







渐进式生成与模型压缩优化方案
一、赛题背景

随着技术的飞速发展,人工智能技术已经成为推动社会变革的关键力量。在这个充满创新的时代,oneAPI技术堆栈崭露头角,为构建各种创新解决方案提供了巨大的潜力。在这一背景下,本次竞赛旨在深入探讨人工智能技术在特定领域的应用,涵盖机器学习、深度学习和数据分析等多个方面,同时为参赛者提供实践机会,通过解决问题和实现功能,更好地理解和运用oneAPI技术。
Stable Diffusion是2022年发布的深度学习图像化生成模型,它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如内补绘制、外补绘制,以及在提示词指导下产生图生图的翻译。
Stable Diffusion技术作为一种先进的生成模型,具有在生成图像任务中表现出色的潜力。然而,在实际部署中,要确保模型在端侧设备上的高效运行,需要面对一系列挑战,包括性能瓶颈和资源利用率。通过模型优化方案,参赛者将深入挖掘Stable Diffusion技术的性能潜力,结合oneAPI技术堆栈,实现在指定硬件平台上的部署优化,为生成图任务提供更高效、更稳定的解决方案。
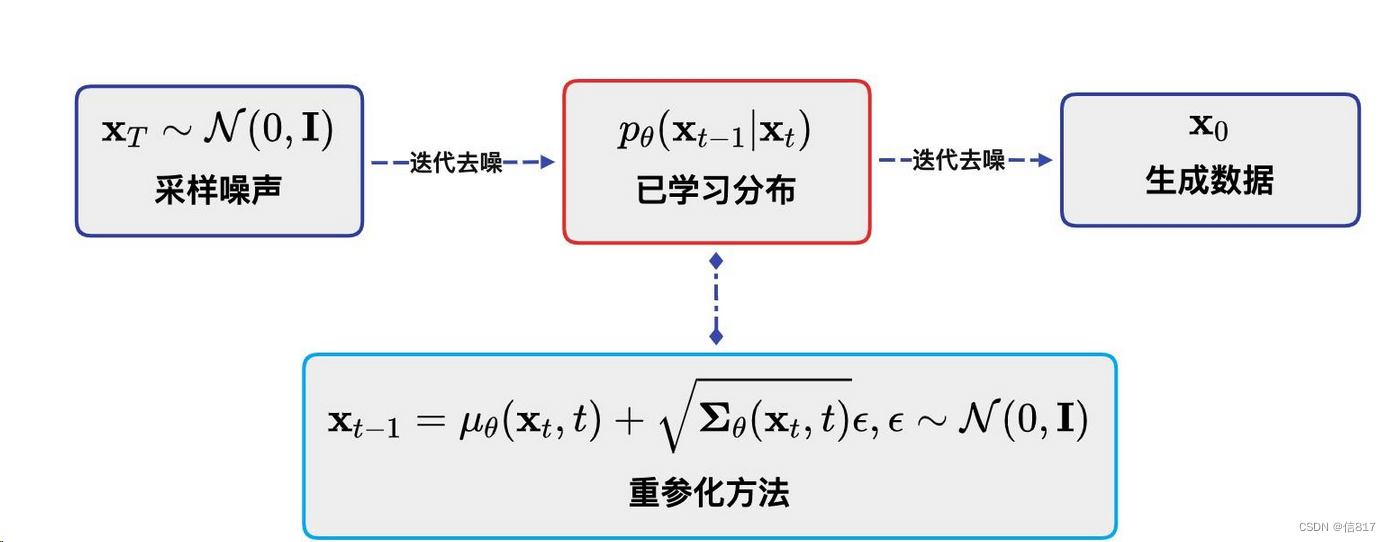
二、原理解读
文生图任务是指将一段文本输入到SD模型中,经过一定的迭代次数,SD模型输出一张符合输入文本描述的图片。

该模型主要可以分为三个部分:
- 变分编码器 Vector Quantised Variational AutoEncoder,VQ-VAE
- 扩散模型 Diffusion Model, DM
- 条件控制器 Conditioning
其中主要的VAE由编码器(Encoder)和解码器(Decoder)两部分组成:

Step 1. 输入图片Input通过编码器被到转换到潜在空间,得到潜在空间的图片表示Latent Image Input
Step 2. 配合Conditioning,Diffusion Model对Latent Image Input进行处理,产生Latent Image Output
Step 3. 解码器将由Diffusion Model产生的Latent Image Output映射回像素空间,得到输出图片Output
图片通过VAE转换到低维空间,配合Conditioning的DM产生新的变量,再通过VAE将生成的变量转换为图片。
例如赛题要求:
- Prompt输入:“a photo of an astronaut riding a horse on mars”
- Negative Prompt输入:“low resolution, blurry”
图片输出:512*512,24 Bit,PNG格式
利用VAE的编码器将输入图片Input降维,得到Latent Image Input。利用训练好的DM,不断对图片进行噪声预测,并对Latent Image Input进行去噪,经过一定步骤后得到去除了噪声的Latent Image Output,最终通过VAE的解码器得到输出图片Output。
通过text prompt得到的Embedding暂时还无法直接使用,还需要通过Transfomer 进行再加工才能喂给属于DM的噪声预测器。值得一提的是,Transformer是SD能够支持多模态的重要原因,它不仅能够处理text prompt生成的embedding,还能够处理类似图片、深度图等输入,将其转化为噪声预测器能够使用的数据。
Transfomer的输出会被噪声预测器多次利用,并且由于Transfomer的Cross Attention机制,它能够正确的利用text prompt中的内容。并且由于Transfomer的Self Attention机制,prompt能够被正确解读,例如"a photo of an astronaut riding a horse on mars",SD会将"astronaut"和"horse"组合。然后利用这个信息去影响噪声预测器的输出,让DM的逆向过程朝着带有”an astronaut riding a horse“的图像生成。
二、优化方向解析
我的项目具体实现是致力于解决在文生成图任务中,模型规模庞大导致的高存储需求和计算开销大的问题。具体方法是通过采用渐进式模型剪枝与量化策略配和CPU与GPU的混合使用,能够在不损失生成质量的前提下,逐步减小模型的大小,并提高模型的推理速度。(项目中具体实现了模型的剪枝,由于时间问题和学习学校课程,文章中的其他优化点还没有具体实现,其它的优化方案在本文中简要的做了说明,有兴趣的小伙伴可以联系wx一起探讨实现)
在模型优化方面,我主要关注神经元剪枝算法,通过精细的剪枝策略降低了模型的冗余部分,同时利用 OpenVINO 工具对模型进行文生成图预处理。利用 OpenVINO 工具套件的 Layout API 对输入进行预处理,一点一点微调,我在不牺牲生成质量和大小的前提下,逐步减小模型大小并提高推理速度,一点点实现了异步执行与 Pipeline 并行性,充分发挥此次大赛提供的硬件资源的优势,为端到端性能提升和硬件适应性提供了一体化的解决方案。(大家有更好的优化方案、想法可以一起讨论)
三、模型压缩方案
OpenVINO工具套件提供了一系列的模型优化工具,包括模型剪枝和量化等等,我的思路和实现也主要是基于这两套工具来对SD模型在比赛提供的硬件上进行模型训练和优化的。具体如下:
首先必不可少的当然是对于工具的利用:在改进数据管道和预处理加速中, OpenVINO 工具中有许多可用的方法 。
3.0 利用工具优化:
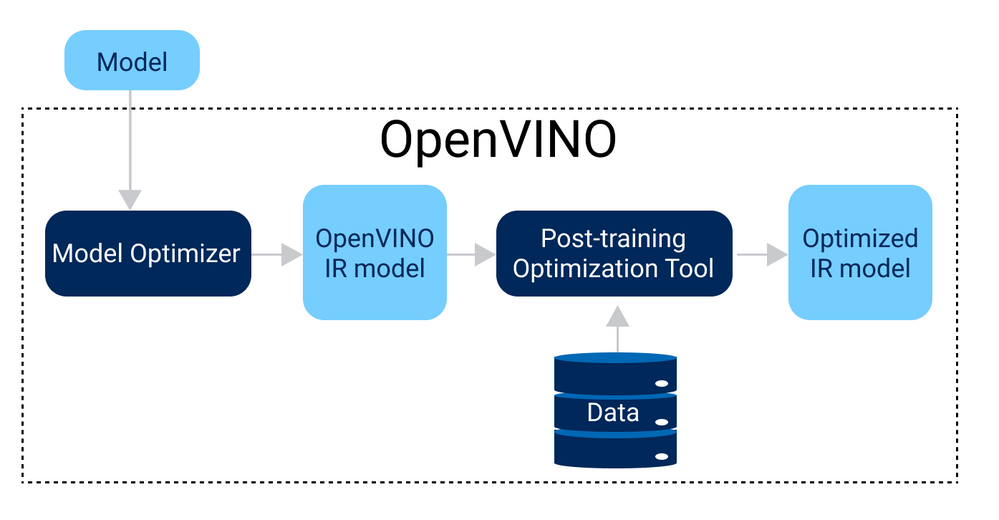
我们的实例中主要运用的是以下两种API对于示例模型进行了一个简单优化处理,在GPU占用率上有了明显可见的下降,且相同配置参数下文生图时间间隔下降了0.4s。具体实现思路和伪代码如下(主要用于大家学习思路):
一、使用 OpenVINO 对输入进行预处理:
-
在对Static Diffusion模型进行优化时,采用 OpenVINO 进行输入预处理是至关重要的。以下是将预处理步骤集成到模型中的具体思路:
- 声明 Tensor 格式: 首先,从实际用户数据中声明模型输入的 Tensor 格式,包括形状、布局、精度、颜色格式等。这样的声明有助于确保模型输入与实际推理数据的格式相匹配。
- 描述预处理步骤: 确定需要应用于用户数据的预处理步骤序列。这可能包括均值调整、尺度缩放、通道反转等,以确保输入数据满足模型的要求。通过 OpenVINO 的模型转换 API,可以方便地描述和配置这些预处理步骤。
- 指定模型数据格式: 对于 Static Diffusion 模型,模型的精度和形状通常是已知的,但需要指定其他信息,如布局等。通过 OpenVINO 提供的模型数据格式参数,可以将模型与实际推理数据正确对齐。
- 集成到模型中: 完成预处理步骤后,将这些步骤集成到模型中。通过 OpenVINO 提供的模型构建功能,可以轻松构建具备预处理功能的模型。
# 示例代码 from openvino
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









