






目录
4.Header——消息头交换机(应用场景比较少,规则复杂)
认识消息队列
消息队列称为(Message Queue ,MQ. 在多线程常常会谈到一个阻塞队列(Blocking Queue)->生产者消费者模型
所谓的消息队列,就是把阻塞队列这样的数据结构,单独提取出了一个程序,独立进行部署->生产者消费者模型(进程和进程之间/服务和服务之间)
分布式系统-整个服务器程序,不是一个单一的程序了,而是一组服务器构成的集群。
生产者消费者模型的作用
1.解耦合(写代码的追求 高内聚,低耦合)
本来分布式系统,a服务器调用b服务器(A给B发送请求,B给A返回响应)->A和B耦合比较大,如何解耦合呢? 引入消息队列后,A把请求发给消息队列,B再从消息队列中获取到请求。
2.削峰填谷
A是入口服务器,A再去调用B完成一些具体的业务,如果A和B直接通信,如果A突然收到一组用户请求的峰值,此时B也会感受到峰值->(物理上的服务器,硬件资源都是有上限的(包括但是不限于,CPU,内存,硬盘,网络带宽)
引入消息队列之后,A把请求发送给消息队列,B从队列中获取请求,虽然A收到的请求很多,队列收到的请求也不少,但是B可以按照原有节奏来取需求,不至于一下子收到很多的量。
市面一些知名MQ:
RabbitMQ
Kafka
RocketMQ:阿里的名气小
ActiveMQ:用的更少
MQ的使用暂时不去讨论
我们去关注MQ怎么模拟实现出来
以RabbitMQ为蓝图去了解。
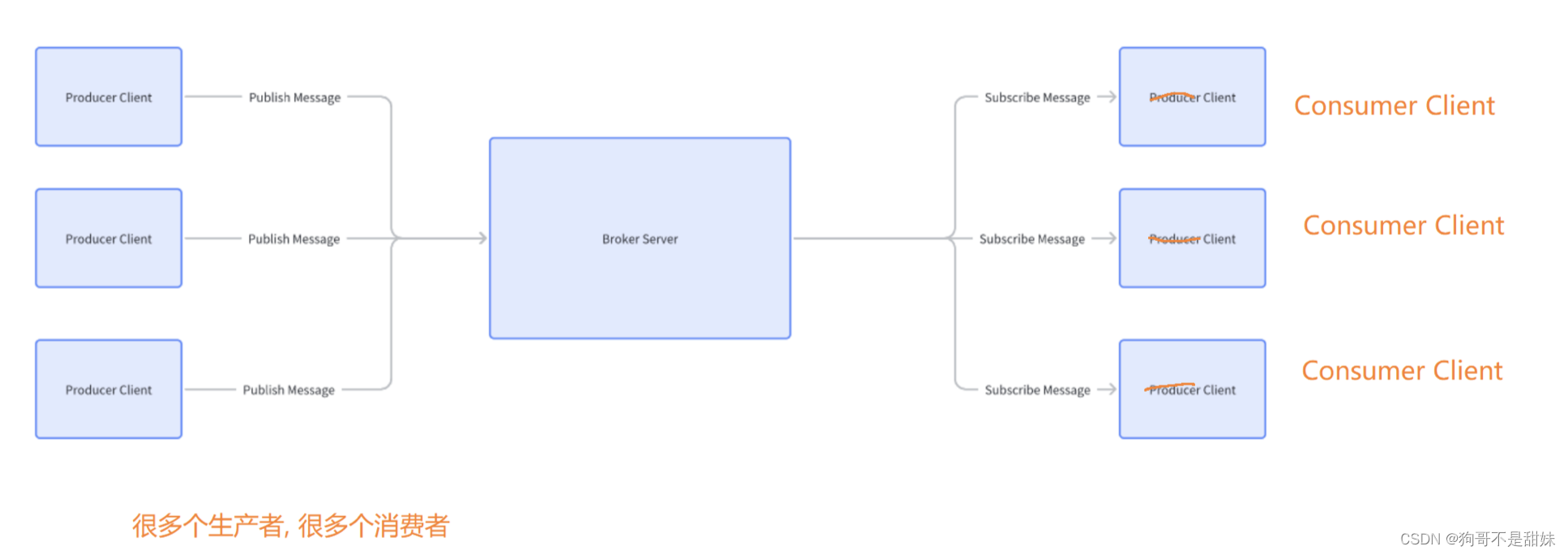
需求分析
1.生产者(Producer)
2.消费者(Comsumer)
3.中间人(Broker)
4.发布(Publish) 生产者向中间人这里投递信息的过程
5.订阅(Subscribe) 哪些消费者要从这个中间人这里取数据,这个注册的过程,称为订阅
(火影忍者充月卡)
6.消费:消费者从中间人这里取数据的动作(领月卡)
服务器很多种含义:
1.7*24小时持续工作的电脑,配置比普通电脑高很多,永远是在机房里面,通过网络进行操作。
2.物理服务器上跑的服务器程序(一个/一种具体的程序)
3.更广义,更抽象的概念(客户端-服务器),主动发起请求的是客户端被动接受的是服务器
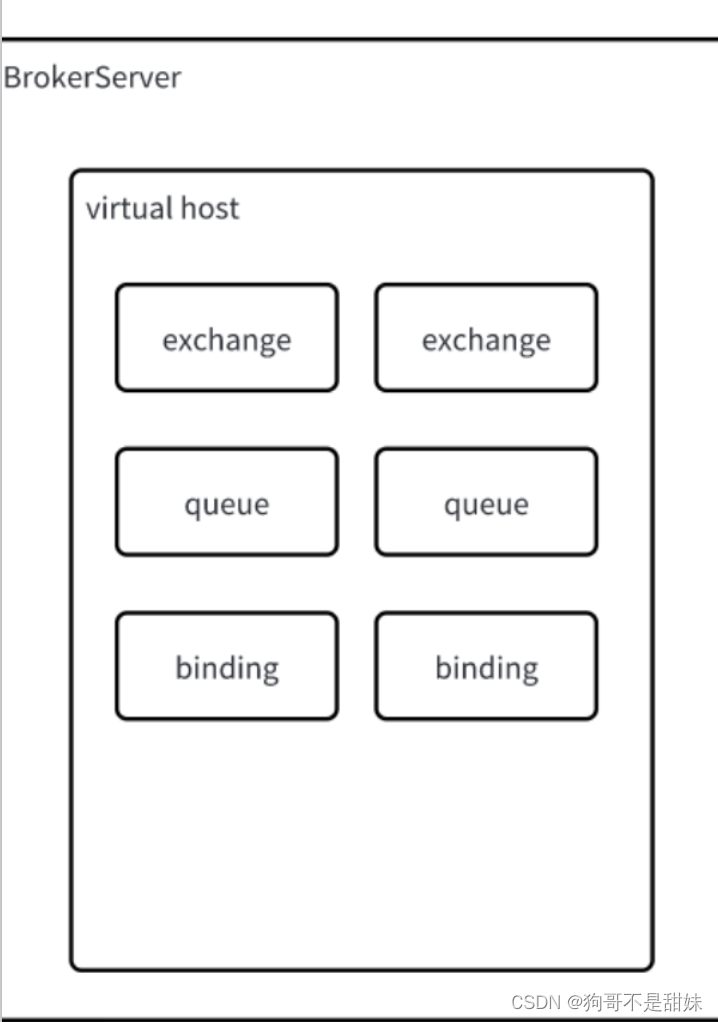
BrokerServer内部也涉及到一些关键概念
1.虚拟主机(Virtual Host)类似于Mysql中database,算是一个逻辑上的数据集合
一个Broker Server也可以组织多种不同类别的数据,可以使用Virtual Host做出逻辑上的区分
实际开发中,一个Broker Server可能会同时用来管理多组业务线上的数据,就可以使用VirtualHost做出区分
2.交换机(Exchange)
生产者把消息投递给Broker Server实际上,是先把消息交给了Broker Server上的某个交换机,再由交换机把消息转发对应的队列
交换机,类似于饭店的服务员(转发姐)
3.队列(Queue)
真正用来存储处理消息的实体,后续消费者也是从对应的队列中取数据,一个大的消息队列中,可以存在很多小的队列
4.绑定(Binding)
把交换机和队列之间,建立起关联关系~~
可以把交换机和队列视为类似数据库中多对多的关系。一个交换机,可以对应多个队列,一个队列,也可以被多个交换机对应,在数据库的时候,多对多,会有一个中间表
5.消息
具体来说,可以认为是服务器A给B发的请求(通过MQ转发),就是一个消息,服务器B给A返回的响应也是一个消息,一个消息可以视为一个字符串,消息中具体包含啥样的数据都是程序员自定义的。
消息队列要提供的核心API
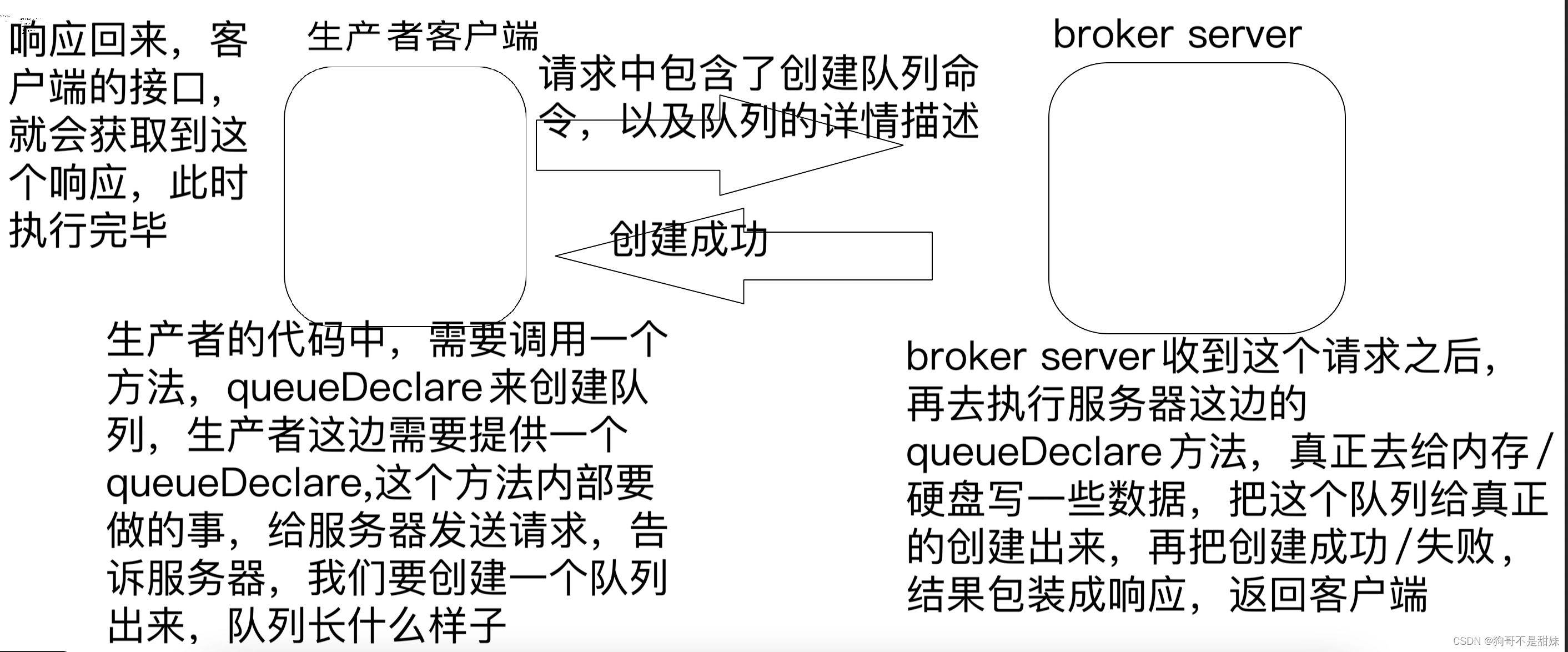
1.创建队列(queueDeclare)此处不使用Create这样的术语,而是使用Declare,Create就只是单纯的创建,Declare起到的效果是:不存在则创建,存在则不做事情
2.销毁队列(queueDelete)
3.创建交换机(exchangeDelete)
4.销毁交换机(exchangeDelete)
5.创建绑定(queueBind)
6.解除绑定(queueUnbind)
7.发布消息(basicPublish)
8.订阅消息(basicConsume)
消费消息不搞
(因为:MQ和消费者之间,工作模式有两种
1.Push(推)Broker把收到的数据,主动的发送给订阅的消费者 RabbitMQ只支持推的方式
2.Pull(拉)消费者主动调用Broker的api取数据 Kafka -支持拉
9.确认消息(basicAck) - TCP(通过确认应答)
这个api起到的效果,是可以让消费者显示的告诉broker server,这个消息我已经处理完毕了~,提高整个系统的可靠性~,保证消息处理没有遗漏。
就相当于是已读未回,已读已回这种
交换机类型:
交换机在转发消息的时候,有一套转发的规则的!,提供了几种不同的交换机类型来描述这里不同的转发规则~
RabbitMQ主要实现了四种交换机类型(也是根据AMQF协议定义的,用来描述交换机张什么样子)
1.Direct——直接交换机
生产者发送消息,会指定一个"目标队列"的名字
交换机收到之后,就看看绑定的队列里,有没有匹配的队列~如果有,转发过去(把消息塞进对应的队列中)如果没有,就直接丢弃
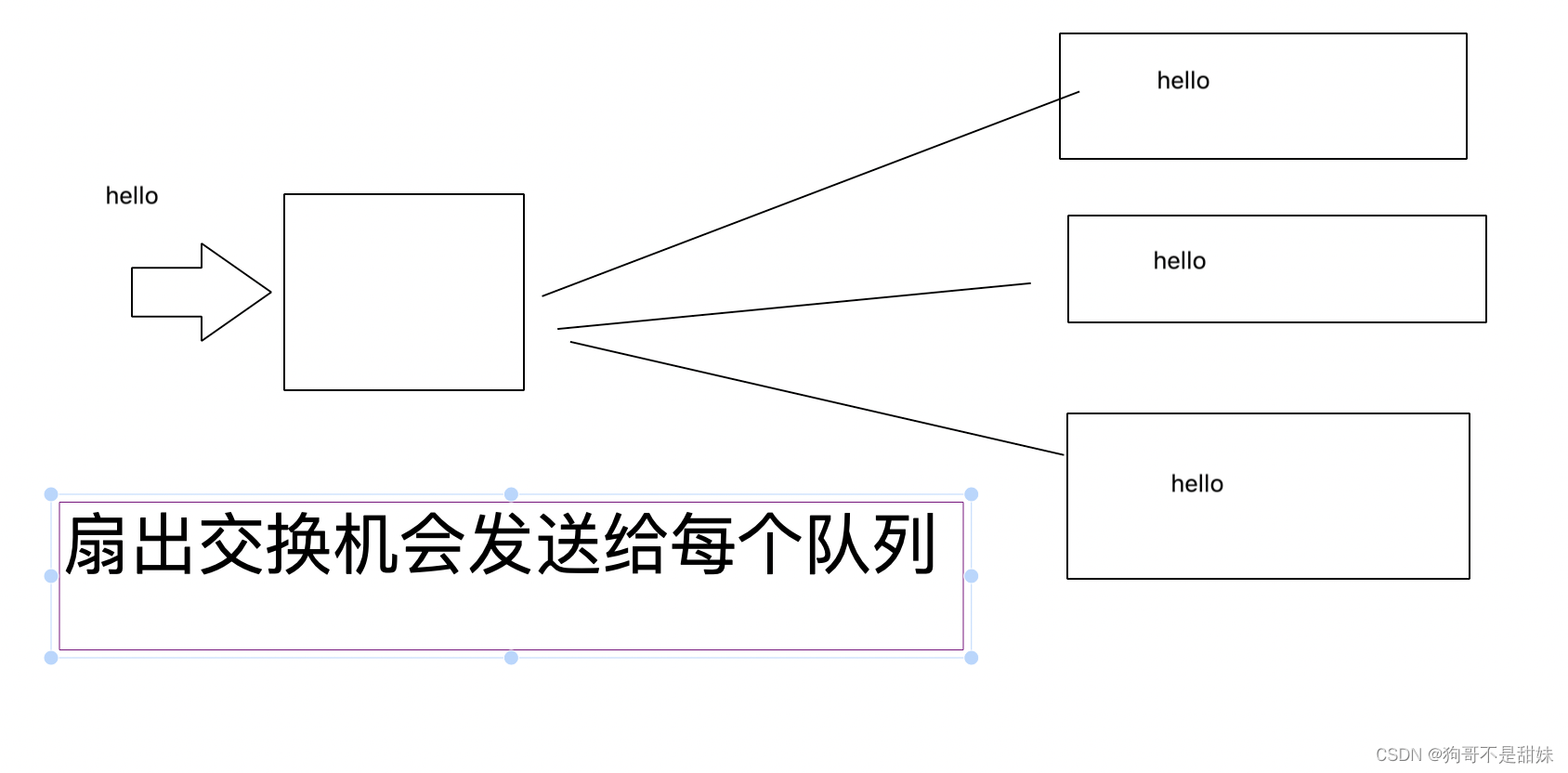
2.Fanout——扇出交换机
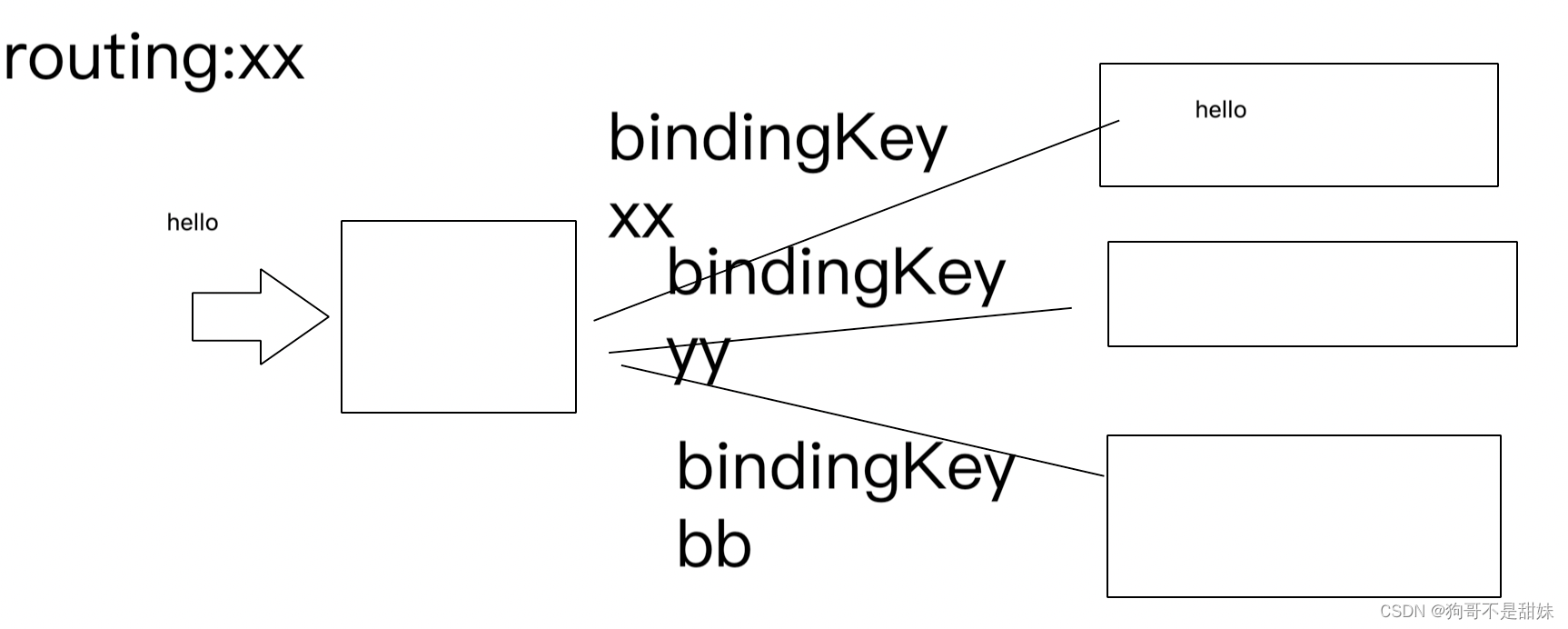
3.Topic——主题交换机
有两个关键概念
(1)bindingKey.把队列和交换机绑定的时候,指定一个单词(如同一个暗号)
(2)routingKey.生产者发送消息的时候,也指定一个单词
如果当前routingKey和bindingKey能对上,此时就可以把这个消息转发到对应的队列中
4.Header——消息头交换机(应用场景比较少,规则复杂)
持久化:
虚拟主机,交换机,队列,绑定,消息,都需要让BrokerServer组织管理
对于上述这些概念对应的数据,需要存储和管理起来,此时内存和硬盘上都会各自存储一份,以内存为主,硬盘为辅
在内存中存储的原因:
对于MQ来说,能够高效的转发处理数据,是非常关键的指标!因此使用内存来组织上述数据,得到的效率,比放硬盘要高的多
(但是一旦断电之后,内存的内容就会丢失,所以在硬盘上存储的原因,为了防止内存中的数据随着进程重启/主机重启而丢失,硬盘的寿命几年-几十年(也要通通电)
网络通信
其他的服务器(生产者/消费者)通过网络,和咱们的Broker Server进行交互的~
此处设定使用,TCP+自定义的应用层协议(这里的主要工作,就是让客户端可以通过网络,调用broker server提供的编程接口,所以客户端,也需要提供上述方法,只不过服务器版本的上述办法,效果是真正干实事,把管理数据进行调整,而客户端这边,只是进行请求的发送和接受),实现生产者/消费者和BrokerServer之间的交互工作
此处,客户端调用了一个本地的方法,结果这个方法在背后,给服务器发了一系列消息,有福气完成了一系列工作,站在调用者的角度,看到的只是说,当前这个功能已经完成,并不知道这背后的细节,虽然调用的事一个本地方法,实际上像是调用了一个远端服务器的方法一样->(远程过程调用RPC)
客户端除了上面9个和服务器这边对应的方法之外,还需提供一下四种方法
1.创建Connection
一个Connection对象,就代表一个TCP连接
2.关闭Connection
3.创建Channel
通道/信道,一个Connection里面可以包含多个Channel,每个Channel上面传递的数据都是互不相干的。
TCP,建立/断开一个连接,成本还是很高的,因此很多时候,我们不希望频繁的建立断开TCP连接~此处的Channel只是一个逻辑概念,比TCP连接的建立和断开,轻量很多
Connection就像是一个打针的那个管,Channel就像是瓶子,我们只需要换瓶子即可
4.关闭Channel
















 2264
2264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











