






引言
最近我打算做一个AI+文旅赛道的应用去参加比赛,但是这其中很独特的一点就是需要用到视觉RAG,这样才能够给作品提供更好的使用体验。这篇文章我就用最通俗易懂的语言以及代码示例来讲解我搜集到几种最有名的视觉RAG解决方案。
“视觉 RAG” (Visual Retrieval-Augmented Generation),一种结合了视觉检索和文本生成的新兴技术,它将彻底改变我们与 AI 的互动方式,特别是对于我最近想做的AI文旅赛道来说,更是不可或缺。
什么是 RAG?
在深入探讨视觉 RAG 之前,我们先来回顾一下 RAG 的基本概念。RAG,即检索增强生成,顾名思义,就是在生成文本内容时,先进行信息检索,然后将检索到的相关信息作为上下文,输入给大语言模型(LLM),从而生成更准确、更丰富的答案。
简单来说,就像我们写论文时,先查阅大量资料,然后再组织成自己的观点一样。RAG 就是让 AI 也学会这个过程,而不是“凭空捏造”。
视觉 RAG:让 AI “看到” 世界
如果说 RAG 是为 AI 提供了 “参考书”,那么视觉 RAG 就是让 AI “看到” 世界。它将信息检索的范围从文本扩展到图像、视频等视觉信息,让 AI 在生成内容时,不仅能参考文本,还能“看到”相关的图像,从而更好地理解用户的意图,生成更生动、更贴近用户需求的内容。
举个例子:
- 传统 RAG: 用户输入“马尔代夫的豪华酒店”,AI 可能只能返回一些文字描述的酒店信息,比如价格、设施等。
- 视觉 RAG: 用户输入“马尔代夫的豪华酒店”,AI 可以检索出马尔代夫豪华酒店的图片,如海景房、无边泳池等,并结合文字描述,生成更具吸引力的推荐信息。
视觉 RAG 如何改变文旅应用的体验?
- 更直观的信息呈现: 用户在旅游时,往往会通过图片来了解目的地,比如景点风貌、酒店环境、美食特色等。视觉 RAG 可以帮助用户更直观地获取这些信息。例如,用户可以上传一张不知名景点的照片,AI 可以识别并提供相关信息,包括历史文化、周边景点等。
- 更精准的语义理解: 比如用户想查找“有泳池的海景酒店”,单靠文本描述可能不够准确,但如果能结合图片检索,就能更精确地找到符合要求的酒店。用户甚至可以直接上传一张“想要的泳池”照片,让 AI 搜索类似的酒店。
- 更丰富的游记生成: 基于用户提供的图片或视频,视觉 RAG 可以帮助生成更生动、个性化的游记内容。例如,用户可以上传旅途中拍摄的照片,AI 可以根据照片内容,自动生成游记草稿,大大减轻了游记创作的难度。
- 更个性化的旅行定制: 结合用户的偏好和视觉信息,AI 可以为用户量身定制行程计划,包括景点推荐、美食推荐、住宿推荐等。比如,如果用户经常浏览海滩照片,AI 可以推荐更多海岛游线路。
主流视觉 RAG 方案解析
接下来,我们将深入了解一些主流的视觉 RAG 方案,并用通俗易懂的方式解释它们的原理:
-
CLIP (Contrastive Language-Image Pre-training)

-
原理: CLIP 是 OpenAI 提出的一个强大的多模态模型,它将图像和文本编码到同一个向量空间中。这样,我们可以用文本来查询图像,或者用图像来查询文本。
-
应用:
- 图像检索: 将用户输入的文本描述(如“埃菲尔铁塔”)编码成向量,然后在图像库中找到与之向量相似的图片。
- 图像标注: 根据图片内容,自动生成文本描述。
- 零样本分类: 无需训练,即可将图片分类到不同的类别。
-
代码示例 (Python + PyTorch):
import torch import clip from PIL import Image import requests from io import BytesIO # 加载 CLIP 模型 device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load("ViT-B/32", device=device) # 要检索的文本 text_query = "a delicious burger" # 将文本编码为向量 text_tokens = clip.tokenize([text_query]).to(device) text_features = model.encode_text(text_tokens).float() # 图片 URL 列表 image_urls = [ "https://images.unsplash.com/photo-1568901346375-23c9450c58cd?q=80&w=2070&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D", "https://images.unsplash.com/photo-1555274175-7955d340419a?q=80&w=2069&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D", "https://images.unsplash.com/photo-1622409243894-c8e9f145a906?q=80&w=1887&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D" ] image_features_list = [] for url in image_urls: # 下载图片 response = requests.get(url) image = Image.open(BytesIO(response.content)).convert("RGB") # 预处理图片 image = preprocess(image).unsqueeze(0).to(device) # 将图片编码为向量 image_features = model.encode_image(image).float() image_features_list.append(image_features) # 计算相似度 similarities = [] for image_features in image_features_list: similarity = (text_features @ image_features.T).squeeze() similarities.append(similarity) # 找到最相似的图片 best_match_index = torch.argmax(torch.tensor(similarities)).item() best_match_url = image_urls[best_match_index] print(f"与 '{text_query}' 最相似的图片是: {best_match_url}")
-
-
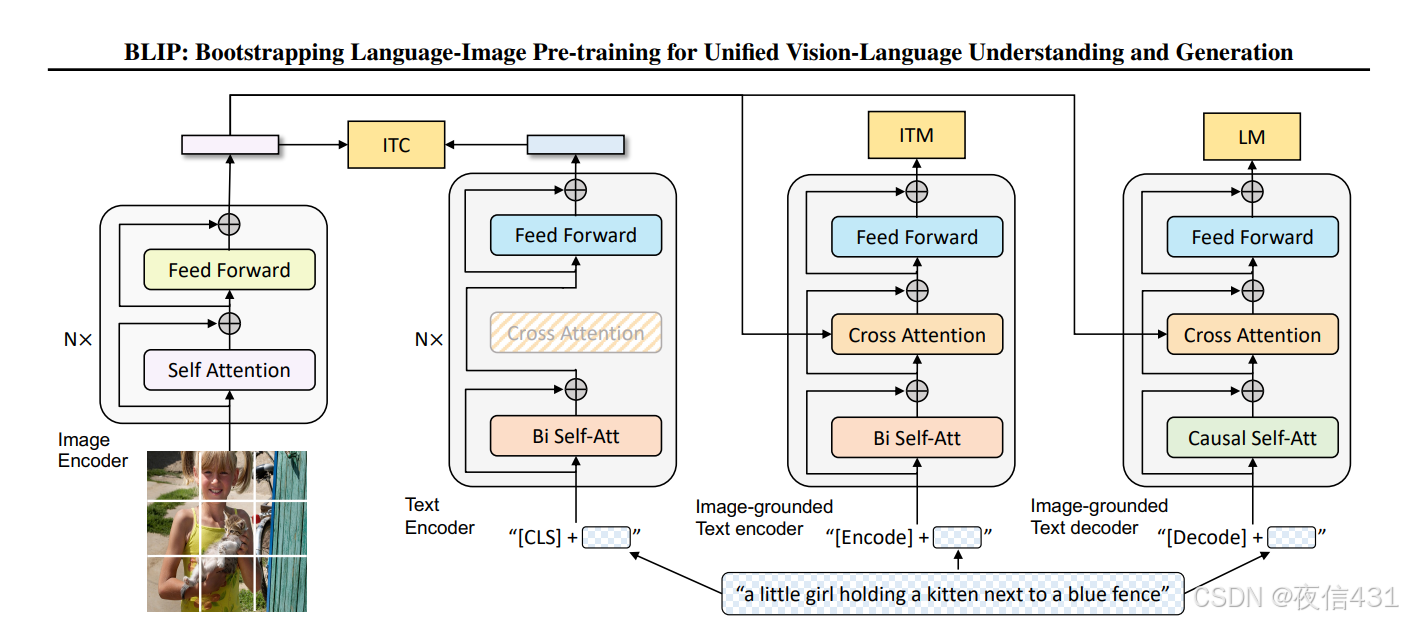
BLIP (Bootstrapping Language-Image Pre-training)
-
原理: BLIP 是一个更先进的多模态模型,它不仅能像 CLIP 一样进行图像文本匹配,还能生成图像的文本描述。
-
应用:
- 图像字幕生成: 为图片自动生成详细的文本描述,帮助 LLM 理解图片内容。
- 视觉问答: 根据图片内容回答用户提出的问题。
- 图像检索和排序: 根据文本查询,检索并排序图像。
-
代码示例 (Python + PyTorch + Transformers):
from PIL import Image import requests from io import BytesIO from transformers import BlipProcessor, BlipForConditionalGeneration # 加载模型和处理器 processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base") model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base") # 图片 URL image_url = "https://images.unsplash.com/photo-1605361780974-5946511a5175?q=80&w=2070&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D" # 下载图片 response = requests.get(image_url) image = Image.open(BytesIO(response.content)).convert("RGB") # 预处理图片 inputs = processor(image, return_tensors="pt") # 生成字幕 output = model.generate(**inputs) caption = processor.decode(output[0], skip_special_tokens=True) print("图片的字幕是:", caption)- 来源:
- 图片来源
- unsplash
|
- unsplash
-
-
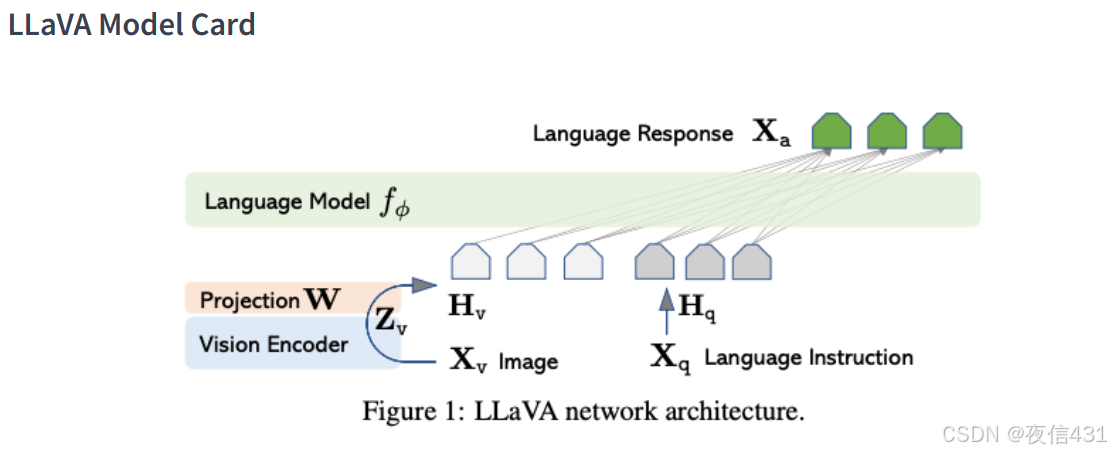
Llava (Large Language and Vision Assistant)
-
原理: LLava 是一个多模态大型语言模型,它将视觉编码器、LLM 和线性投影器结合在一起。可以处理文本和图像输入,并进行各种任务,如多模态对话、视觉问答等。
-
应用:
- 多模态对话: 与用户进行关于图片内容的对话。
- 视觉问答: 根据图片内容回答用户的问题。
- 图像描述和推理: 描述图像内容,并进行推理。
-
代码示例 (Python + PyTorch + Transformers):
from PIL import Image import requests from io import BytesIO from transformers import AutoProcessor, AutoModelForCausalLM import torch # 加载模型和处理器 processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf") model = AutoModelForCausalLM.from_pretrained("llava-hf/llava-1.5-7b-hf") # 图片 URL image_url = "https://images.unsplash.com/photo-1543362947-081e9660889b?q=80&w=2070&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D" # 下载图片 response = requests.get(image_url) image = Image.open(BytesIO(response.content)).convert("RGB") # 用户问题 prompt = "What is this?" # 预处理图片和文本 inputs = processor(text=prompt, images=image, return_tensors='pt').to("cuda" if torch.cuda.is_available() else "cpu") # 生成回答 output = model.generate(**inputs, max_new_tokens=200) response = processor.decode(output[0], skip_special_tokens=True) print("回答:", response)- 来源:
- 图片来源
-
应该你想做这样一款应用,如何将视觉 RAG 应用到旅游应用中?
- 构建高质量的图像数据库: 收集旅游目的地的相关图片,并使用 CLIP 等模型将它们编码成向量,构建图像检索数据库。
- 提供多模态查询方式: 允许用户使用文本、图片或两者的组合进行查询。
- 将视觉检索结果作为 RAG 的上下文: 将检索到的相关图片和文本信息一起输入 LLM,帮助其生成更准确、更丰富的答案。
- 提供个性化的内容生成服务: 根据用户的需求,生成不同的内容,如旅游攻略、游记、行程推荐等。
- 不断优化用户体验: 简化用户操作,提高检索效率,并根据用户反馈进行持续优化。
最后,我想问一问大家:
- 你觉得视觉 RAG 在其他领域还有哪些应用潜力?
- 你对 AI+ 旅游应用有什么期待?
欢迎在评论区留言,一起交流探讨!
结尾
感谢大家阅读本篇博客。希望这篇文章能够帮助您更好地理解视觉 RAG 技术,并激发您对 AI 在旅游领域的更多想象。让我们一起期待,AI 如何用 “视觉” 为我们的旅行带来更多精彩 嘻嘻!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









