






follow me,一起踩坑,一起进步!
第零篇:初识Jmeter
Jmeter是一款java开发的测试工具。主要用于对服务器模拟巨大的负载,和通过创建带有断言的脚本验证程序是否能返回期望的结果。
废话不多说,直接上手一个小demo感受一下jmeter!
目标:查询个人博客文章列表
1、测试计划--右键--线程--添加线程组
2、线程组--右键--取样器--HTTP请求
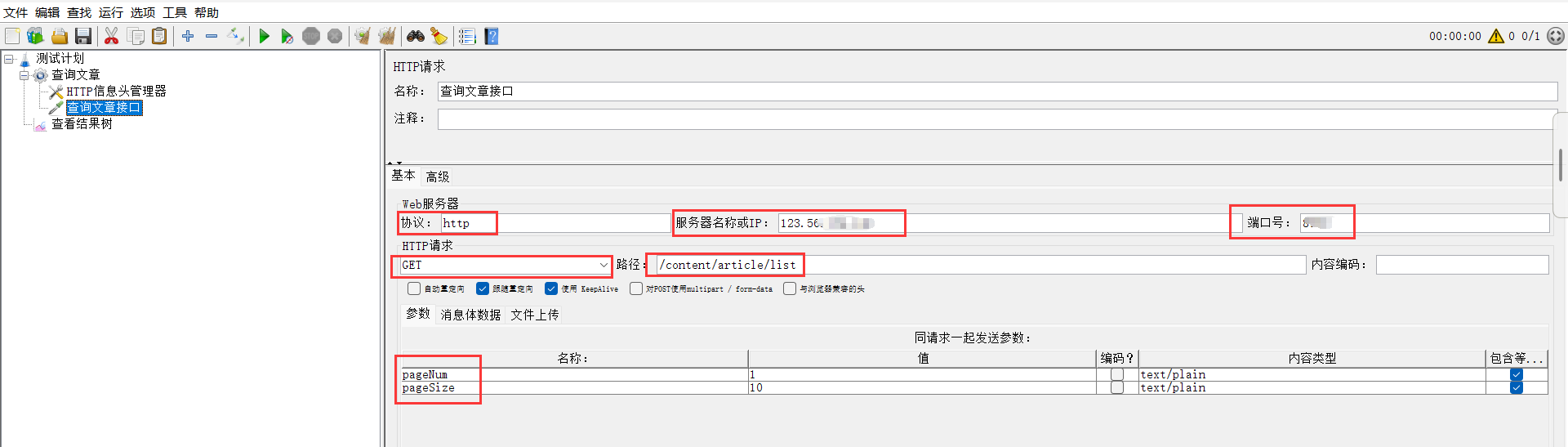
3、HTTP请求->添加->配置元件->HTTP信息头管理器(携带token)

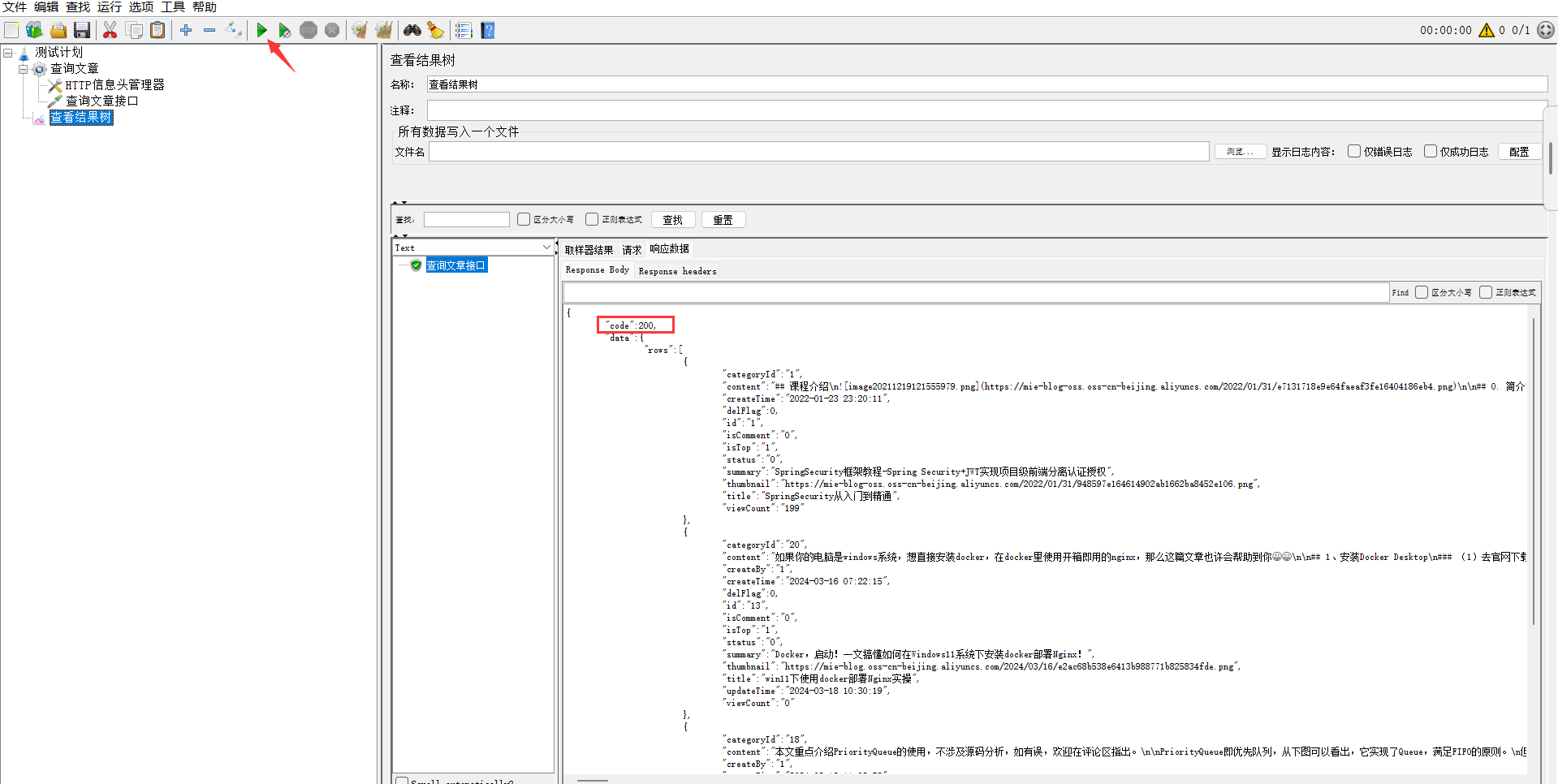
4、测试计划--右键--添加监听器--查看结果树
5、点击运行,查看结果
第一篇:Jmeter的基本使用
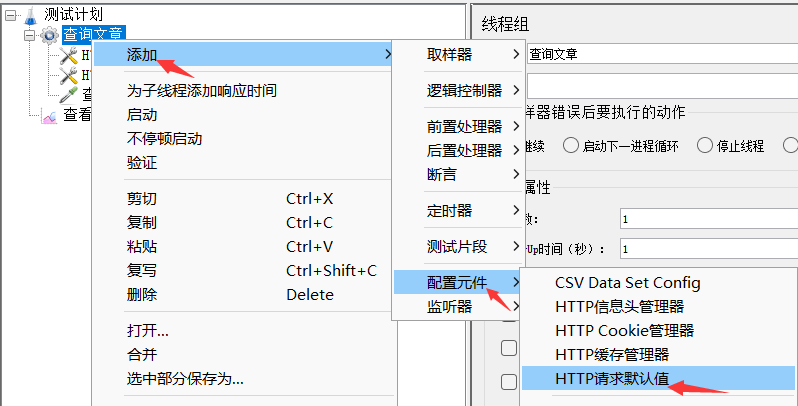
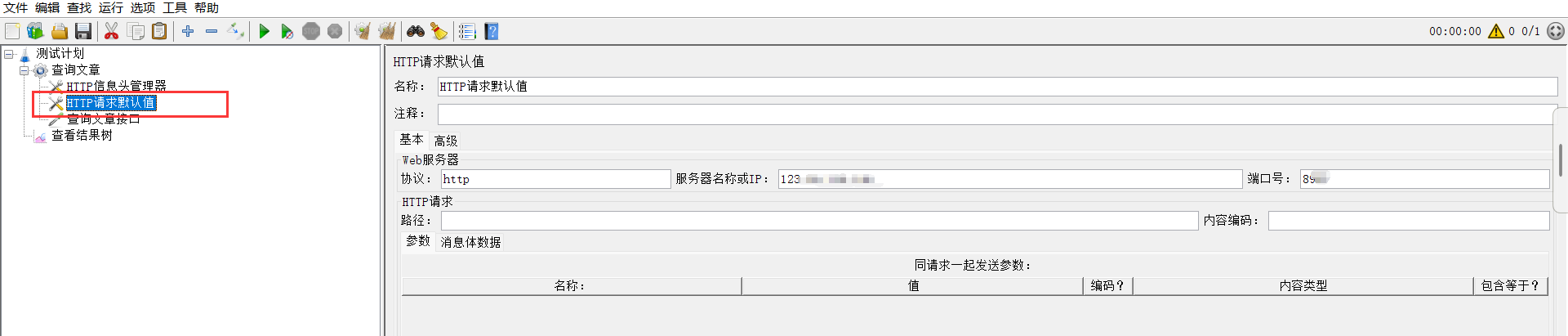
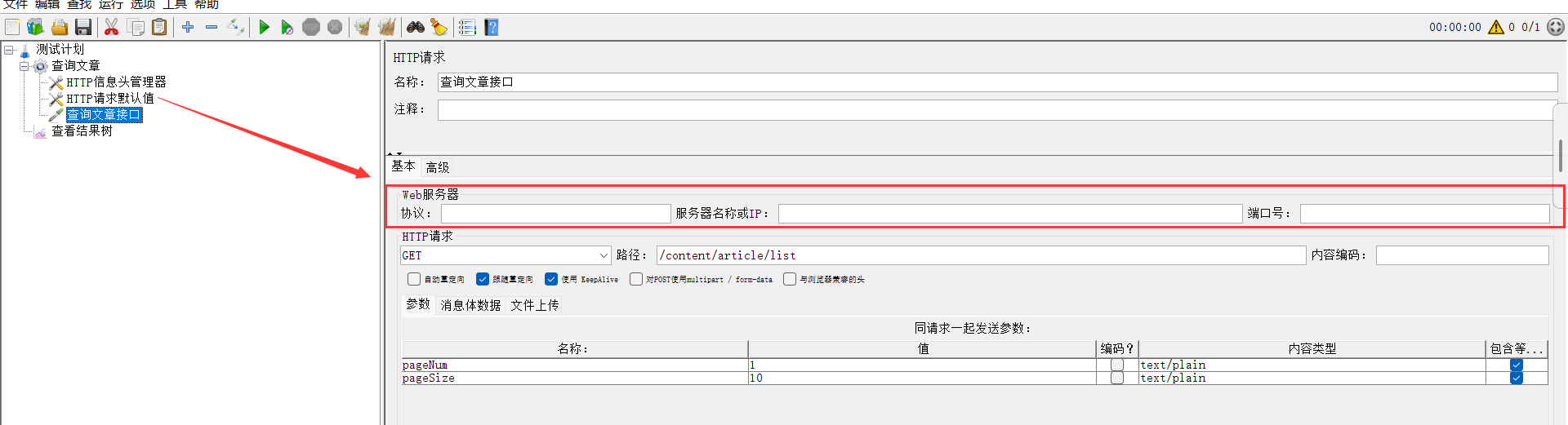
一、设置HTTP请求默认值
封装复用的请求头信息。
目标:复用请求头信息进行文章列表查询。
二、参数化
当提交的数据量较大,手动填入数据耗时耗力,每次测试都要手动填入,效率低下。
我们可以使用jmeter动态获取、设置或生成数据,提高效率。
以下四种方式实现参数化:
1、用户定义的变量
2、CSV 数据文件设置
3、用户参数
4、函数
用户定义的变量
1、添加定义变量
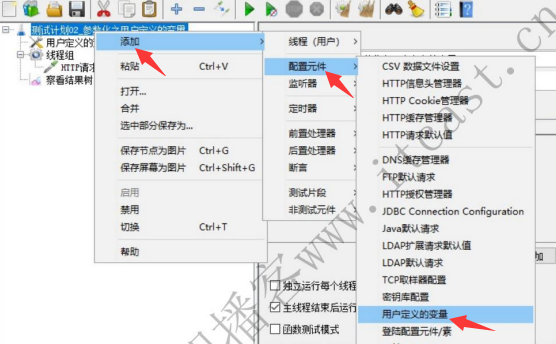
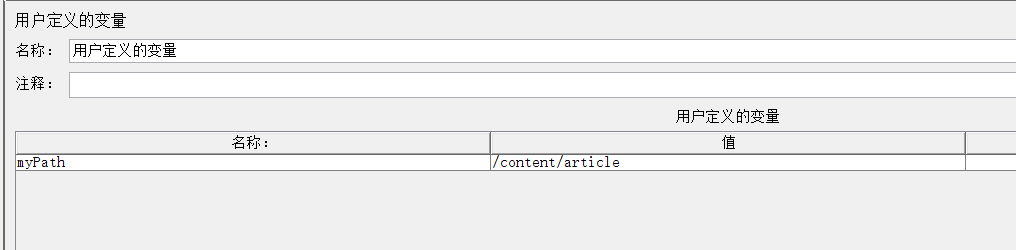
2、添加http请求
用${myPath}取到变量的值

3、运行,查看结果
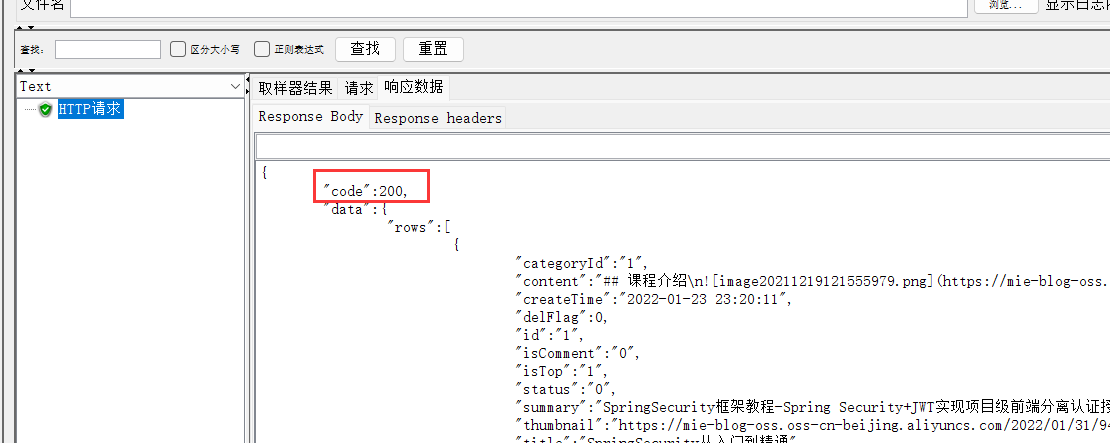
CSV 数据文件设置
第一种方式只适用于复用一个值,而批量新增数据可以采用接下来这种方式。
目标:使用csv文件的数据批量插入标签
实现步骤:
1、添加cav数据文件设置
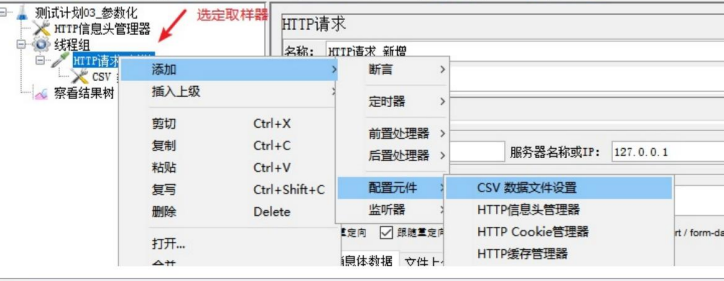
2、http请求,在请求体中编辑好模板
用${key}占位

3、编写csv文件
新建txt文本,写入内容。留意分割符自己用的什么。
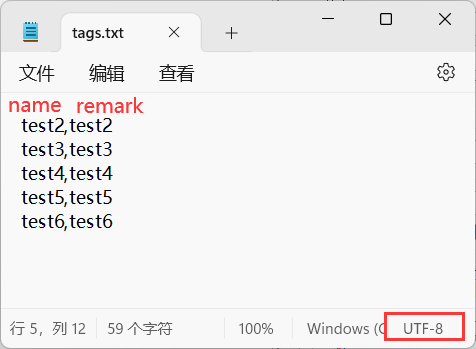
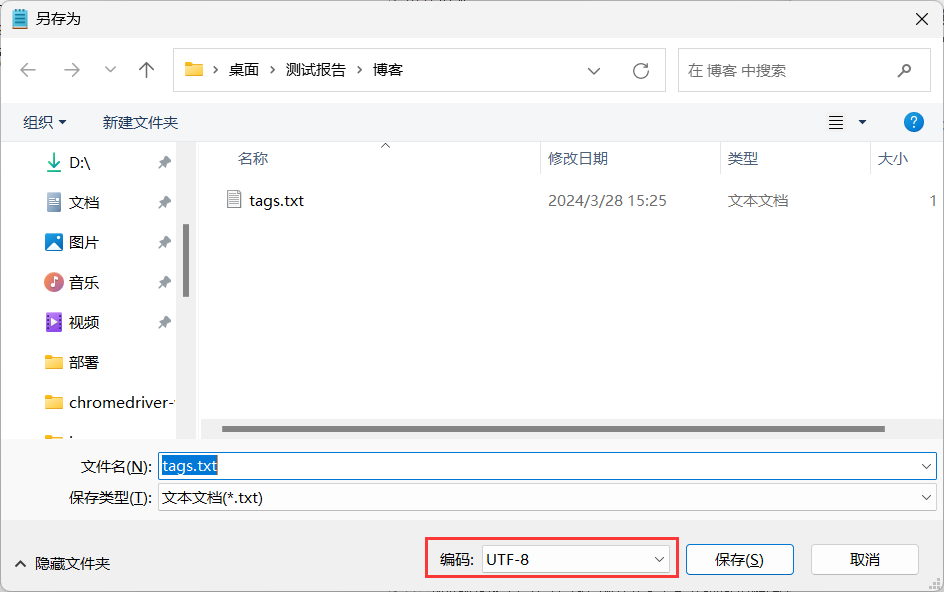
注意保存编码为:UTF-8
4、关联脚本与数据(将文件数据导入脚本)
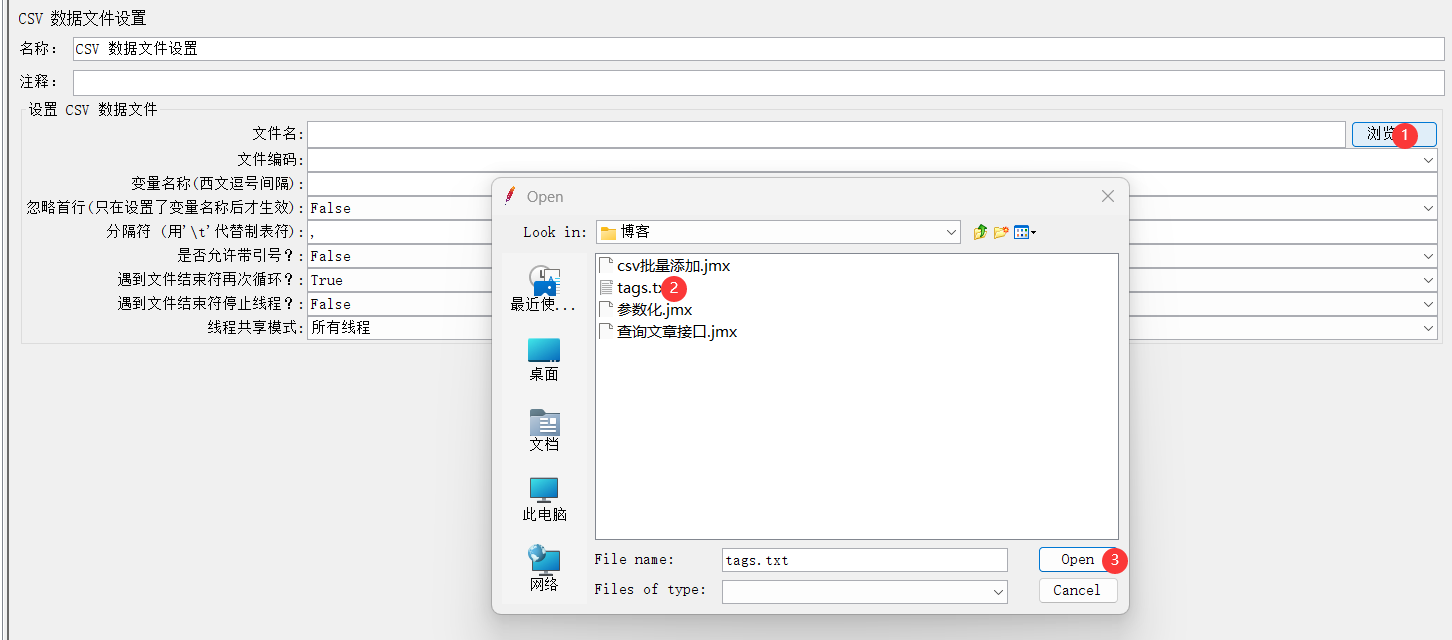
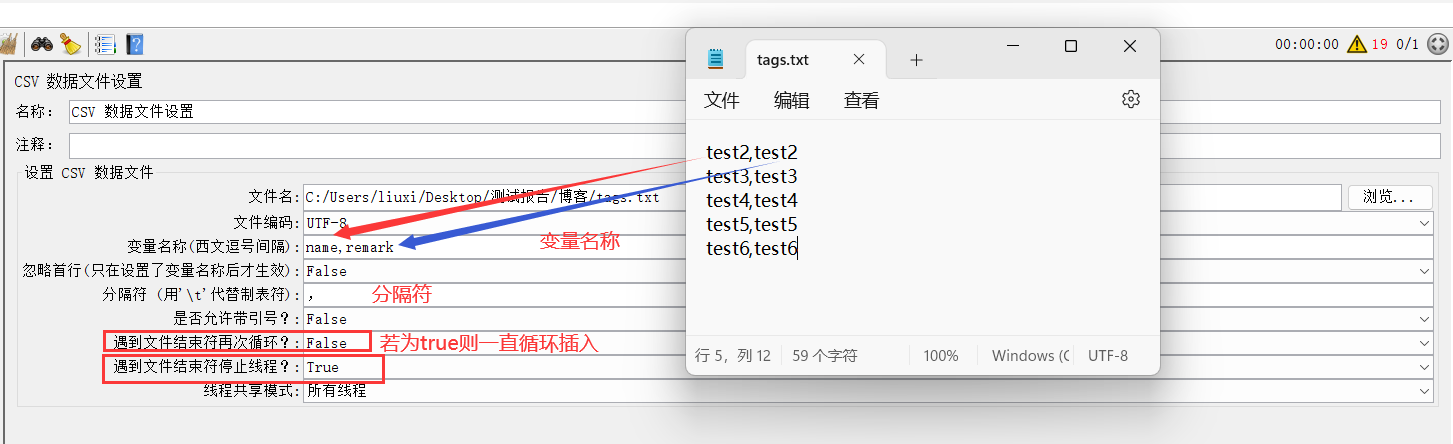
5、设置csv数据文件
文件编码设置为UTF-8,一定要大写!!!
朋友们可以先试下小写,下文会提到这个坑。
6、点击线程组,修改循环次数
推荐勾选永远
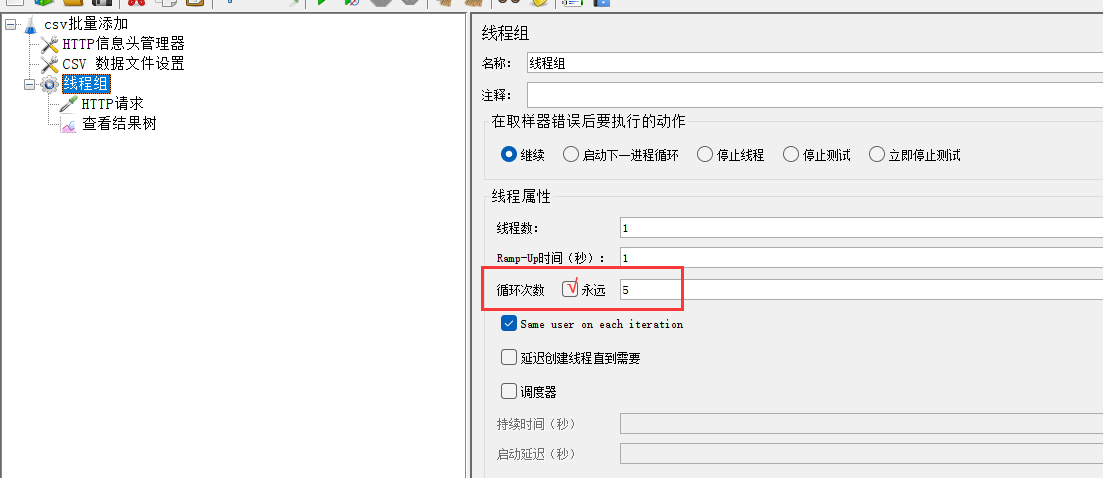
如果你知道插入了几条数据,可以填入数字。但一般情况是不知道的,所以最好勾选上永远
7、点击运行,查看结果。
⚠️咦???点了绿色小三角没有反应,结果树中没有结果。
这时我通过07Jmeter之CSV数据文件设置遇到的问题 - 谷灵精怪 - 博客园 (cnblogs.com)
这篇博客了解到可以通过查看jmeter的日志,了解具体发生了什么。
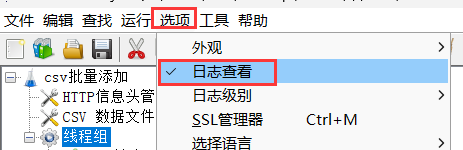
可以看到错误提示:不支持utf-8

怎么会呢?改成大写试一下。
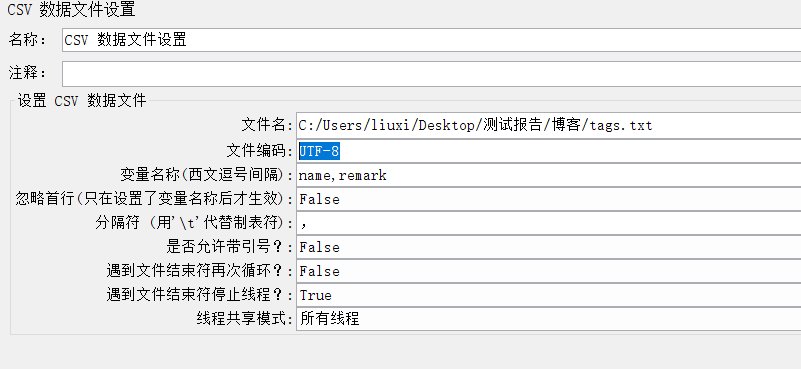
成功了!
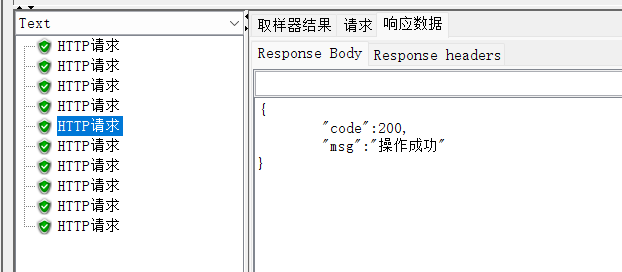
⚠️从浏览器查看后台数据,添加成功了,但是没有按照模板添加。
这明显是分割符的问题。朋友们一定要注意自己分隔符是什么,大写还是小写。
把,改为,后,批量插入成功!

用户参数
与上一种方式不同,用户参数的方式不用单独写csv文件,直接借助jmeter的工具。
平常比较常用的还是csv的方式,因为可以实现数据和脚本分离,修改数据时只修改文件即可。
目标:设置用户参数批量插入标签
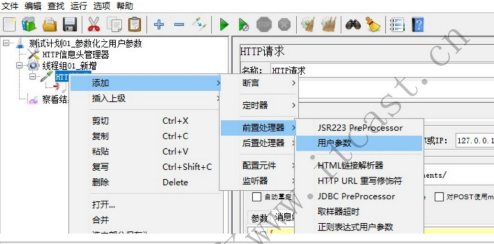
1、添加用户参数
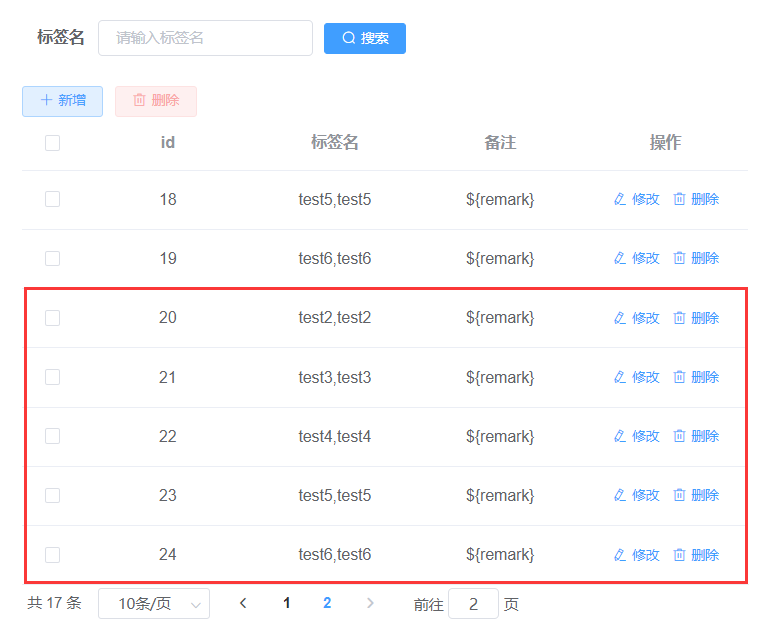
2、添加要插入的数据
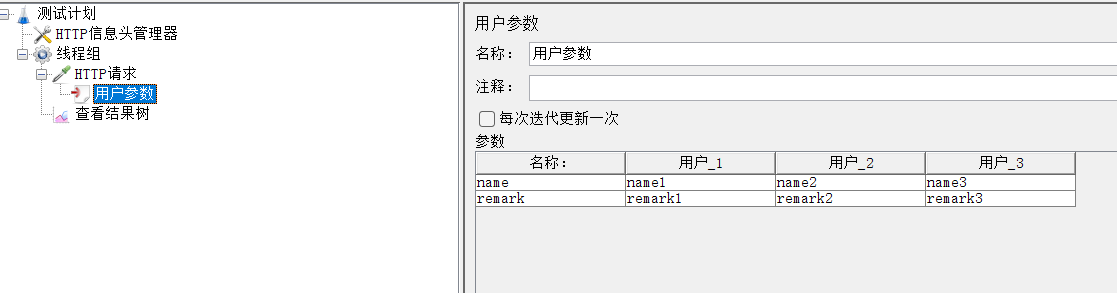
点击添加变量,增加一行
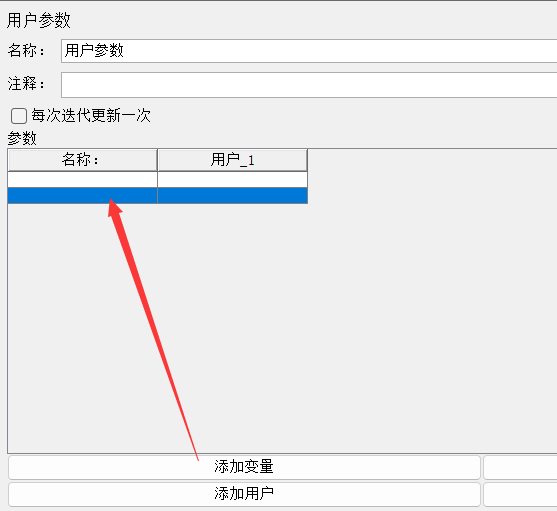
点击添加用户,增加一列
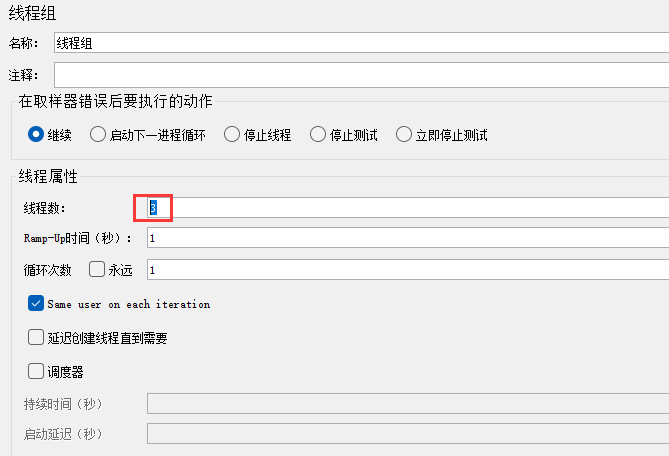
3、修改线程数,修改成你要插入数据的个数
4、运行,查看结果
成功!
函数
目标:调用函数改变请求的名字,数字递增
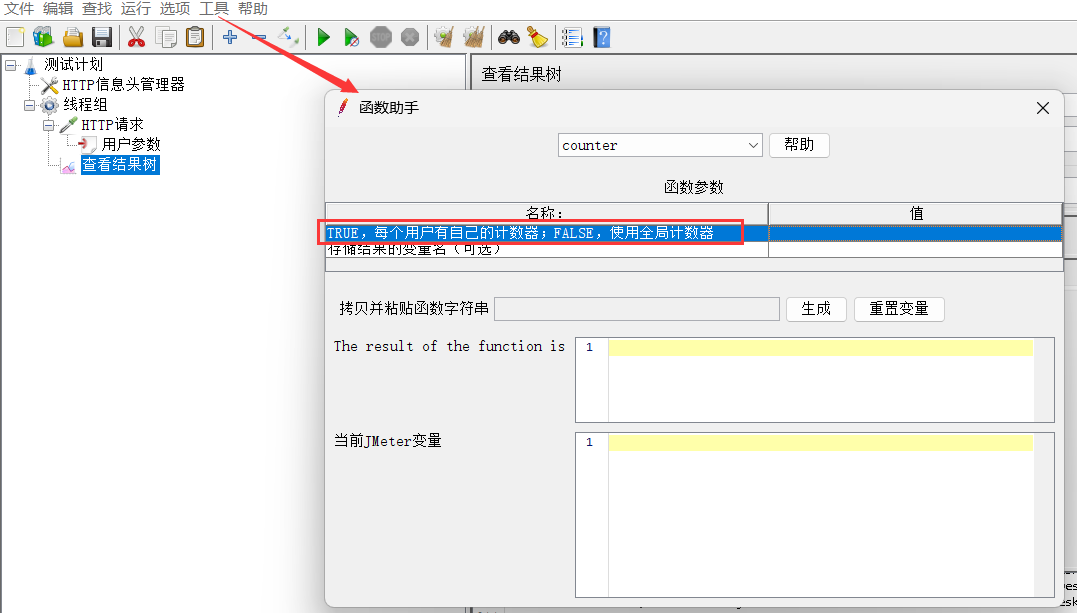
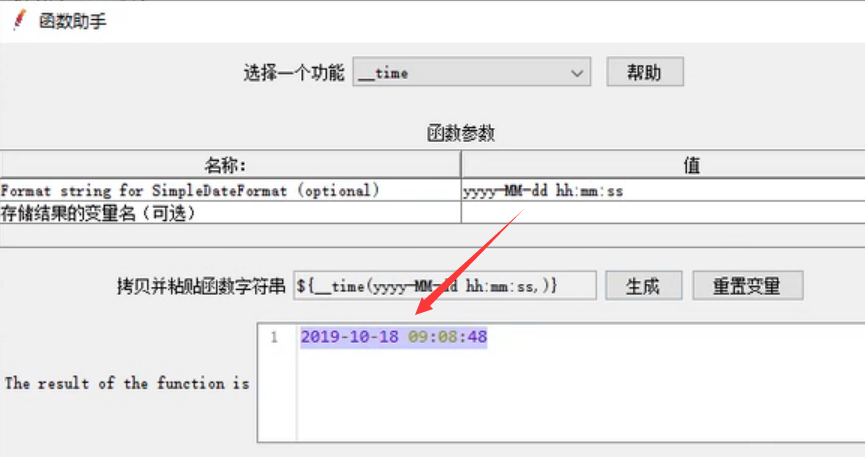
1、使用函数助手生成函数字符串,并复制
2、在对应位置粘贴函数字符串
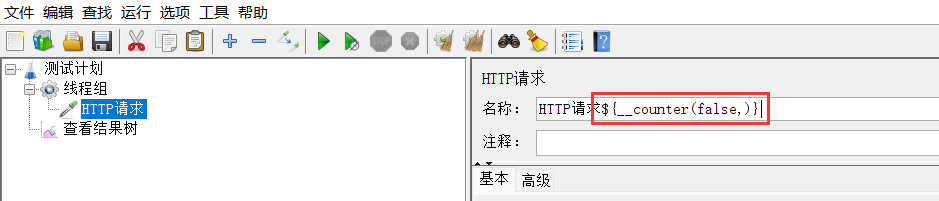
3、运行,查看效果
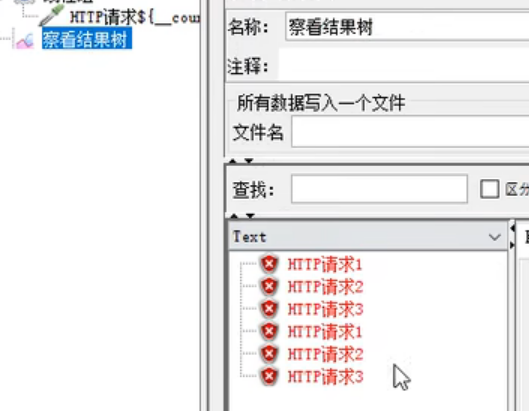
true的效果:
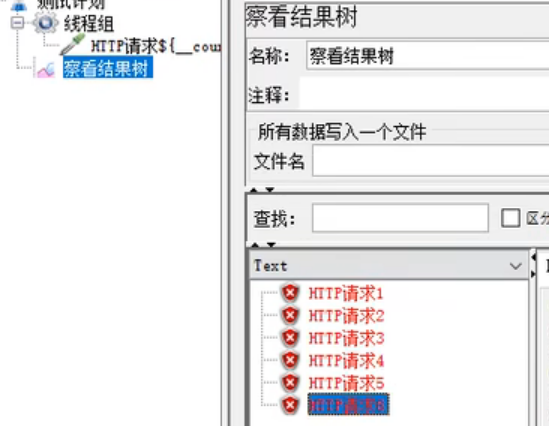
false的效果:
常用的函数
counter 计数器函数 TRUE(每个用户都有自己的计数器) FALSE(所有用户共用一个计数器)
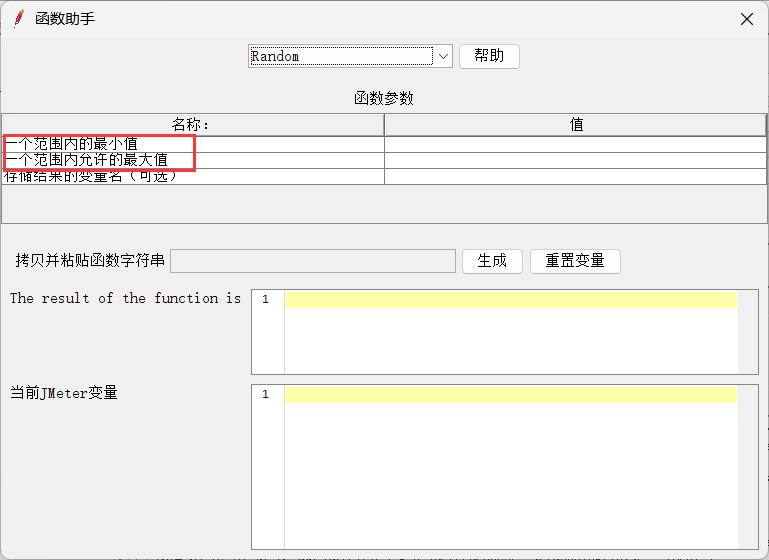
Random 随机数函数 参数1:取值范围最小值(包含) 参数2:取值范围最大值(包含)
__time 获取当前时间的函数 无参: 获取的是距离 1970/01/01 00:00:00 的毫秒值
参数1: yyyyMM_dd HH:mm:ss 格式化成 年\月_日 时:分:秒 格式
三、连接mysql数据库进行测试
目标:连接mysql查询数据,将查询出的数据放到必应上搜索
1、下载jmeter 连mysql 数据库需安装对应的驱动包
点击MySQL :: Download Connector/J
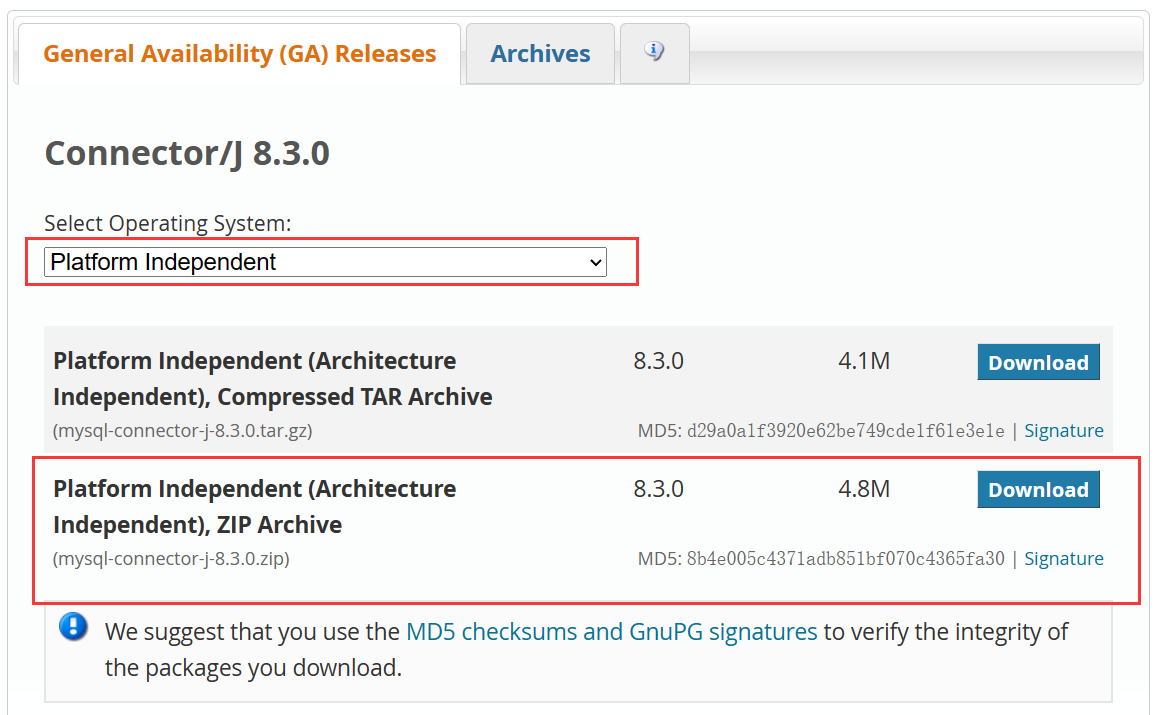
2、安装,下载完成后解压将放到jmeter的lib/ext下
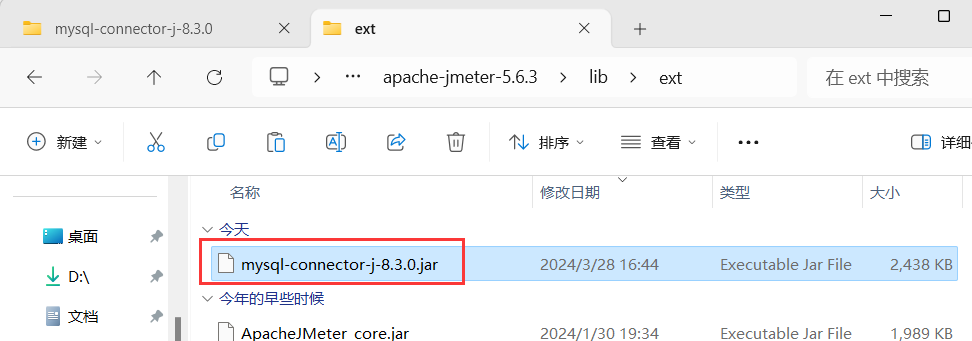
3、重启jmeter,添加库名
即添加刚刚放在lib/ext下的文件

4、添加配置元件-JDBC Connection Configuration
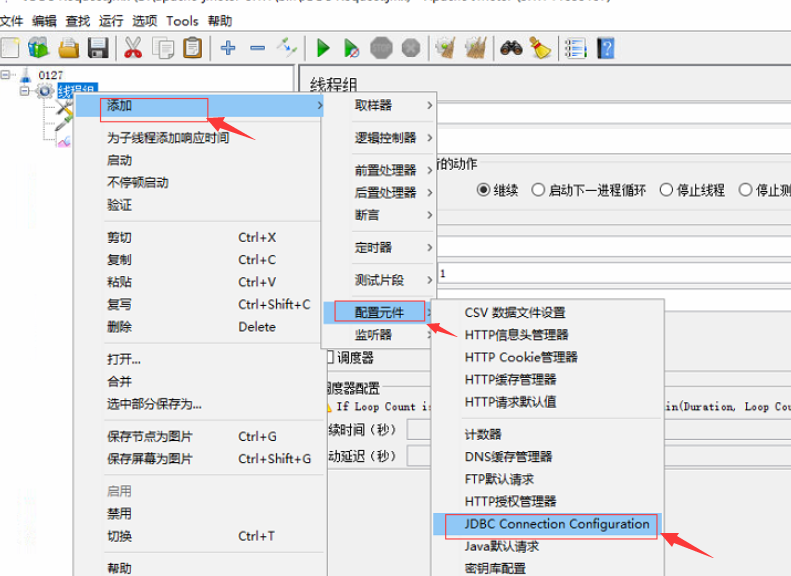
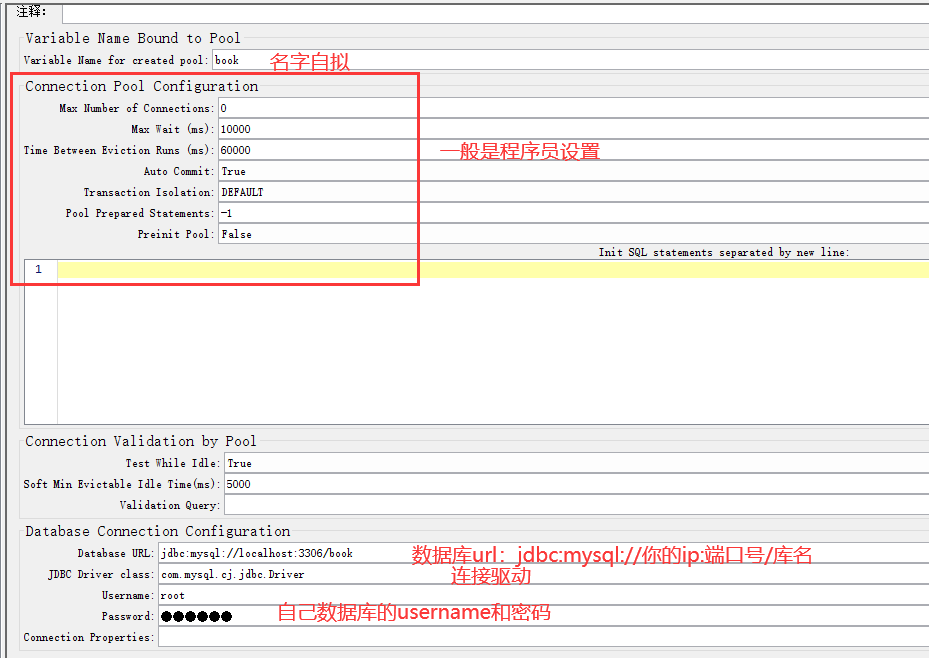
5、配置数据库的连接
-
Variable Name for created pool: 自己定义连接数据库的名称,自己知道是连的哪个数据库就行,如:jdbc_web
-
Database URL:数据库url,jdbc:mysql://主机ip:mysql监听的端口号/数据库名称, 如:jdbc:mysql://localhost:3306/book url后面的参数(可以不写)characterEncoding=utf8&useSSL=true&serverTimezone=UTC 设置时区和编码格式
-
JDBC Driver class:JDBC驱动,mysql5选com.mysql.jdbc.Driver,mysql8用com.mysql.cj.jdbc.Driver
-
username:登陆数据库的用户名
-
passwrod:登陆数据库的密码
6、添加jdbc request请求
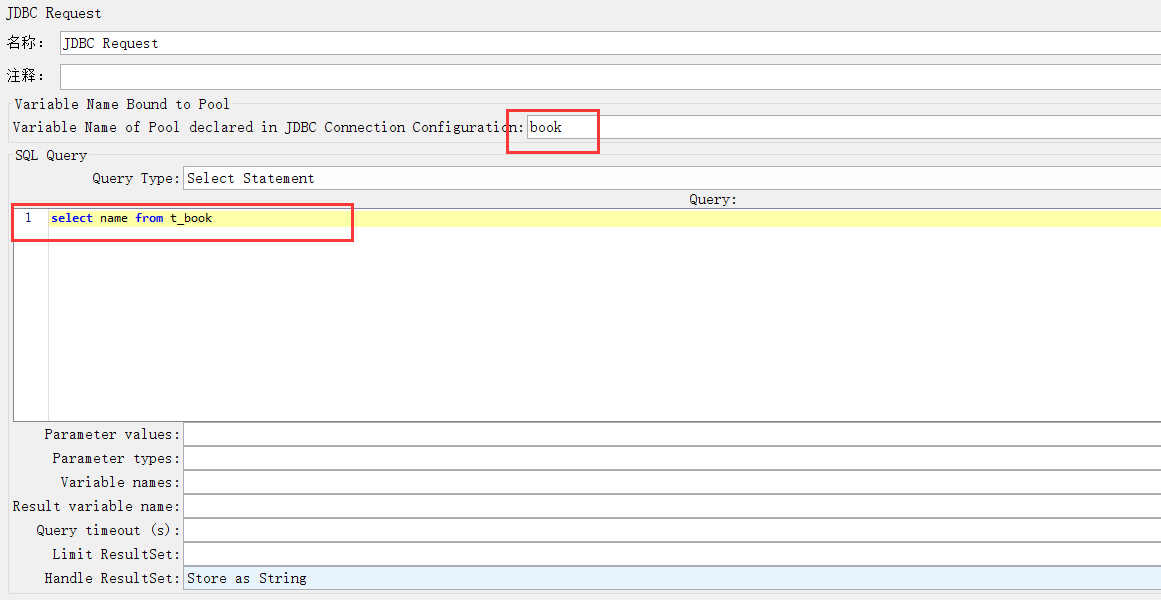
JDBC Request 请求里面写个简单的查询SQL验证下是否能查到数据
-
Variable Name for created pool 前面自己定义的连接数据库的名称
-
Query Type: 查询的sql选择 Select Statement选项
-
Query: 写个查询的SQL select name from book jmeter中写sql语句,末尾不建议用; jdbc request请求中,不支持写多条语句
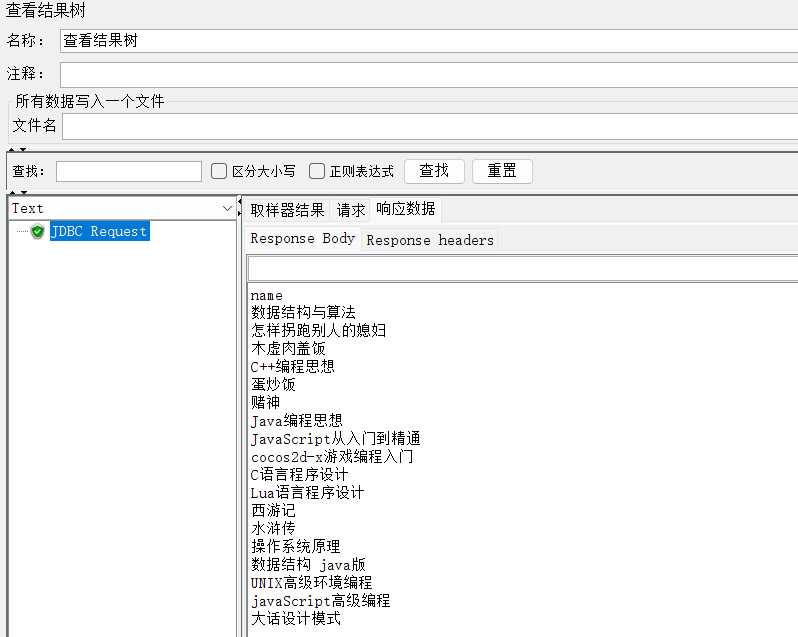
7、运行,查看结果
8、添加调试取样器
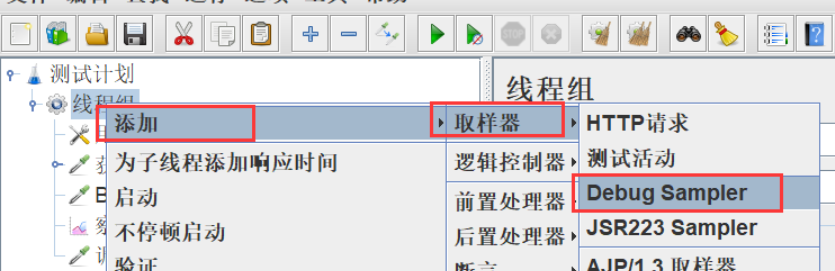
9、设置变量名
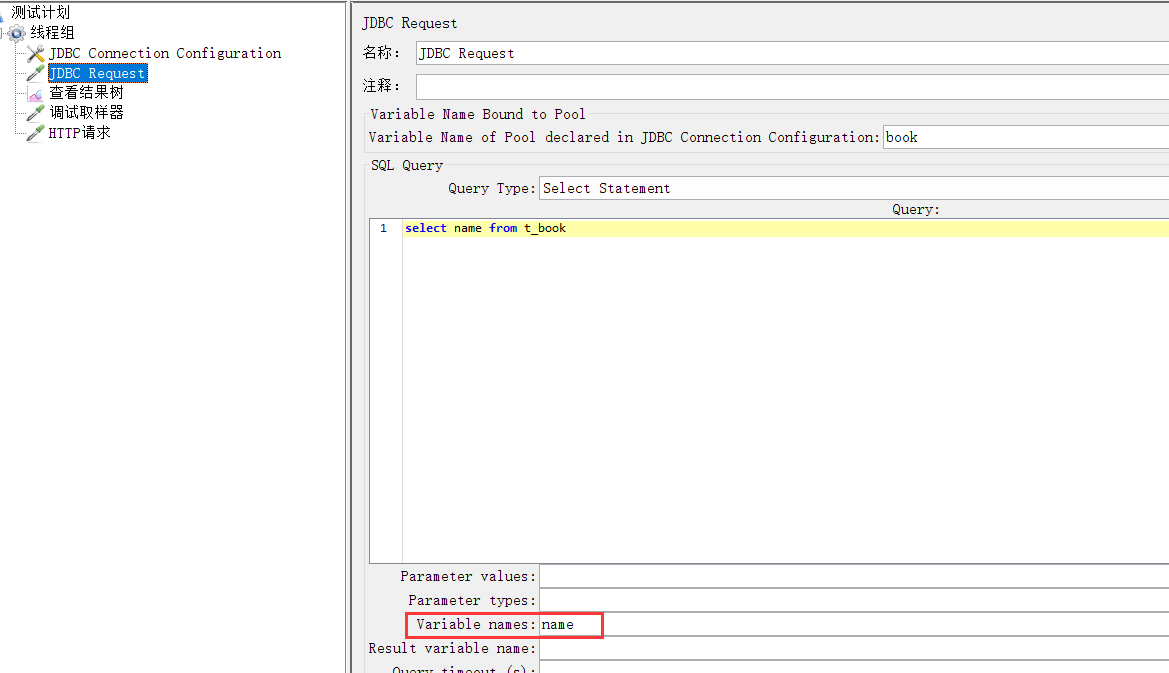
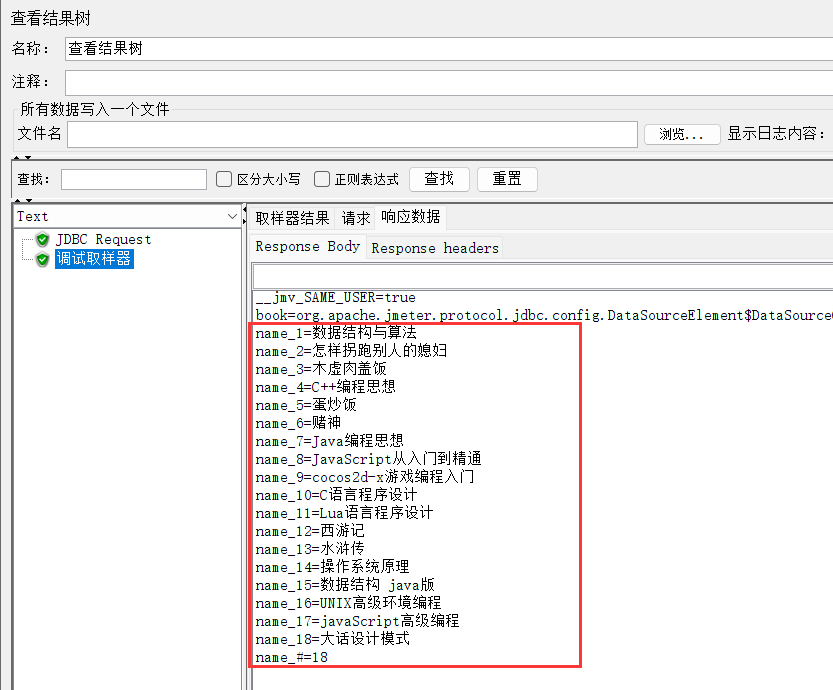
10、运行,查看结果
11、创建http请求

还是用${key_name}取我们的变量
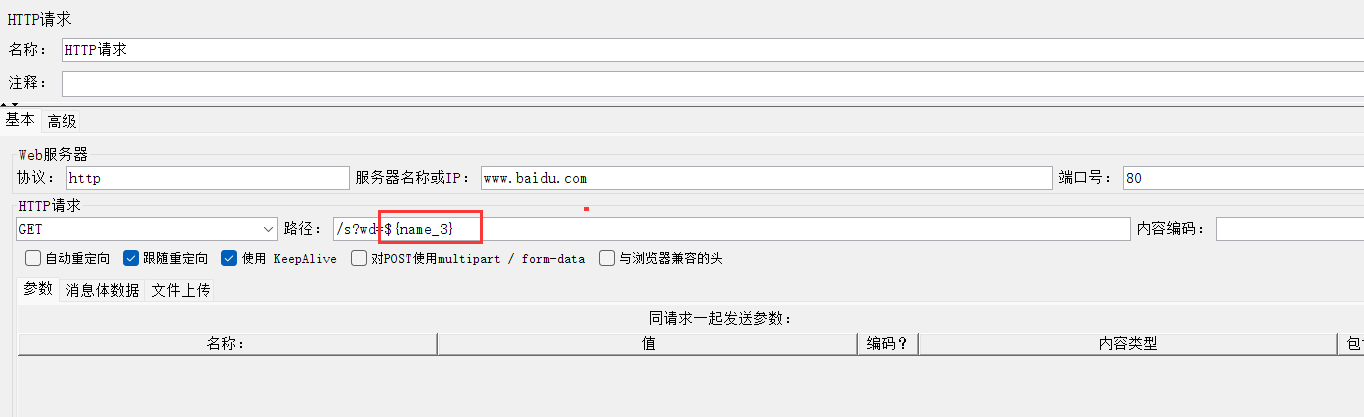
12、运行,查看结果
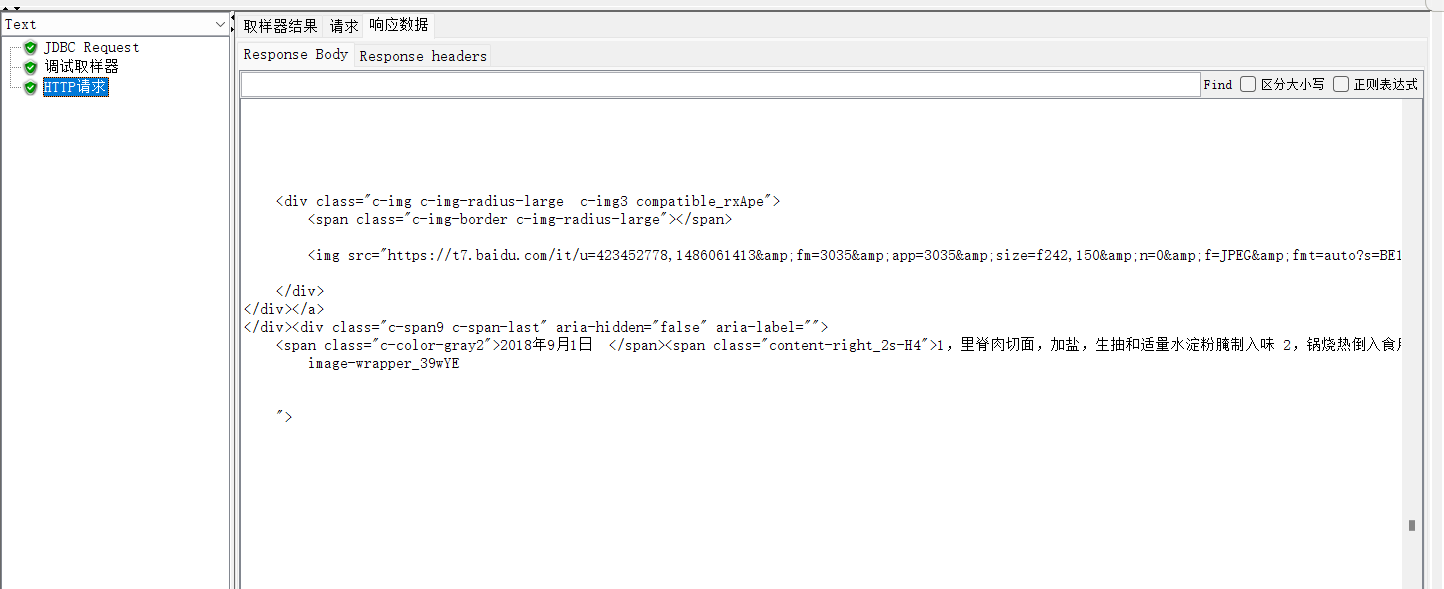
四、断言
断言:让程序代替人工判断响应结果是否符号预期
分类:
响应断言 = 断言状态码和响应体
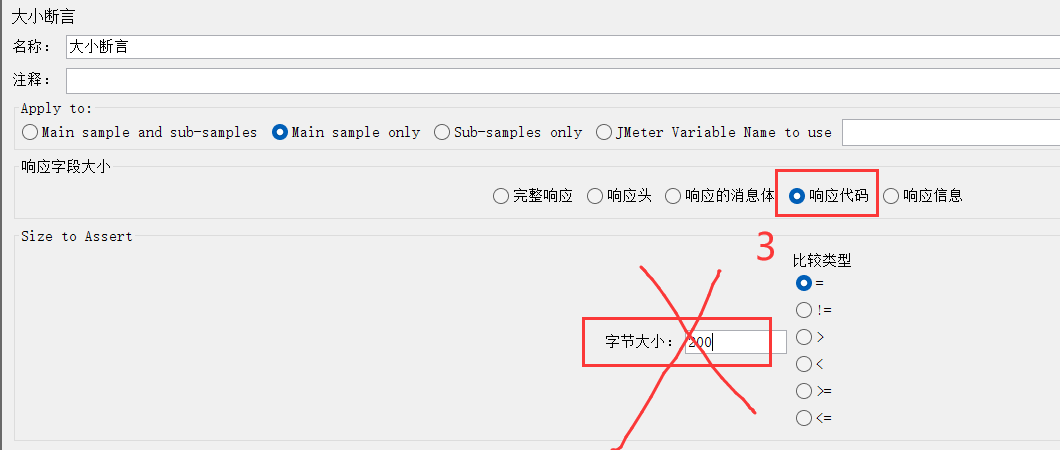
大小断言 = 判断响应内容的字节内容
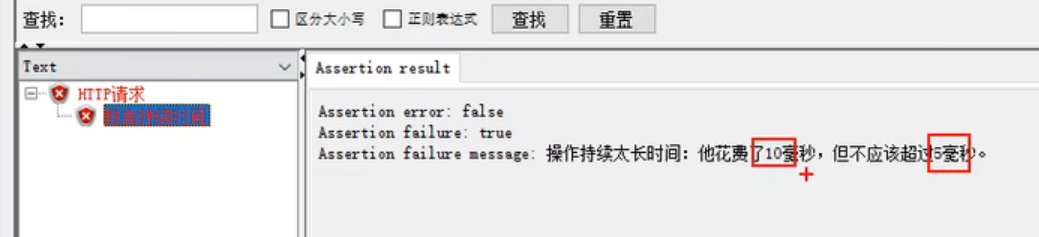
断言持续时间 = 判断响应时间
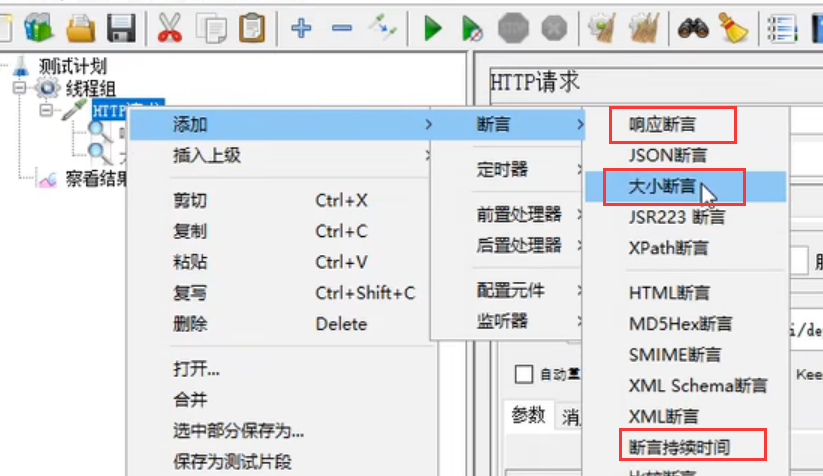
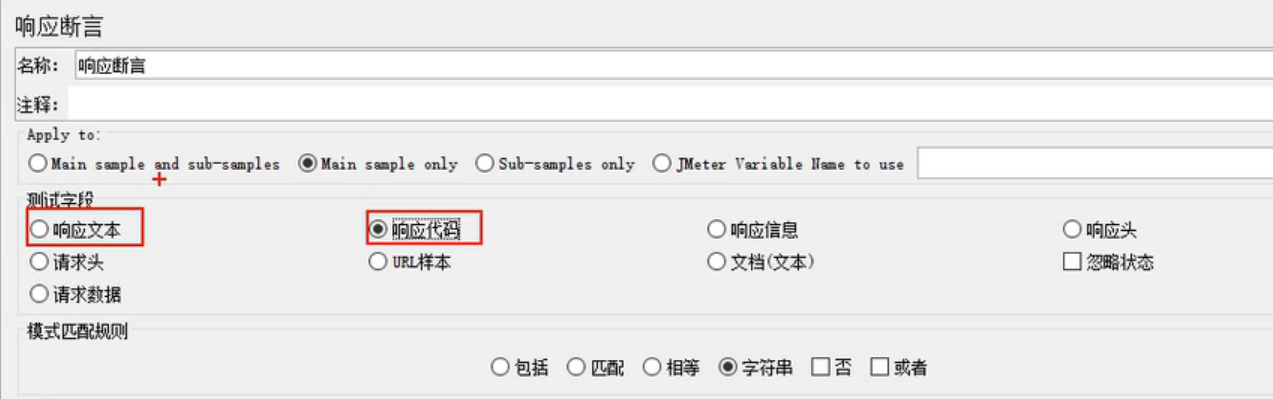
响应断言
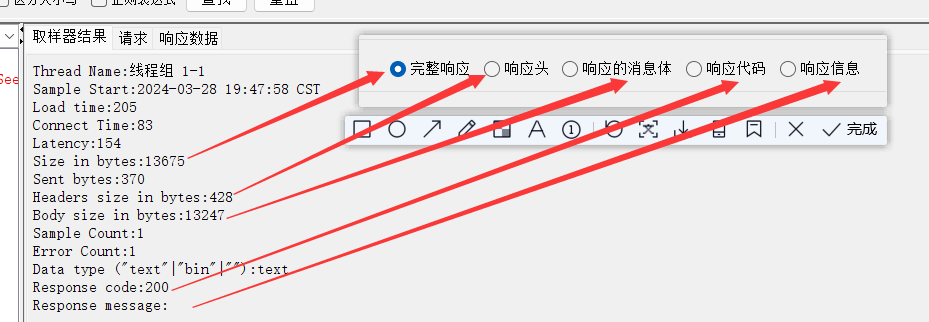
最常用:响应文本和响应代码
目标1:判断查询到的数据是否包含Docker123
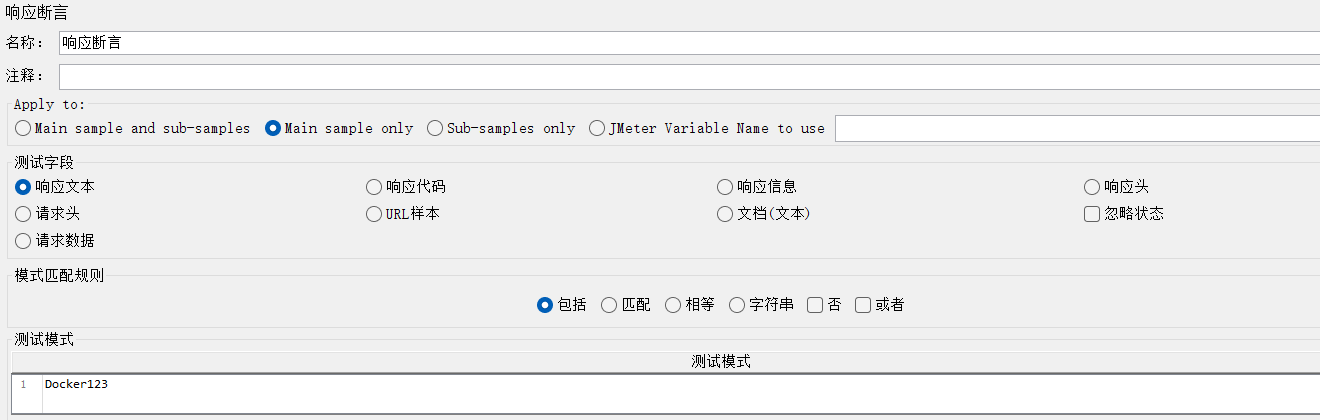
只有断言失败才会显示结果。

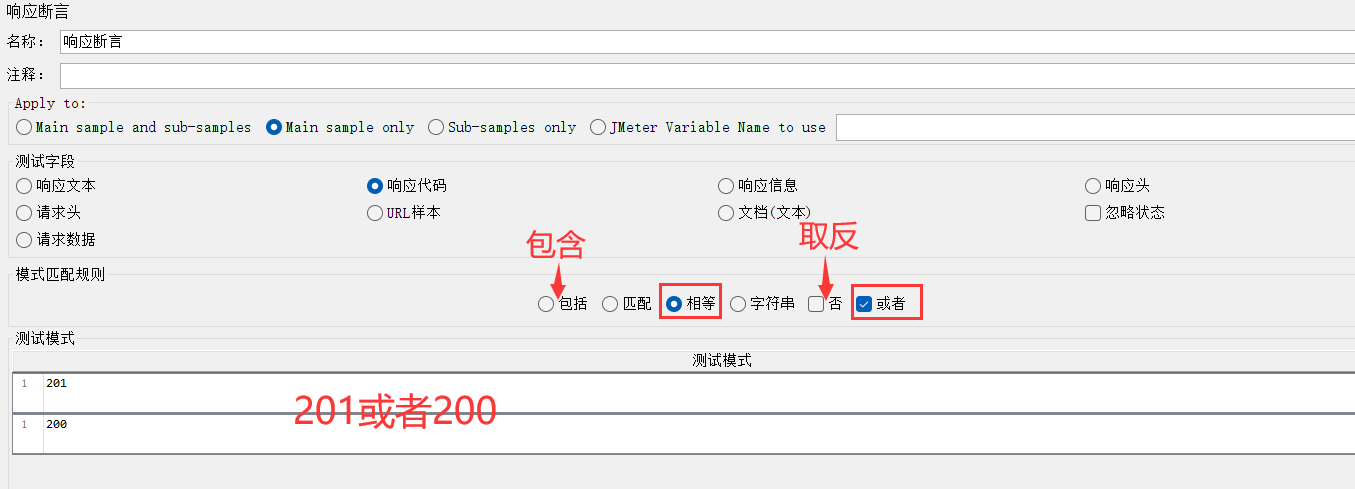
目标2:判断响应码是否是201或者200
大小断言
注意200
断言持续时间
响应时间。注意单位是毫秒,要会计算。

第二篇:Jmeter进阶使用
一、逻辑控制器
1、IF控制器
目标:如果val的值为hh123,则访问百度,反之不访问。
1、添加线程组、添加http请求、添加结果树、添加用户定义的变量

2、添加IF 控制器
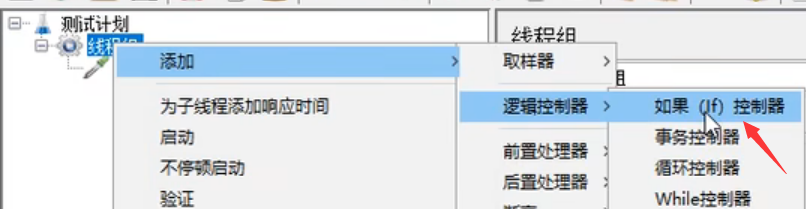
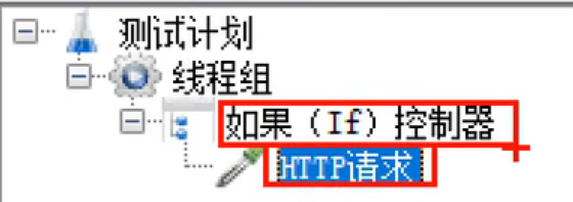
注意一定要将http请求放到if控制器的目录下!
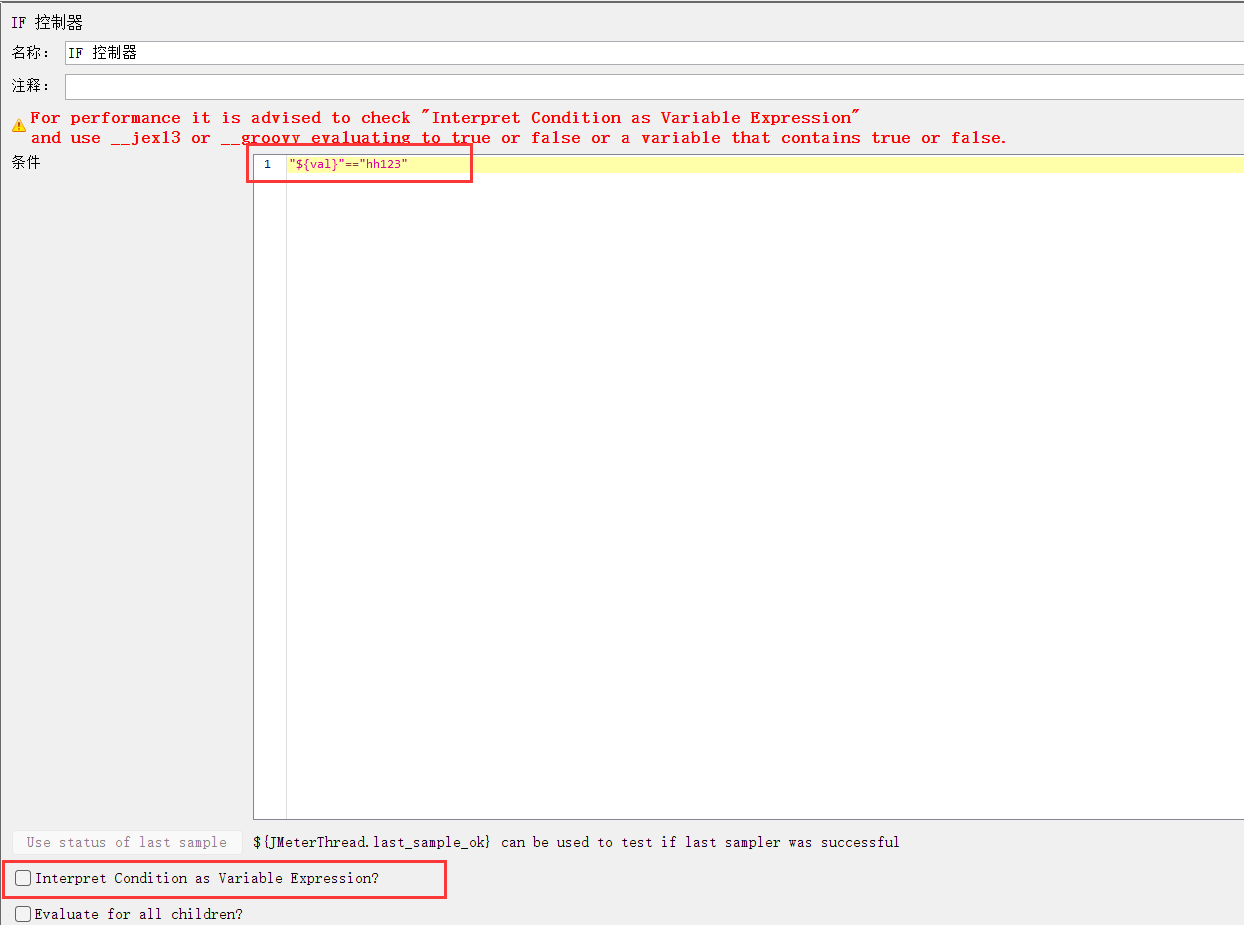
取消勾选Interpret Condi tion as Variable Expressi on?
注意语法:
"xxx" == "xxx"
2、ForEach控制器
目标:for循环百度搜索三个值
1、添加线程组、添加http请求、添加用户自定义变量
名称要按这个格式

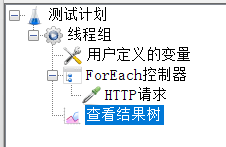
2、添加ForEach控制器
注意一定要将http请求放到ForEach的子目录
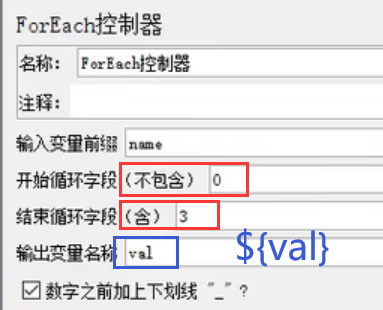
3、添加结果树,运行,查看结果

3、循环控制器
目标:访问百度10次,访问必应5次
直接在线程组设置循环次数,不可以做到对请求1循环10次,对请求2循环5次。

1、添加循环控制器
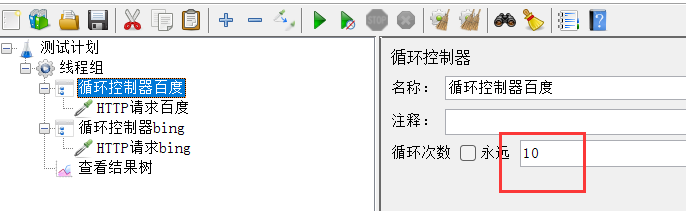
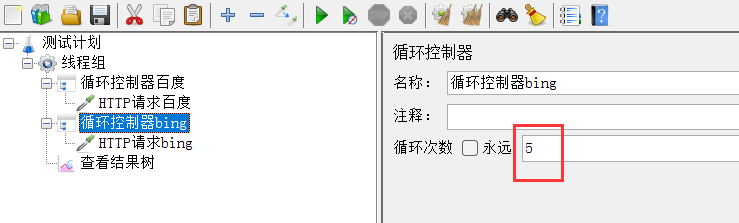
2、运行,查看结果
二、关联
关联:上一个请求的响应结果和下一个请求的数据有关系
1、xpath
目标:两个http请求,请求A访问博客主页,请求B访问百度,将请求A的title作为请求B的关键字搜索这个城市。
1、为第一个http请求添加XPath提取器
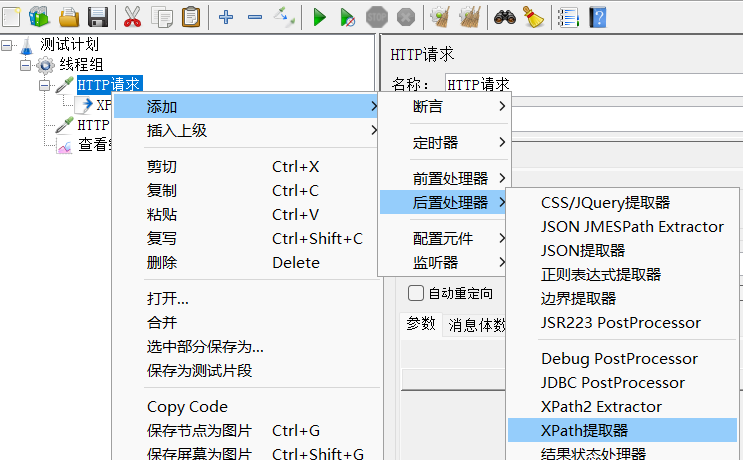
2、核心: 取出传智播客页面源码的 title 值
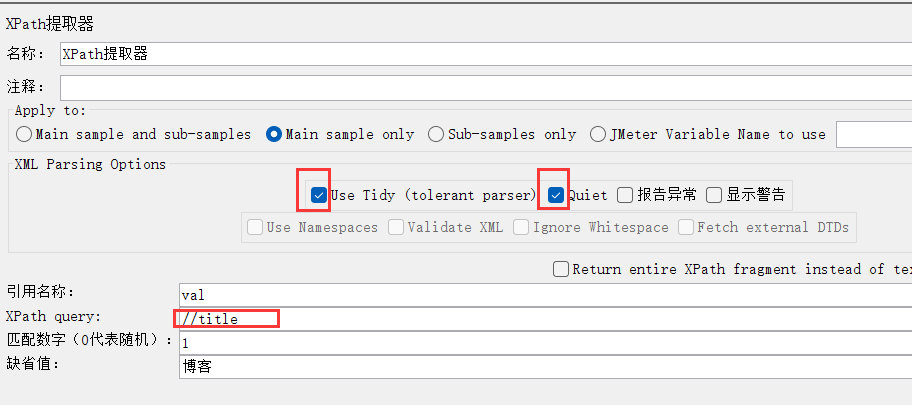
匹配数字:-1全部,1匹配第一个,2匹配第二个。
缺省值:如果我没有找到tilte,就返回博客。
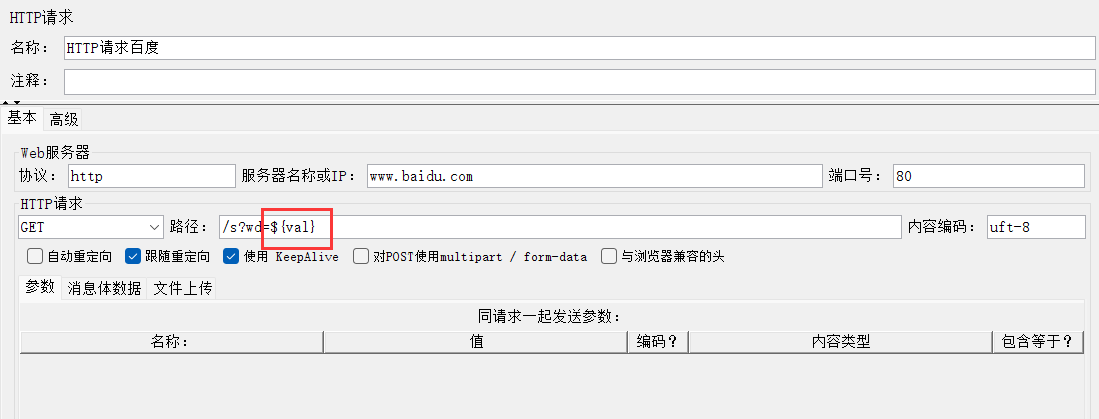
3、传递给百度:${变量名} 的方式传值
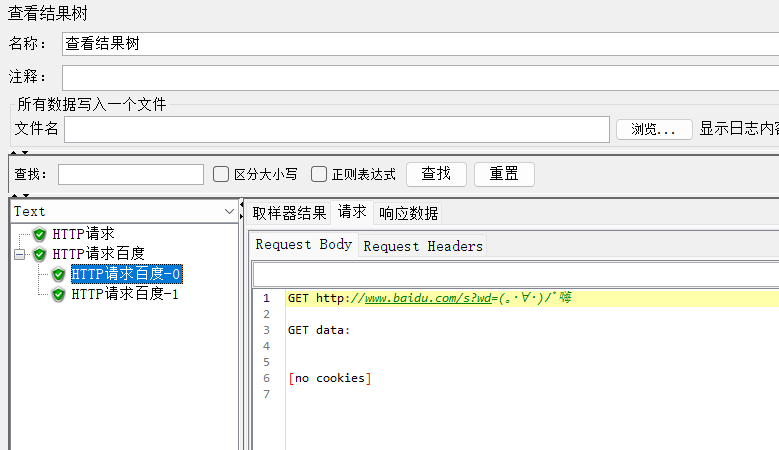
4、运行,查看结果
2、正则表达式
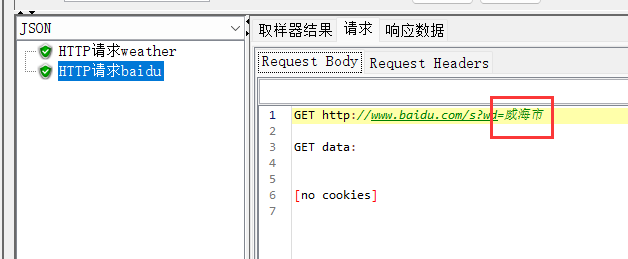
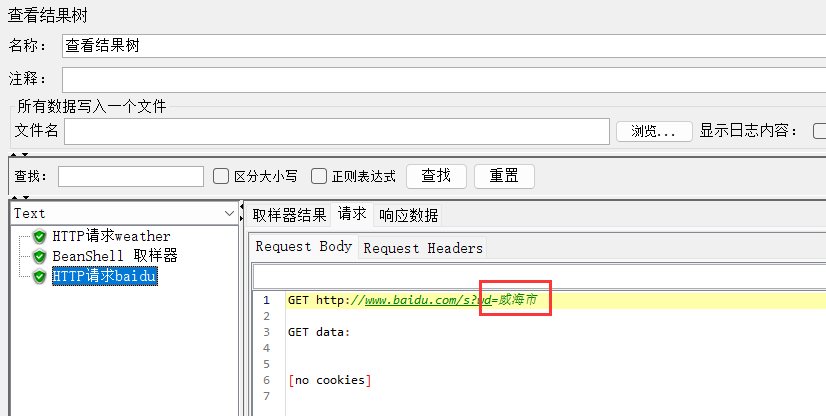
目标:两个请求,请求A访问查询天气,请求B访问百度,将请求A响应数据的city作为请求B的关键字搜索。
1、为请求A添加正则表达式提取器
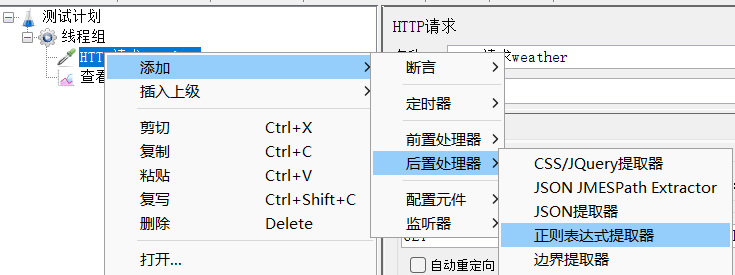
2、写正则表达式
注意千万不要加空格!!!空格是json格式人为加了空格。

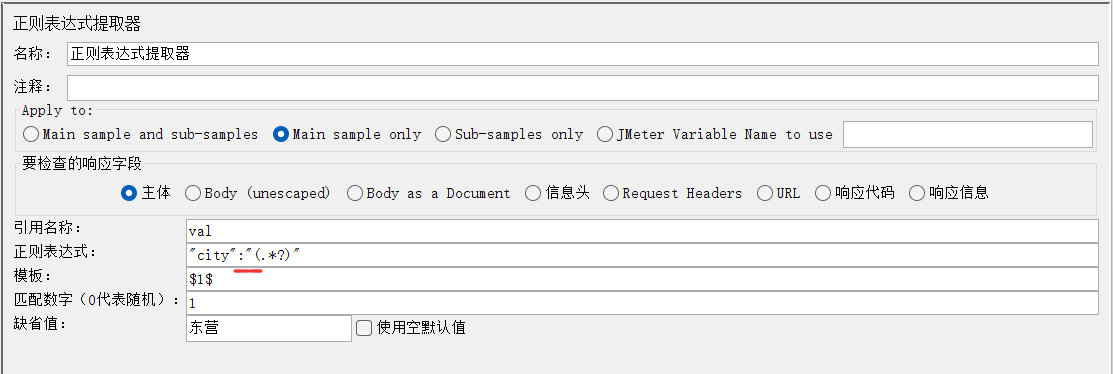
数字代表想选择匹配哪个表达式。
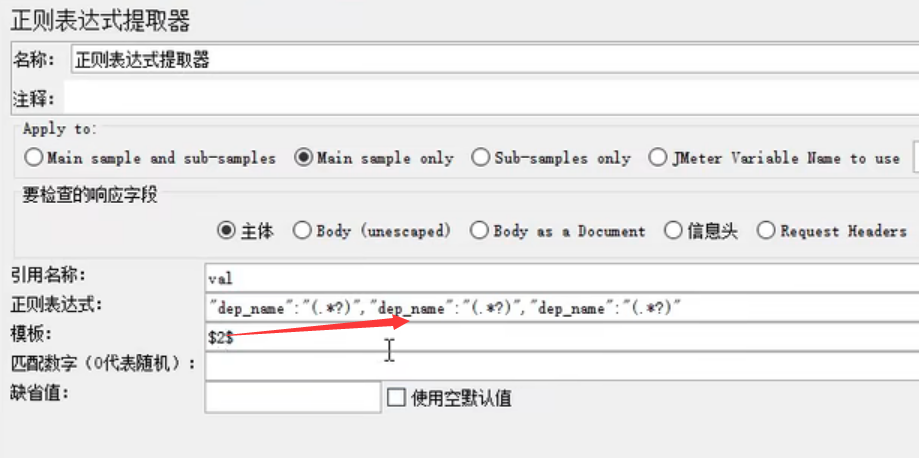
不加?是贪婪模式。匹配到不会停止

3、运行,查看结果
三、跨线程组传值
变量作用域局限于当前线程组,其他线程组不可以直接调用。可以将请求A中提取的结果导出到公共空间 (可以被不同线程组共享),请求B再从公开空间调用该变量,相当于全局变量。
1、将请求A的数据导出到公共空间( setProperty)
调用函数助手,复制字符串
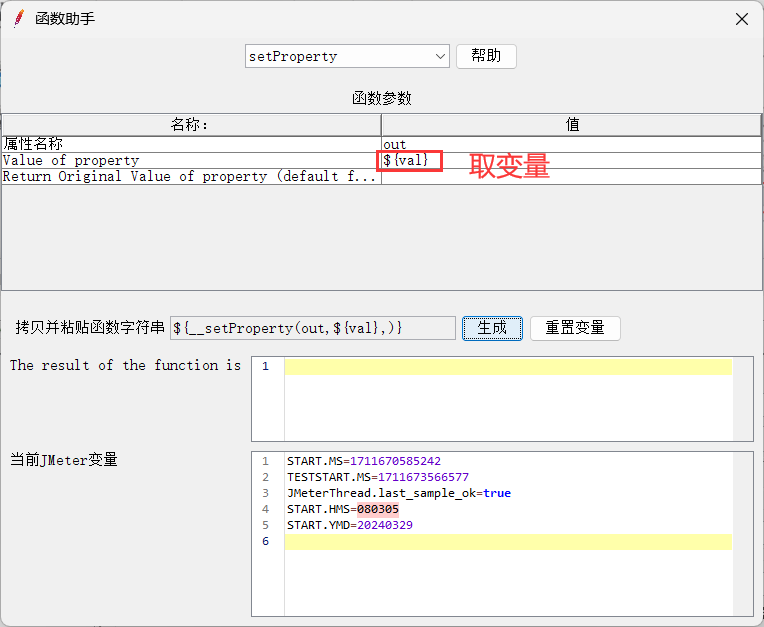
2、添加BeanShell取样器,设置全局变量
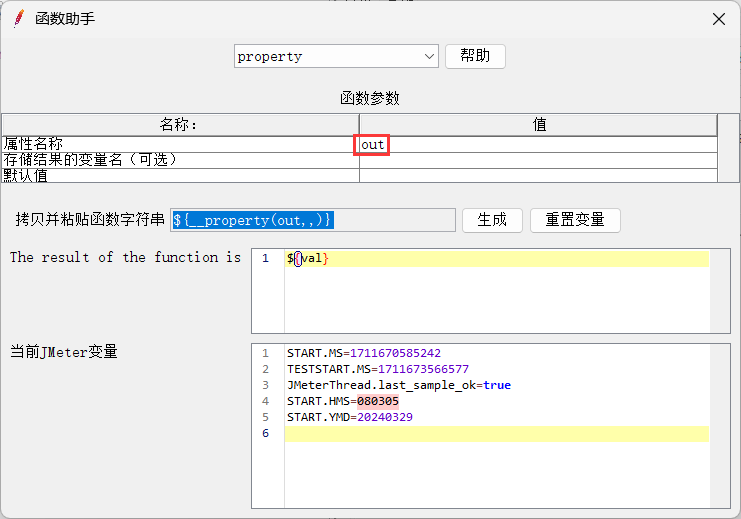
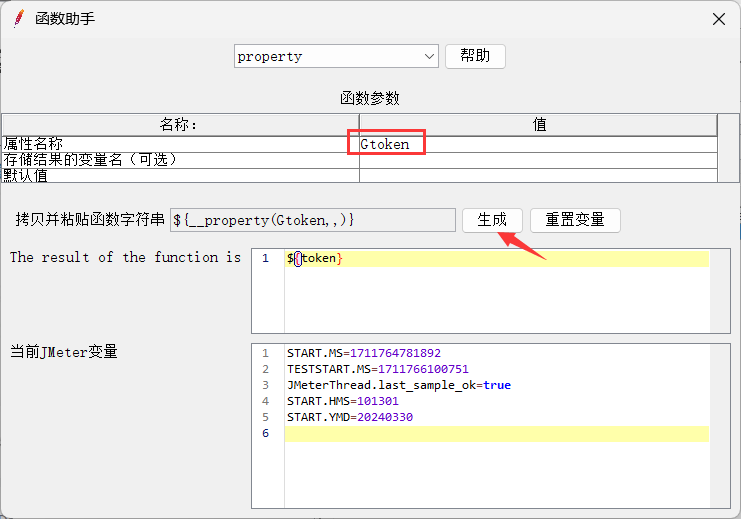
3、请求B从公共空间调用数据 (property)
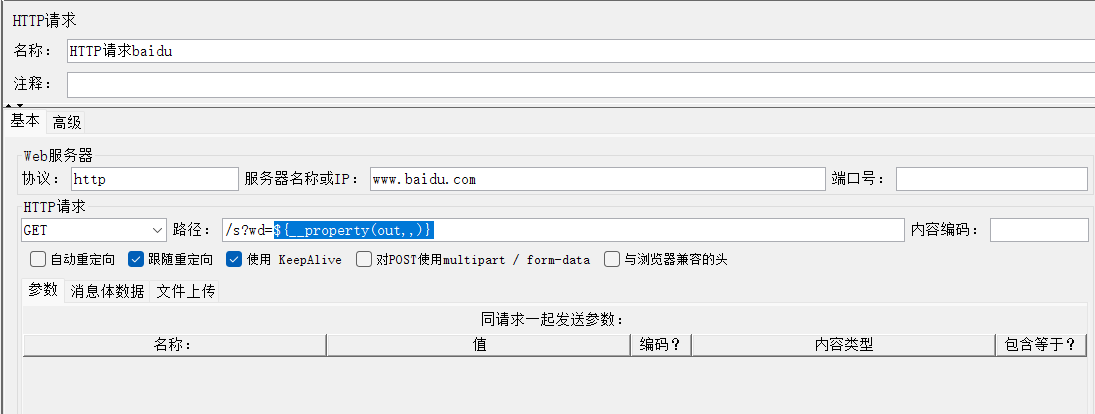
4、放入百度请求的路径中
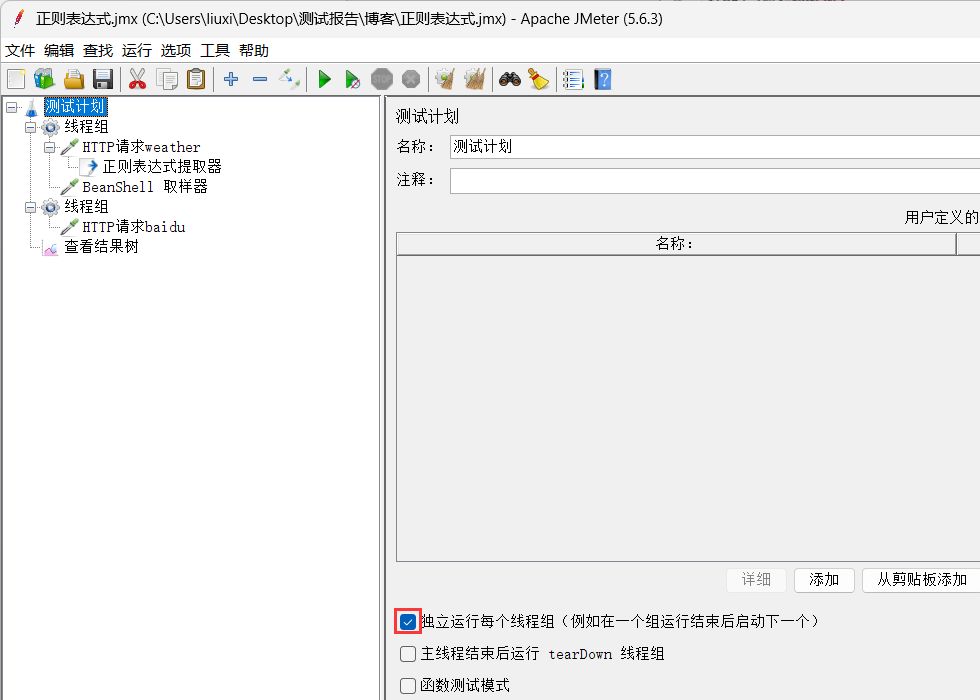
5、勾选独立运行每个线程组
6、添加查看结果树,运行
四、高并发
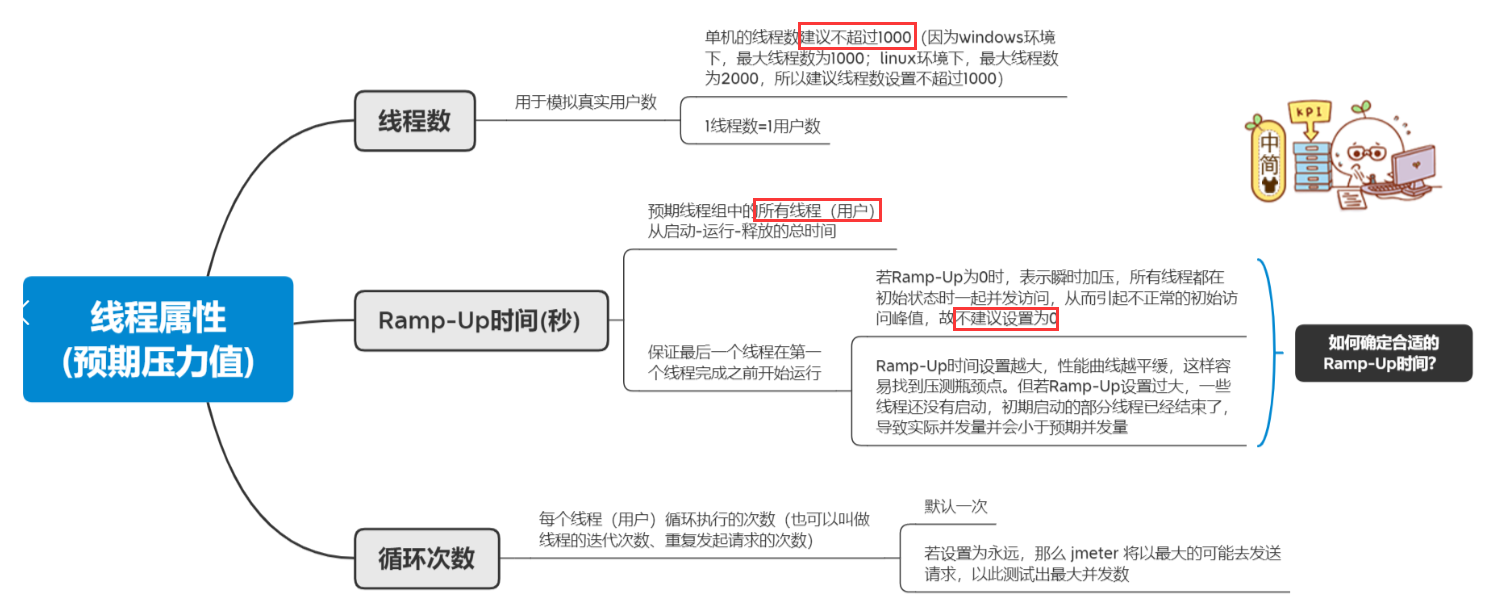
JMeter 中内置了定时器,可以实现时间模式相关的性能测试。
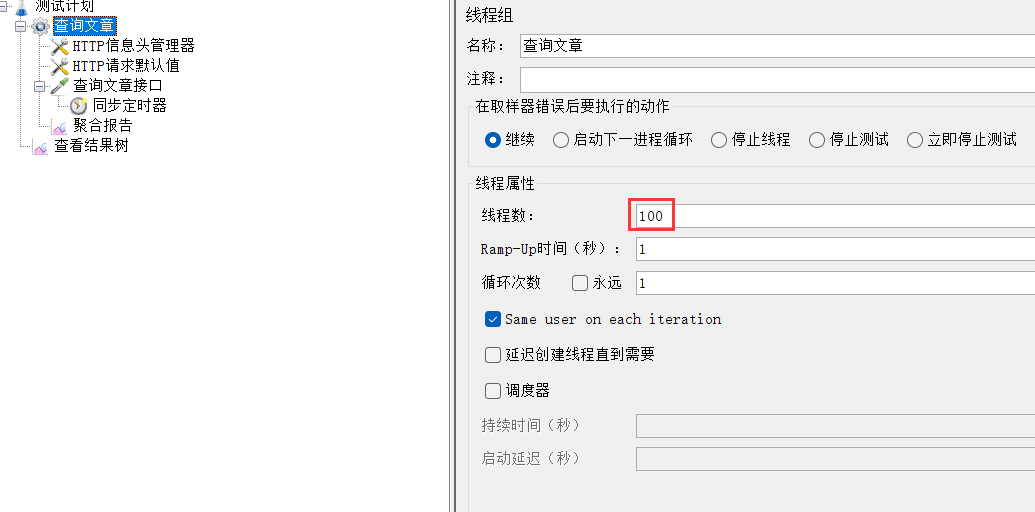
目标:同一时刻 100 个同学去访问个人博客系统的查询所有文章信息功能,统计高并发情况下平均响应时间以及错误率(高并发)
1、搭框架,测试计划,线程组,取样器,结果树(局限性),指定线程组的线程数属性值为 100
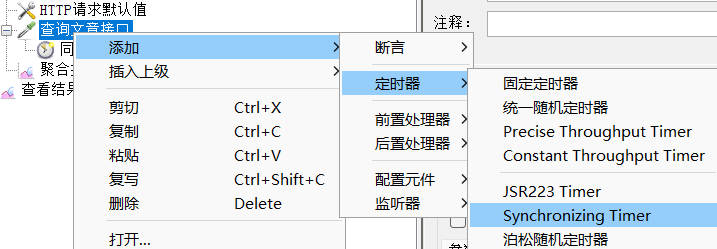
2、添加定时器 synchronizing timer(集合点组件)
模拟用户组的数量:总共100个人为一组一起访问
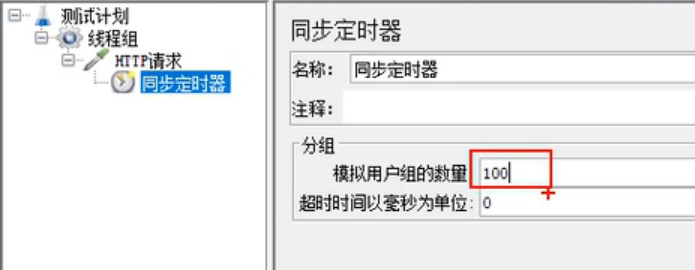
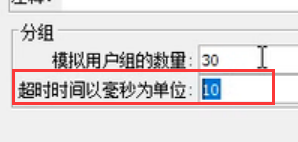
推荐将超时时间以毫秒为单位设定一个数,不为0,防止死等。如果30为一组,且将超时时间设为0,100个人除不尽,最后10个人会不进行请求。但是绝大多情况会设置为除尽的。
3、运行并查看结果查看:聚合报告组件,可以对结果汇总分析

五、高频率
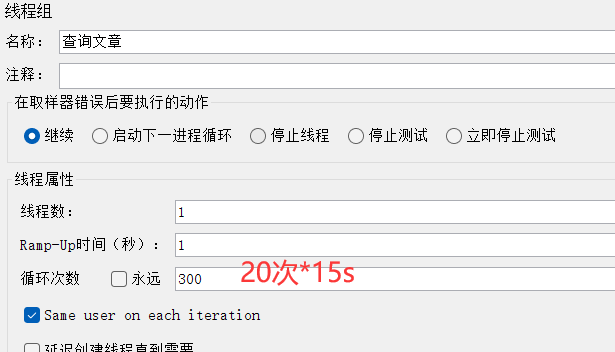
目标:一个用户以 20QPS ( == 20 次/s) 的频率访问个人博客系统服务器,持续15秒,统计服务器的平均响应时间
QPS: Query per Seconds 每秒查询数(查询率),每秒访问多少次服务器
1、搭框架,测试计划,线程组,取样器,聚合报告,根据题干计算数据: 循环次数 = 访问频率 * 持续时间
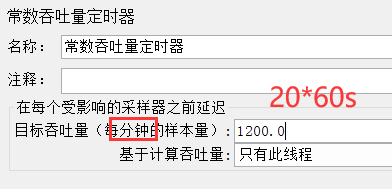
2、添加QPS访问频率控制的相关组件: 每分钟访问次数 = 访问频率 * 60
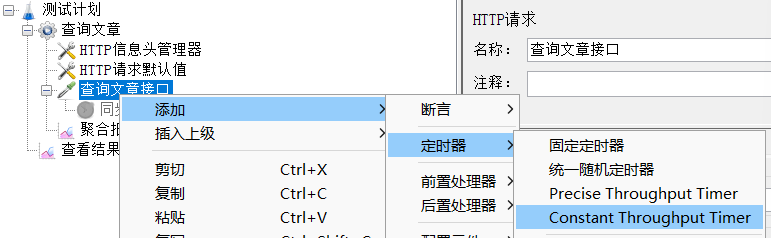
3、运行,查看聚合报告

博客增删改查自动化测试
Jmeter JDBC Request 使用详解 - EdisonYao - 博客园 (cnblogs.com)
Jmeter之JDBC Request及参数化 - 吓吾一跳 - 博客园 (cnblogs.com)
标签
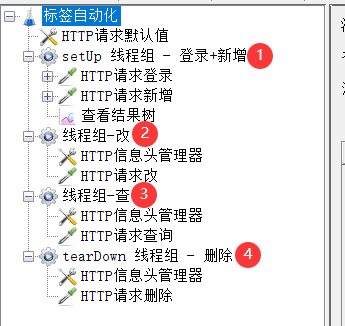
一、自动化脚本架构搭建
1、添加setUp线程组,测试标签新增功能;添加tearDown线程组,测试标签删除功能
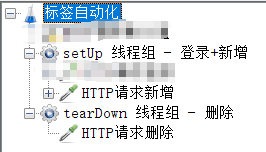
这里可以将标签的增删改查写到一个线程组,但是为了实践setUp和tearDown线程组的使用,将它们写到不同线程组中了。
2、添加登录http请求获取token
(1)添加登录http请求
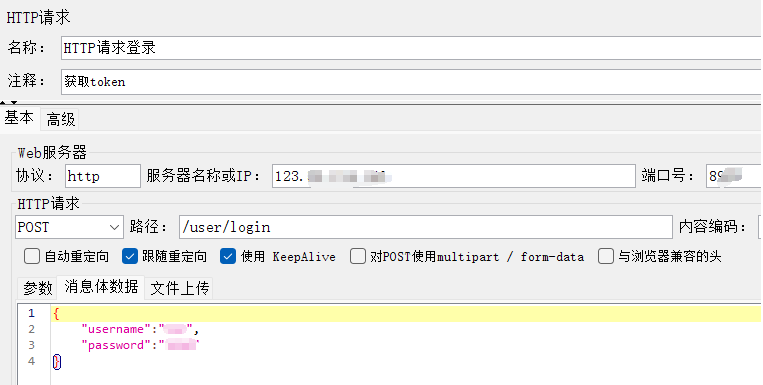
(2)添加查看结果树可以看到登录的响应数据有token

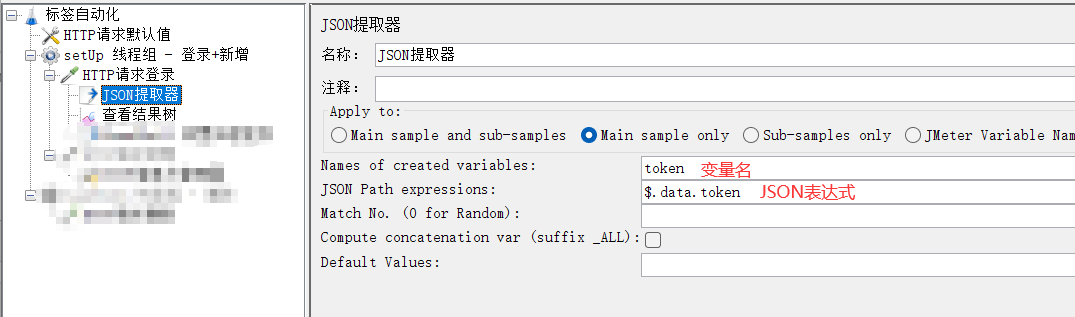
(3)添加JSON提取器提取token
截图左边把还未添加的先注释掉了
(4)利用函数工具生成字符串,添加BeanShell 后置处理程序设置token为全局变量
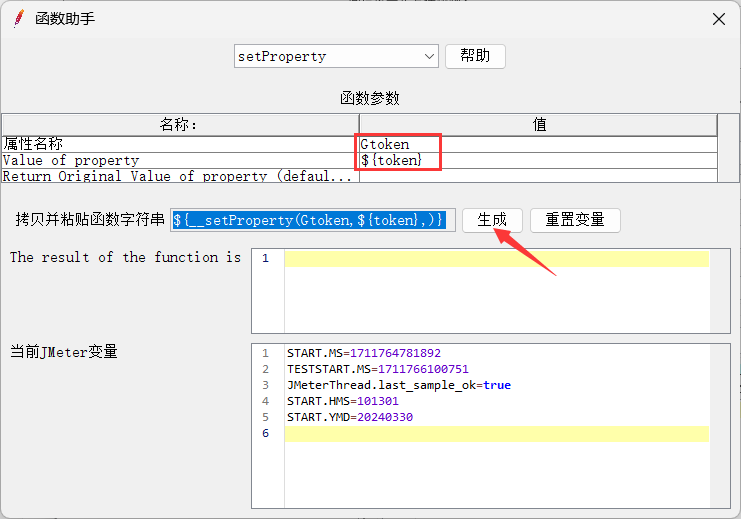
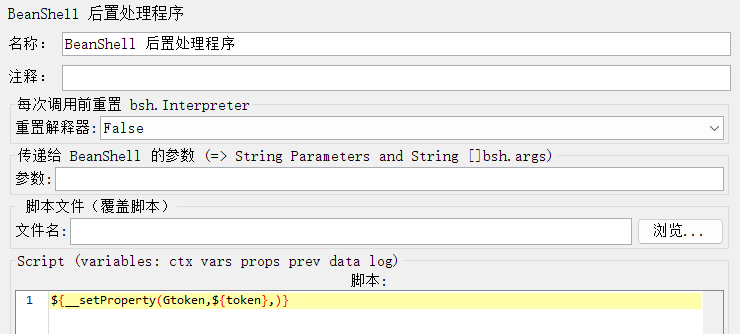
(5)利用函数工具生成字符串,在别的接口的请求头信息中引入token
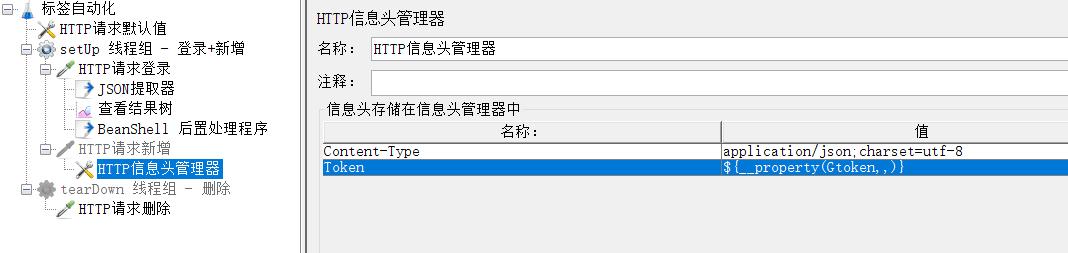
3、添加标签新增http请求
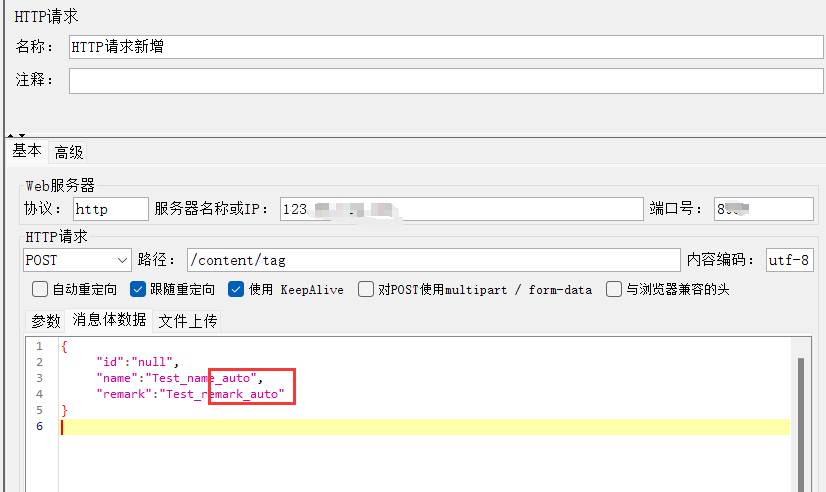
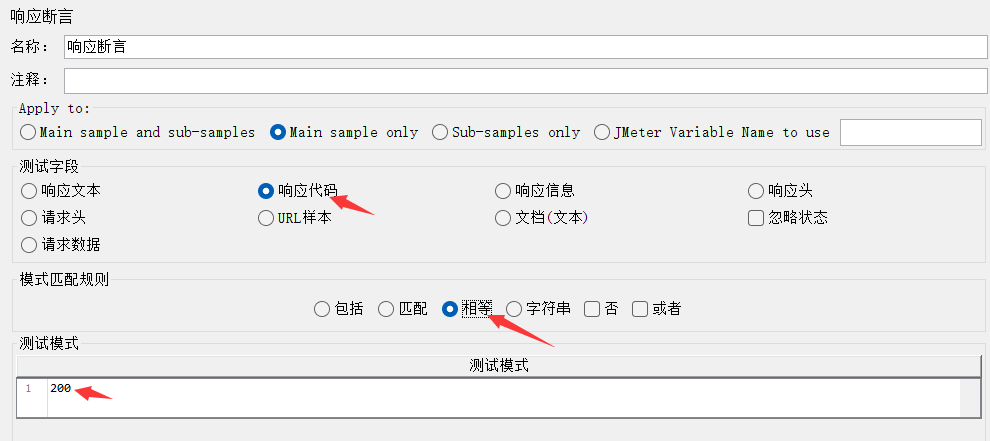
添加响应断言:
新增的数据是json格式,需要在请求头中添加Content-Type
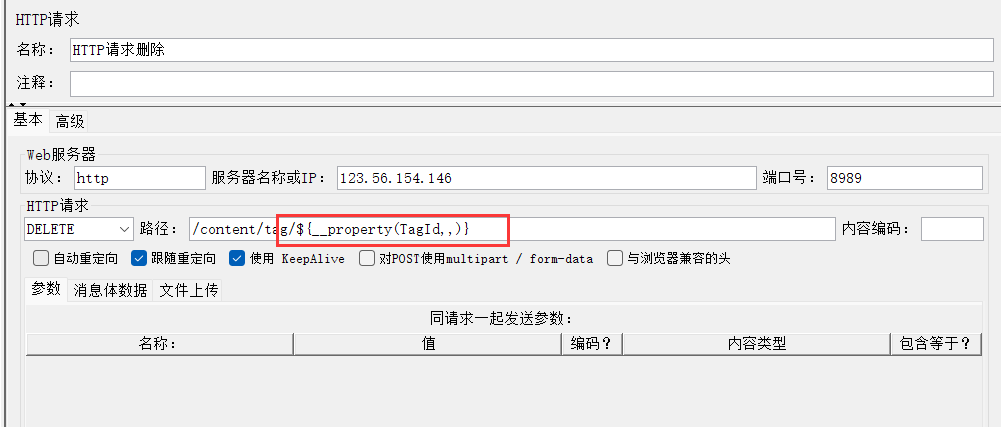
4、添加标签删除http请求

对于重复的内容,我们可以添加请求默认值复用
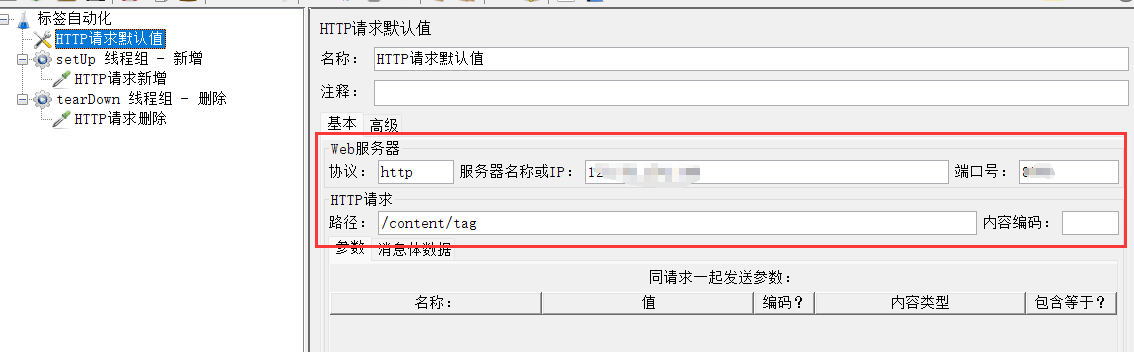
5、添加改、查线程组
勾选独立运行每个线程组保证先改后查
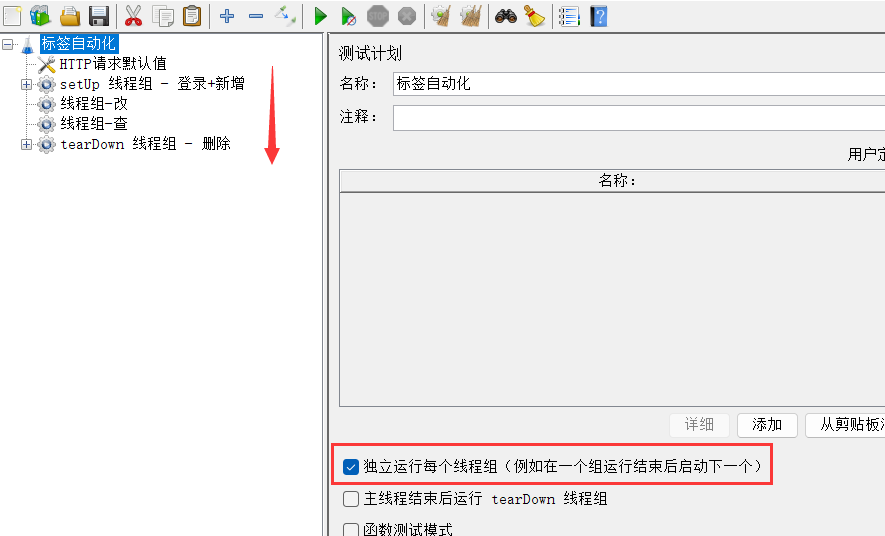
6、添加改、查的http请求
二、增删改查接口测试
1、将新增外的线程组都禁用,测试新增接口是否成功
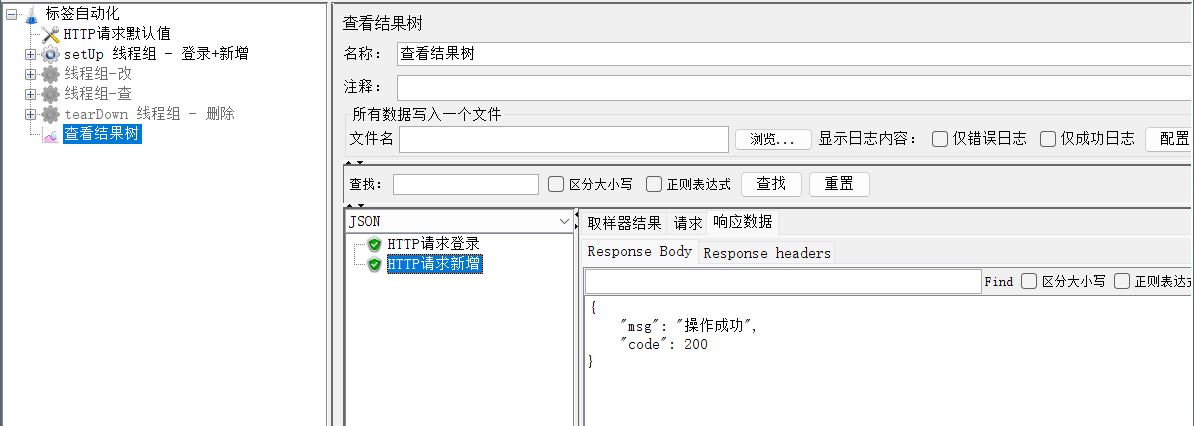
2、查询新增数据name对应的id
原打算将插入数据的id设置为全局变量,让其他改、查、删接口对该id的记录执行操作,这样保证了脚本运行完毕后不对原本数据产生影响。
但是我的博客系统的id采用自增id,无法自己设置id,插入数据。于是我想到先去数据库查询添加的数据name对应的id,然后再将id设为全局变量,对该记录进行改、查、删。
这样迂回的获取到id可能降低脚本的运行时间,可以在数据库给name字段增加索引,提高查询效率。
步骤:
(1)添加mysql库包
库包下载可参考我的另一篇文章(。・∀・)ノ゙嗨 (测试工具——Jmeter从入门到实践学习笔记)
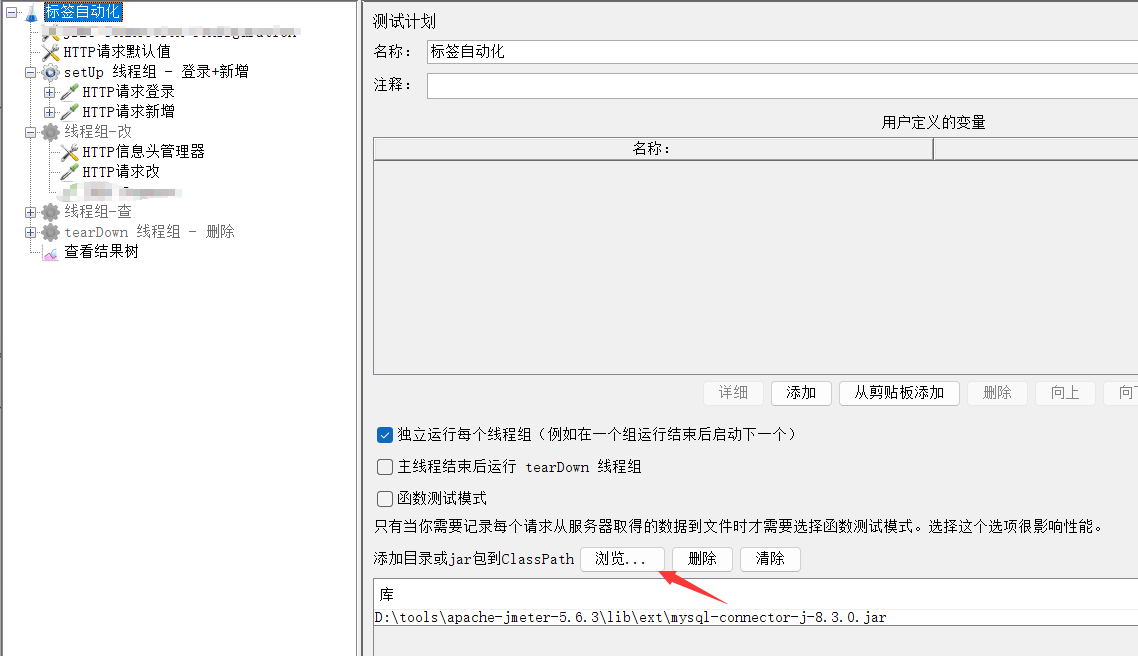
(2)添加JDBC Connection Configuration配置数据库的连接

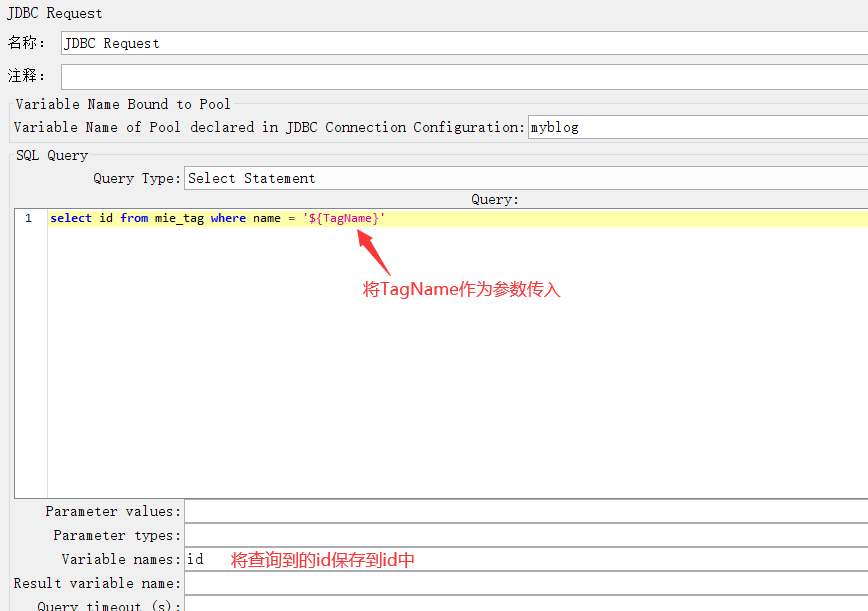
(3)添加JDBC Request
注意:这里为了方便将TagName作为参数使用,新增了用户定义的变量。此外,这里将TagName和TagRemark参数化,便于之后统一更改测试内容。

(4)添加调试取样器,禁用不相关的线程组,运行一下,查看参数名
可以看到id_1的值正是我们想要的值
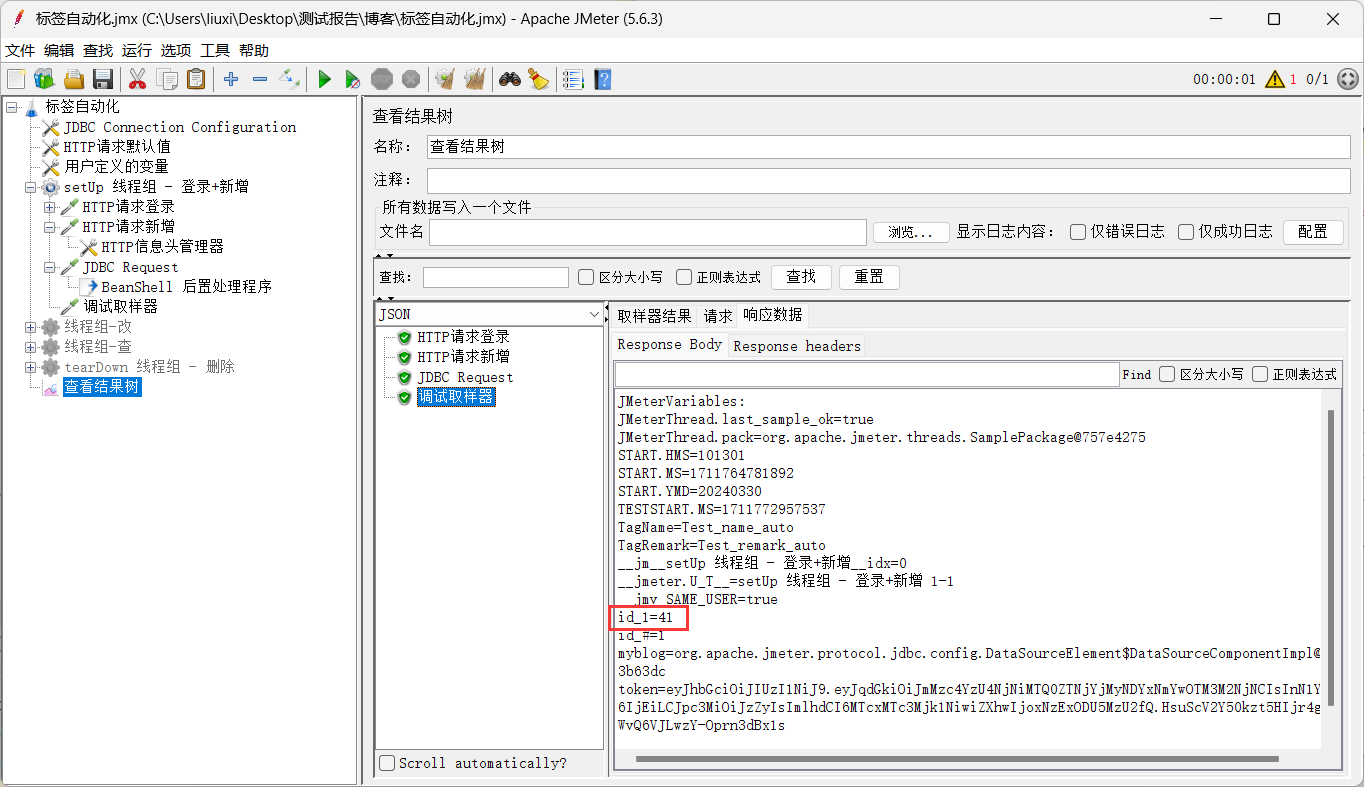
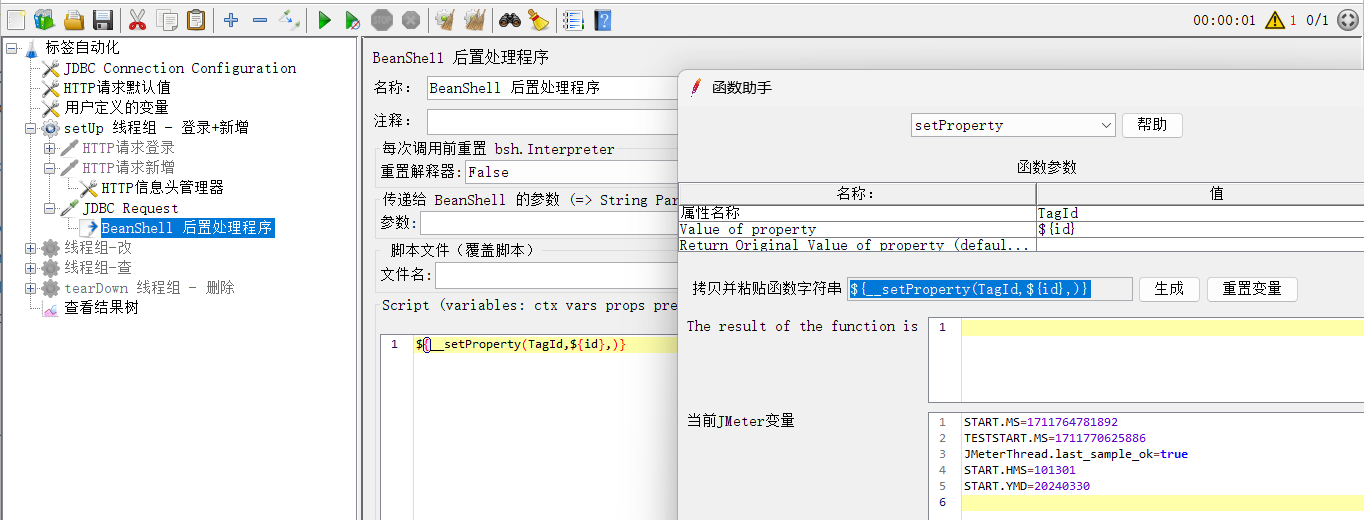
(5)添加BeanShell 后置处理程序,将id_1设置为全局变量
使用函数工具生成字符串复制到BeanShell 后置处理程序中
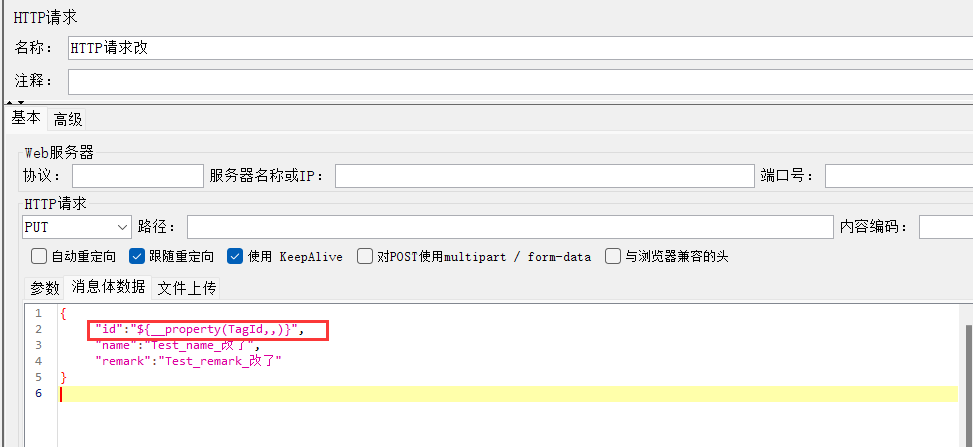
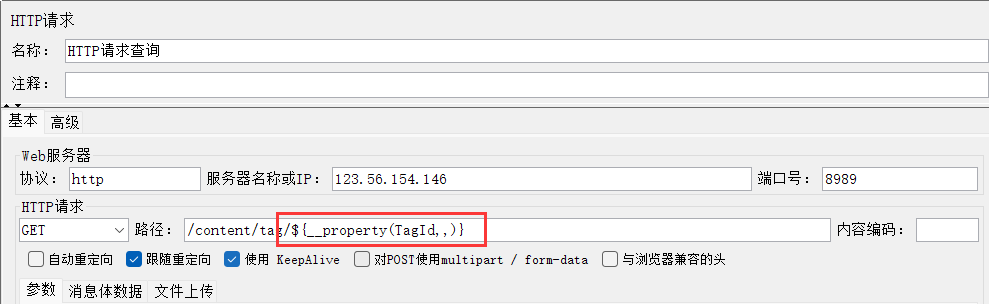
(6)将全局变量取出使用
在改http请求中:
在查http请求中:
3、测试修改接口是否成功

4、测试查询接口是否成功
添加响应断言:
这里同时也测试了修改接口是没问题的。
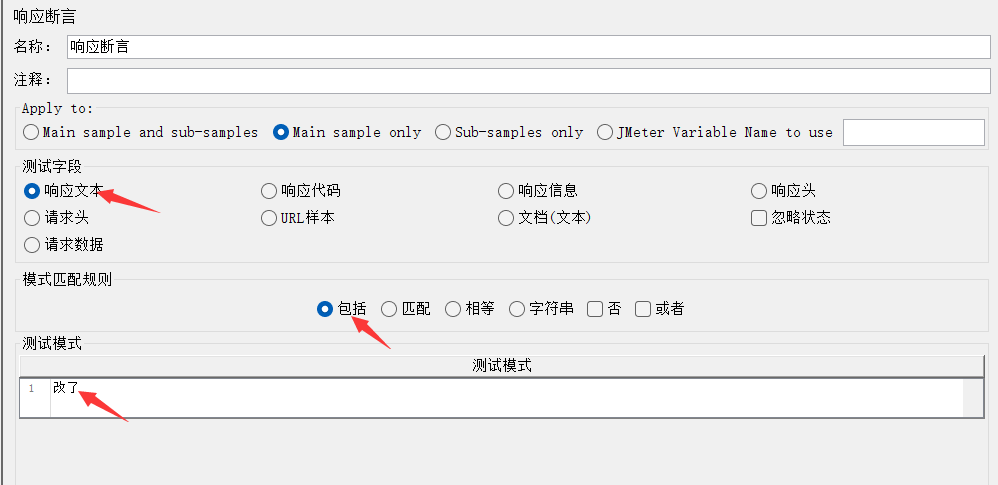
5、测试删除接口是否成功
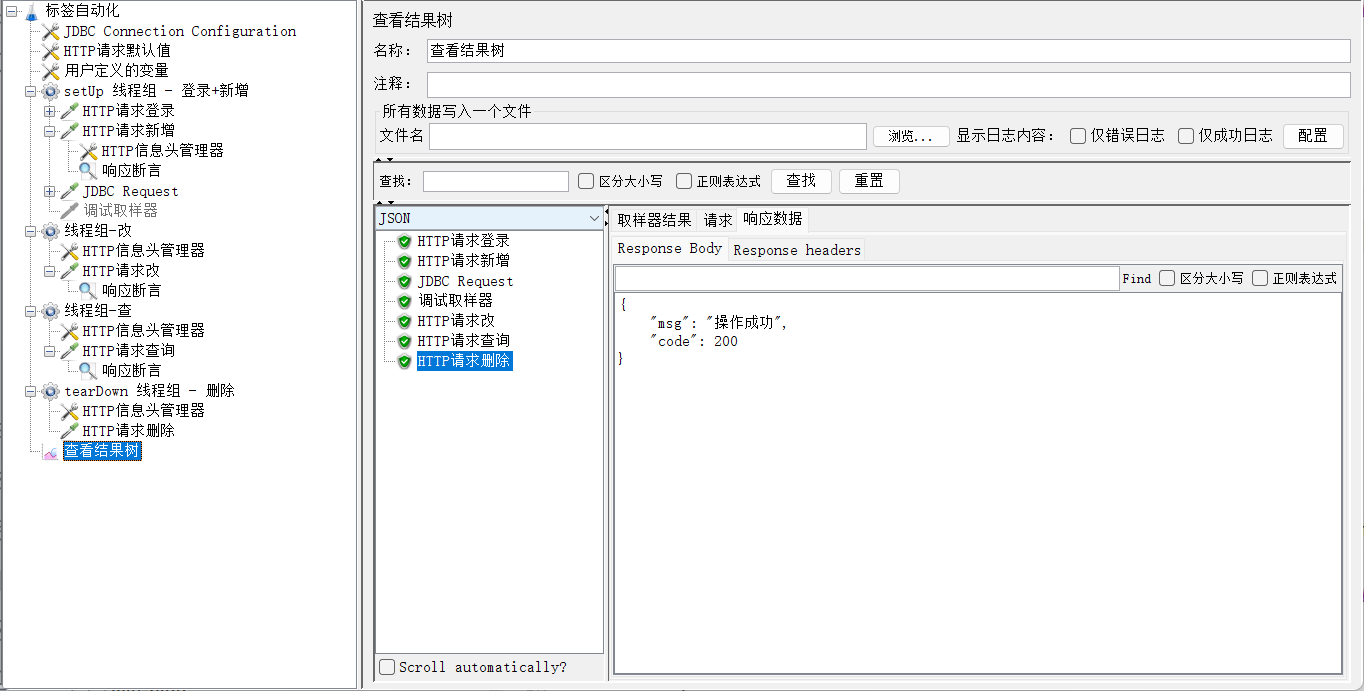
将全部线程组启用,一键运行自动化测试脚本,查看结果树,全绿!!!
三、对博客网站进行性能测试
如果网站的用户并发量很大,产品需求要求进行性能测试,则对程序进行性能测试。个人博客其实用户量没多大,这里进行的性能测试目的是熟悉jmeter的压测步骤。
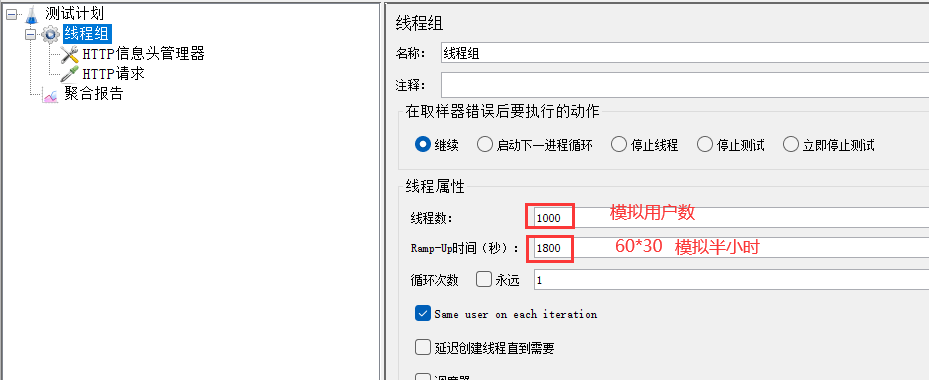
场景1:模拟半小时之内1000个用户访问服务器资源,要求平均响应时间在3000ms内,且错误率为0
半小时以内1000个用户访问,是弱压力测试,不是同一时刻进行访问
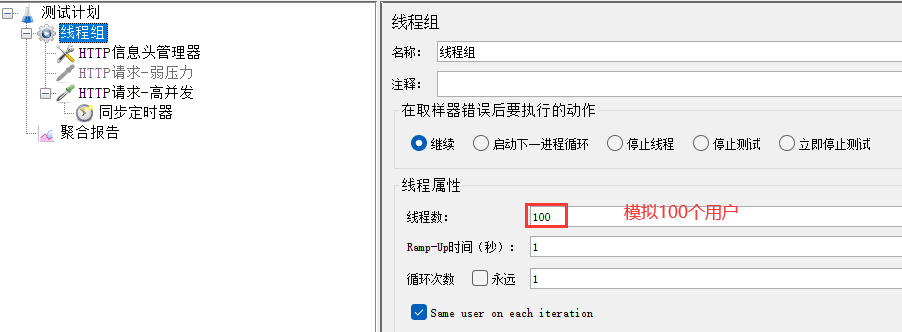
场景2:模拟100个用户同时访问服务器资源,要求平均响应时间在3000ms内,且错误率为0
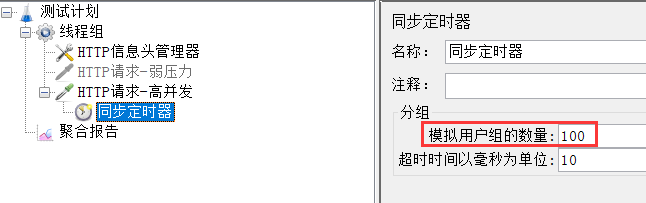
添加同步定时器,100个用户为一组
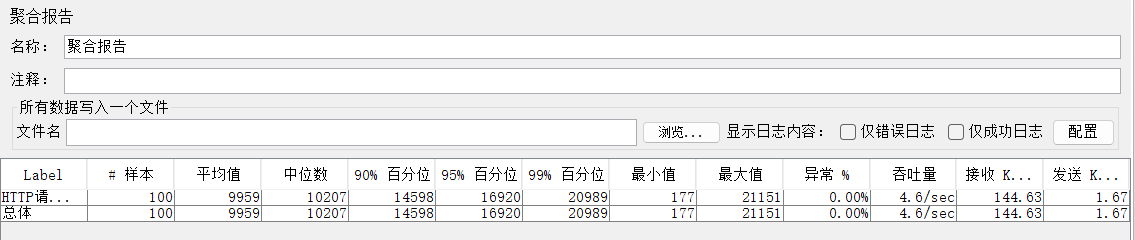
运行,查看聚合报告
场景3:模拟2个用户以20QPS的频率访问服务器资源持续10秒,要求平均响应时间在3000ms内,错误率为0

20QPS:每秒访问20次
添加常数吞吐量定时器

运行,查看聚合报告
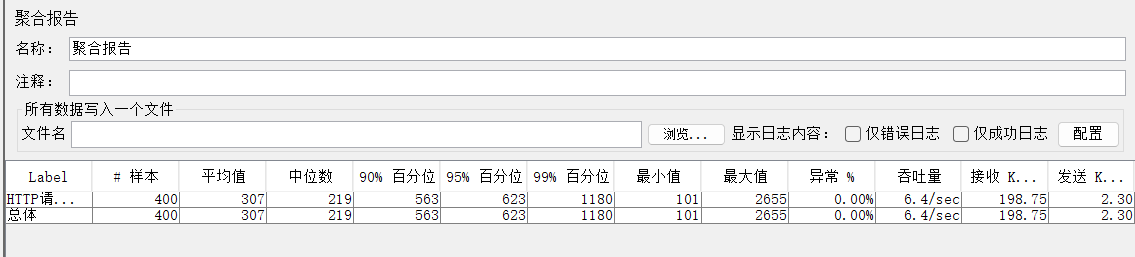
四、生成可视化测试报告
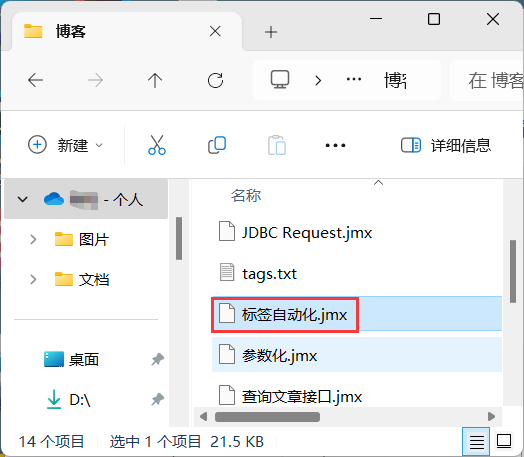
1、将jmx文件复制到jmeter安装目录的bin目录下
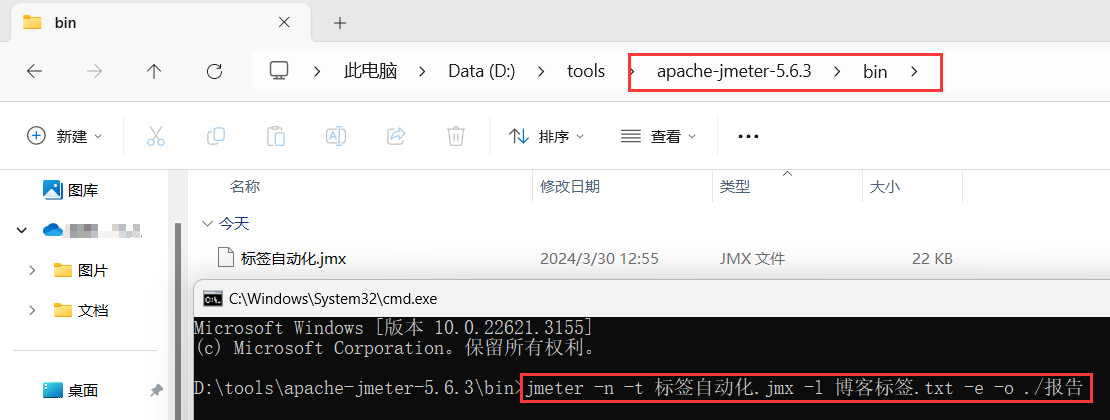
2、执行命令
jmeter -n -t 名.jmx -l 名.txt -e -o ./目录名
-n 无图形化运行
-t 被运行的脚本
-l 将运行信息写入日志文件
-e 生成测试报告
-o 指定报告输出目录














 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









