






什么是es?
搜索引擎,它的功能也类似一个数据库,能高效的从大量数据中搜索匹配指定关键字的内容,它也将数据保存在硬盘中,它本质就是一个java项目,使用它进行数据的增删改查就是访问这个项目的控制器方法(url路径),底层技术是Lucene,对其进行了封装,实现了开箱即用。
使用es的原因:
数据库的模糊查询效率低(所有关系型数据库都有这个缺点),es使用了索引,将模糊查询效率提高了100倍左右,但是索引也会占用一部分空间,所以还是等同于用空间换时间,也遵从最左匹配原则,所以前模糊也用不了索引。
es运行的原理:
es有一个分词器,然后通过分词就可以生成对应的索引(词和索引就像键值对)。
es的启动:
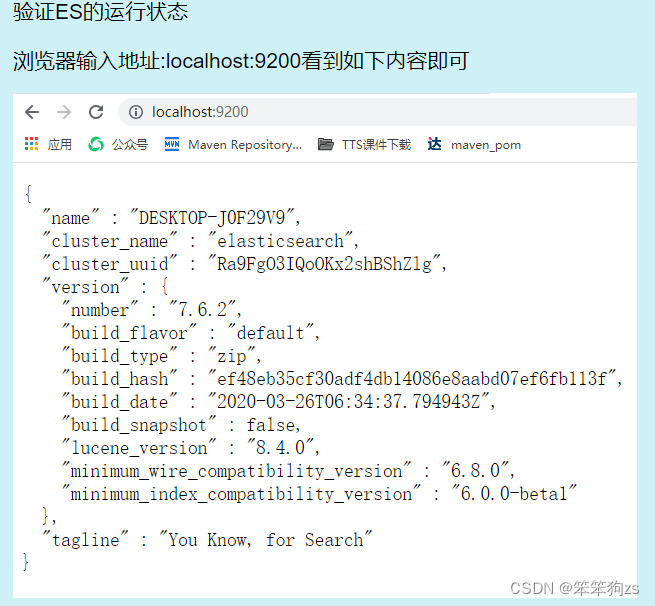
linux系统的启动:
tar -xvf elasticsearch-7.6.2-linux-x86_64.tar.gz
cd elasticsearch-7.6.2/bin
./elasticsearch
然后就是es的使用:
首先还是添加依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Spring Data Elasticsearch 整合SpringBoot的依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
</dependencies>然后在项目中创建一个http文件
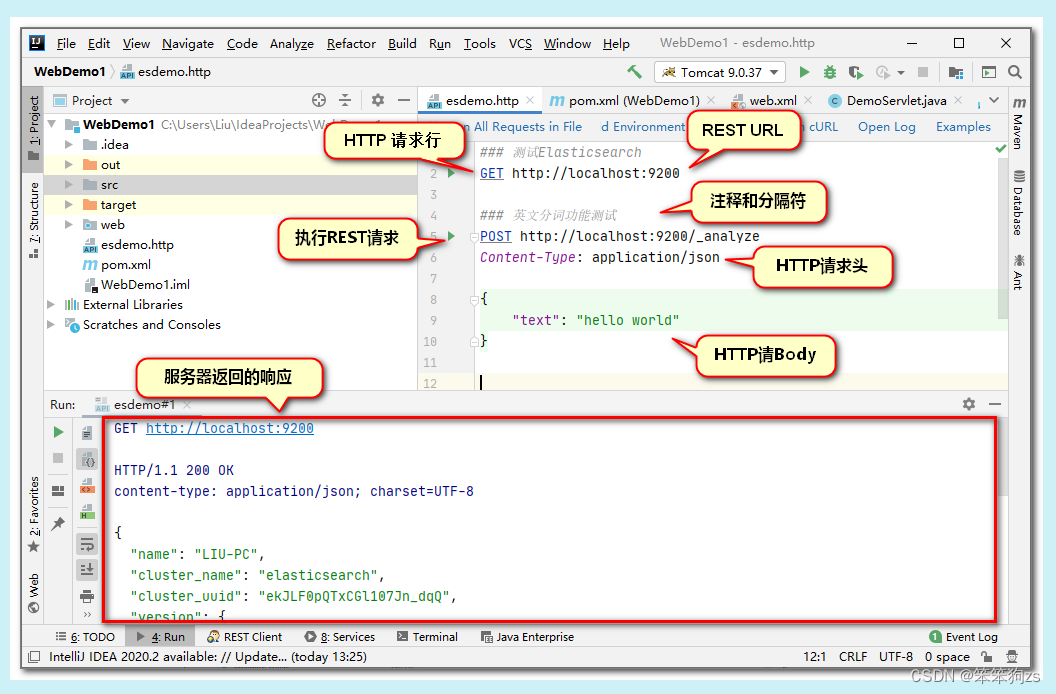
文件中这样写:
### 三个#是注释,也是分隔符,http文件要求每个请求必须以分隔符开始,否则会报错
GET http://localhost:9200
### 测试ES的分词功能,运行请求,查看分词结果
POST http://localhost:9200/_analyze
Content-Type: application/json
{
"text": "my name is hanmeimei",
"analyzer": "standard"
}
但是实际上其因为词库问题,中文分词可能有出入,所以可以添加一个分词插件 ik
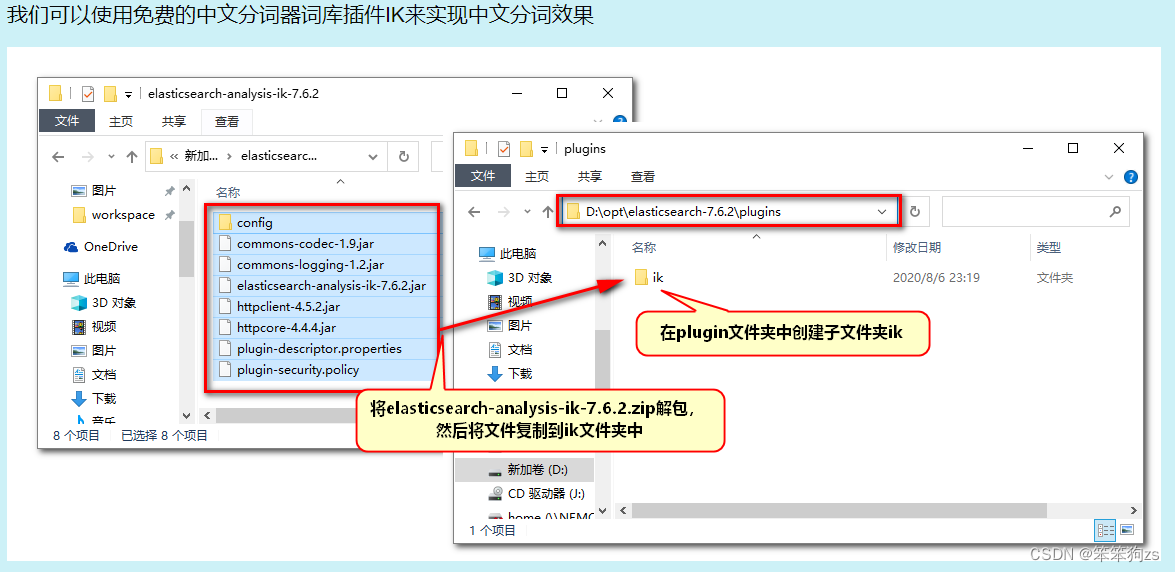
安装完成后重启es然后就可以在刚刚的http文件中
{
"text": "罗技激光鼠标",
"analyzer": "ik_smart"
}来测试分词效果,这个analyzer就是选用的分词器。我们可以修改
POST http://localhost:9200/_analyze
Content-Type: application/json
{
"text": "北京冬季奥林匹克运动会顺利闭幕",
"analyzer": "ik_max_word"
}
ik_smart
-
优点:特征是粗略快速的将文字进行分词,占用空间小,查询速度快
-
缺点:分词的颗粒度大,可能跳过一些重要分词,导致查询结果不全面,查全率低
ik_max_word
- 优点:特征是详细的文字片段进行分词,查询时查全率高,不容易遗漏数据
- 缺点:因为分词太过详细,导致有一些无用分词,占用空间较大,查询速度慢
在springboot中使用es:
首先还是添加依赖,上面的依赖可复用。
然后修改配置文件,
# 配置ES的ip和端口
spring.elasticsearch.rest.uris=http://localhost:9200
# 设置日志门槛
logging.level.cn.tedu.search=debug
# SpringDataElasticsearch框架中日志输出专用类也要设置debug
logging.level.org.elasticsearch.client.RestClient=debug然后创建es需要使用的实体类
@Data
@Accessors(chain = true) // 支持链式set赋值
@AllArgsConstructor // 自动生成包含全部参数的构造方法
@NoArgsConstructor // 自动生成无参数的构造方法
// @Document注解标记当前类是ES框架对应的实体类
// 属性indexName指定ES中对应的索引名称,运行时,如果这个索引不存在,SpringData会自动创建它
@Document(indexName = "items")
public class Item implements Serializable {
// SpringData通过@Id标记当前实体类的主键属性
@Id
private Long id;
// @Field是SpringData标记普通属性的注解
// type是定义这个属性的类型,FieldType.Text是支持分词的字符串,后面要定义两个分词器
@Field(type = FieldType.Text,
analyzer = "ik_max_word",
searchAnalyzer = "ik_max_word")
private String title;
// Keyword是不需分词的字符串类型
@Field(type = FieldType.Keyword)
private String category;
@Field(type = FieldType.Keyword)
private String brand;
@Field(type = FieldType.Double)
private Double price;
// imgPath是图片路径,路径不会成为搜索条件,所以这个列可以不创建索引,节省空间
// index = false,就是不创建索引的设置
// 但是需要注意,不创建索引并不是不保存这个数据,ES中仍然保存imgPath的值
@Field(type = FieldType.Keyword,index = false)
private String imgPath;
// images/2022/11/28/18239adc-8ae913-abbf91.jpg
}然后创建mapper层:这个es自己就有,我们直接继承使用就可以了,在需要自定义查询的时候通过方法名就可以让其自己生成对应的查询了。非常的萤杏花!
// Repository是Spring家族对持久层包名\类名\接口名的规范
@Repository
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
// ItemRepository接口要继承SpringData框架提供的父接口ElasticsearchRepository
// 一旦继承,当前接口就可以编写使用父接口中提供的连接ES的方法了
// 继承父接口后,SpringData会根据我们在泛型中指定的Item实体类,找到对应的索引
// 并生成操作这个索引的基本增删改查方法,我们自己无需编写
// ElasticsearchRepository<[要操作的实体类名称],[实体类主键的类型]>
}我们可以通过方法名中加orderby完成排序查询:
// 排序查询
Iterable<Item> queryItemsByTitleMatchesOrBrandMatchesOrderByPriceDesc(
String title,String brand);然后又有一个问题就是数据量大的话,我们就需要通过分页查询来提高效率,直接在这个接口中就可以写
// 分页查询
// 返回值类型需要修改为Page类型,这个类型既可以保存从ES中查询出的数据
// 又可以保存当前分页查询的分页信息例如:当前页码,每页条数,总条数,总页数,有没有上一页,有没有下一页等
// 参数方面,需要在参数列表末尾添加一个Pageable类型的参数
// 这个类型的对象包含要查询的页码和每页的条数
Page<Item> queryItemsByTitleMatchesOrBrandMatchesOrderByPriceDesc(
String title, String brand, Pageable pageable);以上均为本人自己的理解,所以可能出现一些问题和不规范的地方,(主要还是为了方便cv),有什么问题欢迎各位大佬进行修改补充!















 3674
3674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









