







序言
现代编程很大程度上依赖于集成开发环境(IDEs),这些环境提供了一个优雅的界面,允许开发者编写、测试和调试代码,而无需深入了解底层的编译和链接细节。在 IDE 中,我们输入的代码最初以文本文件的形式存在,随后 IDE 会负责将文本转换成计算机可以理解和执行的指令。
尽管大多数开发者不需要直接处理编译链接过程,但对这一过程的理解能够极大地提升解决问题的能力。当你对程序的构建过程有了更深入的认识时,即使是编译器或链接器产生的错误信息,也能成为你排查问题的有力工具。这种理解能够让你在遇到问题时,更加迅速地定位并解决问题,从而提高编程效率和项目质量。
因此,虽然 IDE 为我们屏蔽了复杂的构建过程,但偶尔抬头看看背后的原理,不仅能够加深我们对编程语言和工具的理解,还能够让我们成为更加出色的开发者。
1. 环境
本文章的程序在 Linux 环境下进行演示。在该环境下可以更方便展示编译和链接过程中的细节。
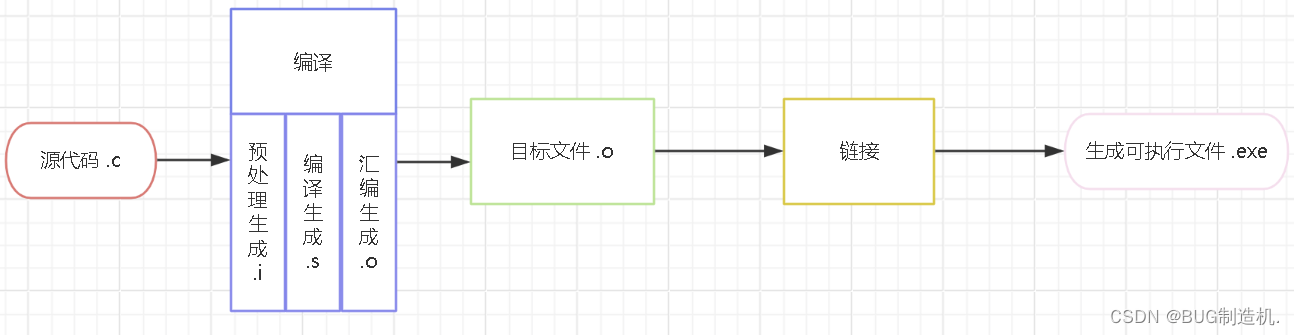
2. 大体流程图
编译器首先将我们写的 .c 程序经过 编译 后生成 .o 目标程序,最后通过 链接 转化为 .exe 可执行程序:
3. 编译
概念
编译(Compile)将我们认识的高级语言的代码比如 C,转化为机器所能认识的机器语言。所以,编译也可理解为翻译的过程。
3.1 预编译(预处理)
我们通过代码来发现预编译后源代码和处理后的代码的区别,我们编写了一个 Add.h 和 Test.c 的程序:
Add.h :
// Add.h
int Add(int left, int right){
return left + right;
}
Test.c:
// Test.c
#include <stdio.h>
#include"Add.h"
#define A 1
#define B 2
// 这是一个小小的程序
int main(){
int num = Add(A, B);
printf("num = %d\n", num);
return 0;
}
通过输入指令 gcc -E Test.c -o Test.i 将 Test.c 只是进行预编译,并将编译结果保存在 Test.i 文件中。现在打开 Test.i 查看里面的内容:
.............................................................
# 913 "/usr/include/stdio.h" 3 4
extern void flockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
extern int ftrylockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)) ;
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 943 "/usr/include/stdio.h" 3 4
# 2 "Test.c" 2
# 1 "Add.h" 1
int Add(int left, int right){
return left + right;
}
# 3 "Test.c" 2
int main(){
int num = Add(1, 2);
printf("num = %d\n", num);
return 0;
}
因为实在是太长了,所以上面很多内容被我使用省略号省略了。我们仔细观察下,发现以下问题:
- 原来的
#include <stdio.h>不见了,取而代之的是一大段代码 - 原来
#inlcude "Add.h"的地方被替换为Add.h的定义 - 我们
define的定义不见了,代码中包含A,B的地方被替换为了具体的数据 - 我们的注释不见了
所以不难得到,在预编译阶段,编译器主要是完成了以下几点工作:
- 预处理指令:预编译器会识别并处理源代码中的预处理指令,如包含(
#include)指令,它会在源代码编译之前将其他文件的内容插入到当前文件中(比如:标准输入输出的函数声明和宏定义); - 宏处理:预编译器会展开宏定义(如宏函数),这个过程称为宏替换;
- 删除注释。注释是给人看的,编译器不需要;
3.2 编译
通过输入指令 gcc -S Test.i -o Test.s 将 Test.i 只是进行编译,并将编译结果保存在 Test.s 文件中,老规矩继续看看发生了啥:
.................................... // 省略了内容
main:
.LFB1:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $2, %esi
movl $1, %edi
call Add
movl %eax, -4(%rbp)
movl -4(%rbp), %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE1:
.size main, .-main
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-44)"
.section .note.GNU-stack,"",@progbits
在这里我们只是看到将 C 转化为了 汇编语言,其实在转化之前,还有很多其他重要复杂的操作:
- 词法分析(Lexical Analysis):编译器会将源代码分解为词法单元,也称为令牌。词法单元是源代码中的基本元素,如关键字、标识符、运算符和分隔符等。
- 语法分析(Syntax Analysis):在这个阶段,编译器会根据编程语言的语法规则检查词法单元之间的组合方式是否符合语法规范。这个过程产生的结果通常是一个语法树或抽象语法树
- 语义分析(Semantic Analysis):编译器会进一步分析语法树,确保程序中的语义是合法的。这个阶段包括类型检查、作用域分析以及其他与语义相关的检查。
- 中间代码生成(Intermediate Code Generation):一些编译器会在此阶段生成中间表示形式,这是一种高级抽象的表示形式,用于进一步优化或转换。中间表示形式可以是三地址码、静态单赋值形式等。
以上四点我们不做深入的探讨(作者还没有进行深入的学习,等以后有能力了在更),但我们要牢牢记住这个步骤 — 符号汇总!这个步骤是干嘛的呢?这一步就是 将你的程序中出现的符号所汇总起来,供下一步汇编时形成符号表。啊!那符号表又是干嘛的呢?客官不慌,且听我徐徐道来。:)
3.3 汇编
汇编过程是将汇编语言转化为机器可以识别的机器语言,可使用指令 gcc -c Test.s -o Test.o 生成并查看:
^@^@^@^@^@^@^@^@<89>^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@1^@^@^@^A^@^@^@^B^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@<89>^@^@^@^@^@^@^@
5 ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@9^@^@^@^A^@^@^@0^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@<93>^@^@^@^@^@^@^@.^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@B^@^@^@^A^@^@^@^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@Á^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^A^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@W^@^@^@^A^@^@^@^B^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@È^@^@^@^@^@^@^@X^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^H^@ ^@^@^@^@^@^@^@^@^@^@^@^@^@^@R^@^@^@^D^@^@^@@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@ ^B^@^@^@^@^@^@0^@^@^@^@^@^@^@
6 ^@^@^@^H^@^@^@^H^@^@^@^@^@
因为是机器语言,全是给机器看的二进制,所以这里就展现出来都是乱码。
除了将汇编语言转化为机器语言之外,还进行了 将上一个过程汇总的符号形成符号表。
什么是符号表?有什么用?
我举个例子为大家说明:这里有三个文件声明文件,定义文件,以及调用的文件:
Print.h:
#pragma once
#include <iostream>
using namespace std;
void Print();
Print.cpp:
#include "Print.h"
void Print() {
std::cout << "Hello, World!" << std::endl;
}
Main.cpp:
#include "Print.h"
int main() {
Print();
return 0;
}
我们从头捋一遍哈:
- 首先编译器预处理会 展开头文件 所以,
Print.h文件就在预编译阶段被展开了,完成了他的工作. - 在编译时,会汇集所有出现的符号包括全局变量名,函数名
- 在汇编阶段,会生成符号表。这些符号表里面保存的就是目标文件里面函数以及变量的地址(这里以函数为例):
Print.cpp的符号表(简化)为:
| 名称 | 地址 |
|---|---|
| 0xffgghh23 |
而Main.cpp 的符号表为:
| 名称 | 地址 |
|---|---|
| 0x00000000 |
为什么前者是一个有效的地址,后者不是呢?因为在 Print.cpp 文件里有该函数的定义呀,而在 Main.cpp 文件里只有该函数的声明没有定义。你一个没有定义的函数我怎么会给你分配空间呢?
那我函数的地址都不是一个有效的地址,我怎么可以正常的调用呢?在链接时,又会再次处理符号表,合并为一个。
好了,回答我们上面的问题:
- 什么是符号表:符号表主要存储目标文件中引用的和定义的全局变量以及函数的信息
- 符号表有什么用:通过符号表,编译器和链接器能够追踪和管理源程序中定义和引用的标识符,从而确保程序的正确运行
以小见大!编译和链接的过程可谓一环套一环!
4. 链接
概念
在编译链接的过程中,链接(Linking)是一个关键阶段,它的主要作用是将程序运行所需要的各个部分组合在一起,形成一个可执行文件。在进入正题之前,我们先简单了解 动态链接 和 静态链接。
4.1 静态链接
概念
静态链接是指在链接阶段,链接器将目标文件与静态库(如.a文件)中的内容合并到最终的可执行文件中。
优缺点
- 由于静态链接将库的内容直接复制到可执行文件中,因此生成的可执行文件通常较大
- 静态链接生成的可执行文件在运行时不需要额外加载库文件,但会占用较多的内存空间
- 静态链接在编译时完成,因此运行时性能较高,没有额外的加载时间
4.2 动态链接
概念
动态链接是指在程序运行时,由操作系统的装载程序负责加载所需的动态链接库。
优缺点
- 文件大小:动态链接生成的可执行文件较小,因为它不包含库文件的实际内容。
- 内存占用:动态链接在运行时加载库文件,因此可以减少内存占用(因为多个程序可以共享同一个库文件的内存映像)。
- 性能:动态链接在运行时加载库文件,因此会有一定的加载时间开销。但是,由于现代操作系统的缓存机制,这种开销通常可以忽略不计。
4.3 链接方式总结
大家可以简单理解为,静态链接就是将需要的资源每个人都拷贝一份,动态链接就是大家共用一份。前者缺点很明显大家都调用时会造成内存空间的浪费,后者的缺点也不小,一出错大家都出错。
4.4 链接 — 最后一步
我们最后生成的可执行文件最后只有一个。链接解决的是一个项目多文件,多模块相互之间调用的问题,将这些模块之间和文件之间连接起来。
之间最重要的一个点就是,将符号表合并。就比如 Print.cpp 和 Main.cpp ,两者都有一个单独的符号表。
- 对于不同名的符号直接加入新的符号表;
- 对于同名的符合会加入地址有效的那一个;
- 如果同名的符号两个地址都有效,那么就会报错:重定义。
5. 总结
所以说一个很简单的程序,背后的事却不少。简单理解编译链接,还是很有必要的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









