







1、使用场景:
1.1 情景说明
使用pandas对单个excel工作簿进行指定列拆分并按部门名称另存为多个工作簿(保留工作簿1、2行数据),并将第2行的“组织机构”作为指定列拆分。但“组织机构”存在3级、4级机构的情况,为避免无效的数据拆分这边需对“组织机构”进行部门数据提取,相关说明如下
这边的“组织机构”部门数据提取说明如下:

1.2 模拟数据示例+拆分效果展示

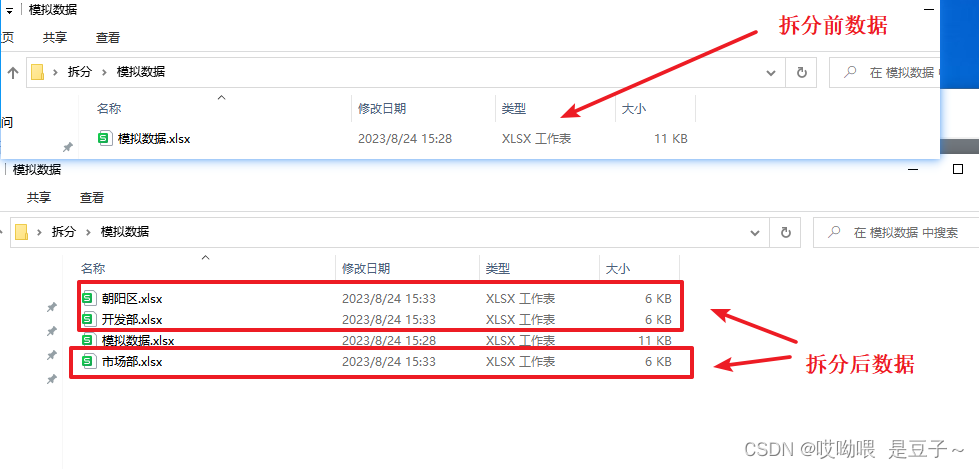

2、解决思路+情景在线+源代码:
演示表格使用的指定列名“组织机构”进行拆分,思路如下:
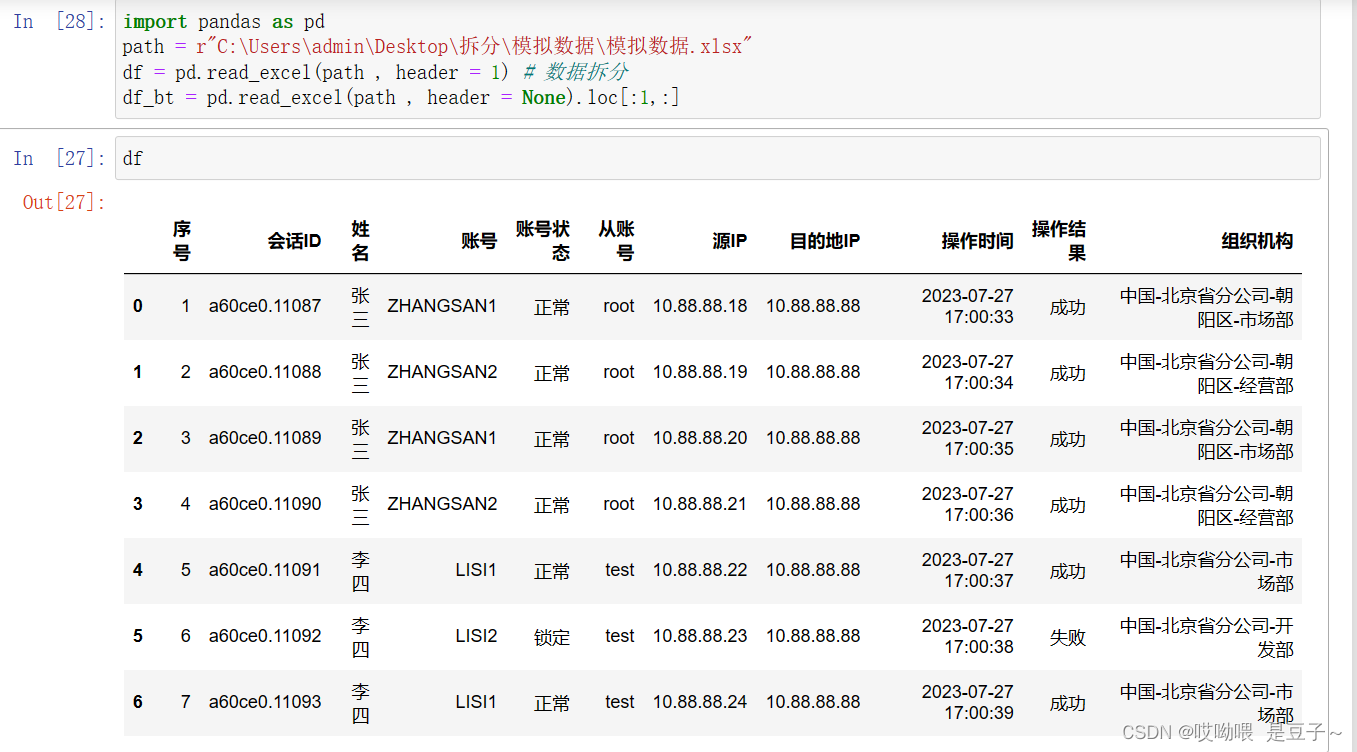
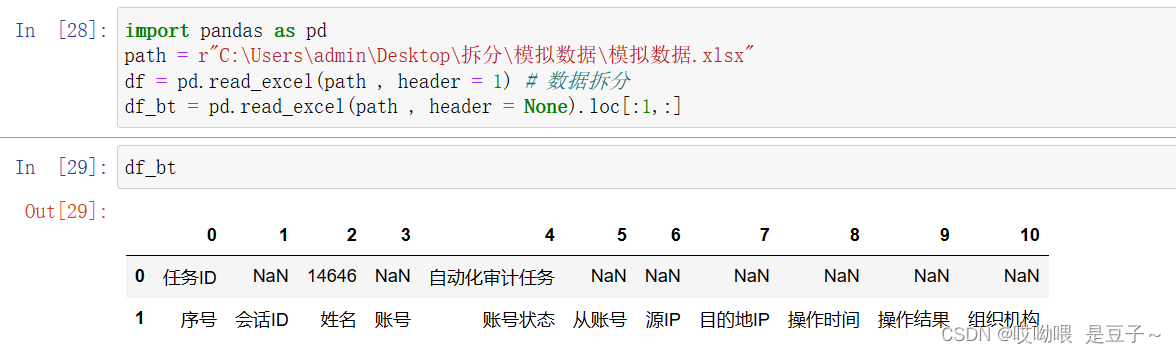
1、为保留工作簿1、2行的表头数据,对同一数据源读取2次:
1)df:读取跳过第1行的全部数据
2)df_bt:读取第1、2行的表头数据
import pandas as pd
path = r"C:\Users\admin\Desktop\拆分\模拟数据\模拟数据.xlsx"
df = pd.read_excel(path , header = 1) # 数据拆分
df_bt = pd.read_excel(path , header = None).loc[:1,:]结果展示:
2、提取根据“组织机构”列提取部门数据
df['部门'] = df['组织机构'].apply(lambda x:x.split('-')[2])结果展示:
3、根据“部门”列进行分组拆分 + 数据拼接+指定部门名称为文件名并另存为
df_split = df.groupby('部门')
for i,j in df_split:
j = j.loc[:,:'组织机构']
j = j.set_axis(list(range(len(j.columns))), axis=1)
j = pd.concat([df_bt,j],ignore_index = True)
new_file_path = 'C:\\Users\\admin\\Desktop\\拆分\\模拟数据\\' + i + '.xlsx'
j.to_excel(new_file_path,sheet_name = i,index=False , header = None)源代码:
import pandas as pd
path = input("请输入要拆分的文件路径,例如:C:\\Users\\admin\\Desktop\\拆分\\模拟数据.xlsx\n请输入:")
df = pd.read_excel(path , header = 1) # 数据拆分
df_bt = pd.read_excel(path , header = None).loc[:1,:]
df['部门'] = df['组织机构'].apply(lambda x:x.split('-')[2])
df_split = df.groupby('部门')
lujing = input("请输入文件拆分后存储路径,例如:C:\\Users\\admin\\Desktop\\拆分\\\n请输入:")
for i,j in df_split:
j = j.loc[:,:'组织机构']
j = j.set_axis(list(range(len(j.columns))), axis=1)
j = pd.concat([df_bt,j],ignore_index = True)
new_file_path = lujing + i + '.xlsx'
j.to_excel(new_file_path,sheet_name = i,index=False , header = None)














 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









