






- python基础部分
- python的面向对象
- python的高级特性
快速入门
python概述
Python发展过程中的三起三落:
① Guido van Rossum(吉多·范罗苏姆) 1989年圣诞节,自己在家胡思乱想——是不是可以研发一门使用容易、很少出错的编程语言,同时兼顾运行性能,于是:python诞生了(用于一个简单的游戏脚本)
② 1991年,Python1.0版本正式发布(测试版)
③ Python 2.0:2000 年 10 月 16 日,让Python正式成为了一门非常重要的编程语言
④ Python 2.7:2010 年 7 月 3 日,同年Python评为当时的全球年度语言,发布了性能最优秀的2.7版本
⑤ Python 3.0:2008 年 12 月 3 日
**⑥ Python 3.6:**2016 年 9 月 20 日
⑦ Python 3.12:2023 年
📝 关于Python的版本
- Python 1.x:过时,淘汰
- Python 2.x:2008~2018年,数据分析领域的主要版本,目前过时不再推荐使用
- Python 3.x:当前市场的主流版本
- Python 3.6以前的版本:过时
- Python 3.6:一些遗留的老项目中可能会遇到(注意:千万不要冒然升级)
- Python 3.8:当前开发中选择的主要版本(如果没有特殊要求,一般新项目直接使用3.8版本)
- Python 3.10:一些新的数据分析项目中,可能会指定要使用3.10的版本
- Python 3.12:目前最新的稳定版本,一般学习语言新特性时建议使用,工作中禁止使用
- Python 3.13:目前正在研发的版本,禁止使用!
Python语言的特性
Python语言:作为一门脚本语言发展起来的编程语言,包含了很多对入门新手非常友好的特性
- 简单易学:语法非常简单,非常容易理解
- 胶水语言:可以和其他很多语言混合开发,这也是Python能作为人工智能首选语言的非常重要的特性
- 应用广泛:脚本运维、WEB网站、数据采集(爬虫)、数据分析、人工智能…都有很重要的应用
- 社区丰富:Python是一个全民语言,包含非常丰富的第三方功能工具,可以直接使用
Python官方网站:https://www.python.org
- 官方文档(菜单):
Documentation,学习和了解官方文档,是入门的第一步- what’s new in python 3.12:每个新版本中的新语法特性介绍
- Tutorial:Python使用教程(重要:不要担心,有中文版文档)
- Library Reference:标准库使用说明
- Language Reference:纯语法教程
- Using Python:Python使用说明
- Download Current Documentation:下载当前文档资料
搭建python的环境
任何编程语言都需要对应的环境来支持编程的。
python也需要对应的编译环境和运行环境。
编译环境
大多数编程语言的编程环境都类似,只要是能够进行文本编辑的工具即可。
像window自动的记事本: 优点:无任何格式;缺点:太原生了
因此推荐使用一些专业(编程开发)记事本工具:UE、EditPlus、sublime、vscode(店家推荐)
vscode官方地址:https://code.visualstudio.com/
当然都存在专业的IDE前期不要使用,等开始学习高阶的知识时,我们使用pycharm。
(1) 什么是开发工具
开发工具,就是编写代码的软件
一般代码都是文本代码,所以只要能编辑文本的工具都可以用来编写代码,如记事本!
📝 关于开发工具的选择
有一些装X的人,会使用记事本开发代码,但是为什么在企业中很少看到真实环境中使用记事本开发代码呢?
- 记事本编写代码,所有字体都是黑白色,专业术语:没有代码高亮,降低开发效率
- 记事本无法管理多个文件,如果同时编写多个代码文件,需要打开多个记事本,编写混乱,减低开发效率
- 记事本功能简单,无法做到代码提示,导致开发速度变慢,专业术语:没有智能提示
- 记事本功能单一,无法做到和相关领域结合,导致环境搭建非常复杂,如做WEB开发的容器配置
🔖 开发工具的的选择:
- 临时修改代码:推荐使用超级记事本(启动速度快、占用资源少、代码高亮、智能提示…),如Nodepad++、Editplus等等
- 开发软件应用:推荐使用IDE高级工具,如Pycharm(推荐)
- 高级开发人员:根据需要定制自己的开发工具,如使用VSCode、Sublime、Atom等工具结合安装具体功能插件定制工具
(2) Pycharm的基本使用
① 主题选择:默认提供了暗黑、明亮主题,根据自己的需要调整
选择File(文件) -> Settings(设置)打开设置窗口
选择Appearance(外观)&Behavior(行为)-> Appearance(外观) ,右侧窗口Theme(主题)选择合适的主题
勾选Use custom font,可以调整工具菜单字体大小
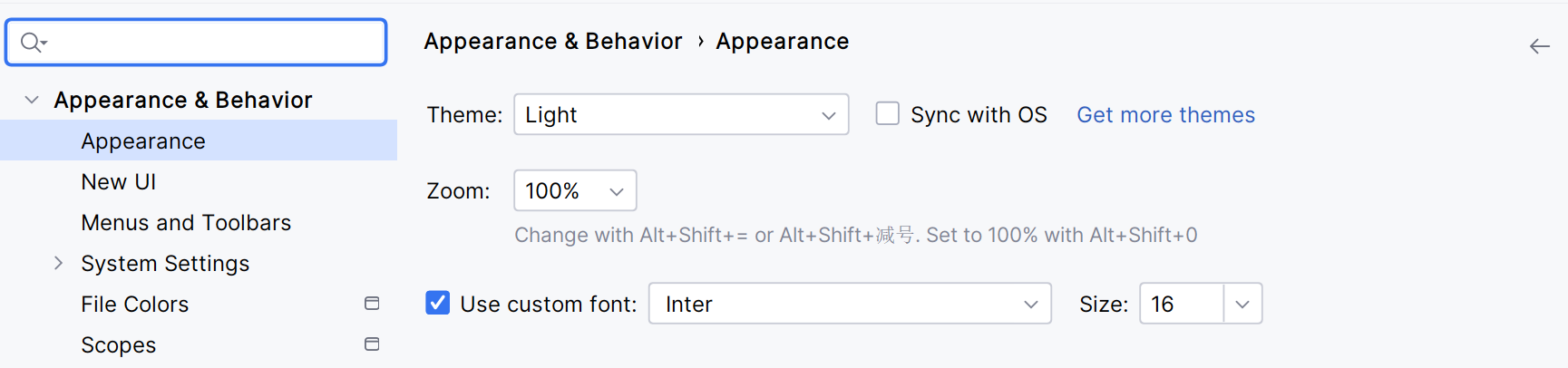
② 字体设置
选择Edit(编辑)菜单,调整两个位置的参数
选择General(常规),右侧窗口中勾选Change font size with Ctrl + Mouse Wheel(按住Ctrl通过鼠标滚动调整窗口代码字体大小),非常好用!
选择Font(字体),右侧窗口中调整三个参数数据:
font:字体,建议选择Source Code Pro,可以很友好的区分容易混淆的字体size:字号,建议选择16/18号字体line height:行高,推荐1.2~1.5倍行高,可以让代码看上去更优雅
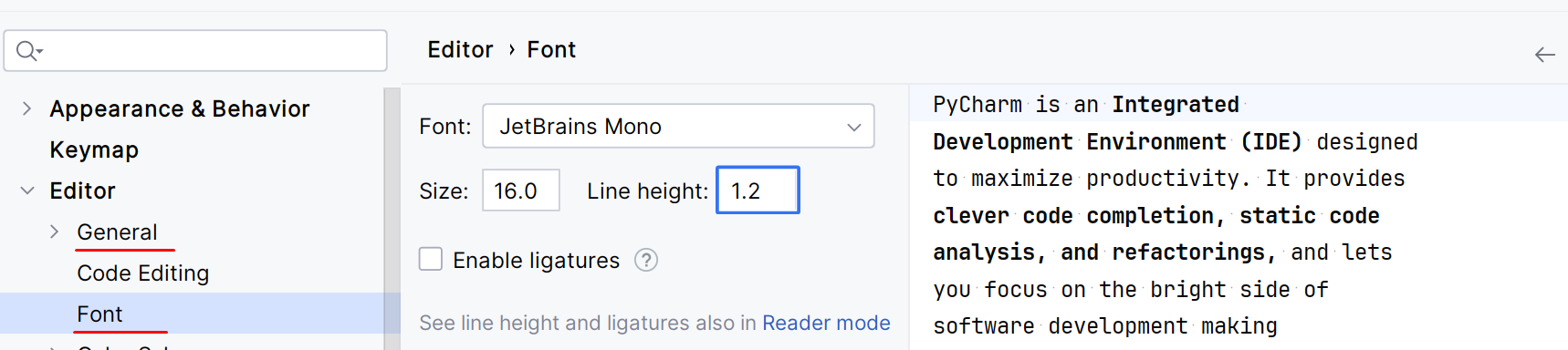
③ 背景选择
根据自己的喜好,调整背景图片(透明度),需要注意-尽量不要让背景图片影响了代码的阅读
运行环境
学习使用Python过程中,建议使用最新的稳定版本:3.12版本

(1) 安装解释器
官方解释器(3.12.2)版本的安装包下载完成后,双击开始安装:
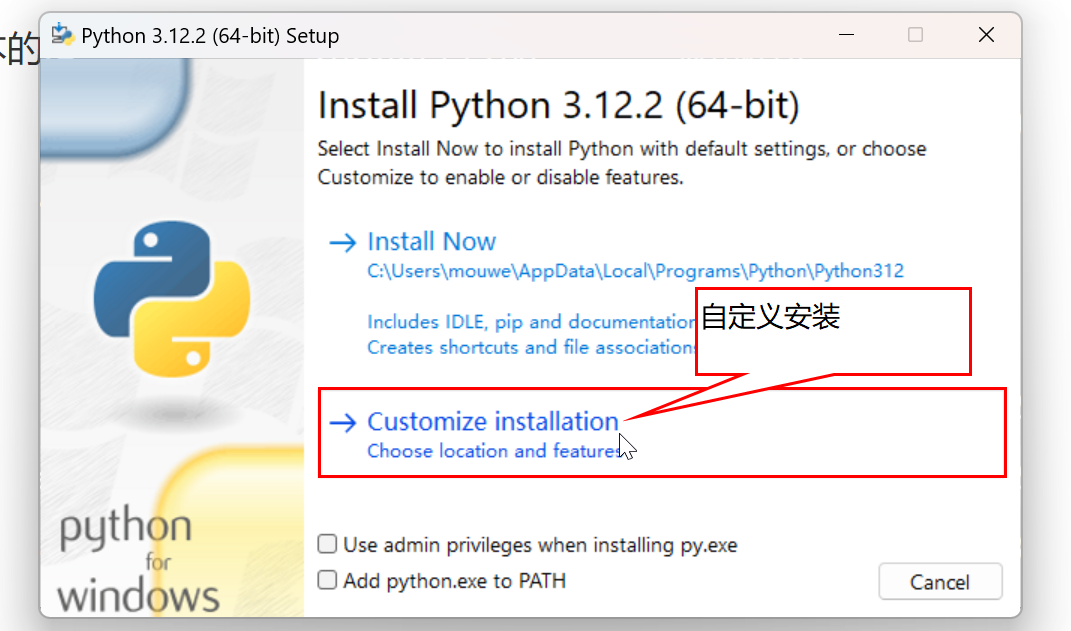
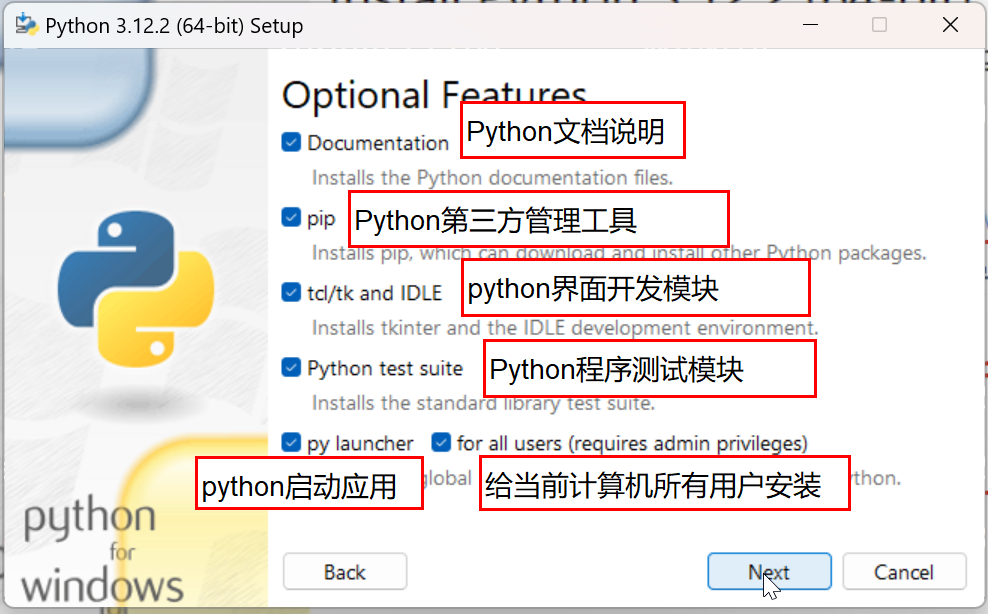
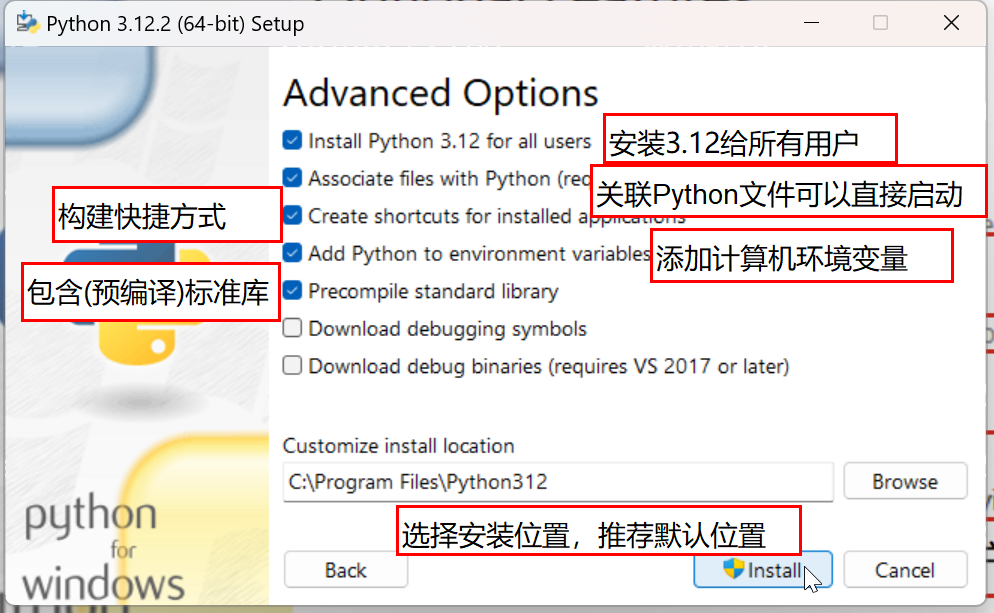
(2) 安装结果验证
按下键盘上的"windows + R"键,打开运行窗口,输入cmd命令,然后回车:打开系统的命令提示符窗口
在命令提示符窗口中,输入python --version 回车执行命令,如果提示了版本信息,说明python安装成功

(3) 注意事项
① 安装软件的位置:
安装Python过程中,推荐使用默认位置安装,有些小伙伴C盘空间不足需要安装到其他磁盘中,需要注意如下几点:
安装位置禁止选择磁盘根目录,如:安装位置: D:/
- 原因:会将大量文件分散到磁盘中导致打开D盘的时候看到相当多陌生的文件,尤其是不小心如果删错了文件导致python不可用!
- 解决方案:可以在其他磁盘中创建新的文件夹安装,如:
安装位置: D:/Python/
安装文件夹路径中注意尽量不要包含中文和空格:如:安装位置: D:/编程/4 13/Python
- 原因:Python程序开发中,后期可能会用到大量的模块,有些模块是国外的小伙伴开发,对中文的支持不太友好,会导致有些文件找不到
- 解决方案:如果英文好-可以使用英文单词组合;英文一般-可以借助翻译软件;如果排斥-可以使用拼音…
② 软件的卸载更换
有些场景下安装错了软件,需要删除软件后重新安装,一定要注意千万不要做如下的 操作:
- 千万注意,不要直接到安装位置,去删除安装好的文件/文件夹,导致这个软件以后无法使用/无法重新安装
- 原因:windows系统中,安装包方式安装的软件,一般会在系统C盘写入文件、同时注册表记录文件信息;这个软件才是可用状态;如果卸载软件的时候你直接删除了文件夹,导致注册表中有这个软件信息,实际C盘没有这些文件,计算机会认为你已经安装好了,但是又找不到文件–报错,并且无法重新安装!
- 解决方案:可以到控制面板去卸载软件/或者借助第三软件管理工具卸载软件,卸载完成后重新安装!
🔖 关于X32、X64、X86的一些故事
系统层面经常会听到32位、64位之类的说法,既是针对CPU的、也是针对操作系统的!
① CPU
CPU中央处理器,包含运算器用于计算机指令的运算,运算过程中一次性从缓存中提取32位二进制数据参与运算的CPU称为32位CPU,一次性提取64位二进制数据参与运算的CPU称为64位CPU
② 操作系统
操作系统开发的时候,就已经针对32位CPU、64位CPU进行了兼容,所以操作系统也区分32位操作系统、64位操作系统;现阶段大部分主流CPU都是64位,所以现在的操作系统基本上都是64位操作系统
- X64:表示当前操作系统是64位操作系统,只能安装在64位CPU上
- X86:表示当前操作系统是32位操作系统,可以安装在32/64位CPU上
③ 软件
软件同样也区分32位、64位软件
- office_win32_64.msi:表示这是一个32/64位兼容的软件安装包
- office_x86_64.msi:表示这是一个32/64位兼容的软件安装包
- office_x86.msi:32位软件,可以安装在32位系统上,也可以安装在64位系统上(速度慢)
- office_x64.msi:64位软件,只能安装在64位系统上
安装错误解析
-
安装时直接过不去
以管理员身份运行
-
安装成功之后,cmd检查不到命令
python -Vpython不是内部或外部命令,也不是可运行的程序或批处理文件。
这种错误可能性非常多,需要一一排查:
- 第一可能就是命令写错了,仔细检查下
- cmd的命令提示符打开的太早
- 前面两个检查了,还是不行,去安装的目录下检查是否安装成功
- 如果安装存在,就说明需要重新配置环境变量
- 安装目录下没有,就说明没有安装成功,重新安装
第一个python程序
从“hello world”开始。
要求从控制台上输出一个这句话。
终端中书写代码
python提供了一个简单的终端,可以在终端中编写python代码,好处,可见即所得,方便于开发者调试、测试、验证代码的准确性,非常方便。当然真正企业开始时,还是要写在python模块中【xxx.py】
写在模块中
python代码需要被书写在一个xxx.py文件中,这种文件被称为python的模块文件。
编写代码
# 第一个Python程序
print("hello world")
print("这个是我的第一个Python程序,请多多关照")
print('少出错,少出BUG!!!!')
使用cmd打开,切换到对应的xxx.py目录下来
执行命令:
python xxx.py
Python注释
注释:标注起来的解释,主要用来给开发者用来说明代码情况的文字或者文本,编译器或者解释器会自动忽略这些内容。
单行注释:只能注释一行内容
Python 的单行注释使用 #
# 单行注释
# 单行注释
多行注释:可以注释多行内容
python使用三引号作为多行注释
三个单引号或者三个双引号,都可以。
"""
控制台上输出如下内容:
英雄联盟商城登录界面
~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~
1. 用户登录
2. 新用户注册
3. 退出系统
~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~
(温馨提示)请输入您的选项:
"""
文档注释:注释可以生成文档,一般不允许压缩。使用的多行注释,只是有特定的要求。
字符串的重复问题
在python,可以使用*来表示字符串的重复次数,乘数字,表示重复对应的次数。
print("\t\t\t英雄联盟商城登录界面")
print("~ * " * 15)
print("~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ * ~ *")
标准输入输出函数
- input
print(字符串) 将字符串输出控制台
input() 将控制台上输入的内容接受代码中
退出终端
cmd python 进入python终端后,可以使用exit()函数退出终端,返回cmd中。
python的变量(variable)
神马是变量
变量:程序运行时(runtime),可以发生变化的量。当然有的人也说,变量是具有名称的内存空间。
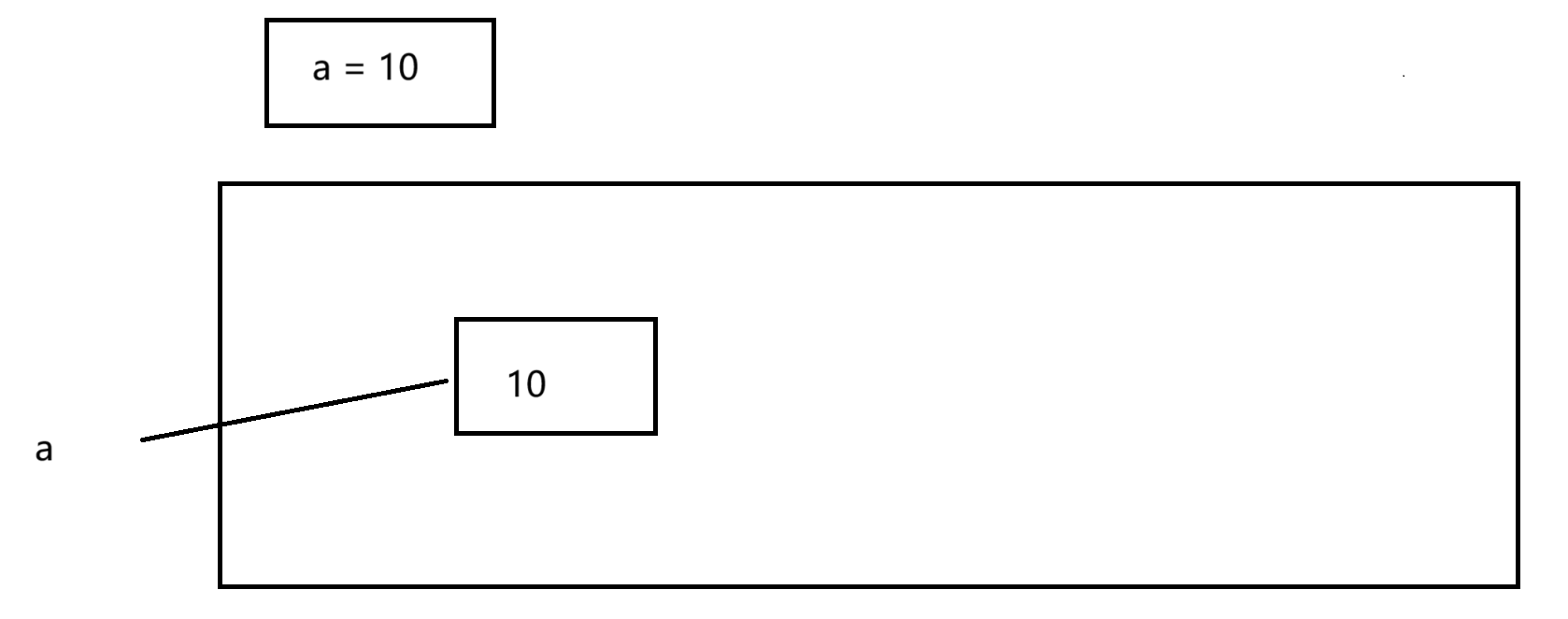
总而言之,变量代表一个具体的值,该值可以参与CPU的运算。
为什么使用变量
使用变量,大大的提高了代码的灵活程度。
python定义变量
在C语言、java、C++(强数据类型编程语言)等编程语言中如何定义变量:
// 语法规范
// 数据类型 变量名称 = 变量值;
int age = 10;
String name = "刘建宏";
boolean isDel = true;
但是也存在一类弱数据类型的编程语言(如、python、PHP、JavaScript)等等,特点是,定义变量时,不用声明变量的类型。
类型交给编译器或者解释器来自动判断,很明显,效率相当而言,较差。
var 变量名称 = 变量值;
但是python中,var都不需要写,直接写成:
# 变量名称 = 变量值
age = 10
name = "刘建宏"
gender = True
price = 3.14
可以使用全局函数type查看变量的类型
print(type(age))
print(type(gender))
python中还存在一个全局函数,可以验证某一个变量是不是属于某个类型。
isinstance函数就可以完成类型判断:
print(isinstance(age, int))
print(isinstance(age, float))
print(isinstance(age, str))
print(isinstance(age, bool))
python的标识符
标识符:程序中表示数据的代词,就是标识符,如变量名称、常量名称、函数名称、类名称……
标识符的命名规范
-
标识符只能有有效符号组成【有效符号:数字、大小写字母、
_】,其他都是特殊符号 -
不能以数字开头!!!
-
不能是
关键字或者保留字 -
尽快避免使用全局模块中的已经定义过的标识符
import builtins print(builtins) """ ['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BaseExceptionGroup', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EncodingWarning', 'EnvironmentError', 'Exception', 'ExceptionGroup', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '_', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'aiter', 'all', 'anext', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip'] """ -
标识符定义是尽量有意义
-
多个单词组成的标识符,建议使用下划线法【推荐】、小驼峰法、大驼峰法【类、结构体】、所有大词都大写【常量】
MAX_AGE = 150 # 这就是一个常量
严格遵循规范:
- 可以避免一些错误
- 可以提高代码的可读性,降低代码的维护成本
python的关键字
关键字:在程序中具有特殊含义的单词或者词组,如 for while if else break……
保留字:目前版本中,不是关键字,但是未来的版本中可能会成为关键字的
import keyword
print(keyword.kwlist)
"""
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
"""
作业1:输入两个数,交换两个数的值【使用多种方式,越多越好】
# 输入两个数,交换两个数的值【使用多种方式,越多越好】
num1 = int(input("请输入第一个数:"))
num2 = int(input("请输入第二个数:"))
print(f"交互前,num1 = {num1},num2 = {num2}")
# 直接交互不可取
# 中间变量法,如果多个值,进行比较,交互等等行为时
# 自身运行,会出现覆盖时,可以多创建变量,来完成值的临时保存
# 临时变量法:优点:简单易懂,非常好理解
# 缺点:浪费内存
# temp = num2
# num2 = num1
# num1 = temp
# 方案2,基于方案1内存占有较多,所以减少内存
# num1 = num1 + num2
# num2 = num1 - num2
# num1 = num1 - num2
# 方案3,是python自身的一种方式
# a, b = 10, 20 这是python提供的一种一行内定义多个变量的方式
# 类似于C语言、java中的 int a = 10, b = 20;
# 注意:这种定义时,多个值会同时被赋值,所以也可以使用这种方式完成多个变量的交互
# num1, num2 = num2, num1
# 方案4,异或运算符
# num1 = num1 ^ num2
# num2 = num1 ^ num2
# num1 = num1 ^ num2
print(f"交互后,num1 = {num1},num2 = {num2}")
作业2:输入两个数,求这两个数的和差商积
num1 = float(input("请输入第一个数:"))
num2 = float(input("请输入第二个数:"))
print(num1 + num2)
print(num1 - num2)
print(num1 * num2)
print(num1 / num2)
print(num1 % num2)
python的数据类型
之前学习的时候,python是弱数据类型的编程语言,在定义和声明变量时,不需要专门声明变量的类型,但是python也存在的数据类型。
python到底存在哪些数据类型?
python的数据类型和C语言、java等类似,存在两大类型的数据类型。
- 基本数据类型
- 复合数据类型
基本数据类型
编程语言已经内置了类型,在开发时,不需要开发者自己申请、定义的类型。
如数字、布尔类型等等。注意:不同的编程语言,基本数据类型可能存在着出入!
-
数值型(number)
表示数字类型,数字往往分为整数、小数、复数
- 整型 (int)
- 浮点型(float)
- 复数(complex)
-
布尔类型(boolean)
只有两个值,一个是真(True),一个是假(False)。
注意:数字中,非零为真,零为假。
注意:字符串中,""表示假,其他都代表真
注意:None也表示假
-
字符串(string)
字符串在python中是基本数据类型。可以直接使用等号来比较两个字符串。
在python中,单引号、双引号、三引号
在python中,单引号和双引号是一个意思,都是字符串。
s = 'this is a string' ss = "this is a string" sss = '''this is a string''' ssss = """this is a string""" sss = """ this is a string !! !!! """所以,三引号,使用在较为复杂的字符串拼接处理中,通过换行来简化操作。
-
None
表示没有
复合数据类型
编译器或者解释器没有内置的数据类型,也就是开发者要使用,必须自己创建才能使用。
list
set
tuple
dict
object
……
万物皆对象
python的类型转换
数学中,我们就学习基本概念:只有相同类型的数据,才可以运算。
但是开发中,往往数据的类型可能不一致,这个时候,要进行运算,必须将数据类型转换为同一种数据类型。
编程中存在两种类型转换规则:
- 自动类型转换
- 强制类型转换
自动类型转换
自动类型转换,顾名思义,不需要开发者手动转换,由编译器或者解释器自动完成转换。如C或者Java中,自动转换,比较多:
boolean < byte < short < int < long < float < double < String
python中,自动类型只存在于三种类型:
- 整型
- 浮点型
- 布尔类型
bool > 整型 > 浮点型
a = True
b = False
c = 10
d = 3.14
print(a + c)
print(b + c)
print(d + c)
注意:浮点数在计算机中的存储和运算问题。
强制类型转换
编译器或者解释器,无法完成自动类型转换,就需要开发者自己进行类型转换。
注意:前提条件:可以转换的。
- int(字符串) 将字符串转换为整数
- float(字符串) 将字符串转换为浮点数
- str(可以转换为字符串类型)
num1 = float(input("请输入第一个数:"))
num2 = float(input("请输入第二个数:"))
# print(num1 + num2)
# print(num1 - num2)
# print(num1 * num2)
# print(num1 / num2)
# print(num1 % num2)
# 第一种字符串格式化的方式,就是将所有类型统统转换为字符串
# print(str(num1) +" + "+ str(num2) +" = "+ str(num1 + num2))
# C语言特性
# print("%d + %d = %d" %(num1, num2, num1 + num2))
# print("num1的值是:%d"%(num1))
# print("num1的值是:%d"%num1)
# print("%.2f + %f = %f" %(num1, num2, num1 + num2))
# 第二种方式
# print("%s + %s = %s" %(num1, num2, num1 + num2))
# 多个值之间,print会以空格的形式拼接
# print(num1, " + ", num2, " = ", num1 + num2)
# 第四种方式,python字符串对象的方法, format方法
# print("{} + {} = {}".format(num1, num2, num1 + num2))
# 第五种方式,确实就是第四种方式的简写
print(f"{num1} + {num2} + {num1 + num2}")
作业
将第二题升级。
xxx + xxx = xxx
xxx - xxx = xxx
内容总结
- 编程语言发展和python这门编程语言的发展
- python的环境搭建
- python的变量
- python注释
- python的关键字、标识符
- python的数据类型
- 数据类型的转换
常见运算符
开发和数学类似,存在很多数据的运算规则(类似于数学中四则运算)。
- 算术运算符
- 关系(比较)运算符
- 逻辑运算符
- 赋值运算符
- 三目运算符
- is运算符
- 所属运算符
- 位运算符
算术运算符
算术运算符:指的数学中算术,及相关规则
+ 加
- 减
* 乘
/ 除
// 整除、地板除法
% 求模、求余数
** 幂次方
a = 10
>>> b = 3
c = 2
>>> a + b
>>> a - b
>>> a * b
30
>>> a / b
3.3333333333333335
>>> a // b
3
>>> a % b
1
>>> a % c
0
>>> a ** b
1000
>>> a ** c
100
>>> a
10
>>> a ** 0.5
3.1622776601683795
>>>
>>>
>>> a
10
>>> a ** 0.333333333333333333333333333333333
2.154434690031884
>>> a ** (1 / 3)
2.154434690031884
>>> 27 ** (1 / 3)
3.0
关系运算符
关系运算符,又被称比较运算符,说明的是多个数之间的关系。
关系运算符的结果是布尔类型,也就是说,是否成立。
>
<
>=
<=
== # 等于符号
!=
a = 10
b = 3
c = 2
>>> a > b
True
>>> a
10
>>> b
3
>>> a < b
False
>>> a >= 10
True
>>> a <= 10
True
>>> a == b
False
>>> a != b
True
逻辑运算符
逻辑运算符说明的问题是,多个运算符之间的关联关系。
and与运算符 代表一种并且关系or或运算符 代表一种或者关系not非运算符 代表取反
>>> a > b and a > c
True
>>> a > b and a < c
False
>>> a > b or a < c
True
>>> a > b
True
>>> not a > b
False
>>>
赋值运算符
将值赋予某个变量,最常见的=。
= # 将等号右侧的值
+= # a = 20; a = a + 10 <===> a += 10
-=
*=
/=
//=
%=
**=
如果此时,我们要数据加1或者减一。
a = 10
print(a += 1)
print(a -= 1)
自减和自减运算符
注意:python没有**自加和自减运算符。**龟叔认为没有必要学习这个复杂的运算符。
如java中:
int a = 10;
a++; // a = 11
++a; // a = 12
--a; // a = 11
a--; // a = 10
int b = a++; // a = 11 b = 10
int c = ++a; // a = 12 c = 12
int d = --a; // d = 11
int e = a--; // e = 11
总结:前加加和前减减运行的优先级别非常高,仅次于括号。而后加加和后减减优先级别非常低,**低到比赋值符(=)还低。**所以一定要注意这个问题。
三目运算符
三目运算符,又被称为三元运算符,本质是if else的简写方式,将多行代码简化为一行代码。
简单的回忆下C、C++、Java语言中的三目运算符:
// 变量 = 表达式 ? 值1 : 值2
int a = 10;
int b = 20;
int c = a > b ? 100 : 200;
int d = a < b ? 100 : 200;
python中,三目运算符是这样写的:
# 变量 = 值1 if 表达式 else 值2
a = 10
b = 3
c = 100 if a > b else 1000
>>> c
100
>>> d = 100 if a < b else 2000
>>> d
2000
所属运算符
- in 表示是否在里面
- not in 表示不在里面
所属运算符表示的判断某一个变量是否在某个**容器(可迭代对象)**中。
>>> a
[1, 2, 3, 4, 45, 10, 56]
>>>
>>>
>>> b = 3
>>>
>>> b in a
True
>>>
>>>
>>> 101 in a
False
>>> b not in a
False
>>> 101 not in a
True
is运算符
python中存在一个is运算符,该运算符跟==非常像,都是用来判断结果的。
- is 判断的是两个变量的内存地址
- == 判断的两个变量的值
- id全局函数,返回变量的内存地址
is not表示is的取反,判断两个变量不是同一个地址
位运算符
计算机底层的运算规则,相当来说,有点难。暂时不讲。
程序控制流程
程序控制流程,又被称为三大流程。
- 顺序结构
- 选择结构
- 循环结构
顺序结构
顺序结构,说的就是程序的整体运行顺序。
python是一门弱数据类型的编程语言,也是一门脚本语言,所有代码是逐行运行的。
从左到右,自上而下执行。
# python中,分号和换行都是语句的结束标志
# 但是建议使用换行,不推荐使用分号
a = 10; b = 20
print(a, b)
选择结构
选择结构,说的是程序在运行中,面临多种情况的一种选择问题。
- 单分支
- 双分支
- 多(三)分支
单分支
只考虑某一种情况,不管其他情况。
语法结构:
"""
if 条件:
# 条件如果成立,则执行if中的代码
"""
age = int(input("请输入您的年龄:"))
# 判断是否成年
if age >= 18:
print("恭喜您,成年了")
print("可以干一些成年人的事")
print("可以去网吧了")
print("game over")
程序流程控制
选择结构
双分支
相对于单分支而言,只考虑一种情况,那么可能存在另一种情况,所以双分支,将两种情况都考虑进去,做出对应的操作。
基本语法:
if condition:
# 如果condition成立(True),则执行if中的代码
else:
# 其他情况下,执行这儿的代码
age = int(input("请输入您的年龄:"))
# 判断是否成年
if age >= 18:
print("恭喜您,成年了")
print("可以干一些成年人的事")
print("可以去网吧了")
else:
print("对不起,您还没有成年,回家找妈妈吧")
print("game over")
多分支
多分支,又被称为三分支。表示多种可能存在(三种或者三种以上)。
语法结构:
if condition1:
# 如果condition1成立(True),则执行if中的代
elif codition2:
# 如果condition2成立(True),则执行这儿的代码
elif codition3:
# 如果condition3成立(True),则执行这儿的代码
……
elif coditionN:
# 如果conditionN成立(True),则执行这儿的代码
[else:
# 其他的剩余条件
]
week = input("请输入今天的星期数:")
if week == '1':
print("今天星期一,猴子穿花衣")
elif week == "2":
print("今天星期二,猴子吃串串")
elif week == "3":
print("今天星期三,猴子去爬山")
elif week == "4":
print("今天星期四,猴子去考试")
elif week == "5":
print("今天星期五,猴子去跳舞")
elif week == "6" or week == '7':
print("今天周末,猴子在家休息")
else:
print("对不起,你说猴子请来的救兵吗?")
#### 循环
##### 什么叫做循环
循环:出自于《战国策》,周而复始,则谓之为循环。
因此循环,就是重复执行某些代码。
在真实的企业中,不要重复粘贴复制代码,因为将来代码的维护成本很高。所以开发者需要一种能够重复执行某些代码的一种语法。
python中,只存在两种循环。
+ for 设计之初,主要用来解决无序数据迭代问题
+ while 常规的循环
##### while循环
语法结构:
```python
while condition:
# 循环体
[else:
# 表示循环正常结束时,才会进入到else
]
案例1:打印输入100行“hello world”。
index = 0
while index < 100:
print("hello wrold", index + 1)
index += 1
print("game over")
循环的注意事项:
- 循环必须存在条件
- 如果条件永远成立,则是死循环
- 循环的条件应该有个极限值
案例2:使用while循环球0~100的和。
index = 0
count = 0
while index <= 100:
count += index
index += 1
print(f"0~100的和是:{count}")
案例3: 求100!。
index = 1
count = 1
while index <= 100:
count *= index
index += 1
print(f"100的阶乘是:{count}")
break、continue关键字
- break 打断、中断,循环表示终止、打断循环
- continue 继续 , 循环中表示跳过本次循环,进入下次循环
index = 10
while index >= 0:
if index == 5:
# 终止里它最近的那层循环
break
print(index)
index -= 1
结论:break会终止循环,默认终止里它最近的那层循环。
index = 10
while index >= 0:
index -= 1
if index == 5:
# 终止里它最近的那层循环
# break
continue
print(index)
结论:跳过本次循环,进入下次循环。continue没有终止循环的功能。
循环else
while condition:
# 循环体
[else:
# 表示循环正常结束时,才会进入到else
]
循环中的else,可以写,也可以不实现(根据具体情况而言)。
else中的代码会不会执行,根据循环是否正常结束来判断,只有循环正常结束,才会进入else块,执行这儿代码。如果循环异常结束【break关键字】,则不会执行else中代码。
index = 10
while index >= 0:
index -= 1
if index == 5:
# 终止里它最近的那层循环
# break
continue
print(index)
else:
print("else是循环正常结束后才执行")
print("这段代码执行了吗?")
print("GAME OVER")
课堂案例:在控制台使用while循环输出九九乘法表。
课堂案例2:用户决定打印多少层
"""
*
**
***
****
*****
"""
layer = int(input("请输入您要打印的层数:"))
""" 矩形 """
# index = 1
# while index <= layer:
# print("*************")
# index += 1
""" 直角三角形 """
# index = 1
# while index <= layer:
# j = 0
# while j < index:
# print("*", end="")
# j += 1
# print()
# index += 1
index = 1
while index <= layer:
print("*" * index)
index += 1
- 课堂案例
- 九九乘法表的打印
i = 1
while i <= 9:
j = 1
while j <= i:
print(f"{j} x {i} = {i * j}", end="\t")
j += 1
print()
i += 1
for循环
python中的for循环和C语言for循环不一样。
龟叔在设计python时,尽可能的减少重复的各种语法,所以将其他编程语言的三种循环减少到一种,就是while循环,设计是发现了新的问题,无法遍历无序数据,就引入了for循环,该for循环是一种迭代的概念,能够迭代无序数据,完成无序数据的遍历。
有序数据的遍历:
a = [1, 2, 3, 555, 5]
>>> i = 0
>>> len(a)
5
>>> i = 0
>>> while i < len(a):
... print(a[i])
... i += 1
...
1
2
3
555
5
在开发中,存在一种无序的容器【哈希表】,不能使用下标,就无法使用下标来遍历:
s = {1, 2, 3, 555, 5}
>>> i = 0
>>> while i < len(s):
... print(s[i])
... i += 1
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: 'set' object is not subscriptable
for的语法结构:
for 临时变量 in 容器:
# 每一次循环时,迭代出的子元素,会临时的保存在临时变量中
[else:
# 只有循环正常结束,才会进入else中
]
>>> for i in s:
... print(i)
...
16
1
2
3
5
10
555
当然也可以迭代有序的:
>>> for _ in a:
... print(_)
...
1
2
3
555
5
在for被创建之后,发现一个问题,for一般和容器配合使用,想要直接进行循环运算反倒比较麻烦,如:求1~100的和。
range函数
range是一个全局函数,是python提供给for循环使用,用来加强for循环的使用。
range返回可迭代对象。是一个范围内的可迭代对象。
- range(num) # [0, num) 区间内的所有整数
- range(start, end) # [start, end) 区间内的所有整数
- range(start, end, step) # step表示步长,默认是1,可以自定义,可以是负数,如果是负数,表示减
>>> # 0~10的和
>>> s = 0
>>> for i in range(11):
... print(i)
...
0
1
2
3
4
5
6
7
8
9
10
>>> for i in range(11):
... s += i
...
>>> s
55
>>> # 10 ~ 20
>>> for j in range(10, 21):
... print(j)
...
10
11
12
13
14
15
16
17
18
19
20
>>> # 10 ~ 20 的偶数
>>> for i in range(10, 21):
... if i % 2 == 0:
... print(i)
...
10
12
14
16
18
20
>>> for i in range(10, 21, 2):
... print(i)
...
10
12
14
16
18
20
>>> for i in range(10, -1, -1):
... print(i)
...
10
9
8
7
6
5
4
3
2
1
0
>>> for i in range(10, 0, -1):
... print(i)
...
10
9
8
7
6
5
4
3
2
1
课堂案例练习:
- 使用for循环输出九九乘法表
- 使用for求出50~100的奇数和和偶数和
- 输入一个正整数(>1),判断该数是否是质数
- 输入行数,在控制台上输出对应的图案
*
***
*****
*******
*********
*
**
***
****
*****
*
***
*****
*******
*********
*********
*******
*****
***
*
*
***
*****
*******
*********
*******
*****
***
*
*
* *
* *
* *
* *
* *
* *
* *
*
*
***
* * *
* * *
*********
* * *
* * *
***
*
-
存在一个三位数ABC,这个数的个位是3,十位是个位的倍数,百位都等于个位和十位之和,求符合条件的所有三位数
-
鸡兔同笼问题:有若干只鸡兔同在一个笼子里,从上面数,有35个头,从下面数,有94只脚。问笼中各有多少只鸡和兔
-
猜数字游戏:
电脑随机生成一个0~100这个范围内的整数,用户来猜,会给对应的提示 -
计算器:
请输入两个数和一个符号,完成两个数的+ - * / % // ** -
让用户输入一个月份,判断这个月是哪个季节?假定3到
4月是春季,5到8月是夏季,9到10是秋季,11、12、1、2
月是冬季 -
提示用户输入用户名,然后再提示输入密码,如果用户名
是“admin”并且密码是“88888”,则提示正确,否则,如果
用户名不是admin还提示用户用户名不存在,如果用户名是
admin则提示密码错误。 -
有一些四位数,百位数字都是3,十位数字都是6,并且它们既能被2整除,又能被3整除,求这样的四位数中最大的和最小的两数各是几?
-
编程求一个四位自然数ABCD,它乘以A后变成DCBA
-
用户输入两个数a、b。如果a能被b整除或a加b大于1000,则输出a;否则输出b
-
输入赵本山的考试成绩,显示所获奖励
成绩==100分,爸爸给他买辆车
成绩>=90分,妈妈给他买MP4
90分>成绩>=60分,妈妈给他买本参考书
成绩<60分,什么都不买 -
请输入一个数,判断这个数是偶数还是奇数,如果使用偶数,请判断从1到该数是3的倍数有哪些,如果是奇数,请判断从1到该数是5的倍数有哪些
-
输入三边的长度,求三角形的面积和周长(海伦公式)
-
某商店T恤的价格为35元/件(2件9折,3件以上8折),裤子的价格为120 元/条(2条以上9折).小明在该店买了3件T恤和2条裤子,请计算并显示小明应该付多少钱?
-
输入一个年份,判断该年是否是闰年
打印图案:
layer = int(input("请输入您要打印的层数:"))
""" 矩形 """
# index = 1
# while index <= layer:
# print("*************")
# index += 1
""" 直角三角形 """
# index = 1
# while index <= layer:
# j = 0
# while j < index:
# print("*", end="")
# j += 1
# print()
# index += 1
# index = 1
# while index <= layer:
# print("*" * index)
# index += 1
"""
胖直接三角形
"""
# for i in range(1, layer + 1):
# # 需要计算每行的*的数量
# for j in range(2 * i - 1):
# print("*", end="")
# print()
# 简化写法
# for i in range(1, layer + 1):
# print("*" * (2 * i - 1))
"""
翻转180度的直角三角形
"""
# for i in range(1, layer + 1):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(i):
# print("*", end="")
# print()
# 简化写法
# for i in range(1, layer + 1):
# print(" " * (layer - i), end="")
# print("*" * i)
# # 打印等腰三角形
# for i in range(1, layer + 1):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(2 * i - 1):
# print("*", end="")
# print()
# 简化写法
# for i in range(1, layer + 1):
# print(" " * (layer - i), end="")
# print("*" * (2 * i - 1))
# # 打印倒等腰三角形
# for i in range(layer, 0, -1):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(2 * i - 1):
# print("*", end="")
# print()
# 简化写法
# for i in range(layer, 0, -1):
# print(" " * (layer - i), end="")
# print("*" * (2 * i - 1))
# 校验用户输入的数据是否合法
while layer % 2 == 0:
layer = int(input("请输入奇数:"))
# 菱形
# # 先打印上部分
# for i in range(1, layer // 2 + 2):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(2 * i - 1):
# print("*", end="")
# print()
# for i in range(layer // 2, 0, -1):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(2 * i - 1):
# print("*", end="")
# print()
# 空心菱形
# for i in range(1, layer // 2 + 2):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(2 * i - 1):
# # 判断是不是第一个或者最后一个
# if j == 0 or j == 2 * i - 2:
# print("*", end="")
# else:
# print(" ", end="")
# print()
# for i in range(layer // 2, 0, -1):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(2 * i - 1):
# # 判断是不是第一个或者最后一个
# if j == 0 or j == 2 * i - 2:
# print("*", end="")
# else:
# print(" ", end="")
# print()
# 对角线菱形
# for i in range(1, layer // 2 + 2):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(2 * i - 1):
# # 判断是不是第一个或者最后一个
# if j == 0 or j == 2 * i - 2 or i == layer // 2 + 1 or j == i - 1:
# print("*", end="")
# else:
# print(" ", end="")
# print()
# for i in range(layer // 2, 0, -1):
# # 先打印空格
# # 空格的数量 layer - i
# for j in range(layer - i):
# print(" ", end="")
# # 再打印*
# for j in range(2 * i - 1):
# # 判断是不是第一个或者最后一个
# if j == 0 or j == 2 * i - 2 or j == i - 1:
# print("*", end="")
# else:
# print(" ", end="")
# print()
判断是否是质数:
"""
判断某个数是否是质数
质(素)数:只能被1和它本身整除的数
"""
num = int(input("请输入一个大于1的正整数:"))
# flag就是用来标记的
flag = True
# 循环遍历,一个一个的除,从2开始,到num - 1
for i in range(2, num // 2 + 1):
# 判断i能不能正常num
if num % i == 0:
# print("不是质数")
flag = False
break
if flag:
print(f"{num}是质数")
else:
print(f"{num}是合数")
求最大值和最小值:
# 定一个列表
nums = []
# 找出所有符合的四位数
for i in range(1000, 10000):
# i = 1234 1就是千位
# q = i // 1000
b = i % 1000 // 100
s = i % 100 // 10
# g = i % 10
if b == 3 and s == 6 and i % 6 == 0:
# print(i)
nums.append(i)
print(nums)
# 求列表中最大值和最小值
# min_value = nums[0]
# max_value = nums[0]
# for i in nums:
# if i > max_value:
# max_value = i
# if i < min_value:
# min_value = i
# print(f"最大值是{max_value}")
# print(f"最小值是{max_value}")
# python提供了两个全局函数、
# max min
print(f"最大值是{max(nums)}")
print(f"最小值是{min(nums)}")
拆位数:
# 编程求一个四位自然数ABCD,它乘以A后变成DCBA
for _ in range(1000, 10000):
a = _ // 1000
b = _ % 1000 // 100
c = _ % 100 // 10
d = _ % 10
if _ * a == d * 1000 + c * 100 + b * 10 + a:
print(_)
容器篇
容器,代表着一种可以存储一批数据的一种结构,python官方叫做集合(Collection),又被成为可迭代对象(Iterable)。
为什么学习容器
现实中,往往需要一种存储大量数据的一种结构。
这些容器都各有特点,所以会学科学习它们,这个就是《数据结构与算法》
-
线性表
- 数组(array):内存中的连续内存结构。存储相同类型数据、大小固定;查询效率高O(1),但是更新效率差
- 链表(list):链表在内存中不一定连续。查询效率没有数组高,但是跟新效率高,单项链表和双向链表的区别请大家注意
- 栈(stack):先进后出(FILO)、后进先出(LIFO)
- 队列(queue)先进先出(FIFO)、后进后出(LILO)
-
哈希表
是一种动态表格,保存数据的结构可能会发生变化,所以哈希表是无序的,不能存储重复数据
-
树
-
图
python的内置容器
python为了方便开发者直接使用一些数据结构,快速开发,所以为大家提供如下几种内置容器。
- list 列表, 底层是一种线性表
- set 集合,底层是种哈希表
- tuple 元组,底层是固定的线性表
- dict 字典,底层也是哈希表
列表(list)
python提供给开发者使用的一种线性表,这种线性表底层采用双向链表结构设计。
注意:python是没有数组这种数据结构的!!!或者说所有的弱数据类型编程语言都没有数组。
定义列表
第一种定义方式:
在python中,[]就是python的列表,所以可以直接给某个变量赋予这种类型的数据,则变量就自然而然的成为了list这种类型。
a = []
>>> type(a)
<class 'list'>
>>> a = [1,2,3,4,45,5]
>>> a
[1, 2, 3, 4, 45, 5]
>>> type(a)
<class 'list'>
第二种定义方式:
可以借助全局函数list,python为开发者提供了这样一个全局函数,该函数的作用是,将某个类型的数据转换为列表类型。
>>> b = list()
>>> b
[]
>>> type(b)
<class 'list'>
>>>
>>> b = list([1,3,34,5,6,67])
>>> b
[1, 3, 34, 5, 6, 67]
>>>
>>> type(b)
<class 'list'>
# list函数主要是用来转换类型的,将其他可以转换为列表的类型转换为列表
>>> s = "i love you, china!!"
>>> s
'i love you, china!!'
>>>
>>>
>>> c = list(s)
>>> c
['i', ' ', 'l', 'o', 'v', 'e', ' ', 'y', 'o', 'u', ',', ' ', 'c', 'h', 'i', 'n', 'a', '!', '!']
# 将set转换为list
>>> ss = {1,2,3,4}
>>> ss
{1, 2, 3, 4}
>>>
>>>
>>> list(ss)
[1, 2, 3, 4]
如何访问列表的元素
列表底层本质上双向链表,而所有的线性表都是有序的!!有序的数据,可以通过**下标(角标)**来访问其中的元素。
注意:下标一般从0开始,也就是说最后一个元素的下标是列表的长度 - 1。
a = [1, 2, 3, 4, 45, 5]
# 第一个值
print(a[0]) #
print(a[2])
print(a[5])
# 注意,如果访问的下标超出了列表的范围,则抛出下标越界的错误
print(a[6]) # error
获取列表的长度
使用全局函数len,该函数可以获取可迭代对象的长度。
>>> len(a)
6
>>> len(b)
6
>>> s
'i love you, china!!'
>>>
>>>
>>> len(s)
19
修改元素的值
可以访问到,如果没有特殊的约束,就可以修改这个值。
>>> a
[1, 2, 3, 4, 45, 5]
>>>
>>>
>>> a[0] = 100
>>>
>>> a[0]
100
>>> a
[100, 2, 3, 4, 45, 5]
遍历列表
可以使用while和for循环完成。
a = [1, 2, 3, 4, 45, 5]
index = 0
while index < len(a):
print(a[index])
index += 1
for i in a:
print(i)
列表的常见方法【重点】
学习python时,要学会使用查看帮助文档,如果查看,主要借助两个全局函数
- dir() 可以将某个模块\类\对象\…… 里面的子成员展开返回
- help() 将需要使用的函数\类\模块…… 查询它的帮助文档
import random
dir(random)
>>> dir(random)
['BPF', 'LOG4', 'NV_MAGICCONST', 'RECIP_BPF', 'Random', 'SG_MAGICCONST', 'SystemRandom', 'TWOPI', '_ONE', '_Sequence', '_Set', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_accumulate', '_acos', '_bisect', '_ceil', '_cos', '_e', '_exp', '_floor', '_index', '_inst', '_isfinite', '_log', '_os', '_pi', '_random', '_repeat', '_sha512', '_sin', '_sqrt', '_test', '_test_generator', '_urandom', '_warn', 'betavariate', 'choice', 'choices', 'expovariate', 'gammavariate', 'gauss', 'getrandbits', 'getstate', 'lognormvariate', 'normalvariate', 'paretovariate', 'randbytes', 'randint', 'random', 'randrange', 'sample', 'seed', 'setstate', 'shuffle', 'triangular', 'uniform', 'vonmisesvariate', 'weibullvariate']
>>>
>>>
>>> help(random.randint)
Help on method randint in module random:
randint(a, b) method of random.Random instance
Return random integer in range [a, b], including both end points.
a = [2, 3, 4, 45, 5]
dir(a)
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
- append(新元素) # 在尾部追加新的元素
- insert(index, 新元素) # 在某一个位置插入新的元素
- clear() # 把列表情况
- remove(元素) # 移除查找到的第一个元素,如果没有,则抛出异常
- pop([index]) # 默认移除最后一个元素,如果写了索引,则因此对应的值
- copy() # 复制列表,本质是浅拷贝
- count(元素) # 统计元素的次数
- extend(新列表) # 合并列表
- index() # 返回查询的一个元素的索引位置,如果找不到,则抛出异常
- reverse() # 翻转元素的顺序
- sort() # 排序
>>> a.append(100)
>>>
Help on built-in function append:
>>>
>>> a
>>> a
>>> a.insert(8,59)
>>>
[59, 2, 3, 4, 59, 45, 5, 100, 59, 59, 59]
>>> a
[59, 2, 3, 4, 59, 45, 5, 100, 59, 59, 59, 99]
>>>
>>>
>>>
>>>
>>>
>>> b
[1, 3, 34, 5, 6, 67]
>>>
>>> b.clear()
[59, 2, 3, 4, 59, 45, 5, 100, 59, 59, 59, 99]
>>>
[59, 3, 4, 59, 45, 5, 100, 59, 59, 59, 99]
>>> a.remove(599)
File "<stdin>", line 1, in <module>
>>>
>>>
>>> help(a.pop)
Help on built-in function pop:
pop(index=-1, /) method of builtins.list instance
Remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range.
>>> a
[3, 4, 59, 45, 5, 100, 59, 59, 59, 99]
>>>
>>>
>>> a.pop()
99
>>> a
[3, 4, 59, 45, 5, 100, 59, 59, 59]
>>>
>>>
>>> a
[3, 4, 59, 45, 5, 100, 59, 59, 59]
>>>
>>>
>>> a.pop(0)
3
>>> a
[4, 59, 45, 5, 100, 59, 59, 59]
>>>
>>> b
[1, 3, 34, 5, 6, 67]
>>>
>>> b.clear()
[59, 2, 3, 4, 59, 45, 5, 100, 59, 59, 59, 99]
>>>
[59, 3, 4, 59, 45, 5, 100, 59, 59, 59, 99]
>>> a.remove(599)
File "<stdin>", line 1, in <module>
pop(index=-1, /) method of builtins.list instance
>>> a
>>>
>>> a.pop()
>>> a
>>>
[3, 4, 59, 45, 5, 100, 59, 59, 59]
>>> a
>>>
>>> a
>>>
>>> b = a
[4, 59, 45, 5, 100, 59, 59, 59]
[4, 59, 45, 5, 100, 59, 59, 59]
>>> a
[4, 59, 45, 5, 100, 59, 59, 59, 1000]
>>> c = a.copy()
[4, 59, 45, 5, 100, 59, 59, 59, 1000]
[4, 59, 45, 5, 100, 59, 59, 59]
>>>
[4, 59, 45, 5, 100, 59, 59, 59]
>>>
>>> a.count(10)
0
>>> a
>>> a.extend(b)
>>>
>>>
>>> a.index(45)
File "<stdin>", line 1, in <module>
>>>
>>> a
[4, 59, 45, 5, 100, 59, 59, 59, 4, 59, 45, 5, 100, 59, 59, 59]
[59, 59, 59, 100, 5, 45, 59, 4, 59, 59, 59, 100, 5, 45, 59, 4]
>>>
>>> a.sort()
>>> a
[4, 4, 5, 5, 45, 45, 59, 59, 59, 59, 59, 59, 59, 59, 100, 100]
>>>
>>>
>>> a
[4, 4, 5, 5, 45, 45, 59, 59, 59, 59, 59, 59, 59, 59, 100, 100]
>>>
>>>
>>> a.append(True)
>>> a
[4, 4, 5, 5, 45, 45, 59, 59, 59, 59, 59, 59, 59, 59, 100, 100, True]
>>>
>>> a.append("liujianhong")
>>> a
[4, 4, 5, 5, 45, 45, 59, 59, 59, 59, 59, 59, 59, 59, 100, 100, True, 'liujianhong']
>>>
>>> a.sort()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'str' and 'int'
>>> a.remove("liujianhong")
>>>
>>>
>>> a.sort()
>>> a
[True, 4, 4, 5, 5, 45, 45, 59, 59, 59, 59, 59, 59, 59, 59, 100, 100]
课堂案例练习:
输入一个大于0的正整数n,如果n == 1 ,则返回1, 如果n是偶数,则返回 n // 2 ,如果n是奇数,则返回 3n + 1,将所有的返回值存放到一个列表中,注意:n是第一个元素,其他的元素根据上述要求生成。最后求返回的列表和列表长度。
集合(set)
python的set,底层采用的就是hash table。哈希表的特点:无序、数据不重复
set定义
和list一样,也是两种方式创建:
第一种:使用{}创建,默认就是set。
注意:如果是空的,则默认是dict,因为dict和set底层都是hash table。
>>> s = {}
>>> type(s)
<class 'dict'>
>>>
>>>
>>>
>>> s = set()
>>> s
set()
>>> type(s)
<class 'set'>
>>>
>>>
>>> s = {12,2,3,4,5,5,6}
>>> type(s)
<class 'set'>
>>> s
{2, 3, 4, 5, 6, 12}
>>> s = {12,2,3,4,5,5,6, 16}
>>> s
{16, 2, 3, 4, 5, 6, 12}
第二种方式,类型转换函数set
ss = set()
ss = set([1,23,4,5,56])
>>> ss = set([1,23,4,5,56])
>>> ss
{1, 4, 5, 23, 56}
>>>
>>> ss = set({1,23,4,5,56})
>>> ss
{1, 4, 5, 23, 56}
再次强调,set是无序的,底层是哈希表,所以没有下标。
无法通过下标来访问元素
set遍历
只能使用for循环迭代。
>>> for i in s:
... print(i)
...
16
2
3
4
5
6
12
常见方法
[‘add’, ‘clear’, ‘copy’, ‘difference’, ‘difference_update’, ‘discard’, ‘intersection’, ‘intersection_update’, ‘isdisjoint’, ‘issubset’, ‘issuperset’, ‘pop’, ‘remove’, ‘symmetric_difference’, ‘symmetric_difference_update’, ‘union’, ‘update’]****]
- add(新元素)
- clear()
- copy()
- remove()
- pop()
- update()
- union()
- intersection()
- difference()
>>> dir(s)
['__and__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__iand__', '__init__', '__init_subclass__', '__ior__', '__isub__', '__iter__', '__ixor__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersectionfference_update', 'union', 'update']
>>>
>>>
>>>
>>> s.add(10)
>>> s
{16, 2, 3, 4, 5, 6, 10, 12}
>>>
>>>
>>> help(s.pop)
>>> s.pop()
>>>
>>> s
>>>
>>> s.update(ss)
{1, 4, 5, 6, 10, 12, 23, 56}
>>> s
>>>
{1, 4, 5, 23, 56}
>>> ss.add(10000)
>>> s
>>>
>>>
>>> ss
{10000, 1, 4, 5, 100, 23, 56, 1000}
>>>
>>>
>>>
>>> s.difference(ss)
{12334, 10, 12, 6}
>>>
>>>
>>> ss.difference(s)
{10000, 1000, 100}
>>>
>>>
>>>
>>> s
{1, 4, 5, 6, 10, 12, 12334, 23, 56}
>>>
>>>
>>>
>>> num1 = [12,2,3,4,4,5]
>>>
>>>
>>> num2 = [12,3,3,4,5,6]
>>> num1 + num2
[12, 2, 3, 4, 4, 5, 12, 3, 3, 4, 5, 6]
元组(tuple)
一组固定不变的值,所以元组是不可变数据类型。
python中使用()来表示元组类型。
>>> season = ("春", "夏", "秋", "冬")
>>>
>>> season
('春', '夏', '秋', '冬')
>>>
>>> season[0]
'春'
>>> season[1]
'夏'
>>> season[0] = "spring"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> tuple
<class 'tuple'>
>>> tuple(s)
(1, 4, 5, 6, 10, 12, 12334, 23, 56)
元组因为不可变,所以只有两个方法。
- index()
- count()
元组是不可变的,但是如果包含了可变对象,可变对象是可以变化的。
>>> t = (1,3,34,5,)
>>> t
(1, 3, 34, 5)
>>> t = (1,3,34,5, [1,3,4,5])
>>> t
(1, 3, 34, 5, [1, 3, 4, 5])
>>> t[4]
[1, 3, 4, 5]
>>> t[4].append(10)
>>> t
(1, 3, 34, 5, [1, 3, 4, 5, 10])
作业
- 输入一个大于0的正整数n,如果n == 1 ,则返回1, 如果n是偶数,则返回 n // 2 ,如果n是奇数,则返回 3n + 1,将所有的返回值存放到一个列表中,注意:n是第一个元素,其他的元素根据上述要求生成。最后求返回的列表和列表长度。
- 猜拳游戏:石头、剪刀、布的游戏
- 求50~150之间的质数是那些?存储在列表中
- 打印输出标准水仙花数,输出这些水仙花数
- 验证:任意一个大于9的整数减去它的各位数字之和所得的差,一定能被9整除.
- 一个五位数,若在它的后面写上一个7,得到一个六位数A,
若在它前面写上一个7,得到一个六位数B,B是A的五倍,求此
五位数. - 有一堆硬币,每次只能拿一个或者两个,求最少多少次可以拿完硬币
[10, 8, 5, 3, 27, 99] - 如果两个素数之差为2,这样的两个素数就叫作"孪生数",找出100以内的所有"孪生数".
- 给定一个列表,求最大值(不能使用系统api),求最小值,求平均值、求和
- 将list中的重复数据去重,至少使用两种方案
- 如何将0-10随机存入列表中
字典dict
dict,字典,本质在底层和set一样,是一个哈希表。
set中的每一个元素是独立的数据,而字典是一个键值对。
所以字典类型可以看做一个kv键值对的二维表格。
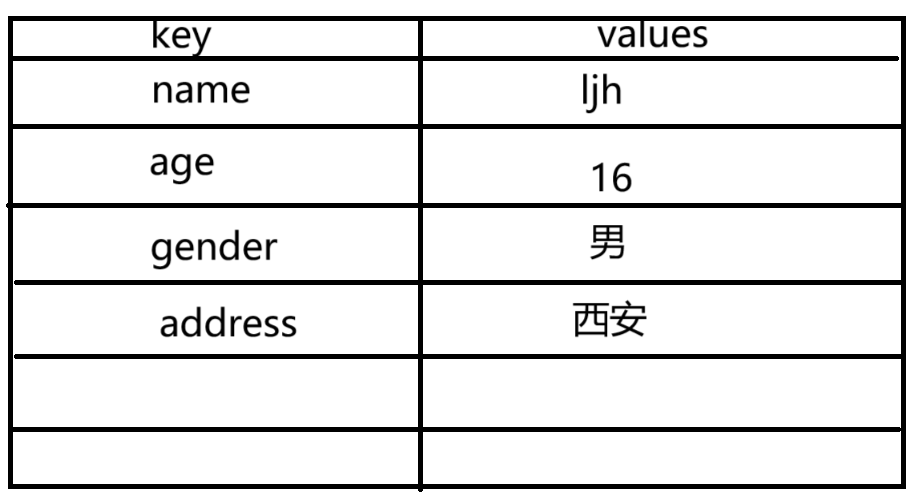
定义字典
d = {}
d = dict()
d = {"name": 'ljh', "age": 16, "gender": "男"}
d["key"] = value # 追加键值对到这个字典对象中
字典的常见操作
d = {}
d["name"] # error,因为没有这个key
# 如果key已经存在,相当于更新值,如果key不存在,则相当于添加键值对
d["name"] = “刘帅哥” # 添加一个键值对
d["age"] = 16
# 注意get方法
d.get("name") # 等价于 d["name"],注意两者的不同
print(d.get("aaa")) # None
print(None == d.get("aaa"))
# 键值对的个数
len(d)
字典常见方法
>>> dir(d)
['__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__ior__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__ror__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
- clear()
- copy()
- get(key)
- keys()
- values()
- items()
- pop(key) # 删除对应的键值对
- popitem() # 移除一个键值对,以LIFO的顺序
- update() # 合并字典
- setdefault() # 添加键值对
- fromkeys() # 注意,这个方法是一个静态方法,属于dict类,一般推荐dict.fromkeys(可迭代对象, 值)
字典的遍历
for key in d.keys():
print(key, d[key])
for key in d:
print(key, d.get(key))
for i in d.items():
print(i[0],i[1])
for (key, value) in d.items():
print(key, value)
for key, value in d.items():
for print(key, value)
注意:目前给大家讲解的内容都是一维结构讲解的,比如说,list是存在多维的结构的
二维数组
二维数组有横纵组成,所以会形成一个平面结构。
b = [[1,2,3,4], [2,3,4,5], [5,6,6,7]]
print(b[2][0]) # 5
多维数组
三位成像
图片在计算机看来,就是三位数组组成的,每一个图片的像素点有颜色组成(三原色恰好可以确定一个颜色),一张图片有横纵两个数组 + 颜色的一个数组,因此三维数组,就可以构成一张图片。
下面代码必须按照对应的库,在cmd中执行命令:
pip install numpy
pip install matplotlib
pip install pandas
成功后,执行下面代码:
# 多维数组
import matplotlib.pyplot as plt
import numpy as np
# 读取当前路径下的一张图片
cat = plt.imread("cat.jpg")
# 图片在计算机看来就是一个三位数组
# print(cat)
# 随机一个三位数组,第三维度的值有三个(正好是三原色)
data = np.random.randint(0, 255, size=(250, 400, 3))
print(data)
# 显示图片
plt.imshow(data)
plt.show()
作业:实现一个用户管理系统,实现用户的增删改查。
users = [{“name”: “ljh”, “password”: “12233”}, {“name”: “lisi”, “password”: “123445”}]
函数篇
什么是函数
函数(function):具有名称的功能代码的集合,被成为函数。
函数本质就是将一段功能代码封装起来,起一个名字,方便后面使用这个功能,直接通过名称调用这段代码,避免重复定义和重复书写相同的代码,也就是函数提高了代码的复用性,降低了代码的维护成本,提到代码的可读性。
函数是一个功能,一个行为动作!!
python中如何定义函数
使用关键字def ,本质是defined function 。
语法结构:
def 函数名称([args……]):
# 函数体
# [return 返回结果]
案例:
def f1():
"""
函数的注释和文档
"""
for _ in range(10):
print("hello")
# 调用函数
f1()
注意:在定义函数时,尽可能的将功能进行细化,这样函数的复用度会进一步的提高,可读性也会提高。
建议:函数中的函数体,代码行数尽可能的不要超过20行。
如果计算存在结果,建议一定返回这个返回值。
函数的分类
-
根据函数是否存在参数
- 有参函数
- 无参函数
-
根据函数是否存在返回值
- 有返回值
- 无返回值
-
根据函数的定义者
- 官方|系统 函数
- 自定义函数
- 第三方函数
def f1():
"""
函数的注释和文档
无参函数
没有返回值
"""
for _ in range(10):
print("hello")
# 调用函数
# f1()
# print(help(f1))
# __doc__ 属性是用来调用帮助文档的
print(f1.__doc__)
有参数,有返回值的函数:
def get_count(x, y):
"""
求两个数之和
x:第一个参数
y:第二个参数
return: x和y的和
"""
return x + y
# print(get_count(10, 8))
a = int(input("请输入第一个数:"))
b = int(input("请输入第二个数:"))
print(get_count(a, b))
注意:在python中,如果函数没有返回值,则表示返回None。
课堂练习: 使用函数,实现求100~200之间,所有的质数,返回这些质数。
# from typing import List, Set, Dict, Tuple
# def is_prime(num: int, a: List) -> float:
# def is_prime(num: int, a: list) -> None:
#课堂练习: 使用函数,实现求100~200之间,所有的质数,返回这些质数
def is_prime(num: int) -> bool:
if num <= 1: return False
"""判断一个数是否是质数"""
for i in range(2, num // 2 + 1):
if num % i == 0:
return False
return True
def range_is_prime(start: int, end: int) -> list:
res = []
for i in range(start, end + 1):
if is_prime(i):
res.append(i)
return res
print(range_is_prime(100, 200))
注意:python3.8提供了新特性,类型声明,需要注意的是,类型声明不强制,而是提高可读性的。
函数调用的内存分析
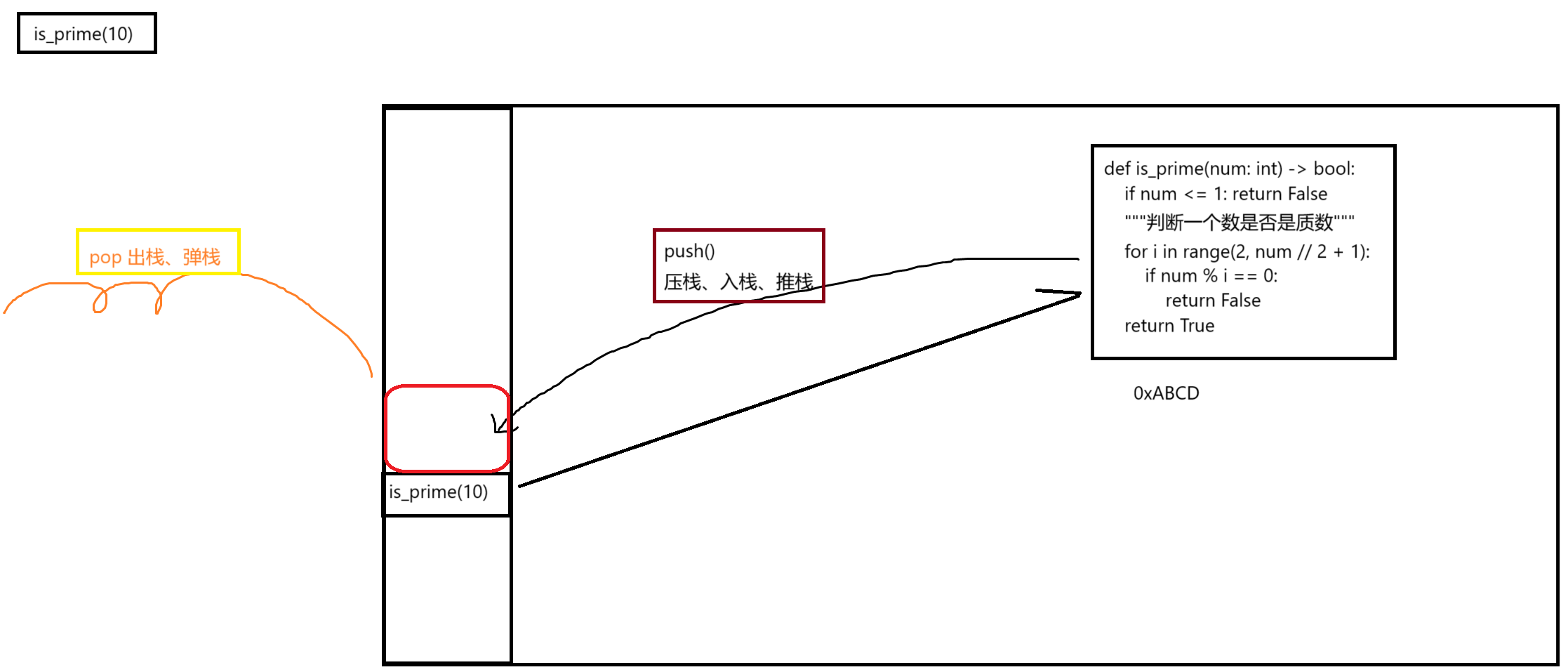
通过函数调用的内存分析,大家看出,函数调用是一个瞬时操作,从压栈到最后的弹栈,保证函数调用完成后,不会常驻栈内存。保证栈内存足够使用。
如果栈内存被大量占据,一旦被耗尽,则会触发栈溢出错误(Stack Overflow)
局部变量、全局变量
局部变量(local variable):又被成为本地变量,定义在函数中的变量就是局部变量,只能在函数中有效
全局变量(global variable):直接定义在模块中的变量
注意:python中,全局变量不允许在函数中修改!!
如果一定要在函数中修改全局变量,则必须提前声明!!!
# 全局变量
name = "刘帅哥"
age = 16
def show_info(gender: str, address: str) -> None:
# 在函数有效代码的第一行上,通过 global 变量 [, 变量2……]
global age
# a就是一个局部变量
a = 100
print(name)
print(age)
# print(a)
# a += 100
# print(a)
age += 1
print(age)
print(gender, address)
show_info("男", "陕西西安")
print(name)
引用传递和值传递
def f2(x, y):
print(x, y)
x = x + 100
y += 200
print(x, y)
# x = 10
# y = 20
# f2(x, y)
# # 思考下,为什么不会变化
# 拷贝的值
# print(x, y)
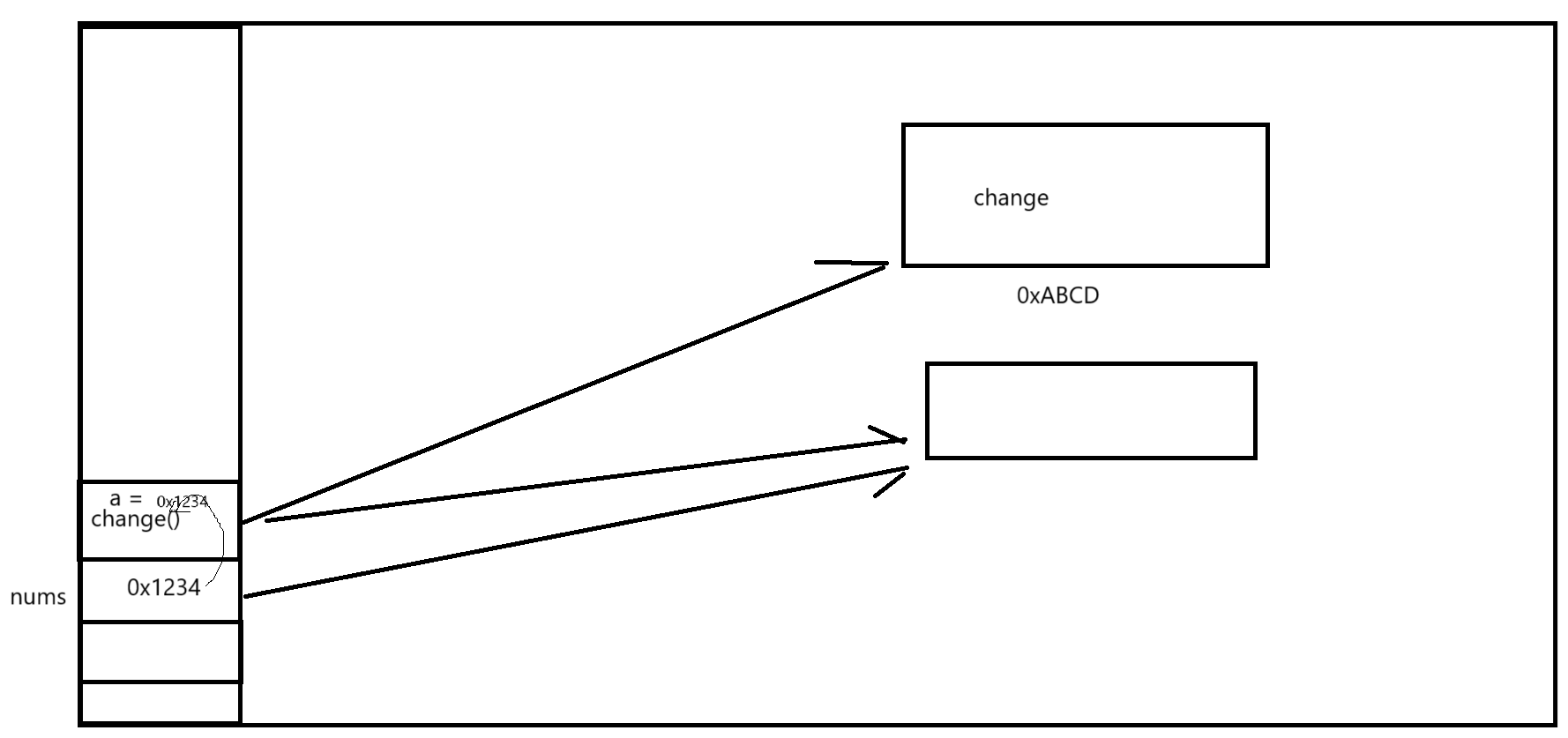
def change(a: list) -> None:
print(a)
a.append(1000)
print(a)
nums = [1, 2, 5, 53, 34, 4]
change(nums)
# 引用传递,也就是实质上,传递进去的是一个对象的内存地址
# 所以修改时,会修改地址指向的实际对象
print(nums)
函数参数问题
python中函数的参数有哪些类型
python中的函数参数,只要是对象就可以,任意即可。
python中函数也是一种对象。
注意:python中函数可以充当参数,传递到函数中!!!
def show_info(fn):
# python中,可以传递一个函数的引用到另个函数中
# 所以相当于将一个函数传递以参数的形式到另个函数中
print(fn)
# 函数调用
fn("hello world")
def print_msg(msg):
print(msg)
# print_msg("刘建宏你好")
show_info(print_msg)
python中的特殊参数
- 默认值参数
- 可变参数
- 关键字参数
默认值参数
def get_circle_area(r: float, PI=3.14) -> float:
"""
求圆的面积
默认值参数
"""
return r * r * PI
print(get_circle_area(4, 3.14))
print(get_circle_area(4, 3.1416))
print(get_circle_area(4, 3.1415927))
print(get_circle_area(4))
print(get_circle_area(5))
print(get_circle_area(6))
提高了调用函数的便捷程度。
注意:默认值参数,必须放在位置(普通)参数之后。
可变参数
在开发过程中,可能出现,多个参数,甚至出现参数完全不固定的情况。
因此python提供了可变参数,供开发者使用,该参数是一种特殊参数,可以接受任意多个数到一个参数中来。
实现语法非常简单,在参数前加上“*”。
如系统提供的print函数。
>>> help(print)
Help on built-in function print in module builtins:
print(*args, sep=' ', end='\n', file=None, flush=False)
Prints the values to a stream, or to sys.stdout by default.
sep
string inserted between values, default a space.
end
string appended after the last value, default a newline.
file
a file-like object (stream); defaults to the current sys.stdout.
flush
whether to forcibly flush the stream.
案例:
def get_circle_area(r: float, PI=3.14, *args) -> float:
"""
求圆的面积
默认值参数
args:就是一个可变参数,可以接受任意多个参数
注意:接受到的参数会默认封装在一个元组中
"""
# print(args)
if len(args) > 0:
print(args[0])
return r * r * PI
# 调用函数
print(get_circle_area(66, 3.14, 2))
print(get_circle_area(66, 3.14, 2,2,2,4,3,4, "刘帅哥", False, [1,2,3,3]))
注意:可变参数,可能被传递进来了值,也可能没有传递进来值,所以一定要判断可变参数中是否存在值,再去取。
注意:可变参数,也必须放在位置参数之后。
关键字参数
关键字参数,也叫做命名参数,也就是使用固定的名称,给函数传递值,就是关键字参数。
实现语法非常简单,在参数前加上“**”。
def get_circle_area(r: float, PI=3.14, *args, **kwargs) -> float:
"""
求圆的面积
默认值参数
args:就是一个可变参数,可以接受任意多个参数
注意:接受到的参数会默认封装在一个元组中
kwargs:就是关键字参数,将所有键值对传输进来的参数,使用kwargs进行封装
注意:封装的数据类型是字典dict
"""
if len(kwargs) > 0:
print(kwargs.get("name"))
print(kwargs.get("age"))
# print(args)
if len(args) > 0:
print(args[0])
return r * r * PI
# 调用函数
print(get_circle_area(4, 3.14, name="liujianhong"))
print(get_circle_area(4, 3.14, name="liujianhong", age=16))
lambda表达式和匿名函数
python中,常规情况下,无法书写匿名函数,所以python提供了lambda表达式,来实现匿名函数。
注意:匿名函数是简化函数的一种写法,主要存在函数作为参数传递到另一个函数中时。
lambda [参数列表……]: 函数体
案例:
def show_info(fn):
# python中,可以传递一个函数的引用到另个函数中
# 所以相当于将一个函数传递以参数的形式到另个函数中
print(fn)
# 函数调用
fn("hello world")
# def print_msg(msg):
# print(msg)
# print_msg("刘建宏你好")
# show_info(print_msg)
# lambda表达式,简化了129行的函数
show_info(lambdamsg: print(msg))
作业
-
求一个十进制的数值的二进制的0、1的个数
-
实现一个用户管理系统(要求使用容器保存数据)
[{name: xxx, pass: xxx, ……},{},{}] -
求1~100之间不能被3整除的数之和
-
给定一个正整数N,找出1到N(含)之间所有质数的总和
-
计算PI(公式如下:PI=4(1-1/3+1/5-1/7+1/9-1…)
-
给定一个10个元素的列表,请完成排序(注意,不要使用系统api)
-
求 a+aa+aaa+…+aaaaaaaaa=?其中a为1至9之中的一个数,项数也要可以指定。
-
合并两个有序数组,合并后还是有序列表
-
给定一个非负整数数组A,将该数组中的所有偶数都放在奇数元素之前
作业讲解
用户登录注册案例:
"""
实现一个控制台版本的用户管理系统
"""
import sys
users = []
def menu1():
print("~ * ~" * 15)
print("\t\t 1. 用户注册")
print("\t\t 2. 用户登录")
print("\t\t 3. 退出系统")
print("~ * ~" * 15)
def sys_exit():
confirm = input("您确定要退出系统吗?Y/y表示退出,其他任意键表示不退出。")
# 字符串对象的 upper() lower()
if confirm.lower() == "y":
sys.exit()
def reg_input():
username = input("请输入您的用户名称:")
password = input("请输入您的用户密码:")
confirm_password = input("请再次确认您的用户密码:")
# 注意:python中的函数,可以返回多个值
# 本质其实是包装成了一个元组(tuple)
return username, password, confirm_password
def exists_user(uname):
"""
uname:要判断是否存在的用户名称
功能:判断uname这个名称是否已经被注册
return: bool True:表示存在该用户,False:表示不存在
"""
for user in users:
if uname == user.get("username"):
return True
return False
def check_user_info(uname, upass, cpass):
# 验证数据
# 用户名不能为空
if uname == None or uname.strip() == "":
print("对不起,用户名称不能为空")
return False
# 校验用户是否存在
if exists_user(uname):
print("对不起,该用户已经存在,请重新填写")
return False
if len(upass) < 3:
print("对不起,用户密码长度太短,必须大于等于3位")
return False
if upass.strip() != cpass.strip():
print("两次密码不一致,请重新输入")
return False
return True
def login(uname, upass):
for user in users:
if uname == user.get("username") and upass == user.get("password"):
return True
else:
print("用户名称或者密码错误")
return False
while True:
menu1()
choice = input("请输入您的选择:")
if choice == "1":
while True:
# 注册
uname, upass, cpass = reg_input()
check_success = check_user_info(uname, upass, cpass)
if check_success:
# 保存用户
user = {"username": uname, "password": upass}
users.append(user)
print("恭喜您,注册成功!!!")
break
elif choice == '2':
while True:
username = input("请输入您的用户名称:")
password = input("请输入您的用户密码:")
succes = login(username, password)
if succes:
print("登录成功")
else:
confirm = input("是否继续登录?")
if confirm.upper() != "Y":
break
elif choice == '3':
sys_exit()
else:
sys_exit()
递归
递归是什么
递归(recursion):将复杂问题,划分为更小的多个相同问题的解法。表现形式是:在函数内部调用函数自身。
求0~100的和。
# 使用递归完成上面功能
def get_count(n):
"""
0~N = n + (n - 1) + (n - 2) + (n - 3) + (n - 4) + ... + 1 + 0
"""
if n == 0:
return 0
return n + get_count(n - 1)
递归的内存分析
通过内存分析,可以看出,递归的内存调用,是不断地调用自身的内存,这样情况下,所有的调用是无法被正常释放的。只能驻留在Stack中,直到递归调用结束。
因此递归算法虽然非常好用,但是往往耗费的栈内存较多,因此注意这种情况。
递归很容易除非一个错误:“栈溢出错误(Stack overflow)”。
注意:python默认只允许,递归1000次,超过会自动抛出错误。
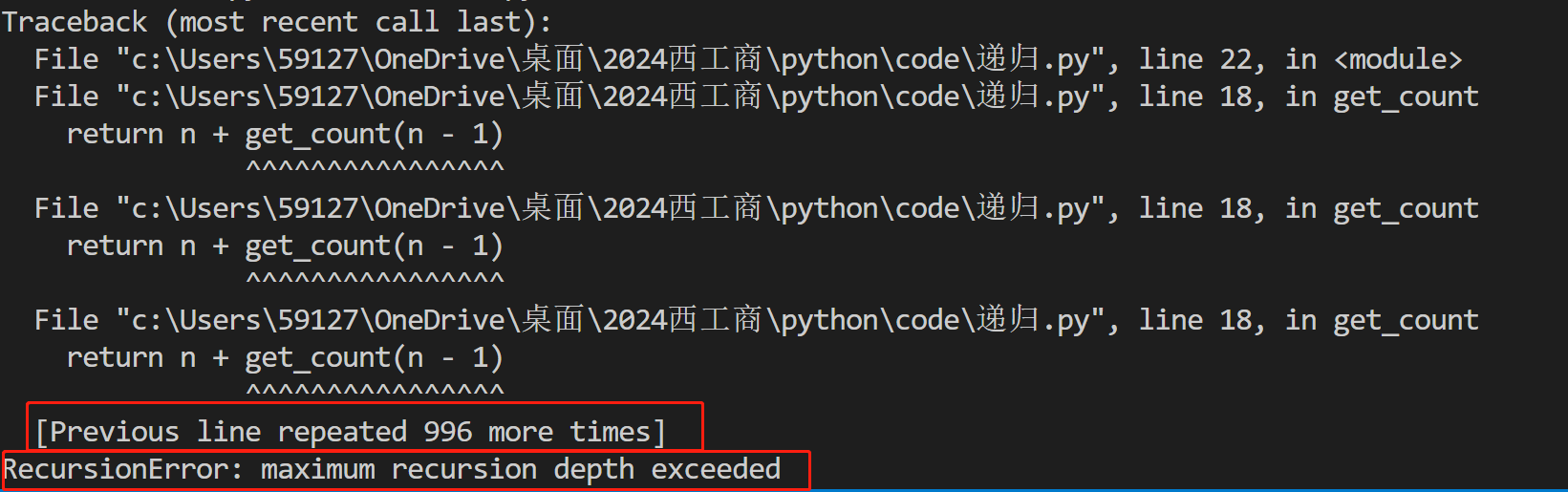
去掉递归结束条件,运行得到。
如何解除递归的层数限制:
>>> import sys
>>>
>>> dir(sys)
['__breakpointhook__', '__displayhook__', '__doc__', '__excepthook__', '__interactivehook__', '__loader__', '__name__', '__package__', '__spec__', '__stderr__', '__stdin__', '__stdout__', '__unraisablehook__', '_base_executable', '_clear_type_cache', '_current_exceptions', '_current_frames', '_debugmallocstats', '_enablelegacywindowsfsencoding', '_framework', '_getframe', '_getquickenedcount', '_git', '_home', '_stdlib_dir', '_vpath', '_xoptions', 'addaudithook', 'api_version', 'argv', 'audit', 'base_exec_prefix', 'base_prefix', 'breakpointhook', 'builtin_module_names', 'byteorder', 'call_tracing', 'copyright', 'displayhook', 'dllhandle', 'dont_write_bytecode', 'exc_info', 'excepthook', 'exception', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'get_asyncgen_hooks', 'get_coroutine_origin_tracking_depth', 'get_int_max_str_digits', 'getallocatedblocks', 'getdefaultencoding', 'getfilesystemencodeerrors', 'getfilesystemencoding', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettrace', 'getwindowsversion', 'hash_info', 'hexversion', 'implementation', 'int_info', 'intern', 'is_finalizing', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'orig_argv', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'platlibdir', 'prefix', 'ps1', 'ps2', 'pycache_prefix', 'set_asyncgen_hooks', 'set_coroutine_origin_tracking_depth', 'set_int_max_str_digits', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdlib_module_names', 'stdout', 'thread_info', 'unraisablehook', 'version', 'version_info', 'warnoptions', 'winver']
>>>
>>> sys.getrecursionlimit()
1000
>>> sys.setrecursionlimit(2000)
递归案例
案例:
import sys
# 将递归的层数限制设置为2000
sys.setrecursionlimit(2000)
"""
求 0~N的和
"""
def sum_n(n):
result = 0
for i in range(n + 1):
result += i
return result
# 使用递归完成上面功能
def get_count(n):
"""
0~N = n + (n - 1) + (n - 2) + (n - 3) + (n - 4) + ... + 1 + 0
"""
if n == 0:
return 0
return n + get_count(n - 1)
# print(sum_n(100))
print(get_count(1996))
课堂练习:有个人上楼梯,一次只能上一个或者两个台阶,问,当他到达第N个台阶的时,共有多少种走法。
# 上楼梯问题
def get_step_count(n):
"""
递归解决上楼梯问题
"""
if n == 1 or n == 2:
return n
return get_step_count(n - 1) + get_step_count(n - 2)
print(get_step_count(1))
print(get_step_count(2))
print(get_step_count(3))
print(get_step_count(4))
print(get_step_count(10))
print(get_step_count(20))
斐波那契数列:
输入一个N(n ≥ 1,n ∈ N*),求第N项的斐波那契数列值。
# 斐波那契数列使用循环完成
def fibonacii(n):
first, second = 0, 1
if n < 3:
return n - 1
for _ in range(3, n + 1):
first, second = second, first + second
return second
def fibonacii_recursion(n):
if n == 1:
return 0
if n == 2:
return 1
return fibonacii_recursion(n - 2) + fibonacii_recursion(n - 1)
# print(fibonacii(1))
# print(fibonacii(2))
# print(fibonacii(3))
# print(fibonacii(4))
# print(fibonacii(5))
# print(fibonacii(6))
# print(fibonacii(7))
# print(fibonacii(8))
print(fibonacii_recursion(8))
课堂案例练习:小明高考非常好,所以父母决定奖励她,为她购买了一对刚刚出生的兔子(一公一母)。小明发现兔子需要四个月长成成年兔子,成年的一对兔子会开始生孩子,假设,每一个只生一对(一公一母)兔子。问第N月时,小明共有多少对兔子,注意:不考虑兔子死亡问题。
字符串对象
python的数据类型(data type)。当时说了,字符串是一种python的基本数据类型。
s = 'this is a string'
ss = "this is a string"
sss = """this is a string"""
ssss = '''
这个可以换行
所以常见于复杂字符串的处理
'''
# 下标来访问字符串中元素
print(s[0])
print(s[1])
print(s[len(s) - 1])
# len
print(len(s))
# 遍历
for i in s:
print(i)
i = 0
while i < len(i):
print(s[i])
i += 1
python面向对象的编程语言,在面向对象的编程语言中,所有的数据类型,本质都是对象,包括基本数据类型。python的字符串即是基本数据类型,方便我们直接进行操作。同时也是一种对象。
所以我们要来看一看,字符串对象的一些知识。
重点当然是字符串对象中的各种属性和方法。
>> dir(s)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__',
'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill'
]
>>>
>>> len(s)
16
>>>
>>>
>>> s.__len__()
16
>>> s.__doc__
"str(object='') -> str\nstr(bytes_or_buffer[, encoding[, errors]]) -> str\n\nCreate a new string object from the given object. If encoding or\nerrors is specified, then the object must expose a data buffer\nthat will be decoded using the given encoding and error handler.\nOtherwise, returns the result of object.__str__() (if defined)\nor repr(object).\nencoding defaults to sys.getdefaultencoding().\nerrors defaults to 'strict'."
>>>
-
center()
-
rjust()
-
ljust()
-
startswith()
-
endswith()
-
find()
-
index()
-
rfind()
-
rindex()
-
format()
-
isxxx 都是判断字符串是否某种规则
-
upper()
-
lower()
-
strip()
-
lstrip()
-
rstrip()
-
removeprefix()
-
removesuffix()
-
replace()
-
join() #
-
split()
-
encode #
-
decode() # 字节对象的方法
-
translate
-
maketrans
name = "刘建宏"
age = 16
s = "this is a string, 他叫{}, 他今年{}岁了"
print(s.format(name, age))
print("Liu Jianhong".upper())
print("Liu Jianhong".lower())
print("Liu Jianhong".capitalize())
print("Liu Jianhong".title())
作业
-
求第n项的斐波那契数列值
-
青蛙跳楼梯,每一次只能跳一个台阶或者两个台阶,注意,不允许倒退,
如果第N个台阶,请问有多少种跳法: -
小明高考结束,成绩非常理想,父母为了奖励他,为他买了一对刚刚出生的兔子,
刚刚出生的兔子经过4个月成长为成年的兔子,就可以生小兔子,
假设成年兔子每月出生一对小兔子,问,第N月,共有多少对兔子,
假设所有不会死亡。 -
找出10000以内能被5或6整除,但不能被两者同时整除的数(函数)
-
写一个方法,计算列表所有偶数下标元素的和(注意返回值)根据完整的路径从路径中分离文件路径、文件名及扩展名
-
根据标点符号对字符串进行分行
-
去掉字符串数组中每个字符串的空格
-
随意输入你心中想到的一个书名,然后输出它的字符串长度。 (len()属性:可以得字符串的长度)
-
两个学员输入各自最喜欢的游戏名称,判断是否一致,如
果相等,则输出你们俩喜欢相同的游戏;如果不相同,则输
出你们俩喜欢不相同的游戏。 -
上题中两位同学输入 lol和 LOL代表同一游戏,怎么办?
-
让用户输入一个日期格式如“2008/08/08”,将 输入的日
期格式转换为“2008年-8月-8日”。 -
接收用户输入的字符串,将其中的字符进行排序(升
序),并以逆序的顺序输出,“cabed”→"abcde"→“edcba”。 -
接收用户输入的一句英文,将其中的单词以反序输
出,“hello c sharp”→“sharp c hello”。 -
从请求地址中提取出用户名和域名
http://www.163.com?userName=admin&pwd=123456 -
有个字符串数组,存储了10个书名,书名有长有短,现
在将他们统一处理,若书名长度大于10,则截取长度8的
子串并且最后添加“…”,加一个竖线后输出作者的名字。 -
让用户输入一句话,找出所有"呵"的位置。
-
让用户输入一句话,判断这句话中有没有邪恶,如果有邪
恶就替换成这种形式然后输出,如:“老牛很邪恶”,输出后变
成”老牛很**”; -
如何判断一个字符串是否为另一个字符串的子串
find() index()
双层循环完成
?? -
如何验证一个字符串中的每一个字符均在另一个字符串中出现过
-
如何随机生成无数字的全字母的字符串
-
如何随机生成带数字和字母的字符串
-
判断一个字符是否是回文字符串(面试题)
“1234567654321”
“上海自来水来自海上”
作业(选做题):
某个人进入如下一个棋盘中,要求从左上角开始走,
最后从右下角出来(要求只能前进,不能后退),
问题:共有多少种走法?
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
切片
切片,python提供一种技术,是python提供出来,用来切割有序序列(sorted sequence)的一种手段。
之前我们学习的list、tuple、str都是有序序列。
切片本质是利用有序序列的下标(角标)来对有序序列,进行切割,并且会返回需要的内容区域。
语法结构:
# 表示获取对应角标的元素
sequence[下标]
# 获取一段元素
sequence[start:end] # 从start开始,到end结束,这个区间是一个前闭后开的区间
# 也可以给切片设置步长step
sequence[start:end:step] # 第三个值,表示步长,默认步长是1
案例使用:
>>> names
['张三', '李四', '王五', '赵六', '钱七', '王婆', '武松']
>>> s
'this is a str'
>>>
season = ("spring", "summer", "autumn", "winter")
>>> s
>>> names
>>> season
('spring', 'summer', 'autumn', 'winter')
>>>
>>> s[0]
't'
>>> s[10]
's'
>>> s[8]
'a'
>>> names[0]
'张三'
>>> names[5]
'王婆'
>>>
>>> season[2]
'autumn'
>>>
>>> s
'this is a str'
>>>
>>>
>>>
>>> s[1:]
'his is a str'
>>> s[:5]
'this '
>>> s[2:9]
'is is a'
>>> s[:5:1]
'this '
>>> s[2:9:1]
'is is a'
>>>
>>> names[:10:1]
['张三', '李四', '王五', '赵六', '钱七', '王婆', '武松']
>>>
>>>
>>> names[::1]
['张三', '李四', '王五', '赵六', '钱七', '王婆', '武松']
>>> names[::2]
['张三', '王五', '钱七', '武松']
>>>
>>> names
['张三', '李四', '王五', '赵六', '钱七', '王婆', '武松']
>>>
>>> names.reverse()
>>> names
['武松', '王婆', '钱七', '赵六', '王五', '李四', '张三']
>>>
>>> names[::-1]
['张三', '李四', '王五', '赵六', '钱七', '王婆', '武松']
>>>
补充知识:python是支持负索引的!!!!
注意:负索引和切片没有关系,只是我们在这儿给大家讲解。
之前使用索引都是正索引,从0开始~到N结束,每次加一,适合于,较小的数据,这样非常方便。
但是开发中,往往会遇到较大数据,此时如果从做开始计算索引,就非常复杂,从右开始,较为简单,因此就有了负索引。
注意:负索引是从右向左算,第一个值,默认是-1,第二个值是-2,依次类推。
>>> names
['武松', '王婆', '钱七', '赵六', '王五', '李四', '张三']
>>>
>>> names[-2]
'李四'
>>> names[-3]
'王五'
>>> s
'this is a str'
>>>
>>> s[-1]
'r'
>>> s[-2]
't'
>>> s
'this is a str'
>>>
>>>
>>> s[10:]
'str'
>>>
>>>
>>> s[-3:]
'str'
>>>
>>> s[-3:-5]
''
>>> s[-3:-5:-1]
's '
>>>
切片是基于索引进行设计的,所以,切片也支持负索引的使用。
课堂案例练习:写一个方法,计算列表所有偶数下标元素的和(注意返回值)根据完整的路径从路径中分离文件路径、文件名及扩展名 。
p = D:\videos\python\9.11西工商\35_第六章_字符串和字节的转换.mp4
排序和查找
排列算法
为了方便快速查找数据,使用相关的查找算法(如二分等),所以,我们在查找前,希望将数据排列成有序数据。
常见的排序算法非常多,大概有十几种。
其中存在三种,是基础的查询方式,时间复杂度是O(n^2),也就是平方阶的时间复杂度。
- 冒泡排序
- 选择排序
- 插入排序
冒泡排序
计算机每次会获取一个最小值(也可以是最大值),两两比较,查找两个数中间的最大值,如果两个数已经是从小到大,则不用动,否则交互这两个数。之后进行下一个数。
arr = [1, 3, 2, 8, -2, 10, -50, 80, 4]
默认数据的顺序: [1, 3, 2, 8, -2, 10, -50, 80, 4]
第一趟: [1, 2, 3, -2, 8, -50, 10, 4, 80]
第二趟: [1, 2, -2, 3, -50, 8, 4, 10, 80]
……
案例:
from typing import List
def bubble_sort(arr: List[int]) -> None:
"""
冒泡算法
"""
# 需要查找多少次最大值
for i in range(len(arr) - 1):
# 一趟中的数据两两比较,查找最大值
for j in range(len(arr) - 1 - i):
# 进行两两比较
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
if __name__ == "__main__":
arr = [1, 3, 2, 8, -2, 10, -50, 80, 4]
print(f"排序前,arr = {arr}")
bubble_sort(arr)
print(f"排序后,arr = {arr}")
选择排序
选择排序,和冒泡排序有点类似,假设第一个值是最大值(或者最小值),之后查找,找到真正的最大值或者最小值,将这两个数交互。
arr = [1, 3, 2, 8, -2, 10, -50, 80, 4]
默认数据的顺序: [1, 3, 2, 8, -2, 10, -50, 80, 4]
第一趟: [-50, 3, 2, 8, -2, 10, 1, 80, 4]
第二趟: [-50, -2, 2, 8, 3, 10, 1, 80, 4]
……
代码案例:
from typing import List
def bubble_sort(arr: List[int]) -> None:
"""
冒泡算法
"""
# 需要查找多少次最大值
for i in range(len(arr) - 1):
# 一趟中的数据两两比较,查找最大值
for j in range(len(arr) - 1 - i):
# 进行两两比较
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
def select_sort(arr: list[int]) -> None:
"""
选择排序,习惯性,假设第一个值是最小值
"""
for i in range(len(arr) - 1):
# 假设第一个值是最小值
min_index = i
for j in range(i + 1, len(arr)):
if arr[min_index] > arr[j]:
min_index = j
# 交互两个值
if min_index != i:
arr[min_index], arr[i] = arr[i], arr[min_index]
def select_sort2(arr: list[int]) -> None:
"""
选择排序,习惯性,假设第一个值是最小值
"""
for i in range(len(arr) - 1):
for j in range(i + 1, len(arr)):
if arr[i] > arr[j]:
arr[j], arr[i] = arr[i], arr[j]
if __name__ == "__main__":
arr = [1, 3, 2, 8, -2, 10, -50, 80, 4]
print(f"排序前,arr = {arr}")
# bubble_sort(arr)
# select_sort(arr)
select_sort2(arr)
print(f"排序后,arr = {arr}")
插入排序
所谓插入排序,就是保证在数据有序的情况下,将一个一个值,依次插入到有序的数据中,注意:每次插入时,必须保证插入后的数据继续有序。如手中拿着扑克,将多拿到一张牌,继续让手中的牌有序。
arr = [1, 3, 2, 8, -2, 10, -50, 80, 4]
默认数据的顺序: [1, 3, 2, 8, -2, 10, -50, 80, 4]
第一趟: [1, 3, 2, 8, -2, 10, -50, 80, 4]
第二趟: [1, 2, 3, 8, -2, 10, -50, 80, 4]
……
from typing import List
def bubble_sort(arr: List[int]) -> None:
"""
冒泡算法
"""
# 需要查找多少次最大值
for i in range(len(arr) - 1):
# 一趟中的数据两两比较,查找最大值
for j in range(len(arr) - 1 - i):
# 进行两两比较
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
def select_sort(arr: list[int]) -> None:
"""
选择排序,习惯性,假设第一个值是最小值
"""
for i in range(len(arr) - 1):
# 假设第一个值是最小值
min_index = i
for j in range(i + 1, len(arr)):
if arr[min_index] > arr[j]:
min_index = j
# 交互两个值
if min_index != i:
arr[min_index], arr[i] = arr[i], arr[min_index]
def select_sort2(arr: list[int]) -> None:
"""
选择排序,习惯性,假设第一个值是最小值
"""
for i in range(len(arr) - 1):
for j in range(i + 1, len(arr)):
if arr[i] > arr[j]:
arr[j], arr[i] = arr[i], arr[j]
def insert_sort(arr: list[int]) -> None:
"""
插入排序
"""
for i in range(len(arr) - 1):
for j in range(i + 1, 0, -1):
if arr[j] < arr[j - 1]:
arr[j], arr[j - 1] = arr[j - 1], arr[j]
if __name__ == "__main__":
arr = [1, 3, 2, 8, -2, 10, -50, 80, 4]
print(f"排序前,arr = {arr}")
# bubble_sort(arr)
# select_sort(arr)
# select_sort2(arr)
insert_sort(arr)
print(f"排序后,arr = {arr}")
内容回顾
- 字符串对象
- 切片
- 常见的排序算法
查找算法
将数据排序(数据有序)的目的,就是为了加快数据的检索速度。
二分查找算法
二分查找,又被称为折半查找算法。这种算法的典型特点,就是每次查询有序数据中间点,数据的中间点和目标数据进行对比,如果中间点数据大于了目标,所以证明数据在前面一半数据中,此时,就可以去除后面的一半数据。
二分查找的时间复杂度是O(logN)。
from typing import List
def bubble_sort(arr: List[int]) -> None:
"""
冒泡算法
"""
# 需要查找多少次最大值
for i in range(len(arr) - 1):
# 一趟中的数据两两比较,查找最大值
for j in range(len(arr) - 1 - i):
# 进行两两比较
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
def select_sort(arr: list[int]) -> None:
"""
选择排序,习惯性,假设第一个值是最小值
"""
for i in range(len(arr) - 1):
# 假设第一个值是最小值
min_index = i
for j in range(i + 1, len(arr)):
if arr[min_index] > arr[j]:
min_index = j
# 交互两个值
if min_index != i:
arr[min_index], arr[i] = arr[i], arr[min_index]
def select_sort2(arr: list[int]) -> None:
"""
选择排序,习惯性,假设第一个值是最小值
"""
for i in range(len(arr) - 1):
for j in range(i + 1, len(arr)):
if arr[i] > arr[j]:
arr[j], arr[i] = arr[i], arr[j]
def insert_sort(arr: list[int]) -> None:
"""
插入排序
"""
for i in range(len(arr) - 1):
for j in range(i + 1, 0, -1):
if arr[j] < arr[j - 1]:
arr[j], arr[j - 1] = arr[j - 1], arr[j]
def binary_search(arr: list[int], target: int) -> int:
"""
二分查找
"""
left, right = 0, len(arr) - 1
while left <= right:
middle = (left + right) // 2
if arr[middle] > target:
# left部分
right = middle - 1
elif arr[middle] < target:
left = middle + 1
else:
return middle
# 表示查询的数据不存在
return -1
def binary_search_recusion(arr: list[int], target: int, left: int, right: int):
"""
使用递归实现二分查找
"""
if left <= right:
middle = (left + right) // 2
if arr[middle] > target:
return binary_search_recusion(arr, target, left, middle - 1)
elif arr[middle] < target:
return binary_search_recusion(arr, target, middle + 1, right)
return middle
return -1
if __name__ == "__main__":
arr = [1, 3, 2, 8, -2, 10, -50, 80, 4]
print(f"排序前,arr = {arr}")
# bubble_sort(arr)
# select_sort(arr)
# select_sort2(arr)
insert_sort(arr)
print(f"排序后,arr = {arr}")
# 二分查找
# 查询对应数据的下标
target = 2
# index = binary_search(arr, target)
index = binary_search_recusion(arr, target, 0, len(arr) - 1)
print(f"{target}这个数,在数组的{index}位置")
全局函数
python的官方,为开发者提供很多全局函数,这些函数默认被加载在全局中,直接可以使用,不需要导入任何包。如:print、input、type、max、min、sum、list、set、tuple、dict、int、float、str ……
如何查看这些全局函数。
需要导入builtins模块。
>>> import builtins
>>>
>>>
>>>
>>> dir(builtins)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BaseExceptionGroup', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EncodingWarning', 'EnvironmentError', 'Exception', 'ExceptionGroup', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'aiter', 'all', 'anext', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
内建模块,主要提供了三大类型的API
- 内建全局异常类
- 魔法属性或者方法
- 全局函数
这儿我们重点关注的是全局函数:
['abs', 'aiter', 'all', 'anext', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
- abs
- all
- any
- ascii
- bin
- oct
- hex
- bool
- str
- list
- set
- tuple
- dict
- int
- float
- complex
- bytes
- enumerate
- min
- max
- sum
- pow
- reversed
- sorted
- filter
- map
- reduce【注意:reduce不在全局函数中】
filter:过滤
>>> filter(lambda x: if x > 0, ls)
File "<stdin>", line 1
filter(lambda x: if x > 0, ls)
^^
SyntaxError: invalid syntax
>>>
>>> filter(lambda x: x > 0, ls)
<filter object at 0x0000021F4C794F70>
>>>
>>>
>>> res = filter(lambda x: x > 0, ls)
>>>
>>>
>>> for i in res:
... print(i)
...
1
2
5
3
4
33
18
map:映射
>>> ls
[1, 2, 5, 3, 4, 33, 18, -5]
>>>
>>>
>>> map(lambda x: x**2, ls)
<map object at 0x0000021F4CD83E50>
>>>
>>> res = map(lambda x: x**2, ls)
>>> for i in res:
... print(i)
...
1
4
25
9
16
1089
324
25
>>>
>>> map(lambda x: int(x), input().split())
1 2 3 4 45
<map object at 0x0000021F4C7950F0>
>>> a = map(lambda x: int(x), input().split())
>>> for i in a:
... print(i)
...
>>>
>>>
>>>
>>> a = map(lambda x: int(x), input().split())
1 23 3 4 4 5 6
>>>
>>> for i in a:
... print(i)
...
1
23
3
4
4
5
6
>>> a = map(int, input().split())
reduce函数,不是全局函数,这个在functools中存在这个函数。使用是需要导入:
import functools
functools.reduce()
import functools.reduce
functools.reduce()
不推荐上面这种导入,如果像上面这种比较长,单词比较复杂,可以使用别名(alias):
import functools.reduce as reduce
reduce()
如果导入的是多级,可以分开导入,这种方式推荐使用:
from functools import reduce
reduce()
>>> from functools import reduce
>>>
>>>
>>> help(reduce)
Help on built-in function reduce in module _functools:
reduce(...)
reduce(function, iterable[, initial]) -> value
Apply a function of two arguments cumulatively to the items of a sequence
or iterable, from left to right, so as to reduce the iterable to a single
value. For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates
((((1+2)+3)+4)+5). If initial is present, it is placed before the items
of the iterable in the calculation, and serves as a default when the
iterable is empty
>> sum(ls)
61
>>> s = 0
>>> for i in ls:
... s + i
...
1
2
5
3
4
33
18
-5
>>> for i in ls:
... s +=i
...
>>> s
61
>>>
>>> reduce(lambda x, y: x + y, ls)
61
>>> reduce(lambda x, y: x * y, ls)
-356400
>>> reduce(lambda x, y: x // 2 * y, ls)
0
>>>
模块篇
模块(module):模块化的概念,常规情况下,我们可以这样理解:xxx.py就是一个模块,如果要使用这个py文件中的函数、方法、类、变量等等,就需要将,这个py看做一个完整的模块,导入import、from等关键字导入,这样其他模块中就可以使用导入的模块。
包(package): 简单理解,就是用来管理模块的文件夹(目录)。
注意:目录可以直接当做包使用
但是包不一定是一个普通的目录
真正的包里面存在一个初始化模块(__init__.py),该模块在导入这个包时候,会自动执行。
import xx
import xxx.xx.xx
import xx as alias
import xxx.xx.xx as alias
from xxx import xxx
from xxx import xxx alias
from xxx import *
内置模块
内置模块(内建模块),指的就是有python官方提供的一些基础模块,这些模块不需要下载,直接导入就可以使用。
常见的内置模块:
- random
- os
- sys
- functools
- math
- uuid
- hashlib
- time
- datetime
- calendar
- ……
math模块
该模块是数学运算相关的模块,提供大量跟数学运算相关的函数。
>>> import math
>>> dir(math)
['__doc__', '__loader__', '__name__', '__package__', '__spec__', 'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'cbrt', 'ceil', 'comb', 'copysign', 'cos', 'cosh', 'degrees', 'dist', 'e', 'erf', 'erfc', 'exp', 'exp2', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf', 'isnan', 'isqrt', 'lcm', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2', 'modf', 'nan', 'nextafter', 'perm', 'pi', 'pow', 'prod', 'radians', 'remainder', 'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc', 'ulp']
>>> math.ceil(3.9999999)
4
>>> math.floor(3.9999999)
3
4
5
>>> math.sin(30)
>>> help(math.radians)
radians(x, /)
Convert angle x from degrees to radians.
>>> math.radians(90)
1.5707963267948966
>>> math.radians(58)
1.0122909661567112
>>>
>>>
>>> math.sin(math.radians(30))
0.49999999999999994
>>> math.pi
3.141592653589793
>>> math.e
2.718281828459045
>>>
>>> math.isnan(10)
False
>>>
>>> math.isnan(math.nan)
random模块
random是随机数模块,注意:计算机都是伪随机数。
随机数在其他编程语言中,一般在数学相关的里面,但是python,直接独立出来,为开发者提供了大量好用的随机数方法。
核心方法:random.random() 会随机一个[0, 1) 的区间随机数。
>>> import random as rm
>>> dir(rm)
['BPF', 'LOG4', 'NV_MAGICCONST', 'RECIP_BPF', 'Random', 'SG_MAGICCONST', 'SystemRandom', 'TWOPI', '_ONE', '_Sequence', '_Set', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_accumulate', '_acos', '_bisect', '_ceil', '_cos', '_e', '_exp', '_floor', '_index', '_inst', '_isfinite', '_log', '_os', '_pi', '_random', '_repeat', '_sha512', '_sin', '_sqrt', '_test', '_test_generator', '_urandom', '_warn', 'betavariate', 'choice', 'choices', 'expovariate', 'gammavariate', 'gauss', 'getrandbits', 'getstate', 'lognormvariate', 'normalvariate', 'paretovariate', 'randbytes', 'randint', 'random', 'randrange', 'sample', 'seed', 'setstate', 'shuffle', 'triangular', 'uniform', 'vonmisesvariate', 'weibullvariate']
>>> rm.random()
>>> rm.random() * 10
3.590536762311781
>>>
>>> math.floor(rm.random() * 10)
0
>>> math.floor(rm.random() * 10)
1
>>> math.floor(rm.random() * 10)
>>> rm.randint(0, 10)
>>> rm.randint(0, 10)
>>> rm.randrange(20, 40)
>>> rm.randrange(20, 40)
>>> rm.uniform(20, 40)
31.348389522930397
>>> rm.uniform(20, 40)
30.18948257648136
>>>
>>> help(rm.randint)
Help on method randint in module random:
randint(a, b) method of random.Random instance
Return random integer in range [a, b], including both end points.
>>> help(rm.randrange)
Help on method randrange in module random:
randrange(start, stop=None, step=1) method of random.Random instance
Choose a random item from range(stop) or range(start, stop[, step]).
Roughly equivalent to ``choice(range(start, stop, step))`` but
supports arbitrarily large ranges and is optimized for common cases.
>>> rm.randrange(0, 1)
0
>>> nums = ["林黛玉", "贾迎春", "贾惜春", "贾探春"]
>>> names = ["林黛玉", "贾迎春", "贾惜春", "贾探春"]
>>>
>>> names
['林黛玉', '贾迎春', '贾惜春', '贾探春']
>>>
>>> rm.choices(names)
['贾探春']
>>> rm.choices(names)
['贾迎春']
>>> rm.choices(names)
['贾迎春']
>>> rm.choices(names)
['贾探春']
>>> rm.choice(names)
'林黛玉'
>>>
>>> names
['林黛玉', '贾迎春', '贾惜春', '贾探春']
>>>
>>> rm.shuffle(names)
>>> names
['贾探春', '贾迎春', '林黛玉', '贾惜春']
OS模块
os模块:操作系统,准确来说,该模块主要用来操作操作系统的文件系统。
>>> import os
>>>
>>>
>>> help(os)
Help on module os:
NAME
os - OS routines for NT or Posix depending on what system we're on.
The following documentation is automatically generated from the Python
source files. It may be incomplete, incorrect or include features that
are considered implementation detail and may vary between Python
implementations. When in doubt, consult the module reference at the
location listed above.
DESCRIPTION
This exports:
- all functions from posix or nt, e.g. unlink, stat, etc.
- os.path is either posixpath or ntpath
- os.name is either 'posix' or 'nt'
- os.curdir is a string representing the current directory (always '.')
- os.pardir is a string representing the parent directory (always '..')
- os.sep is the (or a most common) pathname separator ('/' or '\\')
- os.extsep is the extension separator (always '.')
- os.altsep is the alternate pathname separator (None or '/')
- os.pathsep is the component separator used in $PATH etc
- os.linesep is the line separator in text files ('\r' or '\n' or '\r\n')
- os.defpath is the default search path for executables
- os.devnull is the file path of the null device ('/dev/null', etc.)
Programs that import and use 'os' stand a better chance of being
portable between different platforms. Of course, they must then
only use functions that are defined by all platforms (e.g., unlink
and opendir), and leave all pathname manipulation to os.path
<module 'ntpath' (frozen)>
>>> path
<module 'ntpath' (frozen)>
>>>
['_LCMAP_LOWERCASE', '_LCMapStringEx', '_LOCALE_NAME_INVARIANT', '__all__', '__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_abspath_fallback', '_get_bothseps', '_getfinalpathname', '_getfinalpathname_nonstrict', '_getfullpathname', '_getvolumepathname', '_nt_readlink', '_path_normpath', '_readlink_deep', 'abspath', 'altsep', 'basename', 'commonpath', 'commonprefix', 'curdir', 'defpath', 'devnull', 'dirname', 'exists', 'expanduser', 'expandvars', 'extsep', 'genericpath', 'getatime', 'getctime', 'getmtime', 'getsize', 'isabs', 'isdir', 'isfile', 'islink', 'ismount', 'join', 'lexists', 'normcase', 'normpath', 'os', 'pardir', 'pathsep', 'realpath', 'relpath', 'samefile', 'sameopenfile', 'samestat', 'sep', 'split', 'splitdrive', 'splitext', 'stat', 'supports_unicode_filenames', 'sys']
>>>
>>> os.curdir
'.'
>>> path.abspath(os.curdir)
'C:\\Users\\59127'
>>> os.chdir("c:/")
>>>
>>> os.curdir
'.'
>>>
>>>
>>> path.abspath(os.curdir)
'c:\\'
>>>
>>> os.name
'nt'
<module 'ntpath' (frozen)>
>>> path
<module 'ntpath' (frozen)>
>>>
, 'expandvars', 'extsep', 'genericpath', 'getatime', 'getctime', 'getmtime', 'getsize', 'isabs', 'isdir', 'isfile', 'islink', 'ismount', 'join', 'lexists', 'normcase', 'normpath', 'os', 'pardir', 'pathsep', 'realpath', 'relpath', 'samefile', 'sameopenfile', 'samestat', 'sep', 'split', 'splitdrive', 'splitext', 'stat', 'supports_unicode_filenames', 'sys']
>>> os.curdir
'.'
>>> path.abspath(os.curdir)
'C:\\Users\\59127'
>>> os.chdir("c:/")
>>>
>>> os.curdir
>>> path.abspath(os.curdir)
'c:\\'
>>>
>>> os.name
'nt'
>>>
>>> os.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: read expected 2 arguments, got 0
>>>
>>>
>>>
>>>
>>> di(path)
Traceback (most recent call last):
>>> dir(path)
['_LCMAP_LOWERCASE', '_LCMapStringEx', '_LOCALE_NAME_INVARIANT', '__all__', '__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_abspath_fallback', '_get_bothseps', '_getfinalpathname', '_getfinalpat', 'altsep', 'basename', 'commonpath', 'commonprefix', 'curdir', 'defpath', 'devnull', 'dirname', 'exists', 'expanduser', 'expandvars', 'extsep', 'genericpath', 'getatime', 'getctime', 'getmtime', 'getsize', 'isabs', 'isdir', 'isfile', 'islink', 'ismount', 'join', 'lexists', 'normcase', 'normpath', 'os', 'pardir', 'pathsep', 'realpath', 'relpath', 'samefile', 'sameopenfile', 'samestat', 'sep', 'split', 'splitdrive', 'splitext', 'stat', 'supports_unicode_filenames', 'sys']
>>>
>>>
>>> dir(os)
['DirEntry', 'EX_OK', 'F_OK', 'GenericAlias', 'Mapping', 'MutableMapping', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED', 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'PathLike', 'R_OK', 'SEEK_CUR', 'SEEK_END', 'SEEK_SET', 'TMP_MAX', 'W_OK', 'X_OK', '_AddedDllDirectory', '_Environ', '__all__', '__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_check_methods', '_execvpe', '_exists', '_exit', '_fspath', '_get_exports_list', '_walk', '_wrap_close', 'abc', 'abort', 'access', 'add_dll_directory', 'altsep', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'curdir', 'defpath', 'device_encoding', 'devnull', 'dup', 'dup2', 'environ', 'error', 'execl', 'execle', 'execlp', 'execlpe', 'execv', 'execve', 'execvp', 'execvpe', 'extsep', 'fdopen', 'fsdecode', 'fsencode', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_exec_path', 'get_handle_inheritable', 'get_inheritable', 'get_terminal_size', 'getcwd', 'getcwdb', 'getenv', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'linesep', 'link', 'listdir', 'lseek', 'lstat', 'makedirs', 'mkdir', 'name', 'open', 'pardir', 'path', 'pathsep', 'pipe', 'popen', 'putenv', 'read', 'readlink', 'remove', 'removedirs', 'rename', 'renames', 'replace', 'rmdir', 'scandir', 'sep', 'set_handle_inheritable', 'set_inheritable', 'spawnl', 'spawnle', 'spawnv', 'spawnve', 'st', 'startfile', 'stat', 'stat_result', 'statvfs_result', 'strerror', 'supports_bytes_environ', 'supports_dir_fd', 'supports_effective_ids', 'supports_fd', 'supports_follow_symlinks', 'symlink', 'sys', 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'unsetenv', 'urandom', 'utime', 'waitpid', 'waitstatus_to_exitcode', 'walk', 'write']
>>>
>>> os.listdir()
['$Recycle.Bin', '$WINDOWS.~BT', '$WINRE_BACKUP_PARTITION.MARKER', 'code', 'ComputerZ.set', 'Documents and Settings', 'Drivers', 'DumpStack.log.tmp', 'hiberfil.sys', 'mywork', 'OneDriveTemp', 'pagefile.sys', 'PerfLogs', 'Program Files', 'Program Files (x86)', 'ProgramData', 'Recovery', 'swapfile.sys', 'System Volume Information', 'Users', 'Windows']
案例:遍历磁盘
磁盘遍历思路:os.listdir([path])、os.scandir([path])遍历一个具体的路径,返回该路径下对应的文件或者文件夹,需要注意:以列表的形式返回。
判断如果是文件夹,则继续将该路径传递,进行遍历。
重复遍历,可以使用递归实现。
import os
from os import path
def scanner_files(url: str) -> None:
try:
files = os.listdir(url)
for file in files:
# 应该拼接为完整路径
# url + "/" + file
# path.join(url, file)
real_url = url + path.sep + file
# 判断当前这个拼接后的路径,是不是文件或者文件夹
if path.isfile(real_url):
print(path.abspath(real_url))
elif path.isdir(real_url):
scanner_files(real_url)
except PermissionError:
pass
if __name__ == "__main__":
scanner_files("C:\\")
作业
-
群里第一题
-
群里第二题
-
选做题
某个人进入如下一个棋盘中,要求从左上角开始走,
最后从右下角出来(要求只能前进,不能后退),
问题:共有多少种走法?0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
-
存在一个列表,列表的元素都是从1~N的元素组成,现在有个元素成对出现了,找出这个成对出现的元素。
-
存在一个列表,该列表中的元素都是成对出现,现在有一个不是成对出现,找出它。
-
实现汉诺塔的A-C的步骤
sys模块
sys模块,该模块的系统指的是python自身的系统。
该模块提供的方法、函数、类、变量都是作用域python解释器本身。
>>> dir(sys)
['__breakpointhook__', '__displayhook__', '__doc__', '__excepthook__', '__interactivehook__', '__loader__', '__name__', '__package__', '__spec__', '__stderr__', '__stdin__', '__stdout__', '__unraisablehook__', '_base_executable', '_clear_type_cache', '_current_exceptions', '_current_frames', '_debugmallocstats', '_enablelegacywindowsfsencoding', '_framework', '_getframe', '_getquickenedcount', '_git', '_home', '_stdlib_dir', '_vpath', '_xoptions', 'addaudithook', 'api_version', 'argv', 'audit', 'base_exec_prefix', 'base_prefix', 'breakpointhook', 'builtin_module_names', 'byteorder', 'call_tracing', 'copyright', 'displayhook', 'dllhandle', 'dont_write_bytecode', 'exc_info', 'excepthook', 'exception', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'get_asyncgen_hooks', 'get_coroutine_origin_tracking_depth', 'get_int_max_str_digits', 'getallocatedblocks', 'getdefaultencoding', 'getfilesystemencodeerrors', 'getfilesystemencoding', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettrace', 'getwindowsversion', 'hash_info', 'hexversion', 'implementation', 'int_info', 'intern', 'is_finalizing', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'orig_argv', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'platlibdir', 'prefix', 'ps1', 'ps2', 'pycache_prefix', 'set_asyncgen_hooks', 'set_coroutine_origin_tracking_depth', 'set_int_max_str_digits', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdlib_module_names', 'stdout', 'thread_info', 'unraisablehook', 'version', 'version_info', 'warnoptions', 'winver']
>> a
[1, 2, 3, 4]
>>> sys.getrefcount(a)
3
>>> b = a
>>> b
[1, 2, 3, 4]
>>> sys.getrefcount(a)
4
>>> c = a
>>> sys.getrefcount(a)
4
>>> c
[1, 2, 3, 4]
5
>>>
>>>
>>>
>>> del c
>>> sys.getrefcount(a)
3
>>> del b
>>> sys.getrefcount(a)
2
时间和日期模块
时间的特殊性,使得每门编程语言都提供了时间和日期相关操作的API,python为开发者提供了主要三个跟时间相关个模块:
- time
- datetime
- calendar
time模块
>>> import time
>>>
>>> help(time)
Help on built-in module time:
DESCRIPTION
There are two standard representations of time. One is the number
of seconds since the Epoch, in UTC (a.k.a. GMT). It may be an integer
The Epoch is system-defined; on Unix, it is generally January 1st, 1970.
The actual value can be retrieved by calling gmtime(0).
The other representation is a tuple of 9 integers giving local time.
The tuple items are:
year (including century, e.g. 1998)
month (1-12)
day (1-31)
hours (0-23)
minutes (0-59)
seconds (0-59)
weekday (0-6, Monday is 0)
Julian day (day in the year, 1-366)
DST (Daylight Savings Time) flag (-1, 0 or 1)
If the DST flag is 0, the time is given in the regular time zone;
if it is 1, the time is given in the DST time zone;
if it is -1, mktime() should guess based on the date and time.
CLASSES
builtins.tuple(builtins.object)
>>>
>>>
>>> dir(time)
['_STRUCT_TM_ITEMS', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'altzone', 'asctime', 'ctime', 'daylight', 'get_clock_info', 'gmtime', 'localtime', 'mktime', 'monotonic', 'monotonic_ns', 'perf_counter', 'perf_counter_ns', 'process_time', 'process_time_ns', 'sleep', 'strftime', 'strptime', 'struct_time', 'thread_time', 'thread_time_ns', 'time', 'time_ns', 'timezone', 'tzname']
>>> help(time.ctime)
Convert a time in seconds since the Epoch to a string in local time.
>>>
'Thu Nov 7 11:43:30 2024'
>>>
>>>
>>> dir(time)
', 'process_time', 'process_time_ns', 'sleep', 'strftime', 'strptime', 'struct_time', 'thread_time', 'thread_time_ns', 'time', 'time_ns', 'timezone', 'tzname']
>>>
>>> time.sleep(1)
>>> time.time()
1730980077.1299882
>>> time.time()
1730980110.6324773
>>>
>>>
>>> time.ctime()
'Thu Nov 7 19:48:46 2024'
>>>
>>>
>>> time.ctime(0)
'Thu Jan 1 08:00:00 1970'
>>> time.localtime()
time.struct_time(tm_year=2024, tm_mon=11, tm_mday=7, tm_hour=19, tm_min=49, tm_sec=14, tm_wday=3, tm_yday=312, tm_isdst=0)
>>> now = time.localtime()
>>>
>>>
>>>
>>> print(now.tm_year)
2024
>>> print(f"今年是{now.tm_year}年{now.tm_mon}月{now.tm_mday}")
今年是2024年11月7
>>>
>>> help(time.strftime)
strftime(...)
See the library reference manual for formatting codes. When the time tuple
is not present, current time as returned by localtime() is used.
%H Hour (24-hour clock) as a decimal number [00,23].
%a Locale's abbreviated weekday name.
%A Locale's full weekday name.
%b Locale's abbreviated month name.
%B Locale's full month name.
%c Locale's appropriate date and time representation.
%I Hour (12-hour clock) as a decimal number [01,12].
%p Locale's equivalent of either AM or PM.
Other codes may be available on your platform. See documentation for
the C library strftime function.
>>>
>>> time.strftime("%Y-%m-%d %H:%M:%S")
'2024-11-07 19:53:10'
>>>
>>>
>>> time.strftime("%Y-%m-%d %H:%M:%S", time.ctime(0))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Tuple or struct_time argument required
>>> time.strftime("%Y-%m-%d %H:%M:%S")
'2024-11-07 19:54:47'
>>>
>>> s = "2000/3/4 13:34:56"
>>> s
'2000/3/4 13:34:56'
>>>
>>>
>>> help(time.strptime)
strptime(...)
strptime(string, format) -> struct_time
Parse a string to a time tuple according to a format specification.
See the library reference manual for formatting codes (same as
strftime()).
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%z Time zone offset from UTC.
%a Locale's abbreviated weekday name.
%A Locale's full weekday name.
%b Locale's abbreviated month name.
%B Locale's full month name.
%c Locale's appropriate date and time representation.
%I Hour (12-hour clock) as a decimal number [01,12].
%p Locale's equivalent of either AM or PM.
Other codes may be available on your platform. See documentation for
the C library strftime function.
>>> time.strptime(s)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "D:\dev_soft\python\Python311\Lib\_strptime.py", line 562, in _strptime_time
tt = _strptime(data_string, format)[0]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\dev_soft\python\Python311\Lib\_strptime.py", line 349, in _strptime
raise ValueError("time data %r does not match format %r" %
ValueError: time data '2000/3/4 13:34:56' does not match format '%a %b %d %H:%M:%S %Y'
>>>
>>> time.strptime(s, "%Y/%m/%d %H:%M:%S")
time.struct_time(tm_year=2000, tm_mon=3, tm_mday=4, tm_hour=13, tm_min=34, tm_sec=56, tm_wday=5, tm_yday=64, tm_isdst=-1)
datetiem模块
>>> from datetime import datetime
>>>
>>> dir(datetime)
['__add__', '__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__radd__', '__reduce__', '__reduce_ex__', '__repr__', '__rsub__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', 'astimezone', 'combine', 'ctime', 'date', 'day', 'dst', 'fold', 'fromisocalendar', 'fromisoformat', 'fromordinal', 'fromtimestamp', 'hour', 'isocalendar', 'isoformat', 'isoweekday', 'max', 'microsecond', 'min', 'minute', 'month', 'now', 'replace', 'resolution', 'second', 'strftime', 'strptime', 'time', 'timestamp', 'timetuple', 'timetz', 'today', 'toordinal', 'tzinfo', 'tzname', 'utcfromtimestamp', 'utcnow', 'utcoffset', 'utctimetuple', 'weekday', 'year']
>>> datetime.now()
>>> now = datetime.now()
>>> now.date
<built-in method date of datetime.datetime object at 0x000001918BD94330>
>>> now.date()
datetime.date(2024, 11, 7)
>>>
>>> now.time()
datetime.time(20, 0, 29, 942716)
>>>
>>>
>>> now.year()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'int' object is not callable
>>>
>>>
>>> datetime.year(0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'getset_descriptor' object is not callable
>>> help(datetime.year)
Help on getset descriptor datetime.date.year:
year
>>> now.date().year
2024
>>> now.date().month
11
>>>
calendar模块
import calendar
print(calendar.calendar(2024))
哈希算法相关模块
-
hashlib
-
hmac
>>> import hashlib
dir(haslib)
['__all__', '__block_openssl_constructor', '__builtin_constructor_cache', '__builtins__', '__cached__', '__doc__', '__file__', '__get_builtin_constructor', '__loader__', '__name__', '__package__', '__spec__', '_hashlib', 'algorithms_available', 'algorithms_guaranteed', 'blake2b', 'blake2s', 'file_digest', 'md5', 'new', 'pbkdf2_hmac', 'scrypt', 'sha1', 'sha224', 'sha256', 'sha384', 'sha3_224', 'sha3_256', 'sha3_384', 'sha3_512', 'sha512', 'shake_128', 'shake_256']
>>>
AttributeError: '_hashlib.HASH' object has no attribute 'hexdegist'. Did you mean: 'hexdigest'?
>>>
>>> m = hashlib.md5("123456".encode("utf-8"))
>>>
>>> m.hexdigest()
'e10adc3949ba59abbe56e057f20f883e'
>>>
>>>
>>>
>>>
>>> m = hashlib.sha256("123456".encode("utf-8"))
>>>
>>> m.hexdigest()
'8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92'
>>>
>>>
>>>
>>>
>>> m = hashlib.sha256("123456".encode("utf-8"))
>>>
>>> m.update("789".encode("utf-8"))
>>>
>>> m.hexdigest()
'15e2b0d3c33891ebb0f1ef609ec419420c20e320ce94c65fbc8c3312448eb225'
>>>
>>> m.update("REIOP{Iuuiokoweuiwekweoe4567890pl;--=pjlyu7ikityjklpoopk67wjjiosiopso;sdj".encode("utf-8"))
>>>
>>>
>>> m.hexdigest()
'4ce453bf31eb693f105d355fbdb4d55a94e70983afebca4bda2a9ea5b6ed0863'
>>>
第三方模块
第三方模块,默认是没有安装的,所以需要首先安装需要使用的第三方模块。
使用python自带的工具【pip】
pip install xxx
pip install numpy
pip install matplotlib
pip install pandas
pip install pillow
# 多维数组
import matplotlib.pyplot as plt
import numpy as np
# 读取当前路径下的一张图片
cat = plt.imread("cat.jpg")
# 图片在计算机看来就是一个三位数组
# print(cat)
# 随机一个三位数组,第三维度的值有三个(正好是三原色)
data = np.random.randint(0, 255, size=(250, 400, 3))
print(data)
# 显示图片
plt.imshow(data)
plt.show()
IO流篇
神马是IO流
IO流(input output Stream):输入输出流。指的就是计算机中数据的流动问题。
注意:在理解和认知IO流的时候,需要将自己带入CPU或者内存的立场来。
IO流,指的计算机中需要计算的数据和计算完成后需要存储或者传输的数据。
因为数据一般是存在在磁盘上,所以常规情况下,我们说的IO流,指的是内存与磁盘之间的数据流入和留出。
如果放大角度,我们会发现,电脑与电脑之间也存在着数据的流入流出。这就是广义上的IO流,当然电脑直接进行数据交互,必须借助网络设备,所以一般就叫做网络编程。
IO流的分类
什么叫做分类:分类是一种面向对象的的思维,是人类认知世界的一种手段。
分类是人类的主观意识,所以,往往需要标准。
-
按照数据的流动方向
- 输入流
- 输出流
-
按照数据的类型
- 字节流
- 字符流
python如何操作IO流
python操作IO流非常简单,只需要掌握一个方法即可。全局函数open。
>>> open
<built-in function open>
>>>
>>> help(open)
Help on built-in function open in module io:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
Open file and return a stream. Raise OSError upon failure.
be opened or an integer file descriptor of the file to be
wrapped. (If a file descriptor is given, it is closed when the
returned I/O object is closed, unless closefd is set to False.)
mode is an optional string that specifies the mode in which the file
is opened. It defaults to 'r' which means open for reading in text
mode. Other common values are 'w' for writing (truncating the file if
it already exists), 'x' for creating and writing to a new file, and
'a' for appending (which on some Unix systems, means that all writes
append to the end of the file regardless of the current seek position).
In text mode, if encoding is not specified the encoding used is platform
dependent: locale.getencoding() is called to get the current locale encoding.
(For reading and writing raw bytes use binary mode and leave encoding
unspecified.) The available modes are:
========= ===============================================================
Character Meaning
--------- ---------------------------------------------------------------
'r' open for reading (default)
'w' open for writing, truncating the file first
'x' create a new file and open it for writing
'a' open for writing, appending to the end of the file if it exists
'b' binary mode
't' text mode (default)
'+' open a disk file for updating (reading and writing)
========= ===============================================================
>>> os.path.abspath(os.curdir)
'C:\\Users\\59127'
>>>
>>>
>>>
>>> f = open("npm")
>>>
>>> f
<_io.TextIOWrapper name='npm' mode='r' encoding='cp936'>
>>>
>>>
>>>
>>> dir(f)
['_CHUNK_SIZE', '__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__enter__', '__eq__', '__exit__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_checkClosed', '_checkReadable', '_checkSeekable', '_checkWritable', '_finalizing', 'buffer', 'close', 'closed', 'detach', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'line_buffering', 'mode', 'name', 'newlines', 'read', 'readable', 'readline', 'readlines', 'reconfigure', 'seek', 'seekable', 'tell', 'truncate', 'writable', 'write', 'write_through', 'writelines']
open函数返回的就是文件对象。
注意:在读取或者写入字符流的时候,要注意编码问题!!!
open函数中第四个参数,用来解决编码问题。
文件对象
['buffer', 'close', 'closed', 'detach', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'line_buffering', 'mode', 'name', 'newlines', 'read', 'readable', 'readline', 'readlines', 'reconfigure', 'seek', 'seekable', 'tell', 'truncate', 'writable', 'write', 'write_through', 'writelines']
>>> f.closed
False
>>>
>>>
>>> if not f.closed:
... f.close()
...
>>>
>>>
>>> f.closed
True
>>>
>>> f.readable()
True
>>>
>>>
>>> f.writable()
False
>>>
>>>
>>>
>>> if f.readable():
... f.read()
...
'hello,china,I love you!!!——刘建宏'
>>> f.readline()
'hello,china,I love you!!!——刘建宏\n'
>>> f.readline()
'hello,china,I love you!!!——刘建宏\n'
>>> f.readlines()
['hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏\n', 'hello,china,I love you!!!——刘建宏']
>>> f = open("C:\\Users\\59127\\OneDrive\\桌面\\2024西工商\\python\\code\\a.txt", encoding="UTF-8")
>>>
>>> f.read()
'hello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏'
>>>
>>>
>>> f.read()
''
>>> f.seek(0)
0
>>>
>>> f.read()
'hello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏'
>>>
>>> f.read(3)
''
>>> f.seek(3)
3
>>> f.read()
'lo,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建v宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏\nhello,china,I love you!!!——刘建宏'
IO流操作是,非常存在风险的操作!!!在整体操作过程中,必须注意风险问题。
另外,最后使用IO,必须关闭IO!!!
文件对象的常见方法
- close()
- closed 属性
- encoding 属性
- mode 属性
- name 属性
- readable()
- read([num])
- readline()
- readlines()
- write(msg)
- readable()
- writable()
字符输入流
输入流,指的是,向内存中输入【读入】数据。
# 注意,编码问题
f = open("a.txt", "rt", encoding="utf-8")
# open函数返回的是一个文件对象
content = f.read()
print(content)
# 文件对象打开后,必须关闭
if not f.closed():
f.close()
字符输出流
内存中的数据,输入到其他地方【存储设备】。
msg = "你好,刘建宏,我是粉丝,我好喜欢你哦~~~\n"
f = open("b.txt", "wt", encoding='utf-8')
f.write(msg)
f.close()
字节流
在计算机中,数据往往存在两种表现格式:字节数据【计算机底层,只有这种格式】、字符数据【字符串】。有些文件或者数据,只能使用字节数据——视频、图片、音频、压缩包等等文件。
因此,针对这些数据,可以使用字节流。
注意:计算机底层只有二进制数据,所以字节流可以处理任何格式的数据,包括字符流。
反过来说,字节流都可以转换为字符流,不一定!!!!
>>> s = "hello"
>>>
>>> type(s)
<class 'str'>
>>>
>>>
>>> s = b"hello"
>>> type(s)
<class 'bytes'>
>>>
>>>
>>> s = b"hello 刘建宏"
File "<stdin>", line 1
s = b"hello 刘建宏"
^
SyntaxError: bytes can only contain ASCII literal characters
>>>
>>>
>>>
>>> s = "hello 刘建宏".encode("utf-8")
>>> s
b'hello \xe5\x88\x98\xe5\xbb\xba\xe5\xae\x8f'
>>>
>>>
>>> s
b'hello \xe5\x88\x98\xe5\xbb\xba\xe5\xae\x8f'
>>>
>>> s.decode("utf-8")
'hel
案例:
# 字节输入流
# f = open("a.txt", "rb")
# content = f.read()
# # print(type(content))
# # print(content)
# # 怎么把字节数据转换为字符数据????
# print(content.decode("utf-8"))
# IO流,操作完成后,必须关闭!!!
# f.close()
# 字节输出流
msg = input("请输入您想要存储的数据:")
f = open("b.dat", "wb")
f.write(msg.encode("utf-8"))
print("保存成功!!!")
if not f.closed():
f.close()
案例-大文件拷贝
import os
import uuid
from os import path
def copy_file(src_path, dest_dir):
"""
src_path: c:/a/b/a.mp4
dest_dir: f:/视频/
"""
read_file = open(src_path, "br")
filename = uuid.uuid4().hex + path.basename(src_path)
write_file = open(dest_dir + os.sep + filename, "wb")
# 注意:不要直接这样进行代码拷贝,危险系数较高
# write_file.write(read_file.read())
while True:
content = read_file.read(1024 * 1024 * 10)
if content == b'':
break
write_file.write(content)
read_file.close()
write_file.close()
print("拷贝完成")
if __name__ == "__main__":
copy_file("D:\\os_iso\\CentOS7\\CentOS7-s005.vmdk", "e:/")
缓存问题
为了加快磁盘的运作速度,IO操作中,内存会构建一个缓存区,加速磁盘的写入效率。但是也要注意,因此引起的一系列问题。
>>> import os
'C:\\Users\\59127\\OneDrive\\桌面\\2024西工商\\python\\code'
>>> os.getcwd()
>>>
8
>>> f.write("刘建宏是个欧巴")
7
>>> f.flush()
>>>
>>> f.write("刘建宏是个大帅哥")
8
>>> f.write("刘建宏是个大帅哥")
8
>>> f.write("刘建宏是个大帅哥")
8
>>> f.write("刘建宏是个大帅哥")
8
>>> f.write("刘建宏是个大帅哥")
8
>>> f.write("刘建宏是个大帅哥")
8
>>> f.write("刘建宏是个大帅哥")
8
>>> f.write("刘建宏是个大帅哥")
8
>>>
>>>
>>> f.close()
with的语法块
# file = open("a.txt", "r")
# if file.closed():
# file.close()
with open("a.txt", encoding="utf-8") as f: # f = open("a.txt", "r")
print(f.read())
# with会在这个语法块的时候,自动调用打开的对象的close()
print("数据读取成功了")
对象序列化和反序列
IO流只能存储和读取字符或者字节数据,而开发中,存在大量的对象数据【列表、元组、object等等】,如果要存储这种对象数据,我们无法成功的存储!!!怎么办???
❓ 思考下,如何解决
常规情况下,不管使用字节流或者字符流,都无法存储对象数据。
>>> nums = [1,2,3,6,4,5]
>>> nums
[1, 2, 3, 6, 4, 5]
>>>
>>> with open("a.dat", "wb") as f:
... f.write(nums)
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: a bytes-like object is required, not 'list'
>>>
>>> with open("a.dat", "w") as f:
... f.write(nums)
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: write() argument must be str, not list
序列化(Serialization)
指的就是将某门面向对象的编程语言中的逻辑对象(不是真正的物理数据)转换为可以进行数据传输或者存储的物流对象(字符、字节)数据的过程,叫做对象序列化。
反序列
和序列化正好相反,是将物流数据转换为对应编程语言的逻辑数据!!!
持久化
将内存中的数据永久的存储【类似于磁盘这样的永久存储设置】下来
反持久化
将磁盘等永久存储设置中存储的数据,重新读取到内存中。
python提供序列化方案
python为开发者提供了很多序列化相关的技术,方便开发者直接进行上述操作——pickle、json等
pickle模块
该模块是内置模块,直接导入即可使用。
>>> import pickle
>>>
>>> help(pickle)
Help on module pickle:
MODULE REFERENCE
https://docs.python.org/3.11/library/pickle.html
The following documentation is automatically generated from the Python
source files. It may be incomplete, incorrect or include features that
are considered implementation detail and may vary between Python
implementations. When in doubt, consult the module reference at the
location listed above.
DESCRIPTION
See module copyreg for a mechanism for registering custom picklers.
See module pickletools source for extensive comments.
Functions:
dump(object, file)
dumps(object) -> string
load(file) -> object
loads(bytes) -> object
>>>
>>>
>>> dir(pickle)
['ADDITEMS', 'APPEND', 'APPENDS', 'BINBYTES', 'BINBYTES8', 'BINFLOAT', 'BINGET', 'BININT', 'BININT1', 'BININT2', 'BINPERSID', 'BINPUT', 'BINSTRING', 'BINUNICODE', 'BINUNICODE8', 'BUILD', 'BYTEARRAY8', 'DEFAULT_PROTOCOL', 'DICT', 'DUP', 'EMPTY_DICT', 'EMPTY_LIST', 'EMPTY_SET', 'EMPTY_TUPLE', 'EXT1', 'EXT2', 'EXT4', 'FALSE', 'FLOAT', 'FRAME', 'FROZENSET', 'FunctionType', 'GET', 'GLOBAL', 'HIGHEST_PROTOCOL', 'INST', 'INT', 'LIST', 'LONG', 'LONG1', 'LONG4', 'LONG_BINGET', 'LONG_BINPUT', 'MARK', 'MEMOIZE', 'NEWFALSE', 'NEWOBJ', 'NEWOBJ_EX', 'NEWTRUE', 'NEXT_BUFFER', 'NONE', 'OBJ', 'PERSID', 'POP', 'POP_MARK', 'PROTO', 'PUT', 'PickleBuffer', 'PickleError', 'Pickler', 'PicklingError', 'PyStringMap', 'READONLY_BUFFER', 'REDUCE', 'SETITEM', 'SETITEMS', 'SHORT_BINBYTES', 'SHORT_BINSTRING', 'SHORT_BINUNICODE', 'STACK_GLOBAL', 'STOP', 'STRING', 'TRUE', 'TUPLE', 'TUPLE1', 'TUPLE2', 'TUPLE3', 'UNICODE', 'Unpickler', 'UnpicklingError', '_Framer', '_HAVE_PICKLE_BUFFER', '_Pickler', '_Stop', '_Unframer', '_Unpickler', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_compat_pickle', '_dump', '_dumps', '_extension_cache', '_extension_registry', '_getattribute', '_inverted_registry', '_load', '_loads', '_test', '_tuplesize2code', 'bytes_types', 'codecs', 'compatible_formats', 'decode_long', 'dispatch_table', 'dump', 'dumps', 'encode_long', 'format_version', 'io', 'islice', 'load', 'loads', 'maxsize', 'pack', 'partial', 're', 'sys', 'unpack', 'whichmodule']
注意:pickle模块,对象序列化,都是字节操作,核心方法,共有四个:
- dump(object, file) # 对象持久化,将对象直接存储到磁盘中
- dumps(object) -> bytes # 对象序列化,将对象转换为字节数据
- load(file) -> object # 对象反持久化,将磁盘中 的数据直接转换为内存中的对象
- loads(bytes) -> object # 对象反序列化,将字节数据转化为对象转换
>>> nums
[1, 2, 3, 6, 4, 5]
>>>
>>> # 序列化
>>> res = pickle.dumps(nums)
>>> res
b'\x80\x04\x95\x11\x00\x00\x00\x00\x00\x00\x00]\x94(K\x01K\x02K\x03K\x06K\x04K\x05e.'
>>># 再使用IO流持久化
>>> with open("a.dat", "bw") as f:
... f.write(res)
...
28
>>>
>>> # 也可以直接一步完成持久化
>>> pickle.dump(nums, open("b.txt", "wb"))
>>>
# 这个操作,一步到位的,直接将磁盘中的数据直接读成对象【反持久化】
>>> pickle.load(open("b.txt", "br"))
[1, 2, 3, 6, 4, 5]
>>>
# 通过IO流将磁盘数据读到内存中
>>> f = open("a.dat", "br")
>>>
>>> a = f.read()
>>> a
b'\x80\x04\x95\x11\x00\x00\x00\x00\x00\x00\x00]\x94(K\x01K\x02K\x03K\x06K\x04K\x05e.'
>>>
>>> # 再将字节数据反序列化为对象
>>> pickle.loads(a)
[1, 2, 3, 6, 4, 5]
json模块
python内置模块,该模块可以将对象转换为字符数据,进行对象的序列化和持久化。
该模块会将对象转换为一种特别格式的字符串,所以,不是所有对象都可以转换,必须是存在特定格式的对象,如列表([])、字典({k:v})、tuple(())、集合({})。
注意:当然其他对象,如果重写了__str__()方法,规定了格式,也可以使用。
>>> import json
>>>
>>> dir(json)
['JSONDecodeError', 'JSONDecoder', 'JSONEncoder', '__all__', '__author__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', '_default_decoder', '_default_encoder', 'codecs', 'decoder', 'detect_encoding', 'dump', 'dumps', 'encoder', 'load', 'loads', 'scanner']
>>>
>>>
>>>
>>> json.dump(nums, open("a.txt", "w"))
>>>
>>>
>>>
>>>
>>> json.load(open("a.txt"))
[1, 2, 3, 6, 4, 5]
>>>
>>>
>>>
>>> json.dumps(nums)
'[1, 2, 3, 6, 4, 5]'
>>> d = {"name": "刘建宏", "age": 16}
>>>
>>> d
{'name': '刘建宏', 'age': 16}
>>>
>>>
>>>
>>> json.dump(nums, open("a.json", "w"))
>>>
>>> json.dump(d, open("a.json", "w"))
>>>
注意:json模块一般都是用来操作dict对象的!!!!
面向对象编程(OOP)
面向对象OOP( Object Oriented Programming):是一种编程思想。
非常重要,是目前几乎所有高级编程语言都需要实现的。
什么是面向对象
C:面向过程【函数、功能】编程。
面向对象:在面向过程的基础上,通过分门别类这种方式的,得到一种全新编程思想。
面向对象编程:就是分门别类的一种编程方式!!!
核心概念:
-
类别(class),简称为类,指的就是一类事物,不存在!!是一个抽象概念
-
对象(object),类中一个具体案例,也就是某一个类别中一个具体案例,实实在在存在的案例
-
面向对象的编程:想象需要的场景,分析在该场景中需要出现的类别,定义这些类别(分析该类别的属性和行为)。最后创建对应的对象的编程方式。
-
属性:类的静态特征。
-
方法:类的动态行为。
python如何定义类
几乎所有的面向对象的编程语言定义类,使用关键字:class。
基本语法:
class 类名称[(父类 [,父类……])]:
属性名称 = 属性值
……
# 使用函数来模拟方法
def speak(self [, 参数列表]):
# 方法体
……
代码:
class Student:
"""
定义一个类
"""
name = "刘建宏"
age = 16
address = "陕西西安"
gender = True
def speak(self):
print("大家好,才是真的好,广州好迪")
if __name__ == "__main__":
# 创建对象
s1 = Student()
print(s1.name)
print(s1.age)
print(s1.address)
print(s1.gender)
s1.speak()
也可以在定义类的同时,加上父类信息。
当类在定义时,如果没有写父类,默认继承object类,在python中,该类默认是所有类的父类。
class Cat(object):
# 属性,是Cat这个猫的静态特征
name = "小杰"
age = 3
color = "yellow"
master = "刘建宏"
gender = "米"
def run(self):
print("我是小猫,我会跑,我的名字是:"+ self.name)
def speak(self):
print("我正在咪咪咪叫")
def sleep(self):
print("小猫咪正在念经")
if __name__ == '__main__':
# 创建对象
m1 = Cat()
# print(m1.name)
# print(m1.gender)
# print(m1.color)
# print(m1.master)
#
# # 将小猫送人了
# m1.master = "小明"
#
# m1.sleep()
#
# print(m1.master)
m1.run()
m2 = Cat()
m2.name = "Tom"
m2.run()
通过如上案例,可以看到,直接定义类,在创建对象,调用对象的属性和方法完成编程。
但是将属性直接定义在类中,这种方式,默认所有的对象,在创建之初,就默认存在了对应的默认值。但是,真实场景中,大多数属性,值都是不一样的。这样我们就需要创建之后再修改,麻烦。
所以,python提供一个__init__()方法,用啦初始化属性。
class Cat(object):
# 属性,是Cat这个猫的静态特征
# name = "小杰"
# age = 3
# color = "yellow"
# master = "刘建宏"
# gender = "米"
def __init__(self):
""" 将属性定义到 __init__() 方法中"""
self.name = "小杰"
self.age = 20
self.weight = 3.14
self.color = 'blue'
self.gender = "公"
运行代码,发现和创建在类里面没有区别。这就证明了初始化方法会在创建对象时,自动执行。
既然是一个方法,当然就可以传递参数,将属性的值,在创建对象时传入进入,避免所有的属性只有值。
class Student(object):
def __init__(self, name, age, gender, password, nickname):
self.name = name
self.age = age
self.gender = gender
self.password = password
self.nickname = nickname
self.score = 100
def get_score(self):
return self.score
def set_score(self, score):
self.score = score
def get_name(self):
return self.name
# 该方法默认是打印对象的内存地址
def __str__(self):
return f"name = {self.name}, age = {self.age} , gender = {self.gender}, score = {self.score}"
if __name__ == '__main__':
# 对象的创建
# 对象的实例化(实实在在的案例初始化)
s1 = Student("张三", 20, "男", "123456", "法外狂徒")
print(s1)
s1.name = "赵六"
print(s1)
s2 = Student("李四", 56, "女", "653221", "秦国宰相")
print(s2)
python的main函数的作用
在C、C++、java这些编程语言中,main非常重要,是程序的入口和出口。
而在python、PHP、JavaScript等等脚本语言中,main往往不存在,或者存在的话,也不是程序的入口。
python中存在main函数,但是不是程序的入口。
在python中,main中的代码,不能被导入到其他模块中使用,如果在开发时,不想某些代码在其他模块中或者包中使用,建议书写在main函数中。
面向对象的三大特征
面向对象的三大特征:
- 封装
- 继承
- 多态
封装
将事务包装起来,就被称为封装。
当然在面向对象的编程中,封装是专业术语:
- 类会封装成员,也就是说默认类的成员都是被定义在类内部
- 基于安全考虑,对象的属性,不应该直接裸露在外界,被外界直接访问,安全行不高,建议将属性私有化(只允许在类内部访问)。之后提供公开的get和set方法来访问或者设置的这种方式
注意:如何私有化python的类成员(属性、方法),在该成员名称前加上__。如username属性,则变成__username属性。如方法speack()变成__speak()。
案例如下:
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 18:52
# @Author : 刘帅哥
# @Version:V1.0
# @File : 面向对象的三大特征-封装.py
# @desc : openlab_code -> PyCharm -> 面向对象的三大特征-封装
class User(object):
def __init__(self, name, age, gender, nickname, address):
self.__name = name
self.__age = age
self.__gender = gender
self.__nickname = nickname
self.__address = address
def get_name(self):
return self.__name
def set_name(self, name):
self.__name = name
def introduce_self(self):
# 方法也是类内部的成员,当然可以访问类私有成员
print(f"我叫{self.__name},我今年{self.__age}岁了,我的性别是:{self.__gender}")
if __name__ == '__main__':
u1 = User("刘建宏", 16, "男", "帅哥", "中国")
# print(u1.__name)
# u1.name = "老牟"
# print(u1.name)
# u1.introduce_self()
# 通过提供的公开的get方法来访问私有属性
print(u1.get_name())
u1.set_name("张三")
print(u1.get_name())
python也同时提供了第二种封装方式,将封装的属性,可以以别名的形式,重新在包装一次。
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 18:52
# @Author : 刘帅哥
# @Version:V1.0
# @File : 面向对象的三大特征-封装.py
# @desc : openlab_code -> PyCharm -> 面向对象的三大特征-封装
class User(object):
def __init__(self, name, age, gender, nickname, address):
self.__name = name
self.__age = age
self.__gender = gender
self.__nickname = nickname
self.__address = address
def get_name(self):
return self.__name
def set_name(self, name):
self.__name = name
def get_age(self):
return self.__age
def set_age(self, age):
self.__age = age
def introduce_self(self):
# 方法也是类内部的成员,当然可以访问类私有成员
print(f"我叫{self.__name},我今年{self.__age}岁了,我的性别是:{self.__gender}")
def __str__(self):
return f"{self.__name} -- {self.__age} -- {self.__gender}-- {self.__nickname}---{self.__address}"
# 注意:如下的书写方式
name = property(get_name, set_name)
if __name__ == '__main__':
u1 = User("刘建宏", 16, "男", "帅哥", "中国")
u1.set_name("张三")
u1.set_age(20)
print(u1)
u1.name = "李四"
print(u1)
可以看出,此时对象的属性name就是被封装的__name属性,直接给name属性赋值,则相当于调用set_name,给__name赋值。而访问name属性,则相当于调用get_name()方法,相当于访问__name属性。
注意:一些只在类内部使用的方法,建议也封装起来,防止外界调用。
继承
在面向对象中,存在着类别这种概念,类别都存在包含和被包含的关系,这种关系,就被称为继承。
继承会让子类得到父类中的一些数据。
- 子类:继承者
- 父类、超类(super):被继承者
在面向对象中,继承最大的好处就是可以实现代码的高度复用!!!!将多个类中药公用的代码,可以放在一个父类中,之后让这些类都继承这个父类,这些子类都会继承这些代码。
注意:子类在继承父类的属性和方法时,只能继承公开的属性和方法,不能继承私有的属性和方法。
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 20:12
# @Author : 刘帅哥
# @Version:V1.0
# @File : 面向对象三大特征-继承.py
# @desc : openlab_code -> PyCharm -> 面向对象三大特征-继承
class RichMan(object):
def __init__(self):
# 私有的成员不能继承
self.__name = '我是一个富人'
self.money = 10000000000
self.slogan = "我这个不喜欢钱,我对钱没有兴趣"
self.company = "alimama"
def speak(self):
print("我最后悔的事,就是创建了公司")
class Son(RichMan):
def __init__(self):
# 如果子类没有定义初始化函数,默认直接调用父类的初始化函数完成初始化
# 如果子类存在自己的属性,这时,子类必须定义自己的初始化方法来初始化属性
# 注意:这个时候,默认子类不再调用父类的初始化方法,这样的继承有问题(没有办法继承父类的属性)
# 此时就需要手动调用父类的构造方法
super().__init__()
self.friends = ["lily", "lucy", "rose"]
def tell(self):
print("我是子类,我想说句话,富豪的生活真好")
def demo(self):
self.tell()
# self.speak()
# 指定调用父类的方法
super().speak()
if __name__ == '__main__':
# r = RichMan()
# r.speak()
# print(r.money)
# print(r.company)
s = Son()
print(s.slogan)
print(s.company)
print(s.money)
print(s.friends)
s.speak()
s.demo()
方法重写(overwrite)
方法重写(overwrite)、方法覆盖(override):这两个概念是一个概念,指的都是在继承的基础上,父类提供方法,不足以满足子类使用时,子类可以重新覆盖父类提供的方法。
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 20:12
# @Author : 刘帅哥
# @Version:V1.0
# @File : 面向对象三大特征-继承.py
# @desc : openlab_code -> PyCharm -> 面向对象三大特征-继承
class RichMan(object):
def __init__(self):
# 私有的成员不能继承
self.__name = '我是一个富人'
self.money = 10000000000
self.slogan = "我这个不喜欢钱,我对钱没有兴趣"
self.company = "alimama"
def speak(self):
print("我最后悔的事,就是创建了公司")
class Son(RichMan):
def __init__(self):
# 如果子类没有定义初始化函数,默认直接调用父类的初始化函数完成初始化
# 如果子类存在自己的属性,这时,子类必须定义自己的初始化方法来初始化属性
# 注意:这个时候,默认子类不再调用父类的初始化方法,这样的继承有问题(没有办法继承父类的属性)
# 此时就需要手动调用父类的构造方法
super().__init__()
self.friends = ["lily", "lucy", "rose"]
def tell(self):
print("我是子类,我想说句话,富豪的生活真好")
def demo(self):
self.tell()
# self.speak()
# 指定调用父类的方法
super().speak()
# 方法重写、覆盖
def speak(self):
print("我刚刚登上大位,请各位叔叔伯伯多多照顾")
if __name__ == '__main__':
# r = RichMan()
# r.speak()
# print(r.money)
# print(r.company)
s = Son()
# print(s.slogan)
# print(s.company)
# print(s.money)
# print(s.friends)
# 此时,该方法被重写
# s.speak()
s.demo()
注意:三个相似概念的理解
- 方法重写(overwrite)
- 方法覆盖(override)
- 函数重载(overload)
方法重写(overwrite)和方法覆盖(override)是一个概念,指的都是在继承的基础上,子类继承了某一个或者某一些父类的方法,该方法不足以满足子类使用,子类就会定义相同名称的方法,实现该方法覆盖。
注意:函数重载(overload):函数名称相同,参数的个数或者类型不同,从而在调用的时候,调用对应的函数的现象,就叫做函数重载。
注意:python默认没有函数重载。后者会覆盖前者。
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 20:50
# @Author : 刘帅哥
# @Version:V1.0
# @File : 函数重载.py
# @desc : openlab_code -> PyCharm -> 函数重载
def a():
print("a")
def a(x, y):
print(x, y)
# 注意:只会调用第二个a函数,第一个会被覆盖掉
a()
a(18, 20)
如java中:
public static int add(int x, int y) {
return x + y;
}
// 这个函数和上面函数构不成重载,会报错
public static void add(int x, int y) {
System.out.println(x + y);
}
// 注意:此函数和第一个函数,是同一个函数,够不成重载
public static int add(int y, int x) {
return x + y;
}
public static double add(double x, int y) {
return x + y;
}
public static int add(int x) {
return x + 10;
}
// 这个会调用第二个add函数
add(10);
// 会默认第一个函数
add(10, 200);
多态
self.__age = age
self.__gender = gender
self.__nickname = nickname
self.__address = address
def get_name(self):
return self.__name
def set_name(self, name):
self.__name = name
def introduce_self(self):
# 方法也是类内部的成员,当然可以访问类私有成员
print(f"我叫{self.__name},我今年{self.__age}岁了,我的性别是:{self.__gender}")
if name == ‘main’:
u1 = User(“刘建宏”, 16, “男”, “帅哥”, “中国”)
# print(u1.__name)
# u1.name = “老牟”
# print(u1.name)
# u1.introduce_self()
# 通过提供的公开的get方法来访问私有属性
print(u1.get_name())
u1.set_name("张三")
print(u1.get_name())
python也同时提供了第二种封装方式,将封装的属性,可以以别名的形式,重新在包装一次。
~~~python
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 18:52
# @Author : 刘帅哥
# @Version:V1.0
# @File : 面向对象的三大特征-封装.py
# @desc : openlab_code -> PyCharm -> 面向对象的三大特征-封装
class User(object):
def __init__(self, name, age, gender, nickname, address):
self.__name = name
self.__age = age
self.__gender = gender
self.__nickname = nickname
self.__address = address
def get_name(self):
return self.__name
def set_name(self, name):
self.__name = name
def get_age(self):
return self.__age
def set_age(self, age):
self.__age = age
def introduce_self(self):
# 方法也是类内部的成员,当然可以访问类私有成员
print(f"我叫{self.__name},我今年{self.__age}岁了,我的性别是:{self.__gender}")
def __str__(self):
return f"{self.__name} -- {self.__age} -- {self.__gender}-- {self.__nickname}---{self.__address}"
# 注意:如下的书写方式
name = property(get_name, set_name)
if __name__ == '__main__':
u1 = User("刘建宏", 16, "男", "帅哥", "中国")
u1.set_name("张三")
u1.set_age(20)
print(u1)
u1.name = "李四"
print(u1)
可以看出,此时对象的属性name就是被封装的__name属性,直接给name属性赋值,则相当于调用set_name,给__name赋值。而访问name属性,则相当于调用get_name()方法,相当于访问__name属性。
注意:一些只在类内部使用的方法,建议也封装起来,防止外界调用。
继承
在面向对象中,存在着类别这种概念,类别都存在包含和被包含的关系,这种关系,就被称为继承。
继承会让子类得到父类中的一些数据。
- 子类:继承者
- 父类、超类(super):被继承者
在面向对象中,继承最大的好处就是可以实现代码的高度复用!!!!将多个类中药公用的代码,可以放在一个父类中,之后让这些类都继承这个父类,这些子类都会继承这些代码。
注意:子类在继承父类的属性和方法时,只能继承公开的属性和方法,不能继承私有的属性和方法。
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 20:12
# @Author : 刘帅哥
# @Version:V1.0
# @File : 面向对象三大特征-继承.py
# @desc : openlab_code -> PyCharm -> 面向对象三大特征-继承
class RichMan(object):
def __init__(self):
# 私有的成员不能继承
self.__name = '我是一个富人'
self.money = 10000000000
self.slogan = "我这个不喜欢钱,我对钱没有兴趣"
self.company = "alimama"
def speak(self):
print("我最后悔的事,就是创建了公司")
class Son(RichMan):
def __init__(self):
# 如果子类没有定义初始化函数,默认直接调用父类的初始化函数完成初始化
# 如果子类存在自己的属性,这时,子类必须定义自己的初始化方法来初始化属性
# 注意:这个时候,默认子类不再调用父类的初始化方法,这样的继承有问题(没有办法继承父类的属性)
# 此时就需要手动调用父类的构造方法
super().__init__()
self.friends = ["lily", "lucy", "rose"]
def tell(self):
print("我是子类,我想说句话,富豪的生活真好")
def demo(self):
self.tell()
# self.speak()
# 指定调用父类的方法
super().speak()
if __name__ == '__main__':
# r = RichMan()
# r.speak()
# print(r.money)
# print(r.company)
s = Son()
print(s.slogan)
print(s.company)
print(s.money)
print(s.friends)
s.speak()
s.demo()
方法重写(overwrite)
方法重写(overwrite)、方法覆盖(override):这两个概念是一个概念,指的都是在继承的基础上,父类提供方法,不足以满足子类使用时,子类可以重新覆盖父类提供的方法。
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 20:12
# @Author : 刘帅哥
# @Version:V1.0
# @File : 面向对象三大特征-继承.py
# @desc : openlab_code -> PyCharm -> 面向对象三大特征-继承
class RichMan(object):
def __init__(self):
# 私有的成员不能继承
self.__name = '我是一个富人'
self.money = 10000000000
self.slogan = "我这个不喜欢钱,我对钱没有兴趣"
self.company = "alimama"
def speak(self):
print("我最后悔的事,就是创建了公司")
class Son(RichMan):
def __init__(self):
# 如果子类没有定义初始化函数,默认直接调用父类的初始化函数完成初始化
# 如果子类存在自己的属性,这时,子类必须定义自己的初始化方法来初始化属性
# 注意:这个时候,默认子类不再调用父类的初始化方法,这样的继承有问题(没有办法继承父类的属性)
# 此时就需要手动调用父类的构造方法
super().__init__()
self.friends = ["lily", "lucy", "rose"]
def tell(self):
print("我是子类,我想说句话,富豪的生活真好")
def demo(self):
self.tell()
# self.speak()
# 指定调用父类的方法
super().speak()
# 方法重写、覆盖
def speak(self):
print("我刚刚登上大位,请各位叔叔伯伯多多照顾")
if __name__ == '__main__':
# r = RichMan()
# r.speak()
# print(r.money)
# print(r.company)
s = Son()
# print(s.slogan)
# print(s.company)
# print(s.money)
# print(s.friends)
# 此时,该方法被重写
# s.speak()
s.demo()
注意:三个相似概念的理解
- 方法重写(overwrite)
- 方法覆盖(override)
- 函数重载(overload)
方法重写(overwrite)和方法覆盖(override)是一个概念,指的都是在继承的基础上,子类继承了某一个或者某一些父类的方法,该方法不足以满足子类使用,子类就会定义相同名称的方法,实现该方法覆盖。
注意:函数重载(overload):函数名称相同,参数的个数或者类型不同,从而在调用的时候,调用对应的函数的现象,就叫做函数重载。
注意:python默认没有函数重载。后者会覆盖前者。
# _*_ coding: utf-8 _*_
# @Time : 2024/11/27 20:50
# @Author : 刘帅哥
# @Version:V1.0
# @File : 函数重载.py
# @desc : openlab_code -> PyCharm -> 函数重载
def a():
print("a")
def a(x, y):
print(x, y)
# 注意:只会调用第二个a函数,第一个会被覆盖掉
a()
a(18, 20)
如java中:
public static int add(int x, int y) {
return x + y;
}
// 这个函数和上面函数构不成重载,会报错
public static void add(int x, int y) {
System.out.println(x + y);
}
// 注意:此函数和第一个函数,是同一个函数,够不成重载
public static int add(int y, int x) {
return x + y;
}
public static double add(double x, int y) {
return x + y;
}
public static int add(int x) {
return x + 10;
}
// 这个会调用第二个add函数
add(10);
// 会默认第一个函数
add(10, 200);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









