







1、什么是schema?
schema是指数据库或者其他数据存储系统的结构定义,用于描述数据的组织方式,数据类型、
关系、约束等信息,是数据的元数据。在关系型数据库中,schema通常指数据库中的表、列、键以及它们之间的关系。schema还可以用于描述JSON、XML等非关系型数据库中的数据结构,schema的作用是提供数据的一致性和完整性,以及方便数据的查询和管理。可以简单理解为一个schema就是一个具体的数据库实例,不同的实例可以有不同的组成以及约束规则,比如数据库的字符编码方式、执行引擎等等。一个数据库服务器中可以包含多个schema,就像可以包含多个数据库实例一样。
例如:数据库中有很多数据,比如某一行某一列的数据是150,那这个150指的是height(身高)呢,还是weight(体重)呢?这里的height和weight就是描述数据的数据,也就是mysql中的属性名(或者说列名)。除此之外,数据库名、表名、列名以及其他的定义信息(如字符编码、主键标识)都可以称之为元数据。
information_schema库主要存储schema信息(上面所述相关的元数据)
我们可以查看一下schemata表、tables表、columns表(linux系统下查找语句)
mysql> use information_schema;(运用库)
Database changed
mysql> select * from schemata;(查表)
schemata表信息其实和 show databases的结果是一样的,schemata表中多了一些编码信息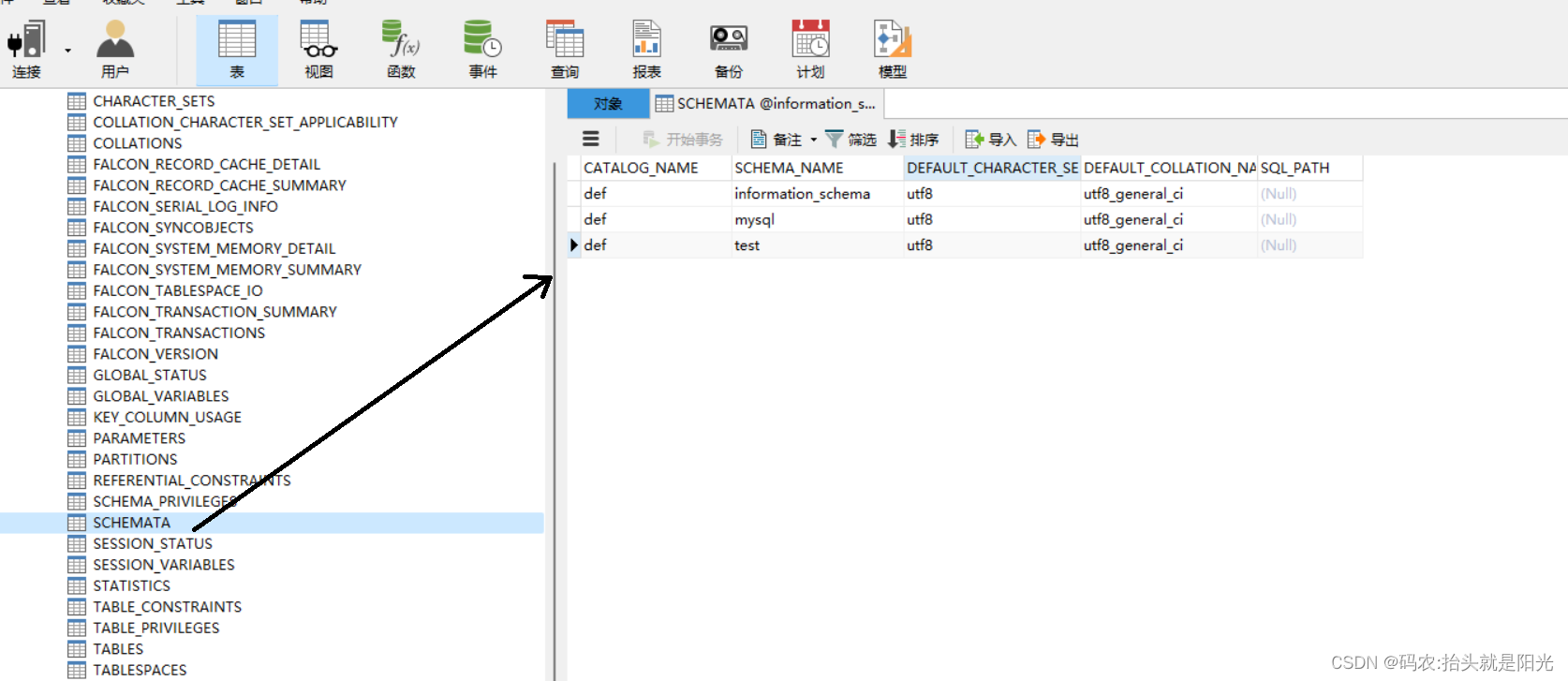
tables表用来描述表信息,字段较多!
mysql> select table_name, table_type, engine, create_time, table_comment from tables where table_schema = 'information_schema';(linux系统下的查询语句)

table_name 表名
table_schema 表所在的数据库名
table_type 两种取值:BASE TABLE 和 VIEW; 由此可见这个information_schema存的不仅仅是基础表,也有可能是视图。
engine 表所用的引擎
create_time 创建时间
table_comment 表备注
columns表描述每个列的信息
mysql> select table_schema, table_name, column_name, ordinal_position, is_nullable, data_type, column_key, extra, column_comment from columns where table_name = 'user';
例如:
table_schema 所属数据库
table_name 所属表的名字
column_name 列名
ordinal_position 在所属表里的顺序
is_nullable 是否可为null
data_type 数据类型
column_key 可能的取值有: 空(可重复的普通列)、PRI(表示该列是主键的组成部分)、UNI(唯一索引的第一列,或者说前导列)
extra 可能的取值有: 空 、auto_increment(自增)
column_comment 列备注
2、通过information_schema来做什么?
a、可以做可视化工具(navicat中的这些数据库名、表名、列名都是从这个库读取的)
b、可以做一些代码生成工具(读取information_schema库中的schema信息,做类型转换、字符串处理,再借助模板引擎,可逆向生成JavaBean、Controller、Service相关代码!)















 645
645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









