






简介
本文写一篇关于java库与库之间的数据传输,现实生产中可能是通过其他方式完成,在没有架构的基础上使用java实现跨库的数据传送,非常不便利。但是作为练习我觉得确实非常有用,涉及的java知识点相对较多。本文以一个实列讲解,一个思考留给学习的粉丝就行后续实操锻炼。
实操准备
| 数据库 | 表名 | 链接url | |
| 数据源 | Oracle-19c | dm.book | jdbc:oracle:thin:@//localhost:1521/ORCL |
| 目标源 | postgresql-15.2 | main.book | jdbc:postgresql://10.0.0.199:6432/postgres |
配置JDBC驱动
通过dbeaver找到想要的驱动信息,也算是开发的一个小tips;
通过dbeaver链接的对应的源库和目标库,如何能正常连接,使用dbeaver连接的JDBC驱动就好了。
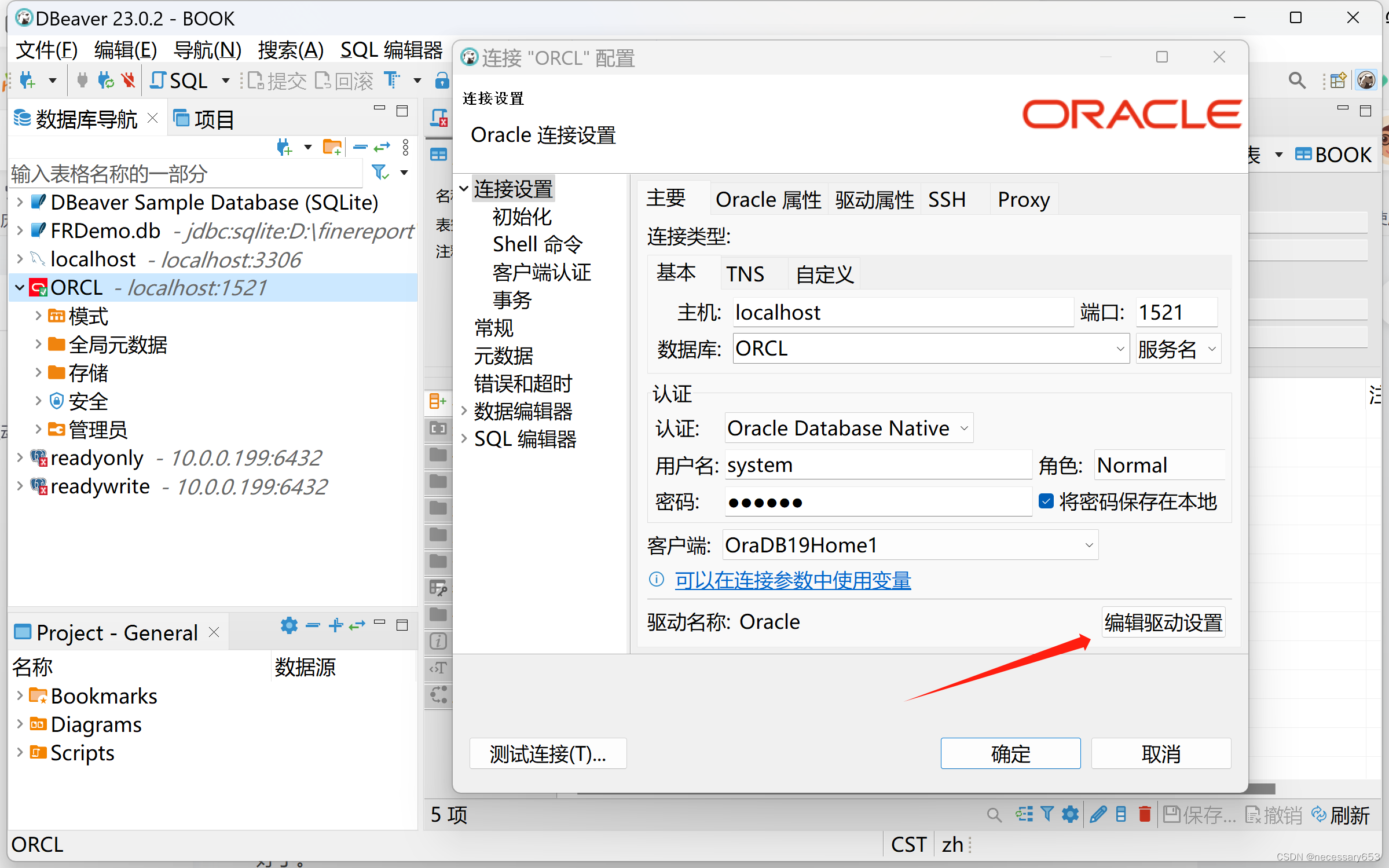
点击编辑驱动,
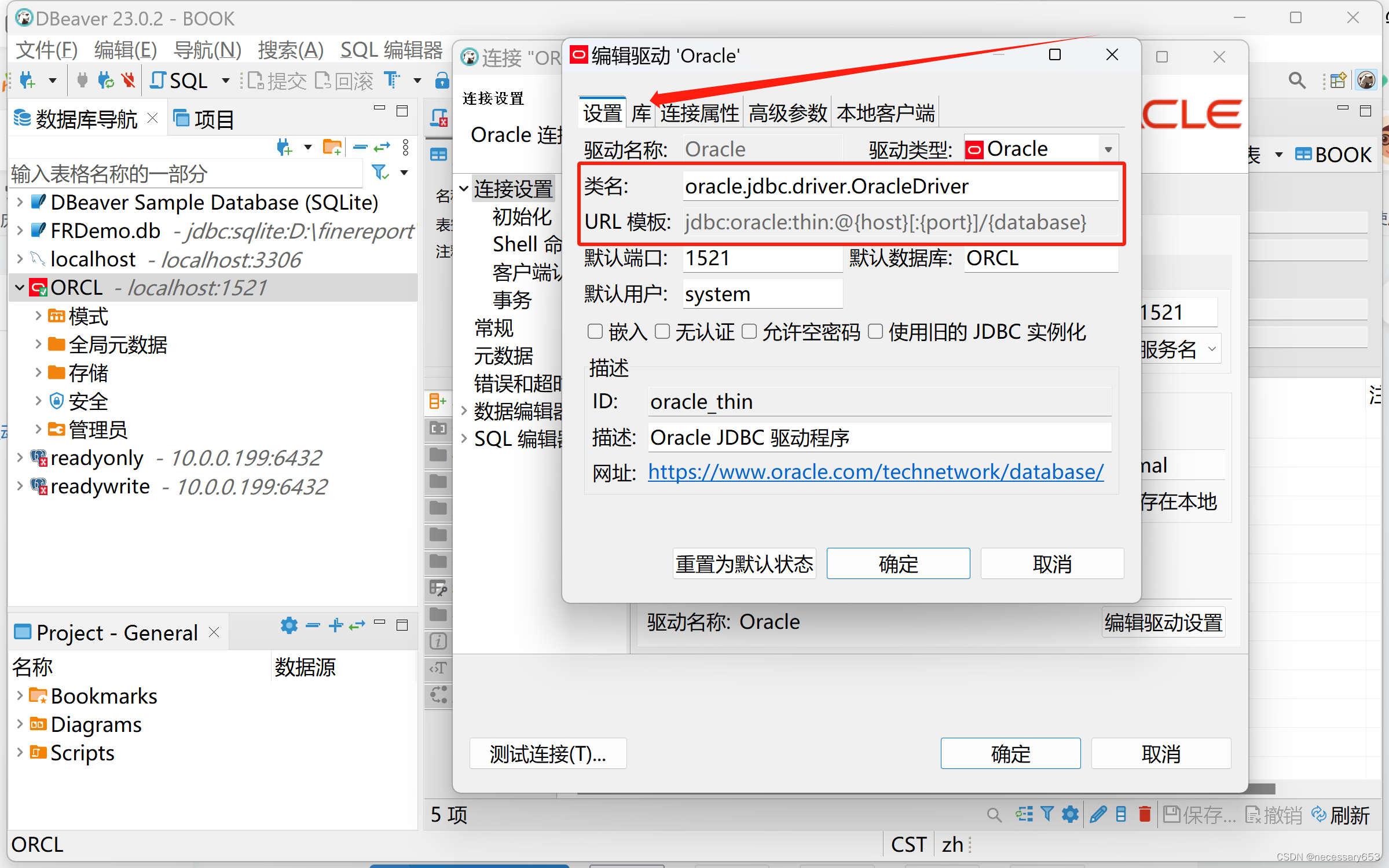
记住这里的类名和url模板。然后点击库,会出现一些JDBC包
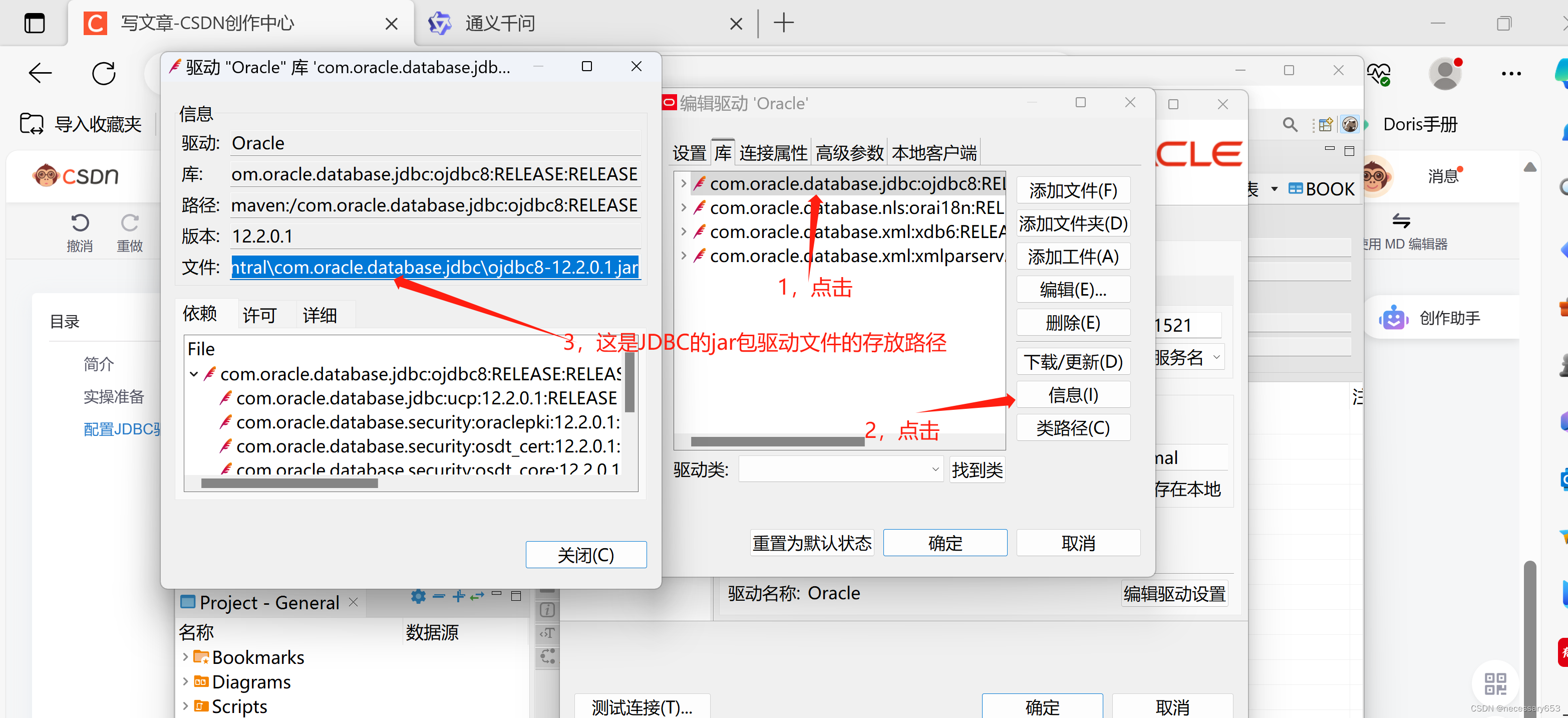
将以上的jar复制到idea当前所创建的project下的lib目录中
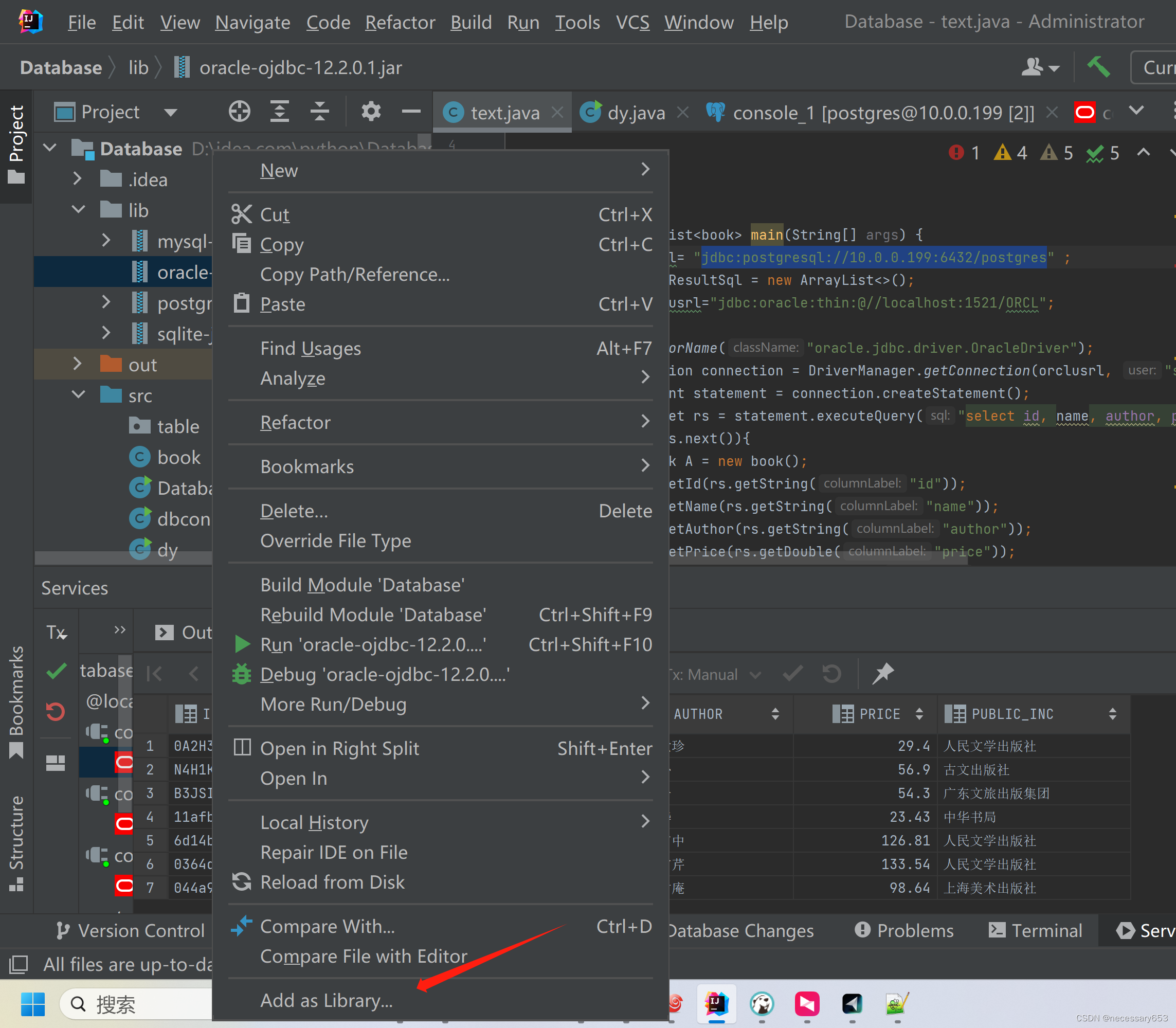
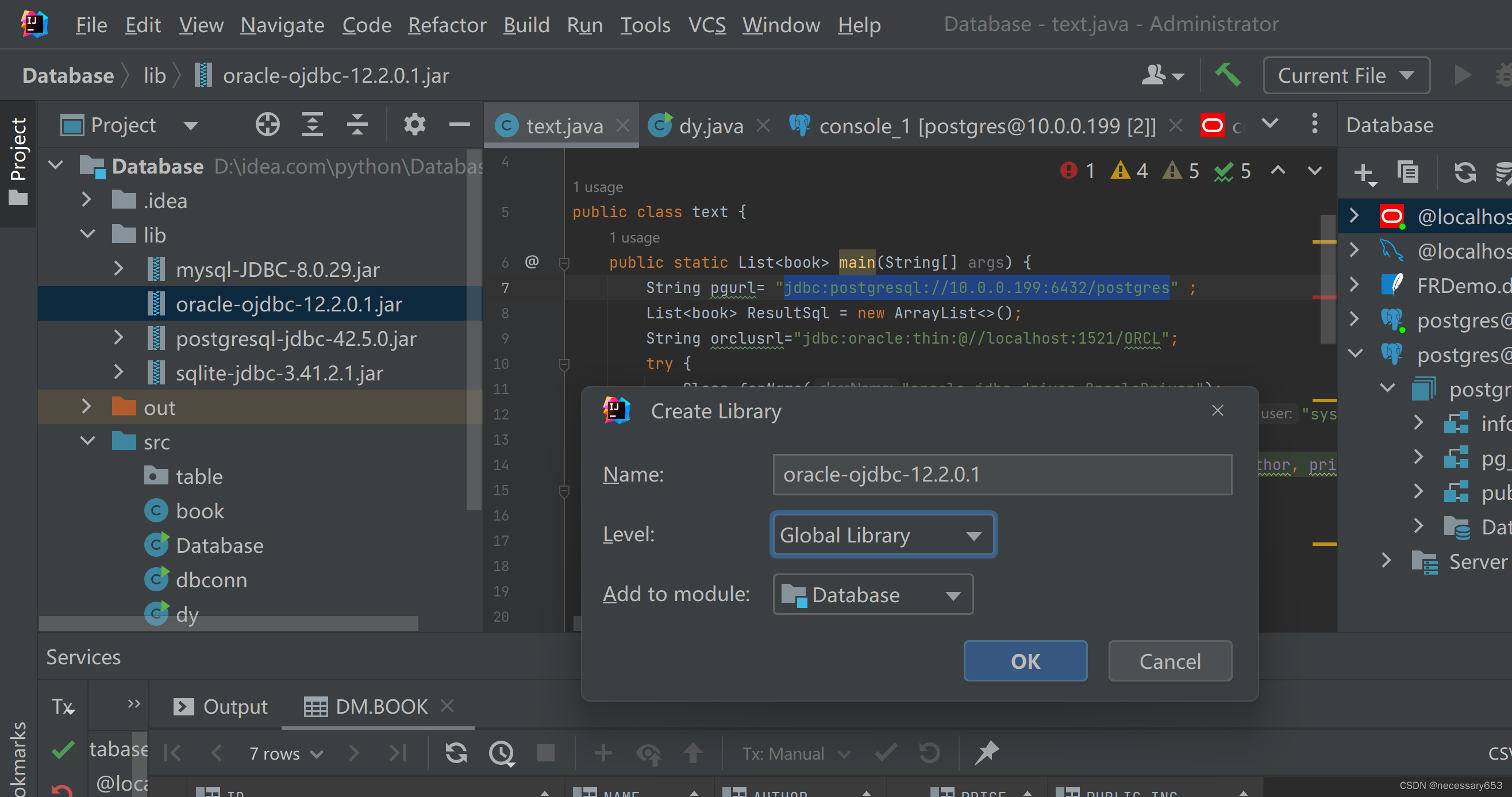
此时JDBC依赖包就创建完成了
创建测试数据
在源数据中创建一个有数据的表,用于将数据调度到postgresql数据库中去
create table dm.book(ID varchar2(50), name varchar2(50), author varchar2(50), price number(10,3), public_inc varchar2(50));
INSERT INTO dm.book
(ID, name, author, price, public_inc)
VALUES('0A2H3IW92I3JQU10S83OQ8O3B4IS8U4H', '镜花缘', '李汝珍', 29.4, '人民文学出版社');
INSERT INTO dm.book
(ID, name, author, price, public_inc)
VALUES('N4H1KS83HSI3HQ9DH33EBSSDIDCJ32C3', '山海经', '厚朴', 56.9, '古文出版社');
INSERT INTO dm.book
(ID, name, author, price, public_inc)
VALUES('B3JSI38AU4JD94KWIW9SHERF3FEV39SD', '玉观音', '海岩', 54.3, '广东文旅出版集团');
INSERT INTO dm.book
(ID, name, author, price, public_inc)
VALUES('11afb0ddf43a4ee59aadf380c1f15ad5', '活着', '余华', 23.43, '中华书局');
INSERT INTO dm.book
(ID, name, author, price, public_inc)
VALUES('6d14bb33654a46e686be7e49d4fae396', '三国演义', '罗贯中', 126.81, '人民文学出版社');
INSERT INTO dm.book
(ID, name, author, price, public_inc)
VALUES('0364d4b04387497a917e5e1dd6d8c96c', '红楼梦', '曹雪芹', 133.54, '人民文学出版社');
INSERT INTO dm.book
(ID, name, author, price, public_inc)
VALUES('044a980718124da894fdd70f37006d13', '水浒传', '施耐庵', 98.64, '上海美术出版社');
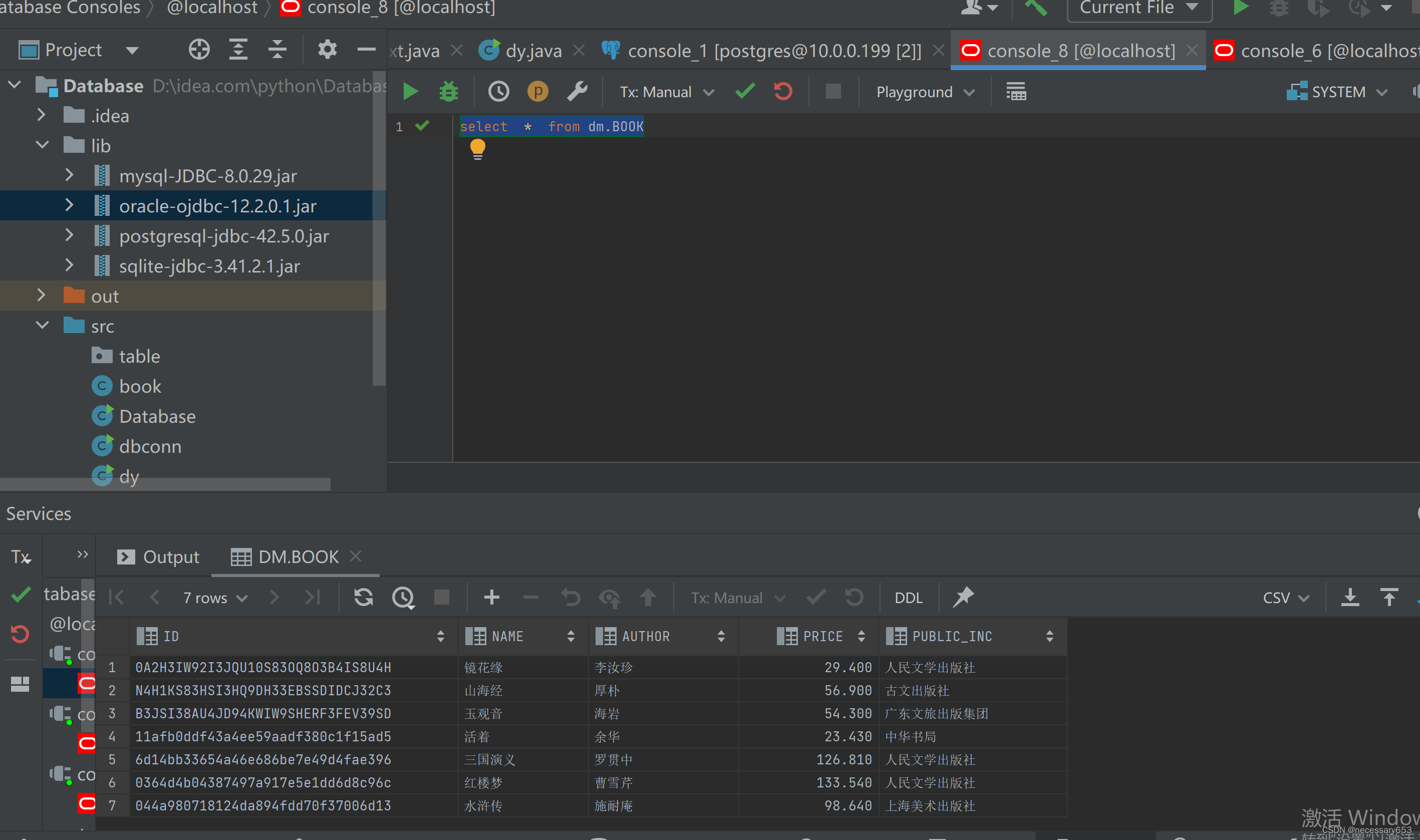
编辑代码
为了完成以上的代码业务需求,我们代码分成三个文件完成
1,创建一个实体类,在java中用于存储表结构的数据,
2,核心逻辑代码,也就整个完成主体调度ETL的主题代码。
3,调用代码
一 ,创建实体类
public class book {
private String id ;
private String name;
private String author;
private double price;
private String public_inc;
//以下代码都是自动生成的,只需要把以上的代码编辑完成,然后生成getter,setter。
public book(String id, String name, String author, double price, String public_inc) {
this.id = id;
this.name = name;
this.author = author;
this.price = price;
this.public_inc = public_inc;
}
public book() {
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public String getPublic_inc() {
return public_inc;
}
public void setPublic_inc(String public_inc) {
this.public_inc = public_inc;
}
}
实体类中创建了变量的数据类型就需要自动生成其然后生成getter,setter以及构造方法和无参构造方法
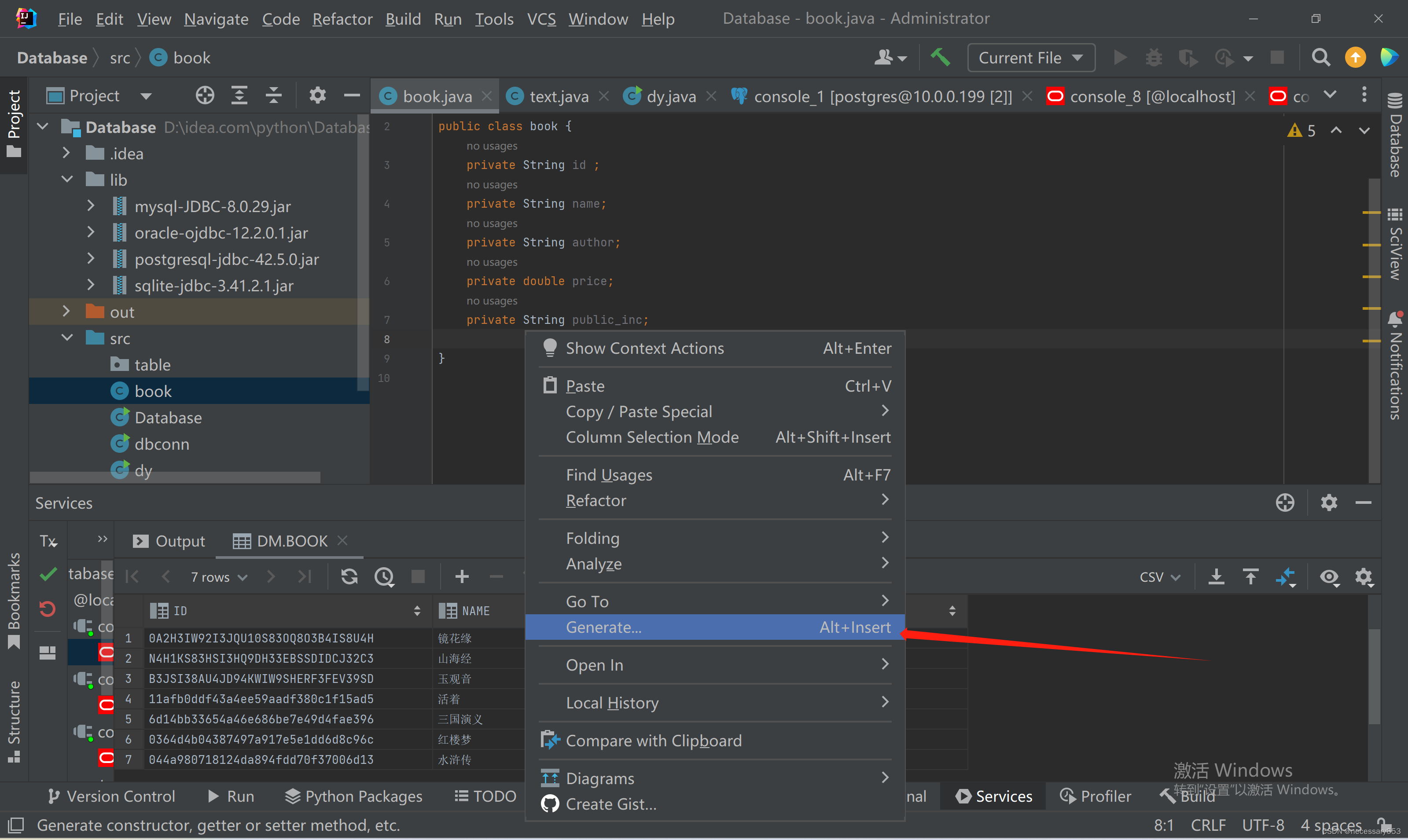
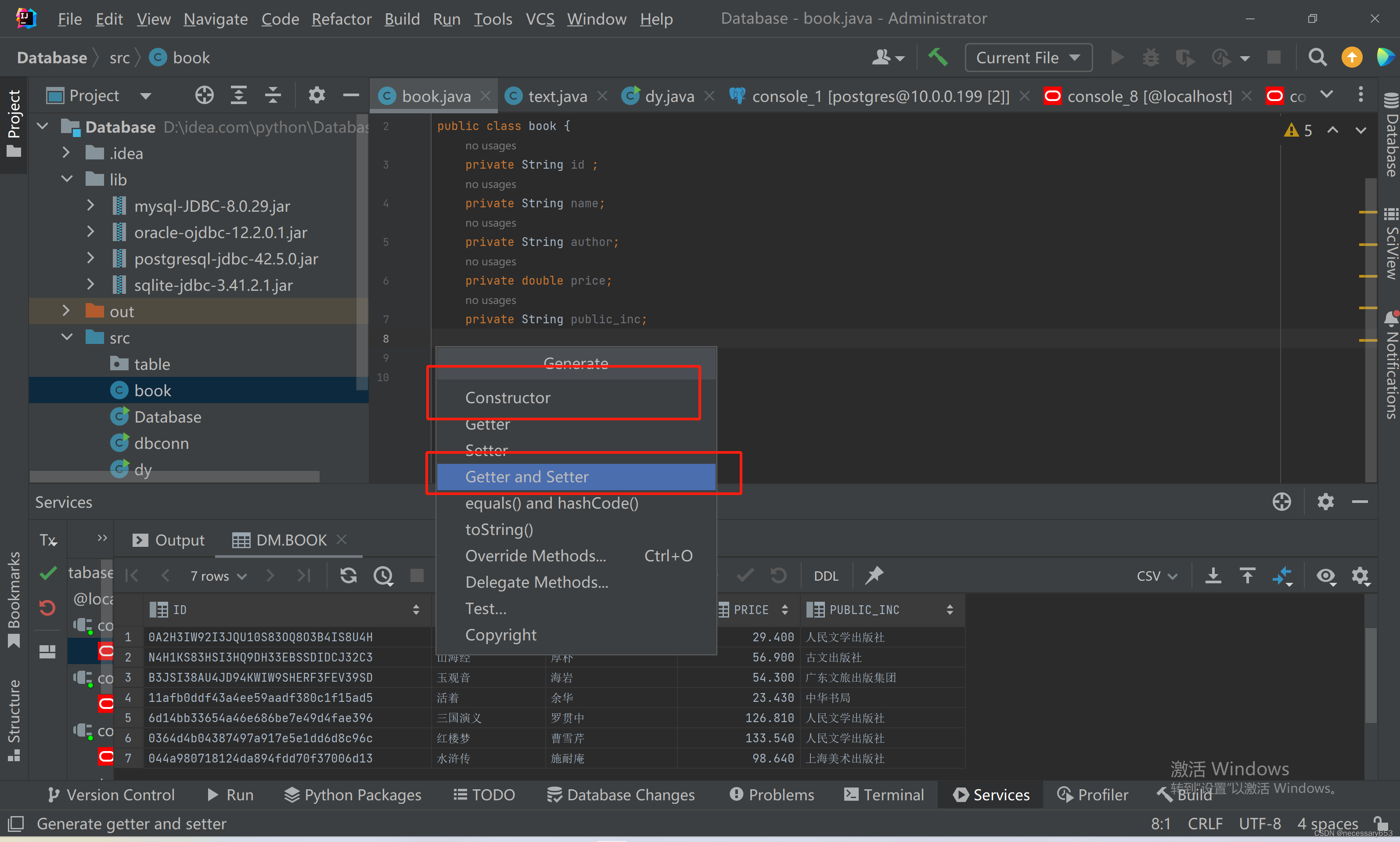 依次点击构造方法,getter and setter.
依次点击构造方法,getter and setter.
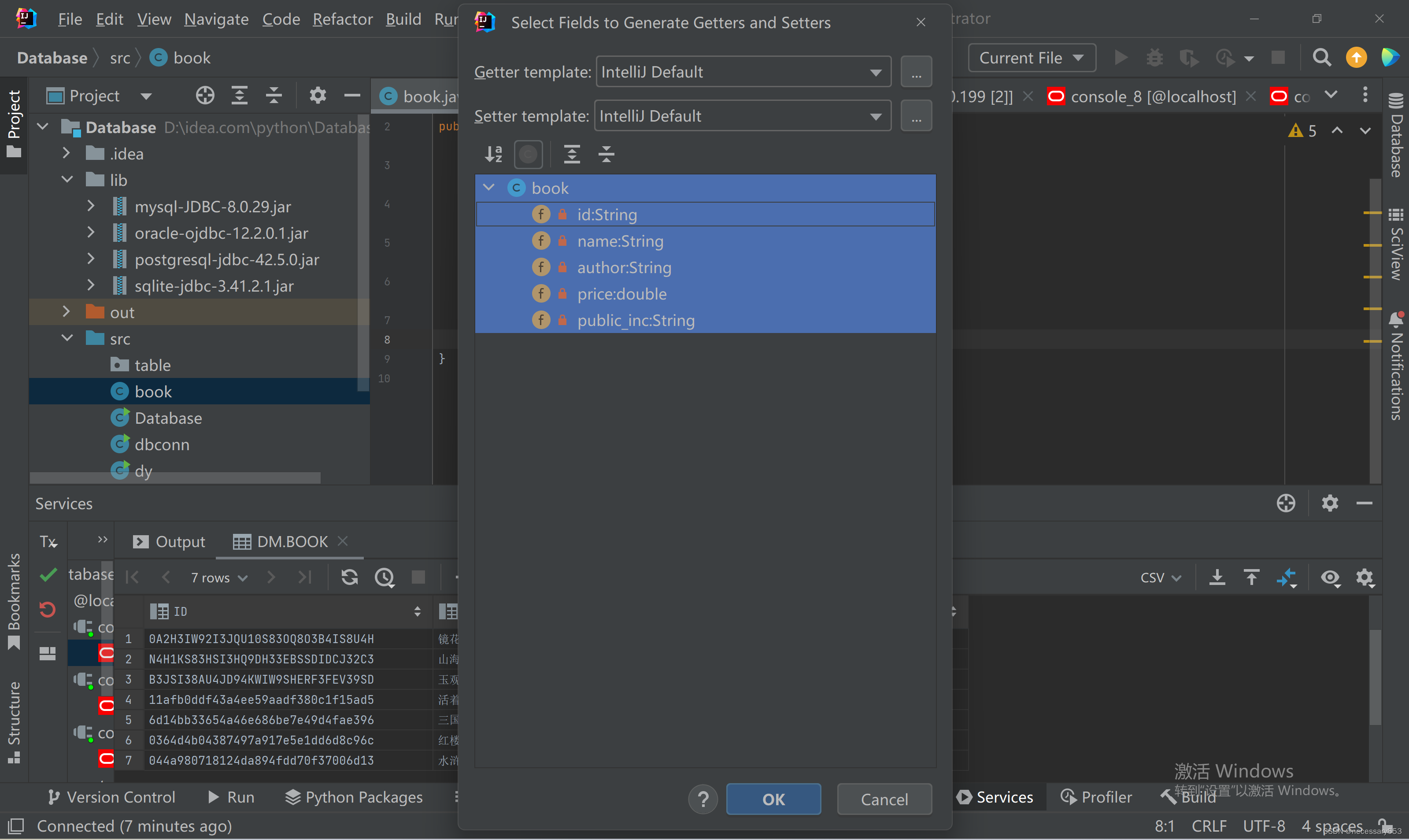
构造方法创建两个,一个无参,一个有参。
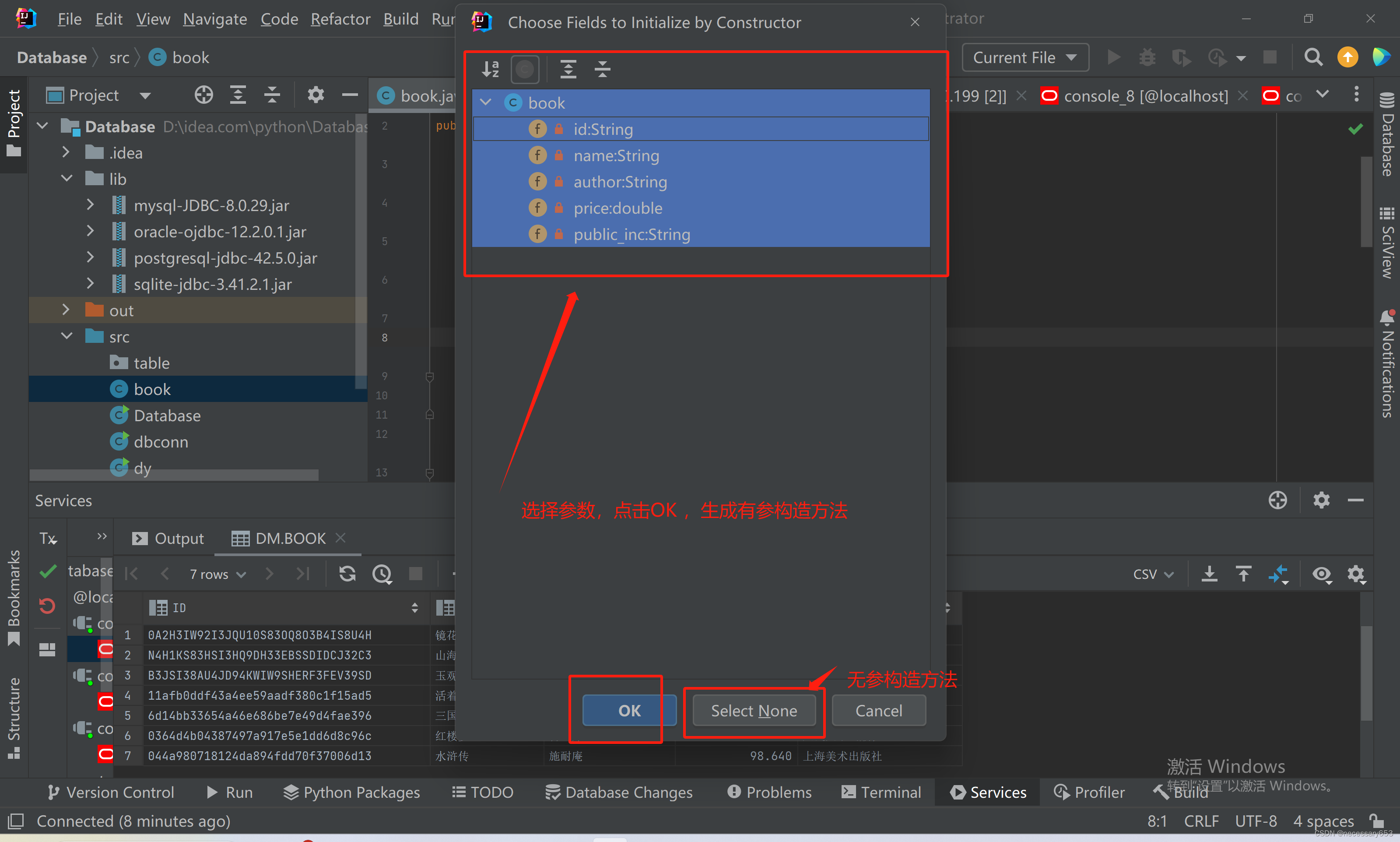
完成这两个操作之后,我们的实体类就创建完成了。
实体类的三大特点:
属性封装:实体类通常会使用private修饰符来保护属性不被直接访问,只通过提供的getter和setter方法来获取或设置属性的值。
数据操作:实体类通常会包含一些数据操作的方法,如插入、删除、修改等,以便在业务逻辑中进行数据处理。
对象实例化:使用实体类可以方便地创建业务模型中的对象实例。
实体类主要适用于存储数据库多行多列的表结构数据。
二,核心逻辑代码
//在下问代码编辑中会提示生成所需的import,只需要点击即可。
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
//创建类名,自定义,本文使用的text
public class text {
//创建main方法
public static int main(String[] args) {
//定义目标数据据的url
String pgurl= "jdbc:postgresql://10.0.0.199:6432/postgres" ;
//创建一个名为ResultSql,数据类型为自定义的book的变量,用于装在表的结构化数据,其表的数据类型必须是自定义实体类book所有的
List<book> ResultSql = new ArrayList<>();
//定义一个源数据库oracle的url
String orclusrl="jdbc:oracle:thin:@//localhost:1521/ORCL";
try {
//第一步加载源数据库的url
Class.forName("oracle.jdbc.driver.OracleDriver");
//使用JDBC的DriverManager类的getConnection()方法建立到指定数据库的连接
Connection connection = DriverManager.getConnection(orclusrl, "system", "system");
//使用Connection对象的createStatement()方法创建一个新的Statement对象。这个对象可以用来执行各种类型的SQL语句,包括查询、更新、删除等。
Statement statement = connection.createStatement();
//使用Statement对象的executeQuery()方法执行SQL查询语句,并将结果集存储在ResultSet对象rs中。
ResultSet rs = statement.executeQuery("select id, name, author, price, public_inc from dm.book");
//while(rs.next()){是一个while循环,它会一直重复,直到结果集中没有更多的行。每次迭代都会使光标向下移动一行,以便读取下一组数据
while(rs.next()){
//它们创建了一个新的Book对象,
book A = new book();
//并通过ResultSet的getString()和getDouble()方法将每一列的数据提取出来,分别赋值给Book对象的属性。
A.setId(rs.getString("id"));
A.setName(rs.getString("name"));
A.setAuthor(rs.getString("author"));
A.setPrice(rs.getDouble("price"));
A.setPublic_inc(rs.getString("public_inc"));
//将这个Book对象添加到了ResultSql集合中。
ResultSql.add(A);
}
//关闭Statement对象
statement.close();
//关闭链接
connection.close();
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//定义变量i用于接受下文executeUpdate方法的返回值
int i = 0;
try {
//加载postgresql的JDBC驱动
Class.forName("org.postgresql.Driver");
//创建与postgresql的数据库链接
Connection connection = DriverManager.getConnection(pgurl, "readywrite", "readywrite");
//使用Connection对象的prepareStatement()方法创建一个PreparedStatement对象。这里的sql参数表示要执行的SQL语句,可以带有占位符,
String sql="insert into main.book(id, name, author, price, public_inc) values (?,?,?,?,?)";
//使用Connection对象的prepareStatement()方法创建一个PreparedStatement对象。这里的sql参数表示要执行的SQL语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//是一个for-each循环,它会对ResultSql集合中的每个元素进行迭代。直到结果集中没有更多的行。每次迭代都会使光标向下移动一行,以便读取下一组数据
for (book A:ResultSql){
//在循环体内。它们将当前Book对象的每个属性的值设置到PreparedStatement对象对应的占位符上。
// 这里的setString()和setDouble()方法是用来设置非二进制类型的数据;
// 对于二进制类型的数据,则需要使用setBinaryStream()、setBlob()、setBytes()、setCharacterStream()、
// setClob()、setNCharacterStream()、setNClob()、setObject()、setRef()、setRowId()、setSQLXML()等方法。
preparedStatement.setString(1,A.getId());
preparedStatement.setString(2,A.getName());
preparedStatement.setString(3,A.getAuthor());
preparedStatement.setDouble(4,A.getPrice());
preparedStatement.setString(5,A.getPublic_inc());
//使用PreparedStatement对象的executeUpdate()方法执行SQL插入语句,返回受影响的行数。
//此处一个是一个循环,所以每一此执行的都是一行,变量I的值也就是1.
i = preparedStatement.executeUpdate();
}
preparedStatement.close();
connection.close();
} catch (SQLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return i;
}
}关键字讲解
在定义一个实体类属性的变量的时候
固定格式:List<实体类名> 变量名 = new ArrayList<>();
line47 int i = 0;
定义了一个变量i,用于接受后面执行insert后的返回值,其返回值是0或者1;
思考:
如何让这个变量I变成一个累计值。
line 54
String sql="insert into main.book(id, name, author, price, public_inc) values (?,?,?,?,?)";
在定义一个SQL语句变量的时候里面使用了“?”,这个问号是一个占位符,用于
preparedStatement.setString方法的定位。
调用代码
import java.util.List;
public class dy {
public static void main(String[] args) {
//在text的main方法的属性设置中,应为viod替换成了static int, 而这个int必须与代码中retrun I 返回值数据类型相同。
//调用代码中设置了一个int类型的bk变量,用于接收text.main调用的返回值I。
int bk = text.main(new String[]{"开始调用"});
System.out.println(bk);
}
}点击运行调用脚本
到目标数据库中查看效果。
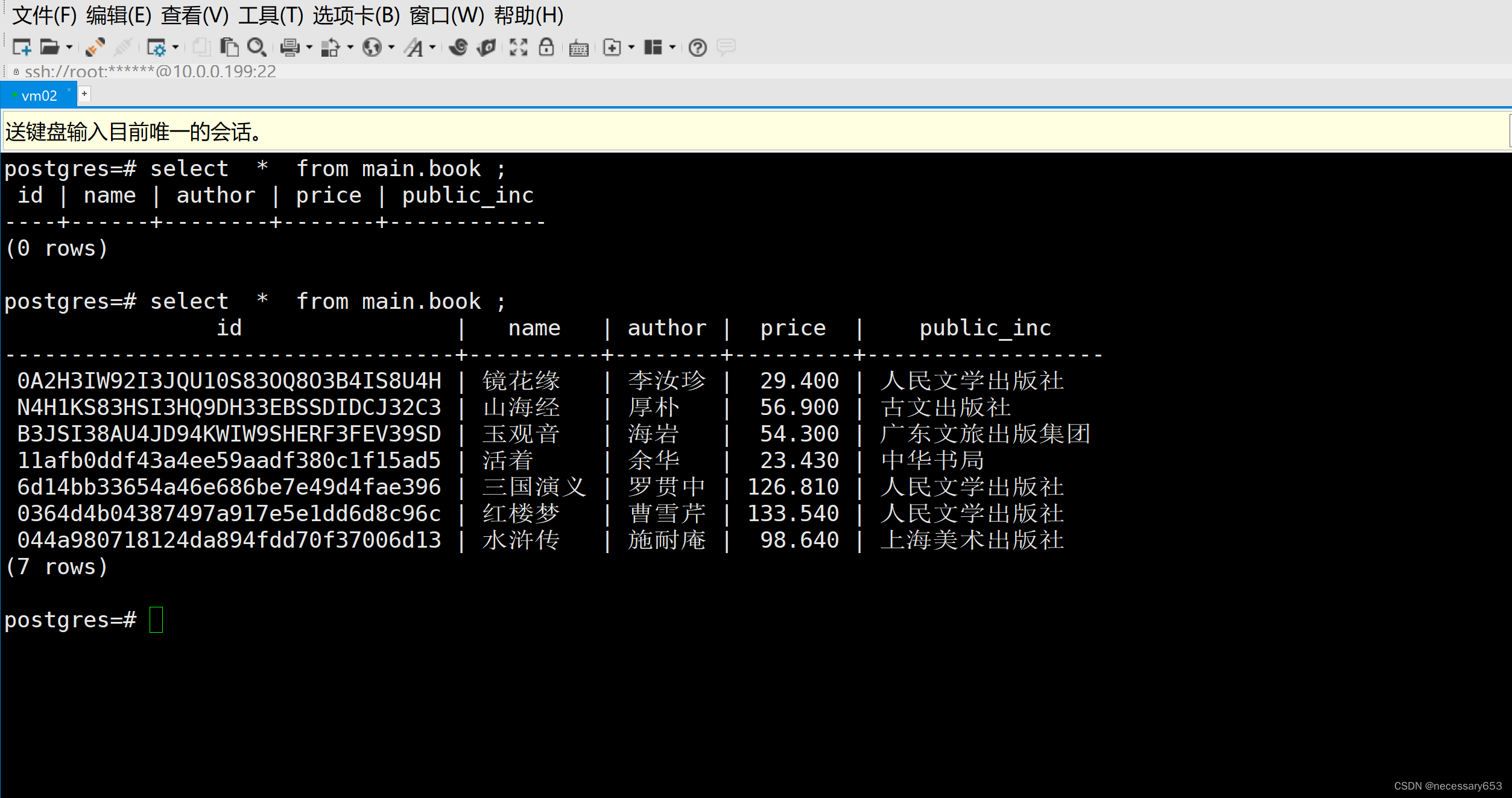
数据库展示正常。
















 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









