向量类型
R中,可以使用6种类型的原子型向量:数值型(双整型,double)、整型(integer)、字符型(character)、逻辑型(logical)、复数类型(complex)、原始类型(raw)。可以使用typeof()查看向量类型。
(1)数值型也叫双整型,是数字的默认类型。可以包含正负数,也可以包含小数。
(2)整型,只包含整数。想要获得一个整型的数字,可以在一个整数后面键入“L”来实现。
注意:双整型会有浮点误差的存在,这是由于双整型对象有64字节的存储空间,在遇到一些数字时可能不能存储完全,就会进行取舍从而造成误差。比如
(
2
)
2
−
2
(\sqrt{2} )^2-2
(2)2−2计算结果就是4.4108…
(3)字符型指的是纯文本,通过在字符外加双引号来获得。比如,text <- "hello"。
(4)逻辑型只有两个,分别是TURE和FALSE在R中默认T和F为连着和的缩写。
(5)复数类型,将数字与字母i相加得到,指的是数学概念上的复数。
(6)原始类型是存储数据的原始字节,可以使用raw(n)生成一个长度为n的空原始类型向量。
3.属性
属性是附加给原子型向量的额外信息,可以理解为对象的元数据(metadata)。通常R会忽略这些属性信息。
可以使用attributes()查看对象的属性信息。但如果不人为为原子型向量添加属性,会返回NULL。原子型向量常见的属性信息为名称、维度和类(后面要介绍的R对象的其他类型也是如此)。名称属性可以使用names()直接查看,可以使用names()为原子型向量附上名称属性。
a <- c(1, 2, 3)
names(a)
#> NULL
names(a) <- c("one", "two", "three")
names(a)
#> "one" "two" "three"
attributes(a)
#> $names
#> [1] "one" "two" "three"
维度属性可以将原子型向量转换为一个多维数组(array)。方法是将原子型向量附上dim属性,例如可以将a向量重排位一个1×3的矩阵(一行三列)。
dim(a) <- c(1, 3)
a
#> [,1] [,2] [,3]
#> [1,] 1 2 3
另外想要删除这些属性,只需要将相应属性附上NULL即可。
类属性将在后面第五节进行说明。
二、R矩阵
矩阵就是一个用来存储数据的二维数组,这与线性代数中的矩阵概念没什么区别。想要生成一个矩阵,要将一个原子型向量交给matrix()函数。其中,使用nrow参数定义该矩阵的行数,或使用ncol参数定义矩阵的列数。
b <- c(1, 2, 3, 4, 5, 6)
m <- matrix(b, nrow = 2)
#> [,1] [,2] [,2]
#> [1,] 1 3 5
#> [2,] 2 4 6
注意matrix的默认排序方式是先排满列在排行。如果想要更改为按行优先排列,可以设置参数byrow = TRUE即可。
三、数组
array函数用于生成一个n维数组。比如可以利用array将数值排列到一个三维立方空间中。它没有matrix函数那么灵活,和dim属性设置的效果类似。array()的第一个参数是一个原子型向量,第二个参数名称为dim。
ar <- c(1:4, 5:8, 9:12)
array(ar, dim = c(2, 2, 3))
#> , , 1
#>
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
#>
#> , , 3
#>
#> [,1] [,2]
#> [1,] 9 11
#> [2,] 10 12
四、列表
列表是将数据组织在一个一维集合中,但它与原子型向量不同的是,它组织的不是具体的值,而是R对象。可以使用list()函数创建列表。
lst <- list(1:20, "R语言真好玩", list(TRUE, FALSE))
lst
#> [[1]]
#> [1] 1 2 3 4 5 6 7 8 9 10 #> 11 12 13 14 15 16 17 18 19 20
#>
#> [[2]]
#> [1] "R语言真好玩"
#>
#> [[3]]
#> [[3]][[1]]
#> [1] TRUE
#>
#> [[3]][[2]]
#> [1] FALSE
结果中的[[1]]表示的是列表中的第一个元素,[1]表示的是某个元素的第1行内容。
可以使用str函数查看列表中的对象
五、数据框
数据框是列表的二维版本,它可以将向量组织在一个二维表格之中,这是数据分析时常用的一种R对象。数据框与矩阵相比,它可以在每一列保存一种类型的数据,列与列之间可以不同,但是每列需要是同一种数据类型的数据,且每列会有列名。
手动创建数据框可以使用data.frame()函数:
df <- data.frame(day = c("Mon", "Tue", "Wed"), event = c("Play", "Play", "Play"), times = c(5, 6, 7))
df
#> day event times
#> 1 Mon Play 5
#> 2 Tue Play 6
#> 3 Wed Play 7
数据框不能组合不等长的向量,需要确保每个向量的长度相等,或者R的循环规则下可以变成等长向量(在学习笔记(一)中提到的,较短向量进行重复至较长的向量长度,及长向量长度需要是短向量长度的整数倍)。
六、类(class)的概念
前面介绍了属性的概念,到这里介绍了更多的R对象,所有的R对象都有属性的特征,都可以看作是这类R对象的元数据。类属性作为属性的一种,具体的表明了对象的类别。改变对象的维度会改变其class属性。
dim(a) <- c(1, 3)
typeof(a)
#> "double"
class(a)
#> "matrix" "array"
在运行attributes()函数时,对象的class属性不一定总会显示,有时可能需要class()函数进行查询。一些原子型向量在查询类属性时如下:
class("感谢阅读,共同成长")
#> "character"
class(6)
#> "numeric"
可以看到,原子型向量的class属性与其类型存在一些偏差,例如双整型向量的类是“numeric”。
可以使用class函数设置对象的类属性。在R中,类属性相同的对象通常具有类似的特性。在后续的学习中也将慢慢地介绍如何构建和使用自己定义的类。
下面介绍另外两种原子型向量的类:日期与时间和因子型。
(1)日期和时间,R中会有一个特殊的类来表示日期和时间数据。
# 获得系统时间
now <- Sys.time()
now
#> [1] "2024-01-29 19:44:55 CST"
class(now)
#> [1] "POSIXct" "POSIXt"
typeof(now)
#> "double"
POSIXct是一个广泛应用于表示日期与时间的框架,在这个框架下,时间表示为自1970年1月1日零点(UTC)开始逝去的秒数。可以使用unclass()函数将class属性移除来显示这一具体秒数。
unclass(now)
#> [1] 1706528695
(2)因子,在R中用于存储分类信息。比如民族和发色等。可以将其视为性别类似的概念,即限定了取值范围。这些值之间可能有一些特殊的顺序规则。
可以使用factor()函数传递一个原子型向量生成一个因子。R会将向量中的值重编码为一串整数值,再将编码的结果存储在一个整型向量中。此外,R还会为其田间一个levels属性和class属性:
color <- factor(c("red", "green", "red", "green"))
typeof(color)
#> "integer"
attributes(color)
#> $levels
#> [1] "green" "red"
#>
#> $class
#> [1] "factor"
使用unclass函数查看R是如何存储因子的:
unclass(color)
#> [1] 2 1 2 1
#> attr(,"levels")
#> [1] "green" "red"
因此可知,R在显示因子信息时使用了levels属性。每个1显示为green,2显示为red。
因子的存在使得统计模型中加入分类变量变得简单,因为这些变量已经被编码为一些数值。但是,因子引起表现为整数值往往会使人比较困惑。
加载和生成数据时,R会经常尝试将字符串类型的数据转换为因子型。一般而言需要禁止这样做。可以使用as.character()函数将一个因子强制转换成字符串,这样R会将因子标签转换为字符串向量而舍弃其中的整数值信息。
七、强制转换
如果尝试将不同类型的数据塞进同一个向量,R会将它们转换为同一种类型。这牵扯到了R的强制转换,也是默认情况下R的一种对数据类型的转换方式。了解这套规则后,可以利用这个功能完成很多事情。
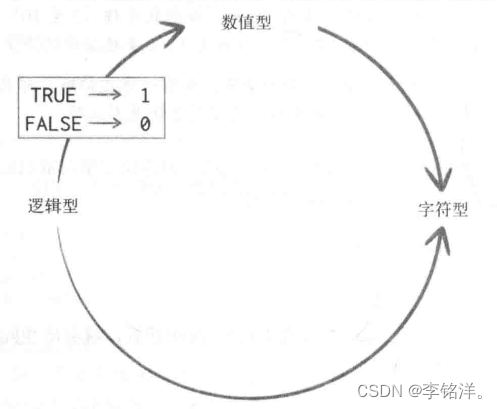
规则是,如果原子型向量包含字符串,R会将该向量中所有元素转换为字符型。如果只包含逻辑型和数值型,R会将逻辑型转换为数值型,其中TRUE值转换为1,FALSE值转换为0。(即转换优先级:字符型 > 数值型 > 逻辑型)引用书中的一幅图来强化一下记忆!
八、加载数据和保存数据
在数据分析过程中,我们往往将外部数据保存为R对象进行分析,然后将分析后的结果R对象保存为输出文件。大多数数据科学应用程序都可以直接打开纯文本文件,也可以将相关数据输出为纯文本文件。
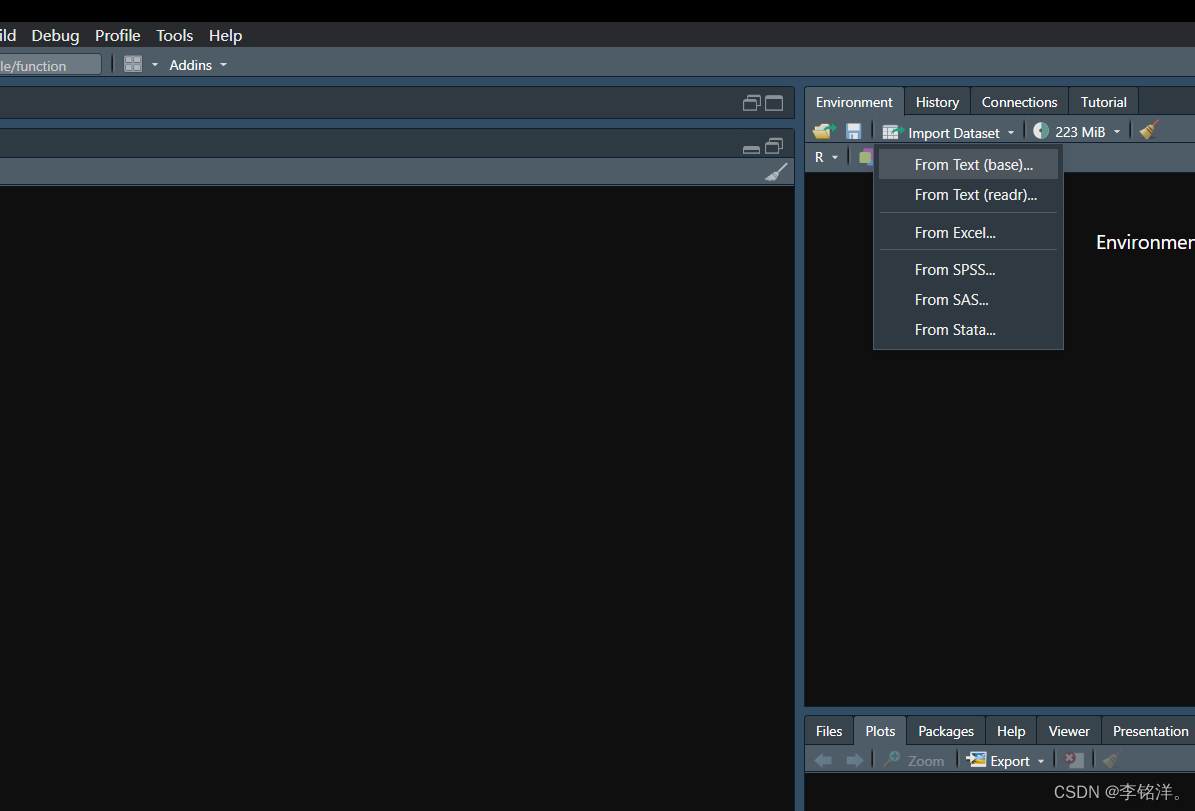
要在R中加载一个纯文本文件,可以在RStudio中单击Import Dataset,然后选择From text file即可。
另外,也可以直接使用read.table()或read.csv()对本地文件进行读取。可以自行使用?read.table调取帮助文档学习。
read.csv("data.csv", header = TRUE)
其中header = TRUE表示data.csv中包含列名。
保存数据时,可以使用write.csv()命令:
write.csv(data, file = "results.csv", row.names = FALSE)
其中row.names = FALSE用于避免R在存储数据时将行名一起存储(一列数字)。
总结
至此,我们了解了R语言中R对象的基本形式。掌握并牢记这些基本的R对象对后续的数据分析十分关键。另外还学到了R对象属性的概念,其中class类属性表示的是R对象的一种类型,这些属性的概念后续还会有重要的应用。在输入数据时,R会执行强制转换,这个强制转换的规则是R的内部规则,熟悉后后续会有不错的应用。















 5964
5964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









