






目录
2.queryCoupleSum()&&queryBestAcquaintance()
一、测试过程分析
1.黑箱测试
黑箱测试,顾名思义,待测试代码如同黑箱一样对测试人员不可见,或者说测试人员对测试代码并不考虑的情况下,对软件功能的测试。
由于黑箱的特效,我认为黑箱测试在着重于对功能的测试之下,应该强调在特定输入下的输出准确性。因此,黑箱测试为了满足测试的全面性,往往会考虑用海量数据+特定边界数据对程序进行测试。
但是由于对待测试代码的了解不够全面,可能会导致无法覆盖所有的代码路径,而导致测试效果降低。同时,尽管找到了错误,也难以定位错误发生的地方。
2.白箱测试
白箱测试,与黑箱测试完全相反,测试人员需要了解并使用软件的内部代码结构和实现来设计和执行测试。
白箱测试的核心是测试人员可以访问并理解程序的源代码。他们使用代码的结构、逻辑和实现细节来设计测试用例。这种方法允许测试人员进行非常详细和精确的测试,包括代码的每一行、每一个分支和每一个条件。
因此,白箱测试相对于黑箱测试来说,对待测试代码的覆盖率更高,能保证源代码的各个部分各个功能都能被测试到。但是,显然,这样的测试方式对于测试人员来说会极大增加测试的工作量,同时如果源代码迭代之后需要对新增功能再次进行编写测试代码。
3.单元测试
在我的理解的里,单元测试就是测试代码中的最小单位,比如一个函数或一个类。 测试的目的就是确保这个最小单位的逻辑是正确的。比如我们作业里的queryCoupleSum,对单个方法的测试就是单元测试。
4.功能测试
功能测试就是测试整个软件的功能是否按照预期工作。测试的目的是为了确保软件在用户使用时能正确执行各种功能。个人理解,功能测试就是对待测试程序向外提供的各种功能进行测试,也就是更加着重功能实现的准确性。
5.集成测试
集成测试就是测试多个模块或组件一起工作时是否正常。 集成测试可以确保不同部分的代码在一起运行时没有问题。因为毕竟很多功能需要多个模块的合作,只是测试单个模块的准确性难以满足测试的需要。
6.压力测试
压力测试,顾名思义就是给待测试代码高强度的压力,也就是测试软件在高负荷或极端条件下的表现。 测试是为了确保软件在繁忙或极端情况下仍能正常运行,同时也可以体现代码对时间复杂度的处理是否恰当。
7.回归测试
回归测试的意思是:在修改代码后,重新测试软件确保没有引入新的错误。 显然对于迭代的代码来说,回归测试是非常必要的,因为这样可以确保修复一个问题或添加一个新功能不会破坏已有功能,避免bug的累计导致难以修复。
二、单元架构设计
实际上,本次作业的迭代非常明显,且每次迭代前后的修改已有代码量非常少,因此本次直接对最后一次作业的代码的架构设计进行分析,这样实际上包含了三次作业的结构展示。
类图: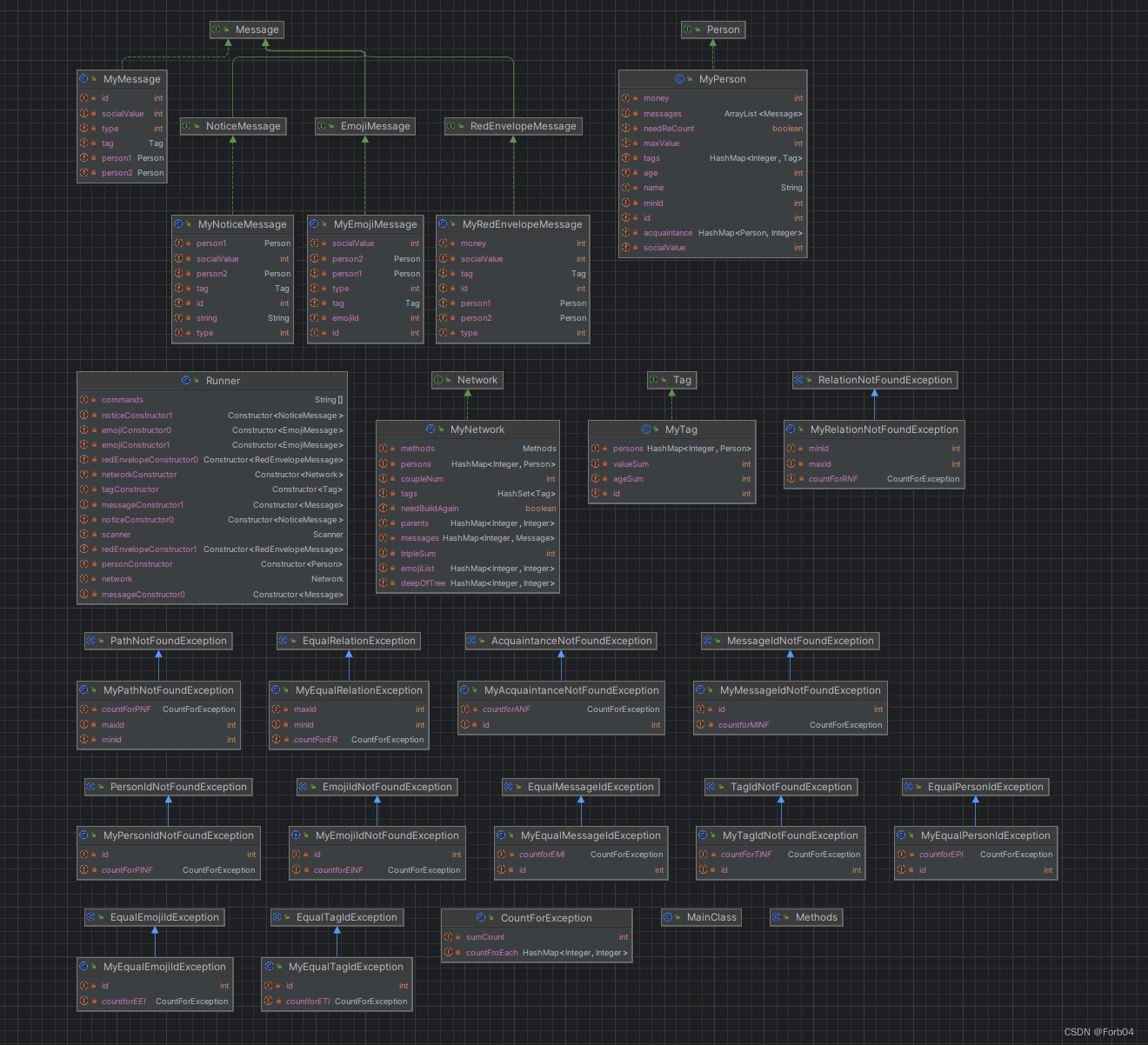
由上图不难看出,第三单元的做作业实现基本都是根据已经给出的接口~进行实现My~类。
其中一共有Network、Person、Tag以及Message类。Network类处于第一层次,我们需要实例化一个Network,紧接着可以在Network里添加Person以及Message。其中Person中又含有tags,也就是标签,标签是对一群人的定义,因此Tag里也维护了一个Persons数组。而Message是独立存在,Message本身就包括了各种信息,比如接收人、发送人以及消息类型等等。
我的图模型构建十分简单,首先Person这个图我用了Hashmap进行存储,也就是存储了人物关系图的结点。同时,Person和Person直接用 A.isLinked(B) 判断两者是否有边,在已知两者有关系的前提下,使用queryValue获取两者之间的边的权重。
当然本次作业的图并不是这么简单,实际上每个人内部维护的tags,也是一个又一个整个Network里的大图的子图,而queryCoupleSum又对查询每个Tag里的边的权重和又有着极高的时间复杂度要求,因此,我直接在Network里建立了一个所有tags的集合,以List的方式存储起来,这样在更改时能够及时通知到Tag里,方便动态维护。
对于维护策略,实际上我的很多维护都是在为了减小时间复杂度的目的下进行的。这部分就放在之后的部分详细讲解。
三、性能问题及其维护
在谈及性能问题时,首当其冲的应当是存储数据的方式。根据本次作业的亲身实践,可以得出结论:在存储时不考虑先后顺序的,且需要查询的,应当使用例如:Hashmap<id, person>的形式进行,不需要查询,或者说不能确保具有一一对应关系而无法查询的,应对使用Hashset存储。如果存储时需要了解顺序,应当使用List这样的存储容器进行存储。
1.getTripleSum()&&isCircle()
实际上我的优化方式是,动态维护了一个TripleSum,并使用并查集的方式建立树,方便及时查询。同时,因为由于关系破裂而需要重建查找树的情况下,我也维护了一个needBuildAgain,为了在需要重建的情况下重建,毕竟重建需要的操作复杂度也不小。以下是实现的相关代码:
private int tripleSum = 0;
private HashMap<Integer, Integer> parents = new HashMap<>();
private HashMap<Integer, Integer> deepOfTree = new HashMap<>();
private boolean needBuildAgain = false;
public boolean isCircle(int id1, int id2) throws PersonIdNotFoundException {
if (containsPerson(id1) && containsPerson(id2)) {
if (needBuildAgain) {
methods.reBuild(parents, deepOfTree, persons);
needBuildAgain = false;
}
return methods.getRoot(id1, parents) == methods.getRoot(id2, parents);
public int queryTripleSum() {
return tripleSum;
}同时,给出维护时的代码。
addPerson时:
for (Person person : persons.values()) {
if (person.getId() != id1 && person.getId() != id2) {
if (getPerson(id1).isLinked(person) && getPerson(id2).isLinked(person)) {
tripleSum++;
}
}
}deleteRelation时:
for (Person person : persons.values()) {
int temId = person.getId();
if (temId != id1 && temId != id2) {
if (person1.isLinked(person) && person2.isLinked(person)) {
tripleSum--;
}
}
}2.queryCoupleSum()&&queryBestAcquaintance()
关于这两种方法的实现我也是在Network里动态维护了一个在CoupleSum,同时在Person里维护了一个BestId以及MaxValue,这两个是对应关系,为了保证及时修改。
对于CoupleSum的维护,实际上每次修改时,只会发生一条边上的改变,因此通过编写一个upDateCoupleNum方法,在修改前后保存状态进行维护即可。
以下是具体实现的代码:
private int coupleNum = 0;
public int queryCoupleSum() {
return this.coupleNum;
}
public void addRelation(int id1, int id2, int value)
throws PersonIdNotFoundException, EqualRelationException {
if (containsPerson(id1) && containsPerson(id2) &&
!getPerson(id1).isLinked(getPerson(id2))) {
coupleNum = methods.upDateCoupleNum(id1,id2,false,persons,coupleNum);
((MyPerson) getPerson(id1)).setLink(getPerson(id2),value);
((MyPerson) getPerson(id2)).setLink(getPerson(id1),value);
coupleNum = methods.upDateCoupleNum(id1,id2,true,persons,coupleNum);
public void modifyRelation(int id1, int id2, int value)
coupleNum = methods.upDateCoupleNum(id1,id2,false,persons,coupleNum);
person1.modifyValue(person2,value);
person2.modifyValue(person1,value);
for (Tag tag : tags) {
if (((MyTag) tag).hasTwoPerson(id1, id2)) {
((MyTag) tag).addValueSum(value);
}
}
coupleNum = methods.upDateCoupleNum(id1,id2,true,persons,coupleNum);
} else {
coupleNum = methods.upDateCoupleNum(id1,id2,false,persons,coupleNum);
for (Tag tag : tags) {
if (((MyTag) tag).hasTwoPerson(id1, id2)) {
((MyTag) tag).subValueSum(id1, id2);
}
}
person1.removeLink(person2);
person2.removeLink(person1);
coupleNum = methods.upDateCoupleNum(id1,id2,true,persons,coupleNum);而对于Person内部的BestId维护如下:
private int maxValue;
private int minId;
private boolean needReCount = false;
public void setLink(Person person, int value) {
if (acquaintance.isEmpty()) {
maxValue = value;
minId = person.getId();
} else {
if (maxValue < value || (maxValue == value && minId > person.getId())) {
maxValue = value;
minId = person.getId();
}
}
public void modifyValue(Person person, int value) {
//使用前确保含与person的关系
int setValue = acquaintance.get(person) + value;
acquaintance.put(person,setValue);
if (person.getId() == minId && value < 0) {
needReCount = true;
return;
}
if (setValue > maxValue || (setValue == maxValue && person.getId() < minId)) {
maxValue = setValue;
minId = person.getId();
}
}
public void removeLink(Person person) {
if (person.getId() == minId) {
needReCount = true;
}
public int getBestAcquaintance() {
if (acquaintance.isEmpty()) {
return Integer.MAX_VALUE;
}
if (needReCount) {
RecountBestValue();
needReCount = false;
}
return minId;
}
private void RecountBestValue() {
maxValue = -1;
minId = 0;
for (Person person : acquaintance.keySet()) {
int value = acquaintance.get(person);
if (value > maxValue ||
(value == maxValue && person.getId() < minId)) {
maxValue = value;
minId = person.getId();
}
}
}
3.queryTagValueSum()
关于这个是实现,我是在tag里维护了valueSum,但是由于边是会被改变的,比如A和B关系改变,且A和B同时在C的tag里,并且A和B的改变是不会通知到C的tag里的,因此需要在Network里存储所有的tag,并且在他们改变时及时通知调整valueSum。
通知相关代码如下:
private HashSet<Tag> tags = new HashSet<>();
//添加关系或修改时
for (Tag tag : tags) {
if (((MyTag) tag).hasTwoPerson(id1, id2)) {
((MyTag) tag).addValueSum(value);
}
}
//删除关系时
for (Tag tag : tags) {
if (((MyTag) tag).hasTwoPerson(id1, id2)) {
((MyTag) tag).subValueSum(value);
}
}同时,在Tag里维护valueSum的代码如下:
private int valueSum;
public void addPerson(Person person) {
if (!persons.containsValue(person)) {
ageSum += person.getAge();
for (Person person1 : persons.values()) {
if (person.isLinked(person1)) {
valueSum += person.queryValue(person1) * 2;
}
}
persons.put(person.getId(), person);
}
}
public void delPerson(Person person) {
if (persons.containsValue(person)) {
ageSum -= person.getAge();
persons.remove(person.getId());
for (Person person1 : persons.values()) {
if (person.isLinked(person1)) {
valueSum -= person.queryValue(person1) * 2;
}
}
}
}
public boolean hasTwoPerson(int id1, int id2) {
return persons.containsKey(id1) && persons.containsKey(id2);
}
public void addValueSum(int value) {
valueSum += value * 2;
}
public void subValueSum(int id1, int id2) {
valueSum -= persons.get(id1).queryValue(persons.get(id2)) * 2;
}
四、Junit测试分析
我认为,借助JML可以很好的帮助设计Junit测试,首先ensure是确保完成的内容,我们可以针对这个进行辨别实现是否有误。同时JML也给出了assignable的范围,我们也可以对该范围外的内容进行检查,是否被修改。
例如第三次作业的Junit测试:
//assertReturn
assertEquals(ans, emojiList.size());
//assertMessagenumber
assertEquals(oldMessages.size(), testNetWork.getMessages().length);
//assertEmoji
Message[] messages = testNetWork.getMessages();
for (Message message : messages) {
if (message instanceof MyEmojiMessage) {
MyEmojiMessage emojiMessage = (MyEmojiMessage) message;
int emojiId = emojiMessage.getEmojiId();
assertEquals (true, emojiList.get(emojiId) >= limit);
}
}
//assertId&Head
assertEquals(newEmojiIdList.length, newEmojiHeatList.length);
//assertEmojiNumber
assertEquals(emojiList.size(), newEmojiIdList.length);
//assertStrict
for (int i = 0; i < newEmojiIdList.length; i++) {
assertEquals(true, emojiList.containsKey(newEmojiIdList[i]));
assertEquals(Optional.ofNullable(emojiList.get(newEmojiIdList[i])), Optional.of(newEmojiHeatList[i]));
}其中恰好对应了其JML的描述:
/*@ public normal_behavior
@ assignable emojiIdList, emojiHeatList, messages;
@ ensures (\forall int i; 0 <= i && i < \old(emojiIdList.length);
@ (\old(emojiHeatList[i] >= limit) ==>
@ (\exists int j; 0 <= j && j < emojiIdList.length; emojiIdList[j] == \old(emojiIdList[i]))));
@ ensures (\forall int i; 0 <= i && i < emojiIdList.length;
@ (\exists int j; 0 <= j && j < \old(emojiIdList.length);
@ emojiIdList[i] == \old(emojiIdList[j]) && emojiHeatList[i] == \old(emojiHeatList[j])));
@ ensures emojiIdList.length ==
@ (\num_of int i; 0 <= i && i < \old(emojiIdList.length); \old(emojiHeatList[i] >= limit));
@ ensures emojiIdList.length == emojiHeatList.length;
@ ensures (\forall int i; 0 <= i && i < \old(messages.length);
@ (\old(messages[i]) instanceof EmojiMessage &&
@ containsEmojiId(\old(((EmojiMessage)messages[i]).getEmojiId())) ==> \not_assigned(\old(messages[i])) &&
@ (\exists int j; 0 <= j && j < messages.length; messages[j].equals(\old(messages[i])))));
@ ensures (\forall int i; 0 <= i && i < \old(messages.length);
@ (!(\old(messages[i]) instanceof EmojiMessage) ==> \not_assigned(\old(messages[i])) &&
@ (\exists int j; 0 <= j && j < messages.length; messages[j].equals(\old(messages[i])))));
@ ensures messages.length == (\num_of int i; 0 <= i && i < \old(messages.length);
@ (\old(messages[i]) instanceof EmojiMessage) ==>
@ (containsEmojiId(\old(((EmojiMessage)messages[i]).getEmojiId()))));
@ ensures \result == emojiIdList.length;
@*/
public int deleteColdEmoji(int limit);五、单元学习体会
在本单元的学习过程中,我体验到了编写和理解JML规格的挑战,也因此有了不少收获。虽然这次经历的感受并不算特别好,但它确实帮助我学到了许多重要的知识和技能。
在学习和使用JML的过程中,我深刻体会到形式化规格对于软件开发的重要性和挑战性。JML通过在Java代码中嵌入详细的行为描述,为开发者提供了一种有效的工具,用来明确程序的预期行为和约束条件。这种明确性不仅有助于提升代码的可靠性,还能在团队协作中提供清晰的沟通桥梁。
然而,学习和使用JML确实有点挑战。写这种规格要求我具备很强的逻辑思维能力和细心的编码习惯。特别是刚开始接触JML时,它复杂的语法和严格的规则常常让我感到困惑和沮丧。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









