






简介
作为数据库管理员(DBA),定期进行数据库的日常巡检是非常重要的。以下是一些原因:
保证系统的稳定性:通过定期巡检,DBA可以发现并及时解决可能导致系统不稳定的问题,如性能瓶颈、资源利用率过高或磁盘空间不足等。
提高数据的安全性:巡检可以帮助DBA发现潜在的安全风险,例如未经授权的访问、数据泄露或其他安全漏洞。及时采取措施,可以防止这些风险演变成实际问题。
避免数据丢失:DBA可以通过检查备份和恢复策略来确保数据的完整性,并确保在发生灾难时能够快速恢复业务运营。
确保合规性:许多行业都有特定的数据管理规定和法规要求。通过巡检,DBA可以确保他们的数据库管理系统符合这些规定和要求。
性能优化:巡检可以帮助DBA识别性能瓶颈,从而优化数据库以提高其效率和响应速度。
资源规划:通过巡检,DBA可以了解当前的资源使用情况,预测未来的资源需求,并根据需要调整资源配置。
综上所述,DBA的日常巡检是保持数据库健康运行的关键环节之一,也是确保业务连续性和高效运行的重要步骤。
目录
8、查询DML死锁会话sid,及引起死锁的堵塞者会话blocking_session
14、查询一个会话session、process平均消耗多少内存,查看下面avg_used_M值
1、查询碎片程度高的表
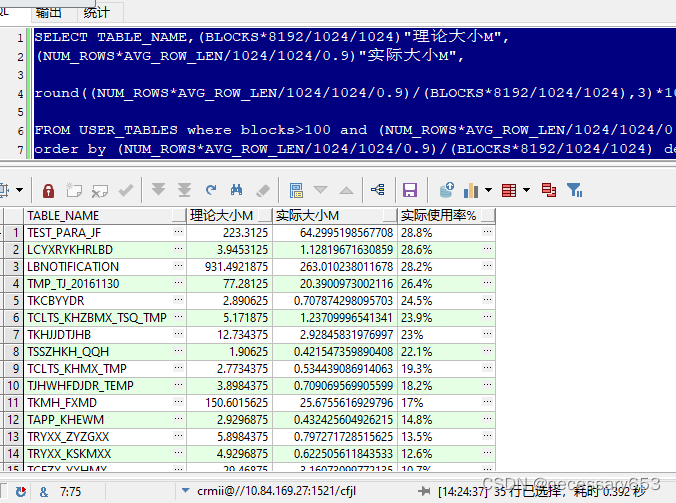
SELECT TABLE_NAME,(BLOCKS*8192/1024/1024)"理论大小M",
(NUM_ROWS*AVG_ROW_LEN/1024/1024/0.9)"实际大小M",
round((NUM_ROWS*AVG_ROW_LEN/1024/1024/0.9)/(BLOCKS*8192/1024/1024),3)*100||'%' "实际使用率%"
FROM USER_TABLES where blocks>100 and (NUM_ROWS*AVG_ROW_LEN/1024/1024/0.9)/(BLOCKS*8192/1024/1024)<0.3
order by (NUM_ROWS*AVG_ROW_LEN/1024/1024/0.9)/(BLOCKS*8192/1024/1024) desc这个SQL语句是在Oracle数据库中执行的,它从USER_TABLES视图中获取信息,该视图包含所有由当前用户拥有的表的信息。查询结果包含了表名、表的理论大小(以MB为单位)、表的实际大小(以MB为单位)和表的实际使用率(百分比)。
下面详细解释各部分含义:
TABLE_NAME: 这是从USER_TABLES视图中选择的列,它表示表的名称。
(BLOCKS*8192/1024/1024): 这是一个表达式,用于计算每个表的理论大小。在这里,“BLOCKS”列代表表占用的数据块数量,每个数据块大小默认为8192字节。因此,BLOCKS8192)/1024/1024得到的结果就是表占用的空间大小(以MB为单位)。
(NUM_ROWS*AVG_ROW_LEN/1024/1024/0.9): 这也是一个表达式,用于计算每个表的实际大小。在这里,“NUM_ROWS”列代表表中的行数,“AVG_ROW_LEN”列代表每行平均长度。“NUM_ROWSAVG_ROW_LEN”得到的结果是整个表占用的总字节数。然后将此结果除以1024再除以1024得到的结果是以MB为单位的表的实际大小。最后除以0.9是为了留出一部分未使用的空间,因为即使表中有空洞,Oracle也不会立即释放这部分空间。
round((NUM_ROWS*AVG_ROW_LEN/1024/1024/0.9)/(BLOCKS*8192/1024/1024),3)*100||'%': 这是一个表达式,用于计算每个表的实际使用率(百分比)。首先计算出实际大小与理论大小的比例(即除法运算),然后使用ROUND函数对结果保留三位小数。最后乘以100并将结果转换为百分比形式。
where blocks>100 and (NUM_ROWS*AVG_ROW_LEN/1024/1024/0.9)/(BLOCKS*8192/1024/1024)<0.3: 这个条件限制了只显示那些块数量大于100且实际使用率小于30%的表。
order by (NUM_ROWS*AVG_ROW_LEN/1024/1024/0.9)/(BLOCKS*8192/1024/1024) desc: 这个排序子句将结果显示为实际使用率从低到高的顺序。
2、查询索引碎片的比例
select name,
del_lf_rows,
lf_rows,
round(del_lf_rows / decode(lf_rows, 0, 1, lf_rows) * 100, 0) || '%' frag_pct
from index_stats
where round(del_lf_rows / decode(lf_rows, 0, 1, lf_rows) * 100, 0) > 30;
这个SQL查询来自Oracle数据库的INDEX_STATS视图,用于检索索引碎片化的程度。它返回的结果包括索引名称、删除的叶节点行数、叶节点行数以及碎片化百分比。
以下是每个字段的具体解释:
name: 是索引的名字。
del_lf_rows: 表示索引中已删除的叶子节点的数量。这表明曾经有记录存在于这些叶子节点,但现在已经不再使用它们。
lf_rows: 表示索引的叶子节点总数。这是一个估计值,并非精确值。
(del_lf_rows / decode(lf_rows, 0, 1, lf_rows)) * 100: 计算索引的碎片化程度。如果索引没有碎片,则该比例应接近于零;如果索引高度碎片化,则该比例应接近于100。
在这个公式中,decode()函数用于处理lf_rows=0的情况,因为在这种情况下除以零会导致错误。如果lf_rows=0,则该函数会将其替换为1,使得结果可以正确计算。round(): 四舍五入函数,用于将结果四舍五入到最接近的整数。
'%': 将结果转换为百分比格式。
where round(del_lf_rows / decode(lf_rows, 0, 1, lf_rows) * 100, 0) > 30: 条件子句,仅显示碎片化程度超过30%的索引。
3、集群因子clustering_factor高的表
集群因子越接近块数越好,接近行数则说明索引列的列值相等的行分布极度散列,可能不走索引扫描而走全表扫描
select tab.table_name,
tab.blocks,
tab.num_rows,
ind.index_name,
ind.clustering_factor,
round(nvl(ind.clustering_factor, 1) /
decode(tab.num_rows, 0, 1, tab.num_rows),
3) * 100 || '%' "集群因子接近行数"
from user_tables tab, user_indexes ind
where tab.table_name = ind.table_name
and tab.blocks > 100
and nvl(ind.clustering_factor, 1) /
decode(tab.num_rows, 0, 1, tab.num_rows) between 0.35 and 3
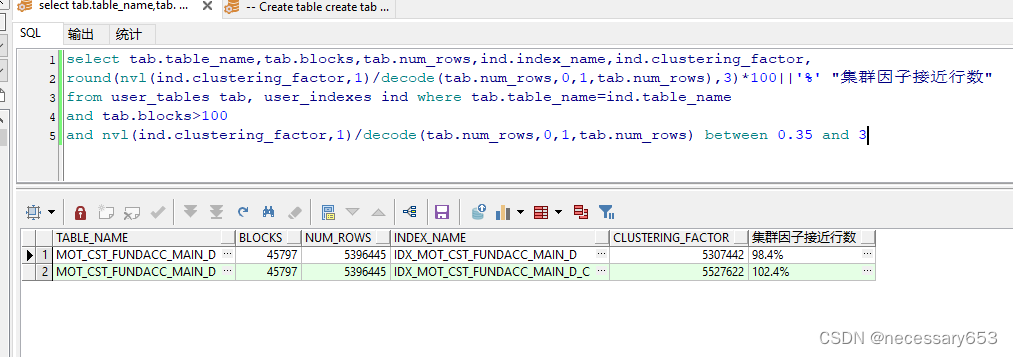
这个查询从Oracle数据库的USER_TABLES和USER_INDEXES两个视图提取信息,这两个视图分别包含了用户所有的表及其索引的信息。该查询结果包括表名、表的块数、表的行数、索引名、索引的聚簇因子以及聚簇因子与表的行数之间的相对比例。
以下是每个字段的具体解释:
table_name: 指定要查看的表的名称。
blocks: 指定表所占的块数。每个块的大小通常为8192字节,所以可以根据该数值来估算表所占的空间大小。
num_rows: 指定表的行数。
index_name: 指定表对应的索引名。
clustering_factor: 表示基于索引列上的值在物理存储上的聚集程度。较低的聚簇因子表示数据更紧密地分布在物理空间中,较高的聚簇因子表示数据较分散。聚簇因子与查询性能有关,在选择使用哪种类型的扫描时会参考这一因素(全表扫描或索引扫描)。
(nvl(ind.clustering_factor, 1) / decode(tab.num_rows, 0, 1, tab.num_rows)) * 100 || '%': 计算聚簇因子与行数之间的比例,将结果转换为百分比。nvl()函数用于处理可能为NULL的情况,如果ind.clustering_factor`为NULL,则该函数将其替换为1,以便可以进行除法运算。
between 0.35 and 3: 在WHERE子句中,该查询过滤出了聚簇因子与行数之间比例在0.35至3之间的表。这是根据经验设定的一个范围,一般来说,在这个范围内的表可能是最优的
4、根据sid查spid或根据spid查sid
select s.sid, s.serial#, s.LOGON_TIME, s.machine, p.spid, p.terminal
from v$session s, v$process p
where s.paddr = p.addr
and s.sid = XX
or p.spid = YY
查询从Oracle数据库的SESSION和VPROCESS两个动态性能视图中提取信息,其中SESSION提供了会话的详细信息,而PROCESS则提供了进程的详细信息。
该查询结果包括会话ID(SID)、序列号(Serial#)、登录时间、客户端机器名称、操作系统进程ID(SPID)以及终端类型。
以下是每个字段的具体解释:
s.sid, s.serial#, s.LOGON_TIME, s.machine: 这些字段均来自于V$SESSION视图,分别代表会话ID、序列号、登录时间以及客户端机器名称。
p.spid, p.terminal: 这些字段均来自于V$PROCESS视图,分别代表操作系统的进程ID和终端类型。
where s.paddr = p.addr: 这个条件用于关联V$SESSION和v$PROCESS两个视图,使我们可以得到与会话相关联的操作系统进程信息。
and s.sid = XX: 如果需要查找特定的会话,可以在WHERE子句中
添加该条件。例如,如果您想查找SID为XX的会话,只需将XX替换为您想要查找的SID即可。
or p.spid = YY: 同样,如果您需要查找特定的操作系统进程,可以使用该条件进行查找。例如,如果您想查找SPID为YY的进程,只需将YY替换为您想要查找的SPID即可。
5、根据sid查看具体的sql语句
select username, sql_text, machine, osuser
from v$session a, v$sqltext_with_newlines b
where DECODE(a.sql_hash_value, 0, prev_hash_value, sql_hash_value) =
b.hash_value
and a.sid = &sid
order by piece;
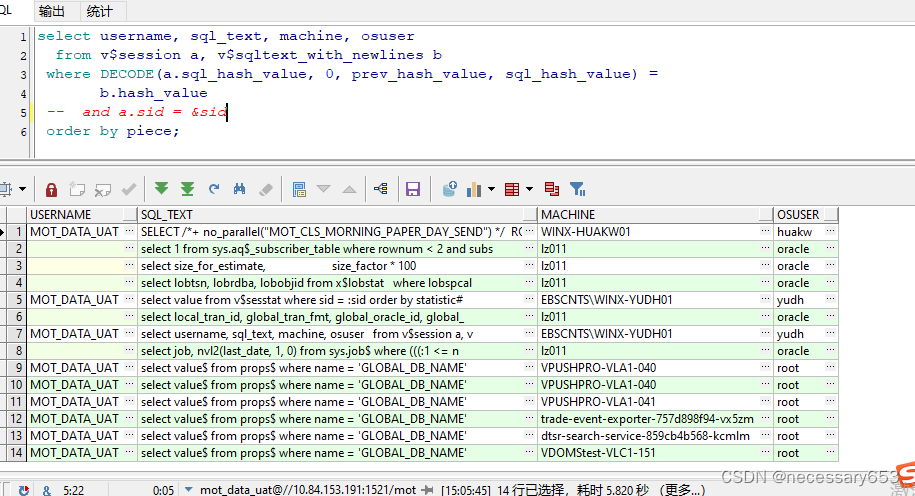
查询从Oracle数据库的v$session 和v$sqltext_with_newlines两个动态性能视图中提取信息。v$session视图提供了关于当前活动会话的信息,包括会话ID(SID)、用户名等;而VSQLTEXT_WITH_NEWLINES视图则提供了一个SQL文本(含换行符)及其哈希值的信息。
以下是每个字段的具体解释:
username: V$SESSION视图中的字段,代表当前用户的用户名。
sql_text: V$SQLTEXT_WITH_NEWLINES视图中的字段,代表SQL语句及其参数值。
machine: V$SESSION视图中的字段,代表连接的客户端机器名称。
osuser: V$SESSION视图中的字段,代表操作系统用户。
prev_hash_value, sql_hash_value: 分别代表V$SESSION视图中上一次执行的SQL语句的哈希值和当前正在执行的SQL语句的哈希值。
b.hash_value: V$SQLTEXT_WITH_NEWLINES视图中的字段,代表SQL语句的哈希值。
and a.sid = &sid: WHERE子句中的条件,代表查询指定会话的SID。
order by piece: ORDER BY子句用于按照SQL文本片段进行排序,以便更好地查看SQL语句的不同部分。
6、根据spid查询具体的sql语句
select ss.SID,
pr.SPID,
ss.action,
sa.SQL_FULLTEXT,
ss.TERMINAL,
ss.PROGRAM,
ss.SERIAL#,
ss.USERNAME,
ss.STATUS,
ss.OSUSER,
ss.last_call_et
from v$process pr, v$session ss, v$sqlarea sa
where ss.status = 'ACTIVE'
and ss.username is not null
and pr.ADDR = ss.PADDR
and ss.SQL_ADDRESS = sa.ADDRESS
and ss.SQL_HASH_VALUE = sa.HASH_VALUE
and pr.spid = XX
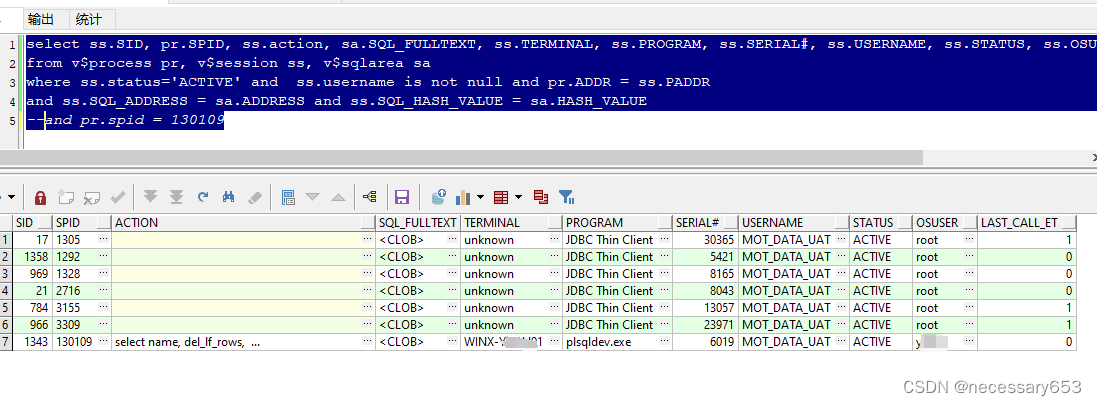
这个查询从Oracle数据库的v$process,v$session和v$sqlarea三个视图中提取信息。V$PROCESS提供了关于操作系统进程的信息,v$session提供了关于活动会话的信息,而V$SQLAREA则提供了关于SQL地址和哈希值的相关信息。
下面是各字段的详细解析:
ss.SID: V$SESSION视图中的字段,代表当前活动会话ID。
pr.SPID: V$PROCESS视图中的字段,代表操作系统进程ID。
ss.action: V$SESSION视图中的字段,代表当前会话的动作,如“SELECT”、“INSERT”等。
sa.SQL_FULLTEXT: V$SQLAREA视图中的字段,提供了SQL语句及其参数值的完整文本。
ss.TERMINAL: V$SESSION视图中的字段,代表终端类型,如“VTY”、“TELNET”等。
ss.PROGRAM: V$SESSION视图中的字段,代表应用程序的名称,如“TOAD”、“PL/SQL Developer”等。
ss.SERIAL#: V$SESSION视图中的字段,代表会话序列号。
ss.USERNAME: V$SESSION视图中的字段,代表当前用户。
ss.STATUS: V$SESSION视图中的字段,代表会话的状态,如“ACTIVE”、“INACTIVE”等。
ss.OSUSER: V$SESSION视图中的字段,代表操作系统用户。
ss.last_call_et: V$SESSION视图中的字段,代表上次调用的时间(毫秒)。
pr.ADDR = ss.PADDR: 这个条件用于关联v$process,v$session两个视图,使我们可以在同一查询中获得操作系统进程和会话的信息。
ss.SQL_ADDRESS = sa.ADDRESS and ss.SQL_HASH_VALUE = sa.HASH_VALUE: 这两个条件用于关联v$session和v$sqlarea两个视图,使我们可以在同一查询中获得SQL语句及其地址和哈希值的信息。
and pr.spid = XX: 这个条件用于查找特定的OS进程ID。
这个查询主要用于查找特定操作系统的进程在当前活动会话中的详细信息,包括会话ID、动作、SQL语句及参数值、终端类型、程序名称、序列号、用户名称、状态、操作系统用户以及上次调用的时间等。
7、查看历史session_id的SQL来自哪个IP
当然这是个误解,都是历史的了,怎么可能还查到spid,其实查看trace文件名就可以知道spid,trace文件里面有sid和具体sql,如果trace存在incident,那trace就看不到具体sql,但是可以在incident文件中看到具体的sql,如DW_ora_17751.trc中17751就是spid,里面有这样的内容Incident 115 created, dump file: /XX/incident/incdir_115/DW_ora_17751_i115.trc,那么在DW_ora_17751_i115.trc就可以看到具体的sql语句)
DB_ora_29349.trc中出现如下
*** SESSION ID:(5057.12807) 2016-10-26 14:45:52.726
通过表V$ACTIVE_SESSION_HISTORY来查,如下
select a.sql_id,a.machine,a.* from V$ACTIVE_SESSION_HISTORY a where a.session_id=5057 and a.SESSION_SERIAL#=12807
查询上面的machine的IP是多少
select s.sid,s.serial#,s.LOGON_TIME,s.machine,p.spid,p.terminal from v$session s,v$process p where s.paddr=p.addr and s.machine='localhost'
通过上面的spid在oracle服务器上执行netstat -anp |grep spid即可
[oracle@dwdb trace]$ netstat -anp |grep 17630
tcp 210 0 192.168.64.228:11095 192.168.21.16:1521 ESTABLISHED 17630/oracleDB
tcp 0 0 ::ffff:192.168.64.228:1521 ::ffff:192.168.64.220:59848 ESTABLISHED 17630/oracleDB出现两个,说明来自220,连接了228数据库服务器,但是又通过228服务器的dblink去连接了16服务器
8、查询DML死锁会话sid,及引起死锁的堵塞者会话blocking_session
select sid,
blocking_session,
LOGON_TIME,
sql_id,
status,
event,
seconds_in_wait,
state,
BLOCKING_SESSION_STATUS
from v$session
where event like 'enq%'
and state = 'WAITING'
and BLOCKING_SESSION_STATUS = 'VALID'
在Oracle数据库中,这个查询从v$session视图中检索信息,v$session视图提供了当前活动会话的相关信息。
下面是各字段的详细解析:
sid: 代表当前会话ID。
blocking_session: 代表阻塞该会话的其他会话ID。
LOGON_TIME: 代表当前会话的登录时间。
sql_id: 代表当前会话正在执行的SQL ID。
status: 代表当前会话的状态,如“ACTIVE”、“INACTIVE”等。
event: 代表等待事件,如“enqueue”、“latch free”等。
seconds_in_wait: 代表当前会话等待的时间(以秒为单位)。
state: 代表当前会话的执行状态,如“WAITING”、“RUNNING”等。
BLOCKING_SESSION_STATUS: 代表阻塞会话的状态,如“VALID”、“INVALID”等。
event like 'enq%': 这个条件用于筛选出等待队列事件中含有“enq”的会话,表明这些会话正在等待资源。
and state='WAITING': 这个条件用于筛选出正在等待状态的会话。
and BLOCKING_SESSION_STATUS='VALID': 这个条件用于筛选出有效的阻塞会话。
可以在v$session.LOGON_TIME上看到引起死锁的堵塞者会话比等待者要早
如果遇到RAC环境,一定要用gv$来查,并且执行alter system kill session 'sid,serial#'要到RAC对应的实例上去执行
或如下也可以
select
(select username from v$session where sid=a.sid) blocker,
a.sid,
a.id1,
a.id2,
' is blocking ' "IS BLOCKING",
(select username from v$session where sid=b.sid) blockee,
b.sid
from v$lock a, v$lock b
where a.block = 1
and b.request > 0
and a.id1 = b.id1
and a.id2 = b.id2; 查询从v$lock视图中检索信息,v$lock视图提供了关于Oracle数据库锁的信息。该查询找出正在阻塞其他会话的会话,以及被阻塞的会话。
以下是各字段的详细解析:
(select username from v$session where sid=a.sid) blocker: 从中提取阻塞会话的用户名。
a.sid: 当前锁定会话ID。
a.id1: 锁定对象的第一部分标识符。
a.id2: 锁定对象的第二部分标识符。
`'is blocking ': 标识出阻塞者和被阻塞者的关系。
(select username from v$session where sid=b.sid) blockee: 从中提取被阻塞会话的用户名。
b.sid: 被阻塞会话ID。
where a.block = 1: 选出具有排他锁定模式的锁(即独占锁定)。
and b.request > 0: 选出请求解锁但尚未获取锁的会话(被阻塞的会话)。
and a.id1 = b.id1 and a.id2 = b.id2: 对应匹配的锁定对象。
9、查询DDL锁的sql
SELECT sid, event, p1raw, seconds_in_wait, wait_time
FROM sys.v_$session_wait
WHERE event like 'library cache %'
p1raw结果为'0000000453992440'
sid: 代表当前会话ID。
event: 当前会话正在等待的事件类型,如“library cache lock”、“library cache pin”等。
p1raw: 关于事件的详细信息,比如对象编号、表名等。
seconds_in_wait: 当前会话已经等待的时间(以秒为单位)。
wait_time: 当前会话等待的累计时间(以微秒为单位)。
WHERE event like 'library cache %': 这个条件用于筛选出事件名称中包含"library cache"的会话。
SELECT s.sid, kglpnmod "Mode", kglpnreq "Req", s.LOGON_TIME
FROM x$kglpn p, v$session s
WHERE p.kglpnuse=s.saddr
AND kglpnhdl='0000000453992440';
s.sid: 查询会话ID。
kglpnmod: x$kglpn视图中的字段,代表库缓存锁模式,例如“Row-X”,“Table-S”等。
kglpnreq: x$kglpn视图中的字段,表示是否持有锁。
s.LOGON_TIME: v$session视图中的字段,代表当前会话的登录时间。
p.kglpnuse=s.saddr: 这个条件用于关联x$kglpn和v$session视图,使得我们可以同时查看锁信息和会话信息。
AND kglpnhdl='0000000453992440': 这个条件用于筛选出指定对象的锁信息。
10、查询锁住的DDL对象
select d.session_id, s.SERIAL#, d.name
from dba_ddl_locks d, v$session s
where d.owner = 'MKLMIGEM'
and d.SESSION_ID = s.sid
旨在从Oracle数据库的两个数据字典视图中检索信息:dba_ddl_locks 和 v$session。
这段代码:
select d.session_id, s.SERIAL#, d.name: 这一行指定了查询结果应包含的列。其中 d.session_id 是从 dba_ddl_locks 视图选择的会话ID,s.SERIAL# 是从 v$session 视图选择的序列号,d.name 是从 dba_ddl_locks 视图选择的名称。
from dba_ddl_locks d, v$session s: 这里列出了查询将使用两个数据字典视图,一个是 dba_ddl_locks,用别名 d 表示,另一个是 v$session,用别名 s 表示。
where d.owner = 'MKLMIGEM': 这一行是一个过滤条件,它限制了查询结果只包括那些 dba_ddl_locks 视图中 owner 列的值为 'MKLMIGEM' 的行。这可能意味着你只对属于某个特定用户(即 'MKLMIGEM')的DDL锁感兴趣。
and d.SESSION_ID = s.sid: 这是另一个过滤条件,它进一步限制了查询结果只包括那些在 dba_ddl_locks 视图中 SESSION_ID 列的值与在 v$session 视图中 sid 列的值相匹配的行。这可能是为了确保你检索的会话ID是匹配和一致的。
11、查询当前正在执行的sql
SELECT s.sid,
s.serial#,
s.username,
spid,
v$sql.sql_id,
machine,
s.terminal,
s.program,
sql_text
FROM v$process, v$session s, v$sql
WHERE addr = paddr
and s.sql_id = v$sql.sql_id
AND sql_hash_value = hash_value
v$session(别名为s)
选择会话ID (sid)、
序列号 (serial#)、
用户名 (username)、
v$sql(别名为v$sql)选择SQL ID (sql_id)。
spid(可能表示进程ID)、
machine(表示机器名)、
terminal(表示终端名)、
program(表示程序名),
sql_text(表示SQL语句文本)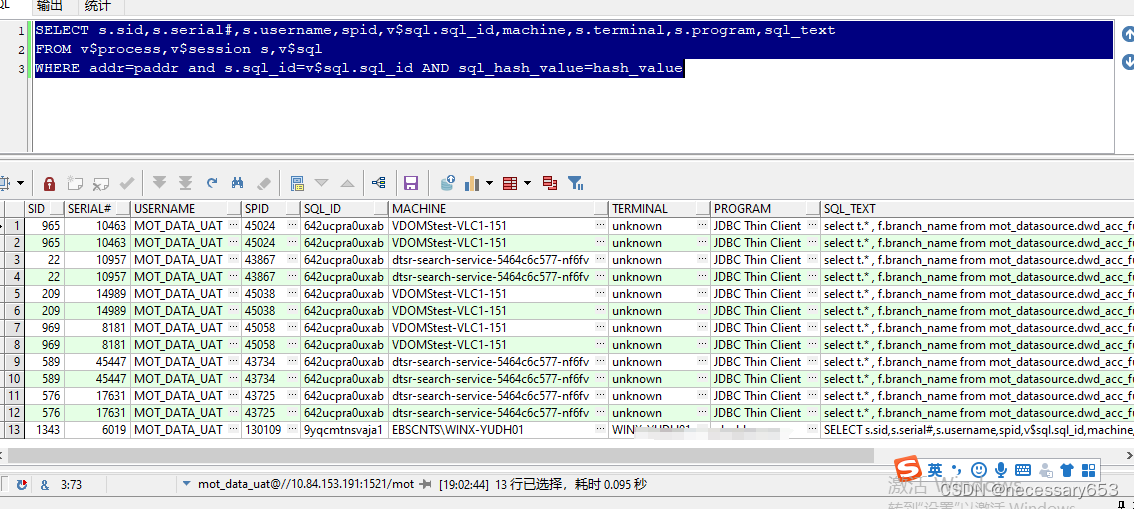
12、查询正在执行的SCHEDULER_JOB
select owner, job_name, sid, b.SERIAL#, b.username, spid
from ALL_SCHEDULER_RUNNING_JOBS, v$session b, v$process
where session_id = sid
and paddr = addr
查询是从Oracle数据库的几个数据字典视图中检索信息。我将逐行解释代码的含义,并给出字段的描述:
select owner, job_name, sid, b.SERIAL#, b.username, spid: 这一行指定了查询结果应包含的列。owner调度作业的所有者,
job_name是作业的名称,
sid是Oracle会话的标识符,
SERIAL#是Oracle会话的序列号,
username是Oracle会话的用户名,
spid可能是进程ID。
v$session b: 这里使用v$session视图,并给它指定了别名b。v$session视图包含关于数据库会话的信息。
,v$process: 这个视图包含关于数据库中进程的信息。
where session_id = sid: 这是一个过滤条件,它将查询结果限制为那些session_id列的值等于sid列的值的行。
and paddr = addr: 这是另一个过滤条件,它将查询结果限制为那些paddr列的值等于addr列的值的行。
13、查询正在执行的dbms_job
select job, b.sid, b.SERIAL#, b.username, spid
from DBA_JOBS_RUNNING a, v$session b, v$process
where a.sid = b.sid
and paddr = addr
指定了查询结果应包含的列。
它选择了job列(指作业名称),
b.sid(Oracle会话的标识符),
b.SERIAL#(Oracle会话的序列号),
b.username(Oracle会话的用户名),
和spid(进程ID)。
14、查询一个会话session、process平均消耗多少内存,查看下面avg_used_M值
select round(sum(pga_used_mem) / 1024 / 1024, 0) total_used_M,
round(sum(pga_used_mem) / count(1) / 1024 / 1024, 0) avg_used_M,
round(sum(pga_alloc_mem) / 1024 / 1024, 0) total_alloc_M,
round(sum(pga_alloc_mem) / count(1) / 1024 / 1024, 0) avg_alloc_M
from v$process;
select round(sum(pga_used_mem) / 1024 / 1024, 0) total_used_M,
这行代码计算了已使用的内存总量(以MB为单位)。pga_used_mem是每个进程已使用的PGA(Program Global Area)内存量,1024 * 1024是将这个量从字节转换为MB的转换因子。round(sum(pga_used_mem) / 1024 / 1024, 0)表示对总和进行四舍五入,保留小数点后0位。total_used_M是结果列的别名,表示已使用的内存总量(以MB为单位)。
round(sum(pga_used_mem) / count(1) / 1024 / 1024, 0) avg_used_M,
这行代码计算了每个进程平均使用的内存量(以MB为单位)。count(1)计算了进程的总数。所以,这行代码首先计算所有进程已使用的内存总量,然后除以进程总数,得到每个进程的平均使用量。avg_used_M是结果列的别名,表示每个进程平均使用的内存量(以MB为单位)。
round(sum(pga_alloc_mem) / 1024 / 1024, 0) total_alloc_M,
这行代码计算了已分配的内存总量(以MB为单位)。pga_alloc_mem是每个进程已分配的PGA内存量,同样,1024 * 1024是将这个量从字节转换为MB的转换因子。total_alloc_M是结果列的别名,表示已分配的内存总量(以MB为单位)。
round(sum(pga_alloc_mem) / count(1) / 1024 / 1024, 0) avg_alloc_M,
这行代码计算了每个进程平均分配的内存量(以MB为单位)。与第二行类似,它首先计算所有进程已分配的内存总量,然后除以进程总数,得到每个进程的平均分配量。avg_alloc_M是结果列的别名,表示每个进程平均分配的内存量(以MB为单位)。
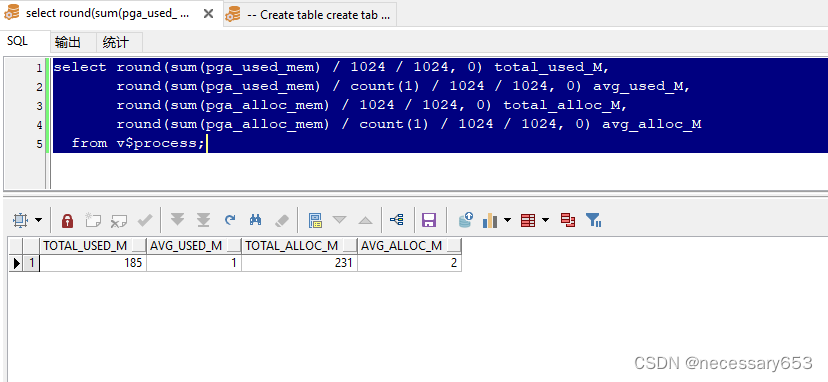
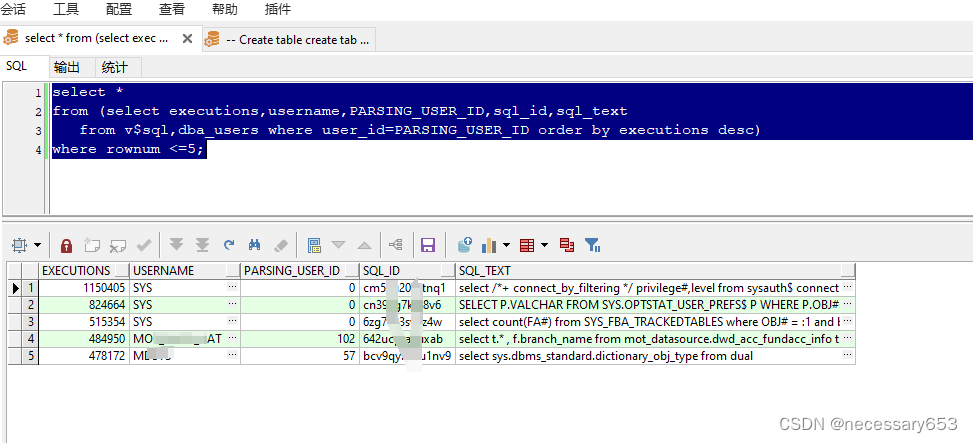
15、TOP 10 执行次数排序
select *
from (select executions, username, PARSING_USER_ID, sql_id, sql_text
from v$sql, dba_users
where user_id = PARSING_USER_ID
order by executions desc)
where rownum <= 5;
执行次数(executions)、
用户名(username)、
解析用户ID(PARSING_USER_ID)、
SQL ID(sql_id)
SQL文本(sql_text)。
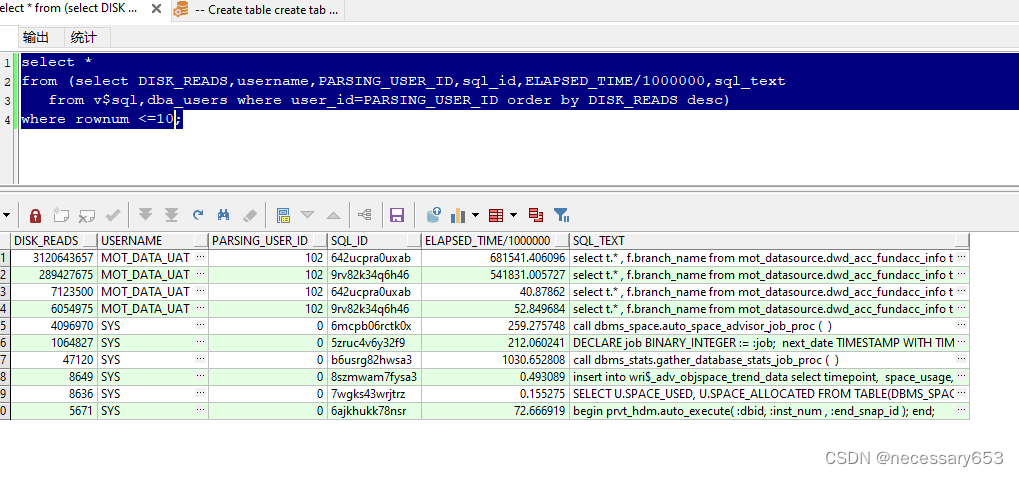
16、TOP 10 物理读排序
select *
from (select DISK_READS,
username,
PARSING_USER_ID,
sql_id,
ELAPSED_TIME / 1000000,
sql_text
from v$sql, dba_users
where user_id = PARSING_USER_ID
order by DISK_READS desc)
where rownum <= 10;
(不要使用DISK_READS/ EXECUTIONS来排序,因为任何一条语句不管执行几次都会耗逻辑读和cpu,可能不会耗物理读(遇到LRU还会耗物理读,LRU规则是执行最不频繁的且最后一次执行时间距离现在最久远的就会被交互出buffer cache),是因为buffer cache存放的是数据块,去数据块里找行一定会消耗cpu和逻辑读的。Shared pool执行存放sql的解析结果,sql执行的时候只是去share pool中找hash value,如果有匹配的就是软解析。所以物理读逻辑读是在buffer cache中,软解析硬解析是在shared pool)
磁盘读取次数(DISK_READS)、
用户名(username)、
解析用户ID(PARSING_USER_ID)、
SQL ID(sql_id)
SQL文本(sql_text)。
关注博主后续继续更新
















 3278
3278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









