







 本文介绍了LRU算法在LinuxPageCache和MySQLBufferPool中的应用,探讨了预读失效和缓存污染的问题,并提出Linux和MySQL通过活跃/非活跃链表和访问次数阈值优化LRU策略,以提高缓存效率和性能。
本文介绍了LRU算法在LinuxPageCache和MySQLBufferPool中的应用,探讨了预读失效和缓存污染的问题,并提出Linux和MySQL通过活跃/非活跃链表和访问次数阈值优化LRU策略,以提高缓存效率和性能。
LRU算法
Linux 的 Page Cache 和 MySQL 的 Buffer Pool 的大小是有限的,并不能无限的缓存数据,对于一些频繁访问的数据我们希望可以一直留在内存中,而一些很少访问的数据希望可以在某些时机可以淘汰掉,从而保证内存不会因为满了而导致无法再缓存新的数据,同时还能保证常用数据留在内存中。要实现这个,最容易想到的就是 LRU(Least recently used)算法。
LRU 算法一般是用「链表」作为数据结构来实现的,链表头部的数据是最近使用的,而链表末尾的数据是最久没被使用的。那么,当空间不够了,就淘汰最久没被使用的节点,也就是链表末尾的数据,从而腾出内存空间。
传统的 LRU 算法的实现思路是这样的:
- 当访问的页在内存里,就直接把该页对应的 LRU 链表节点移动到链表的头部。
- 当访问的页不在内存里,除了要把该页放入到 LRU 链表的头部,还要淘汰 LRU 链表末尾的页。
代码实现LRU算法
// 哈希表 + 自定义双向链表
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 拼凑双向链表结构
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
// 往头部插入最新的元素
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 删除指定节点——主要利用的是双向链表特性精确定位前后元素
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
// 将目标元素移动到链表头部实现最新插入的需求(先删后头部添加)
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
// 容量不够的时候移除队尾元素
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}LRU 算法的缺陷及其优化方案
传统的 LRU 算法无法避免下面这两个问题:
-
预读失效导致缓存命中率下降;
-
缓存污染导致缓存命中率下降;
预读机制
inux 操作系统为基于 Page Cache 的读缓存机制提供预读机制,一个例子是:
-
应用程序只想读取磁盘上文件 A 的 offset 为 0-3KB 范围内的数据,由于磁盘的基本读写单位为 block(4KB),于是操作系统至少会读 0-4KB 的内容,这恰好可以在一个 page 中装下。
-
但是操作系统出于空间局部性原理(靠近当前被访问数据的数据,在未来很大概率会被访问到),会选择将磁盘块 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加载到内存,于是额外在内存中申请了 3 个 page;
下图代表了操作系统的预读机制:
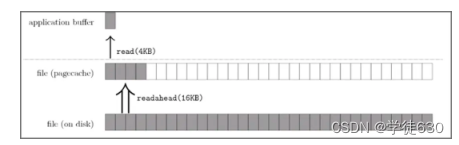
上图中,应用程序利用 read 系统调动读取 4KB 数据,实际上内核使用预读机制(ReadaHead) 机制完成了 16KB 数据的读取,也就是通过一次磁盘顺序读将多个 Page 数据装入 Page Cache。
因此,预读机制带来的好处就是减少了 磁盘 I/O 次数,提高系统磁盘 I/O 吞吐量。
MySQL Innodb 存储引擎的 Buffer Pool 也有类似的预读机制,MySQL 从磁盘加载页时,会提前把它相邻的页一并加载进来,目的是为了减少磁盘 IO。
预读失效会带来什么问题?
如果这些被提前加载进来的页,并没有被访问,相当于这个预读工作是白做了,这个就是预读失效。
如果使用传统的 LRU 算法,就会把「预读页」放到 LRU 链表头部,而当内存空间不够的时候,还需要把末尾的页淘汰掉。不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率 。
避免预读失效造成的影响
Linux 操作系统和 MySQL Innodb 通过改进传统 LRU 链表来避免预读失效带来的影响,具体的改进分别如下:
Linux方案
-
Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表和非活跃 LRU 链表;
-
有了这两个 LRU 链表后,预读页就只需要加入到 inactive list 区域的头部,当页被真正访问的时候,才将页插入 active list 的头部。如果预读的页一直没有被访问,就会从 inactive list 移除,这样不会影响 active list 中的热点数据。active list 淘汰的数据就会被降级到 inactive list ,作为 inactive list 头部
-
MySQL方案
-
MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。
-
young 区域在 LRU 链表的前半部分,old 区域则是在后半部分,这两个区域都有各自的头和尾节点 ,63:37(默认比例),预读的页就只需要加入到 old 区域的头部,当页被真正访问的时候,才将页插入 young 区域的头部
-
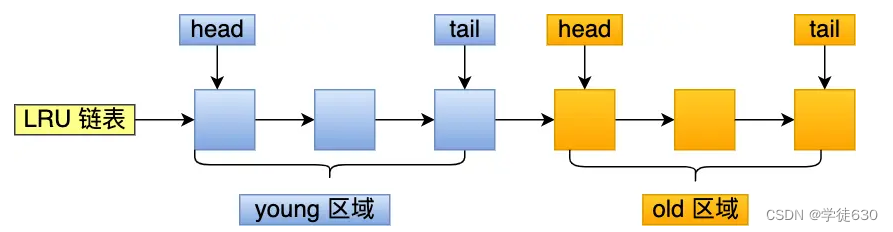
这两个改进方式,设计思想都是类似的,都是将数据分为了冷数据和热数据,然后分别进行 LRU 算法。不再像传统的 LRU 算法那样,所有数据都只用一个 LRU 算法管理。
缓存污染
当我们在批量读取数据的时候,由于数据被访问了一次,这些大量数据都会被加入到「活跃 LRU 链表」里,然后之前缓存在活跃 LRU 链表(或者 young 区域)里的热点数据全部都被淘汰了,如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了。
以 MySQL 举例子
某一个 SQL 语句扫描了大量的数据时,在 Buffer Pool 空间比较有限的情况下,可能会将 Buffer Pool 里的所有页都替换出去,导致大量热数据被淘汰了,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 I/O,MySQL 性能就会急剧下降。
怎么避免缓存污染造成的影响
前面的 LRU 算法只要数据被访问一次,就将数据加入活跃 LRU 链表(或者 young 区域),这种 LRU 算法进入活跃 LRU 链表的门槛太低了!正式因为门槛太低,才导致在发生缓存污染的时候,很容易就将原本在活跃 LRU 链表里的热点数据淘汰了。所以,只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉。
Linux 操作系统和 MySQL Innodb 存储引擎分别是这样提高门槛的:
-
Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
-
MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
-
如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),那么该页就不会被从 old 区域升级到 young 区域;
-
如果第二次的访问时间与第一次访问的时间超过 1 秒,那么该页就会从 old 区域升级到 young 区域;
-
提高了进入活跃 LRU 链表(或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。
在批量读取数据时候,如果这些大量数据只会被访问一次,并且不是多次连续访问,那么它们就不会进入到活跃 LRU 链表(或者 young 区域),也就不会把热点数据淘汰,只会待在非活跃 LRU 链表(或者 old 区域)中,后续很快也会被淘汰。
















 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











