






一、项目背景
腾讯云 AI 代码助手是由腾讯云自研的一款开发编程提效辅助工具,开发者可以通过插件的方式将 AI 代码助手安装到编辑器中辅助编程工作(VS Code 或者 JetBrians 系列 IDE);而 AI 代码助手插件将提供:自动补全代码、根据注释生成代码、代码解释、生成测试代码、转换代码语言、技术对话等能力。通过腾讯云 AI 代码助手,开发者可以更高效地解决实际编程问题,提高编程效率和代码质量。
本文将详细介绍我将腾讯云的AI代码助手服务和腾讯云的文字转语音服务相融合,结合前端框架和后端技术,一步一步搭建一个集成语音合成和情感分析的智能聊天机器人,包括我是如何提问的。(本人之前没有系统学习过前端,这个项目90%都是腾讯云AI完成的)
可以通过官网学习安装腾讯云AI代码助手,这里不再赘述:
二、功能特点
这个项目主要是在一个初始项目上进行功能的添加,初始项目运行后可以进行基础的对话功能。在这个智能聊天机器人页面中,我增加了多个实用的功能,如下:
- 💬 优化前端界面:使界面更加合理美观。
- 🎤 文字转语音功能:将聊天内容转化为语音播放,增强互动性。(重点功能)
- 📊 情感分析和可视化:分析用户输入的情感倾向,并以图表形式展示。(重点功能)
- 💾 聊天记录本地存储:记录每一次聊天内容,方便日后查看。
- 📥 聊天记录导出功能:用户可以将聊天记录导出为JSON文件进行保存。
三、名称由来
“情声共鸣”这一名称来源于作品的两个核心功能——文字转语音和情感分析与可视化。在这个名字中,“情”代表了情感分析,体现了AI能够理解和捕捉用户情感的能力;“声”则指代文字转语音功能,强调AI通过声音与用户进行互动。而“共鸣”则是指情感的共鸣和反响,意味着AI不仅能理解用户的情感,还能通过语音与用户产生情感上的共振,使对话更加人性化、贴心。
这个名字充分表达了作品的目标——通过语音和情感分析的结合,打造一个与用户心灵深度连接的智能聊天体验。
四、技术栈
本项目涉及多种前端和后端技术的结合,具体技术栈如下:
- 前端框架:Vue 3(为项目提供响应式界面)
- 后端框架:Flask(用于情绪分析 API 和文本转语音服务)
- 自然语言处理:Hugging Face Transformers 库(情感分析)
- UI 组件库:TDesign Vue Next(美观的界面设计)
- 状态管理:Vue Refs(用于管理状态)
- 图表库:Chart.js(情感分析结果可视化)
- HTTP 客户端:Axios(用于与后端进行数据交互)
- 语音合成:腾讯云 TTS API(将文本转换为语音)
五、功能实现
接下来我将介绍我是如何一步步增加功能的
下面是初始代码
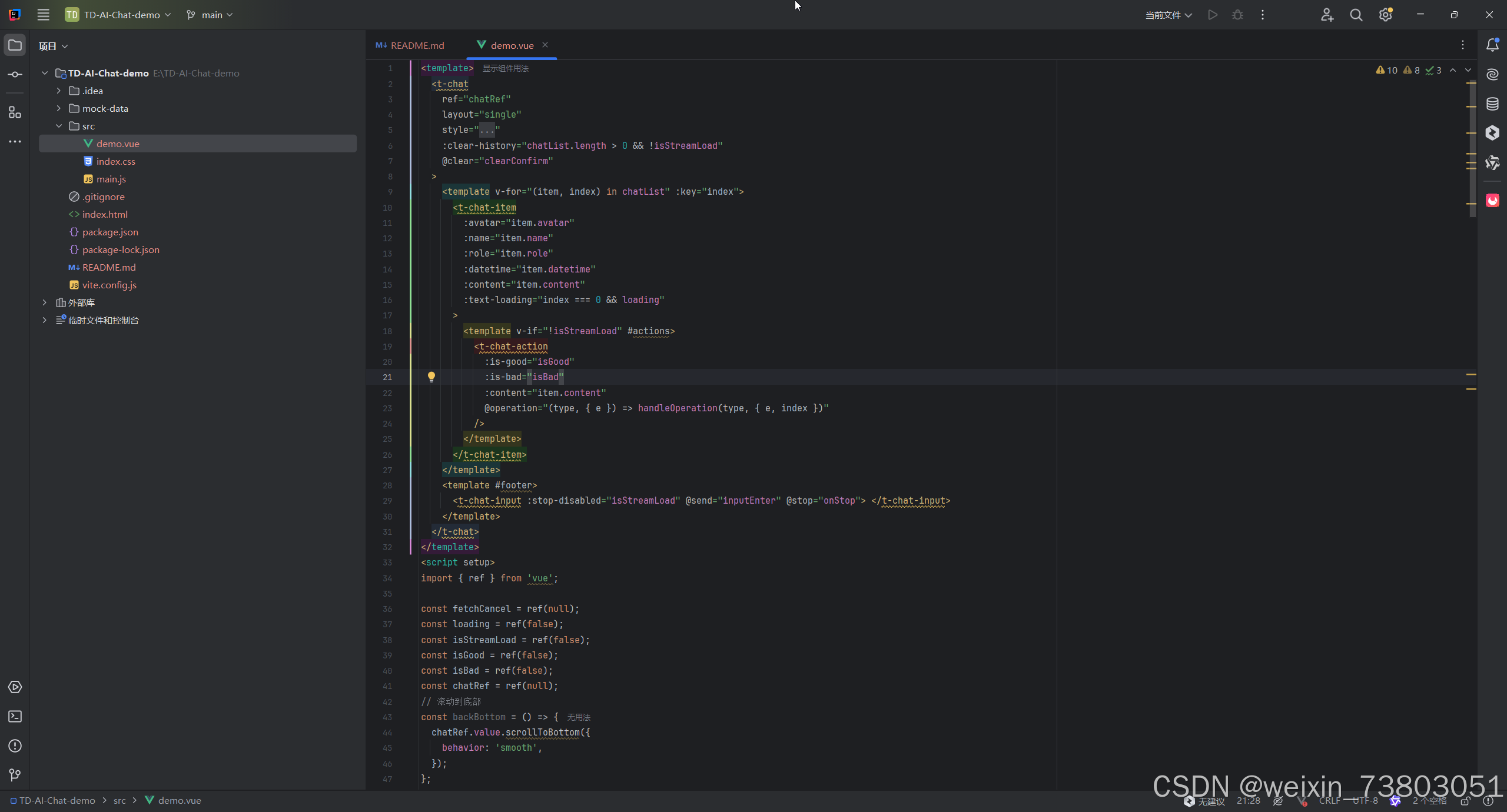
1.聊天记录本地存储
使用后我发现每次刷新,聊天记录都会丢失,因为聊天记录是被缓存在一个数组里的,为了实现能够查看历史记录,我决定询问腾讯云AI:
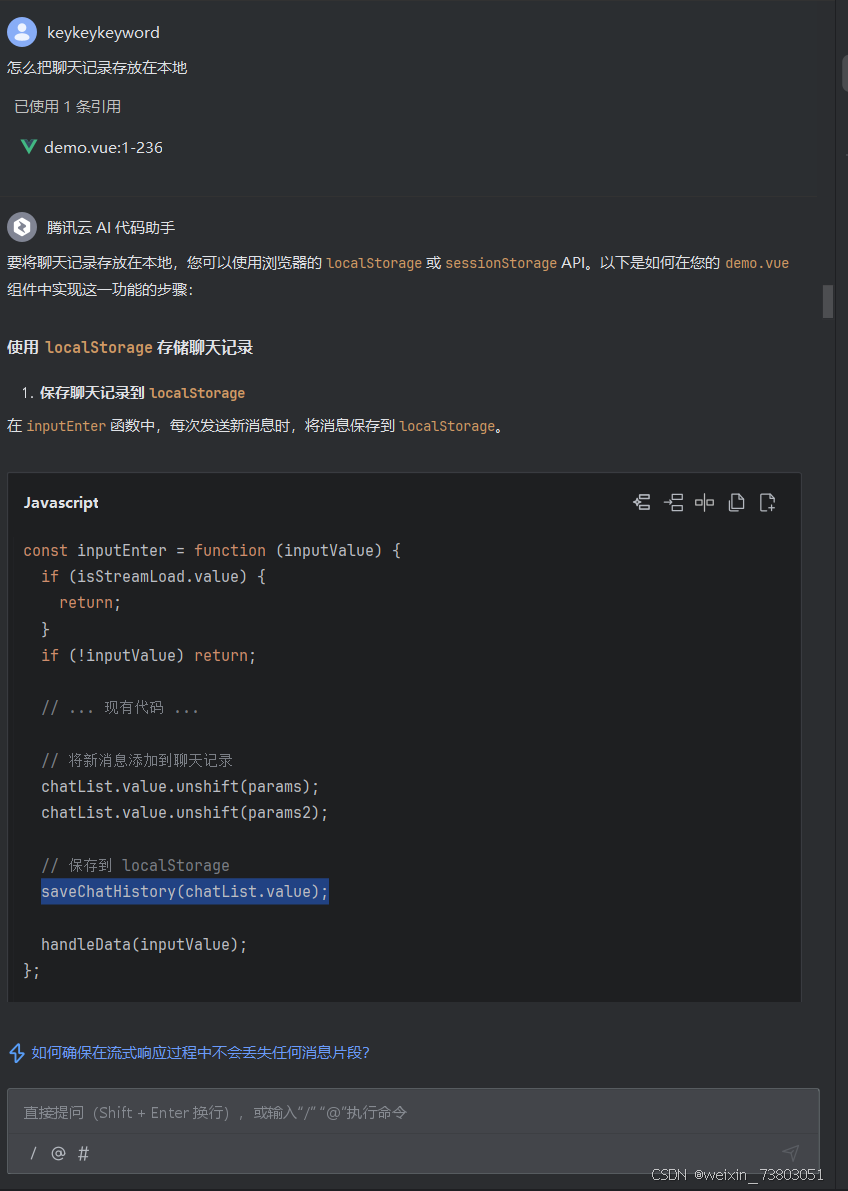
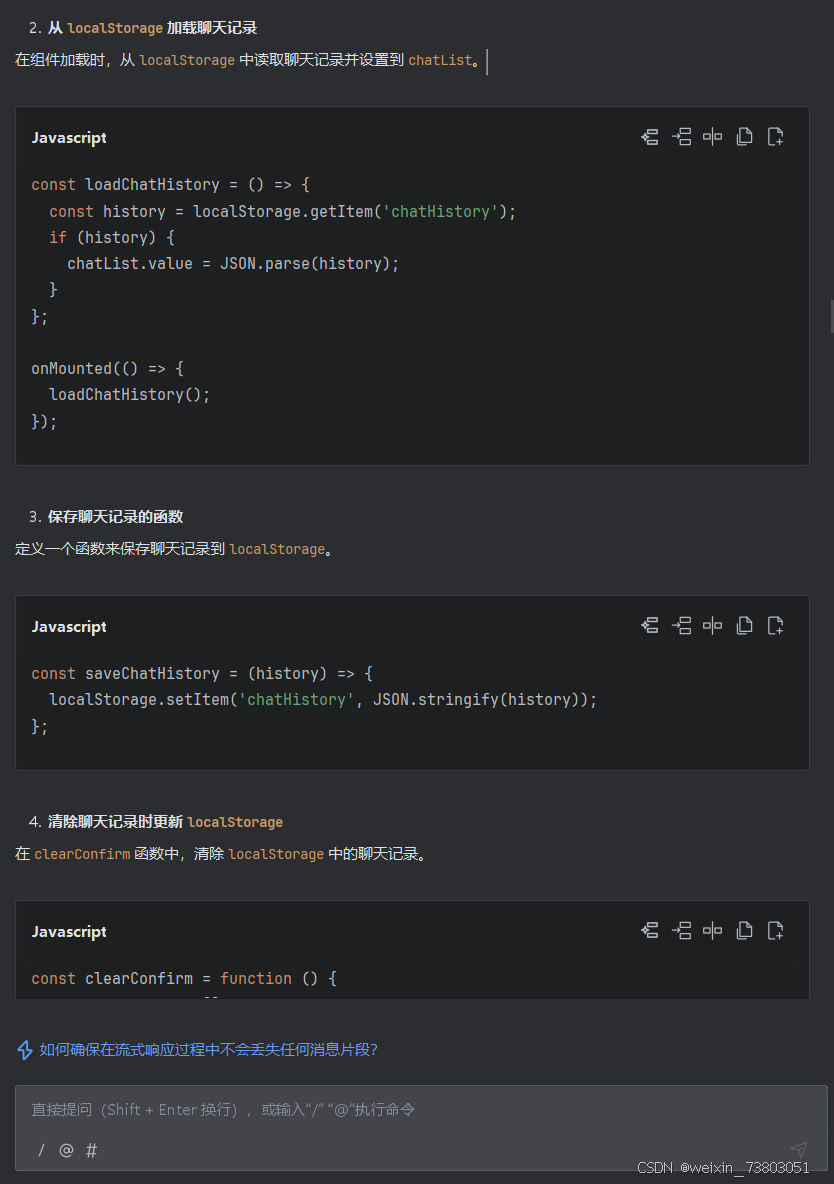
但是把修改代码后,出现了异常情况: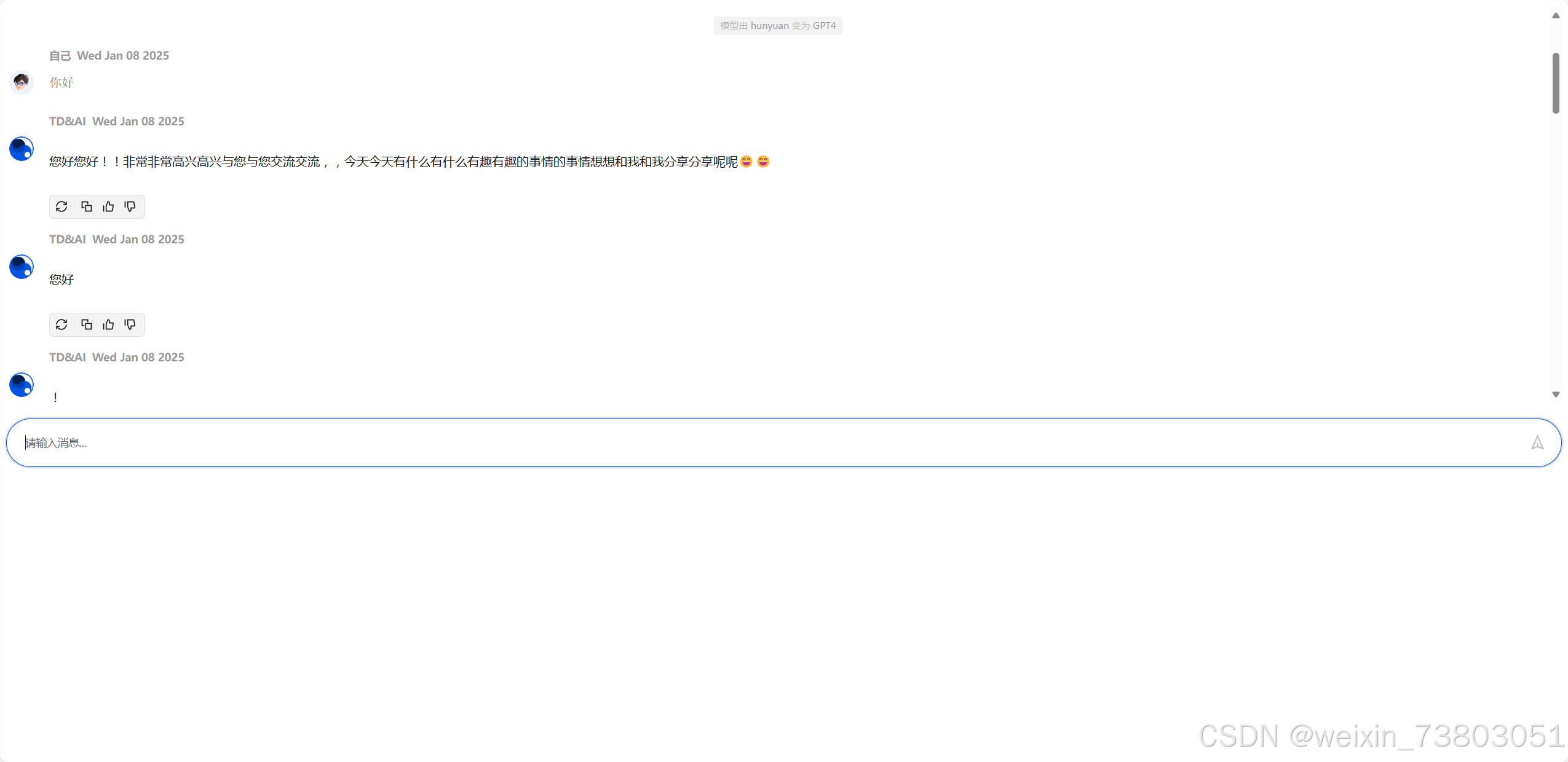
下面是 localstorage内容:

于是我把localstorage复制给AI继续询问
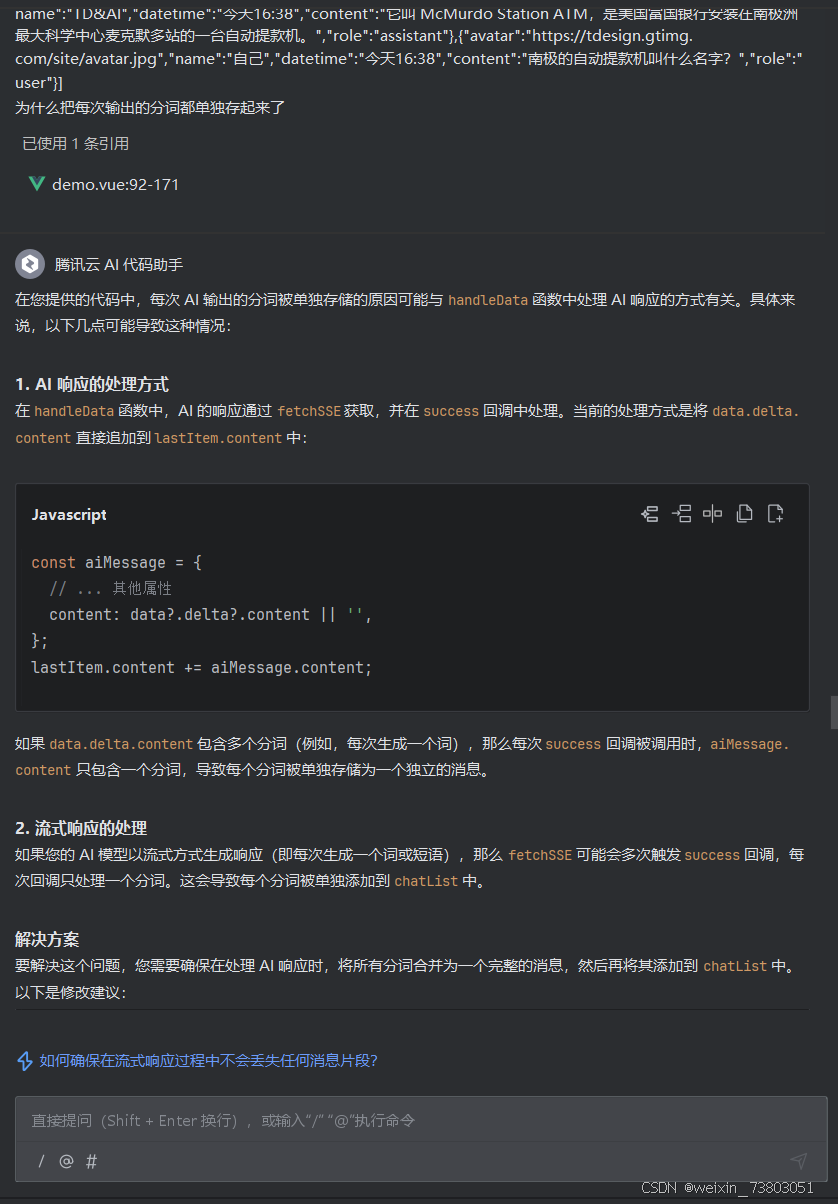
根据AI的回答,我怀疑是存储流程的问题,于是我提出:
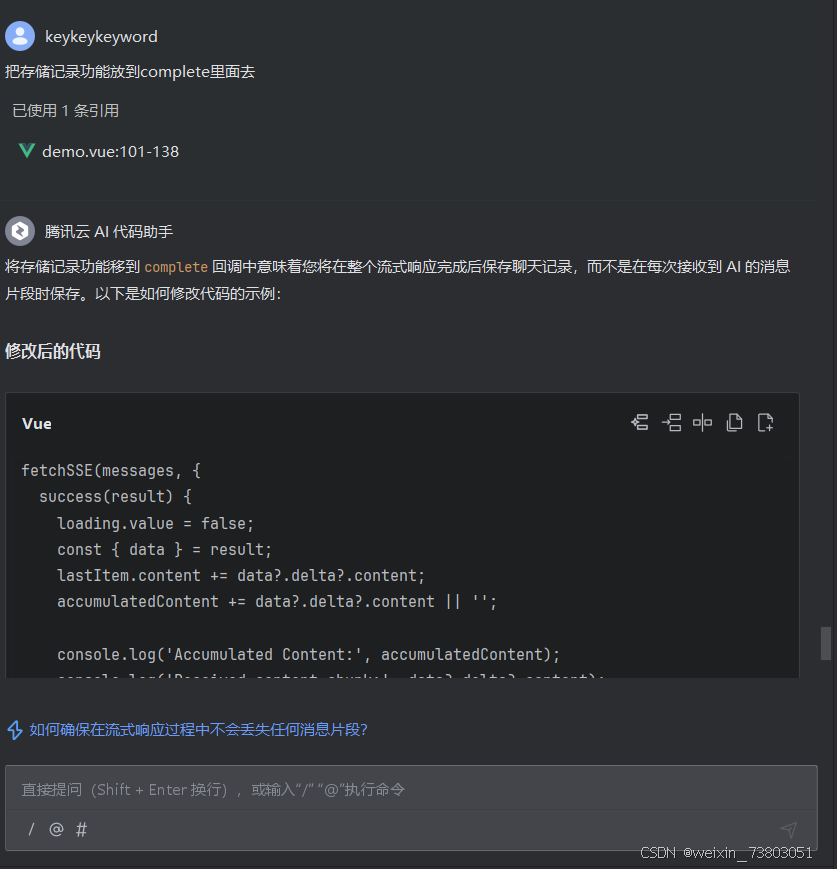
最后实现了存储效果:

然而在点击清除历史记录后,存在本地localstorage里的记录还没有删除,于是继续提问:

替换代码后成功实现点击清除历史记录后,存在本地localstorage里的记录同时删除(除了第一条)。
第一个修改结束
2.优化前端界面
1)优化页面布局
在初始界面中,输入框是居中的,上面是聊天界面,下面是空白,显得整个页面头重脚轻,于是我题出把输入框放到页面底下。
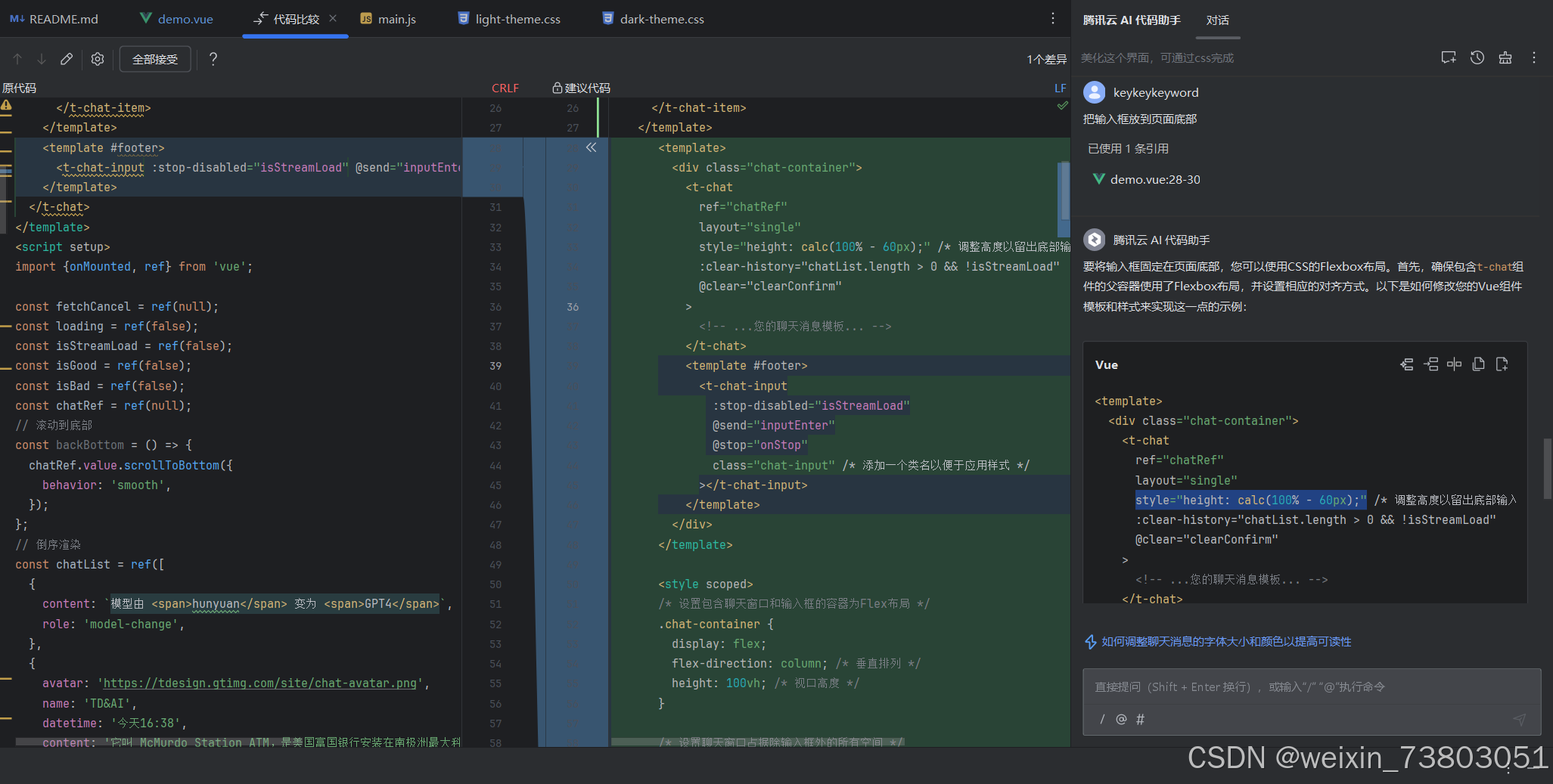
这里我还使用了代码助手的代码比较功能,可以直观地看出新旧代码的区别。
实现效果如下:
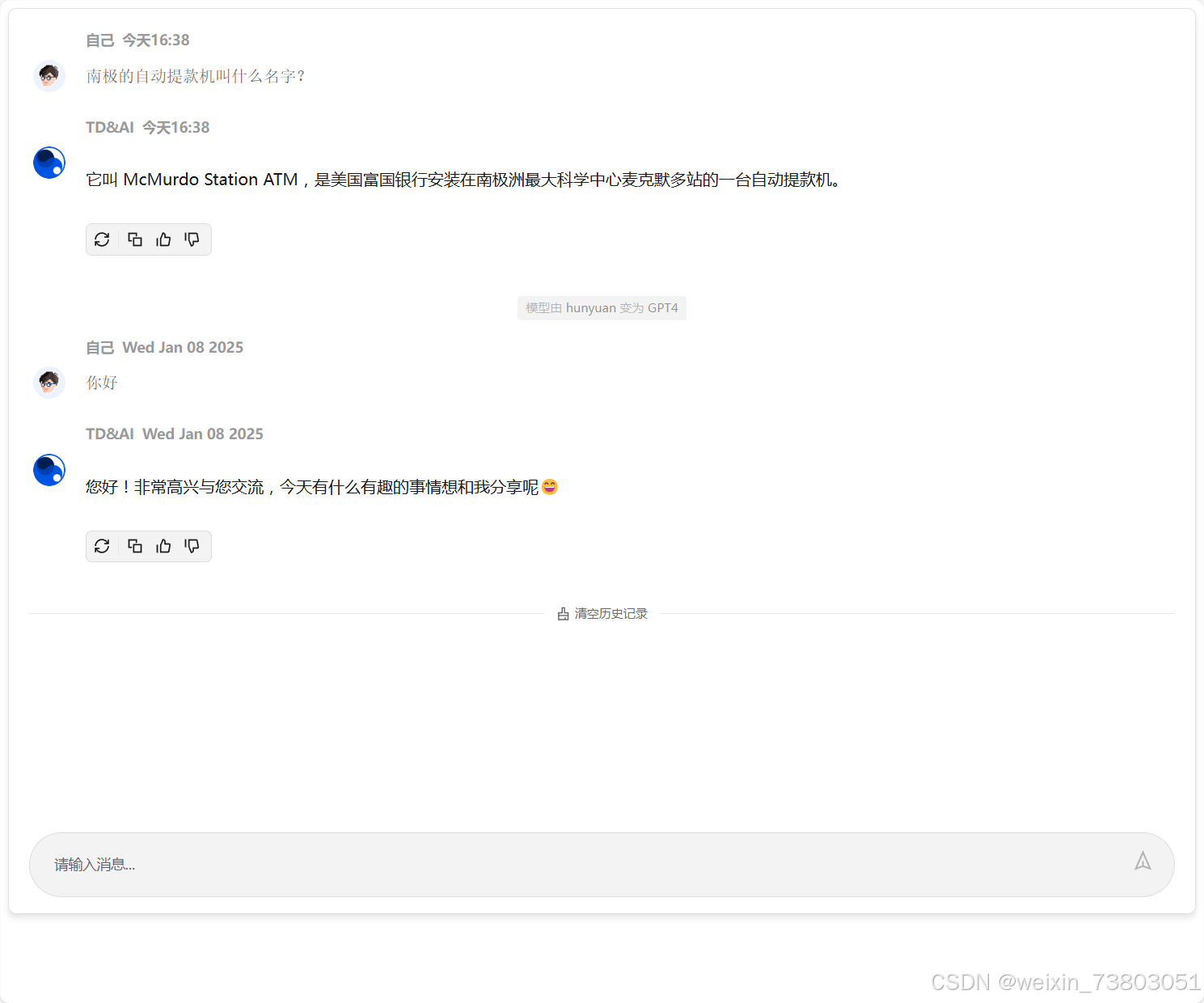
2)显示欢迎语句
在进入页面时显示欢迎语句,可以让用户有宾至如归的感觉
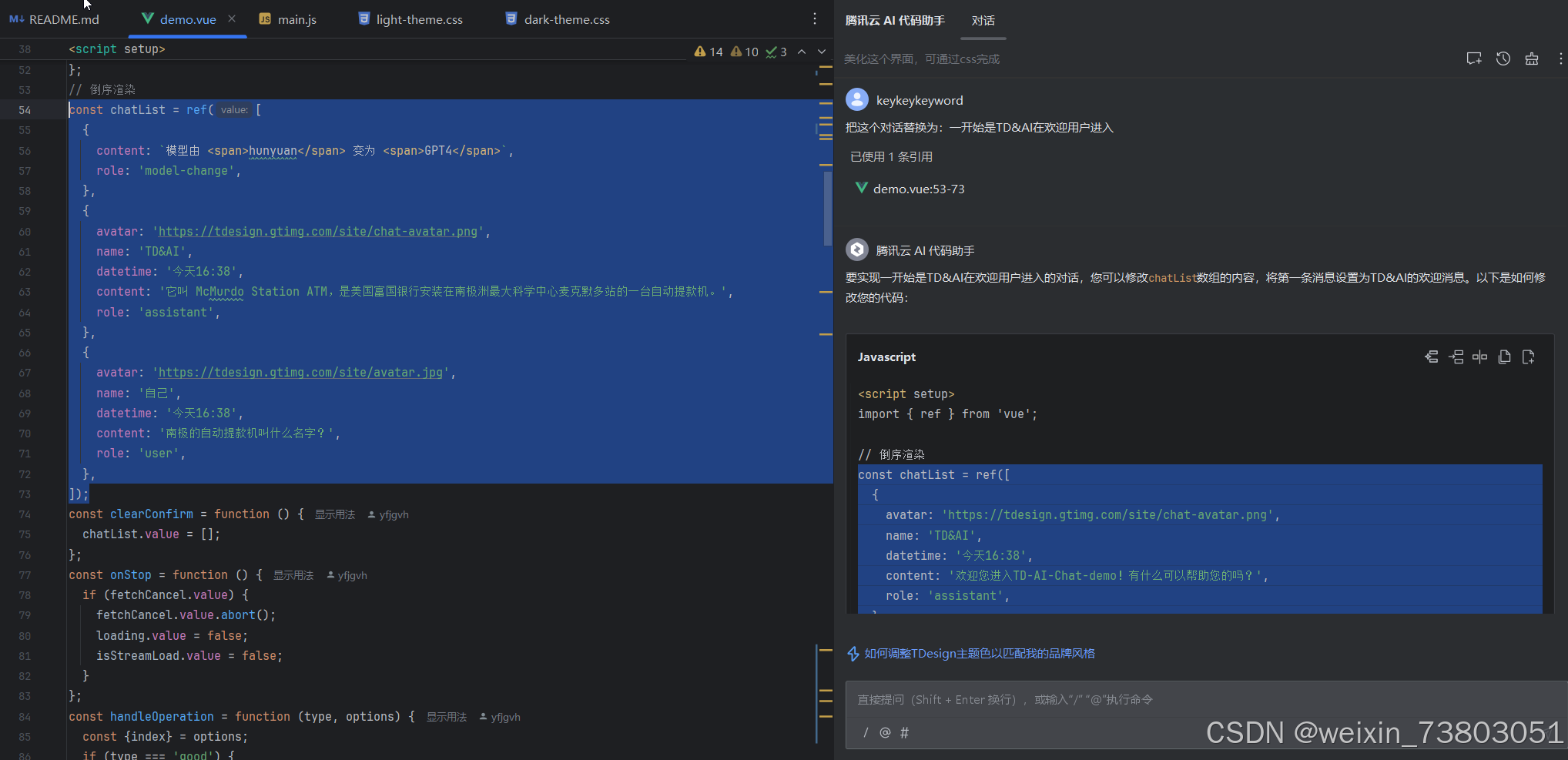
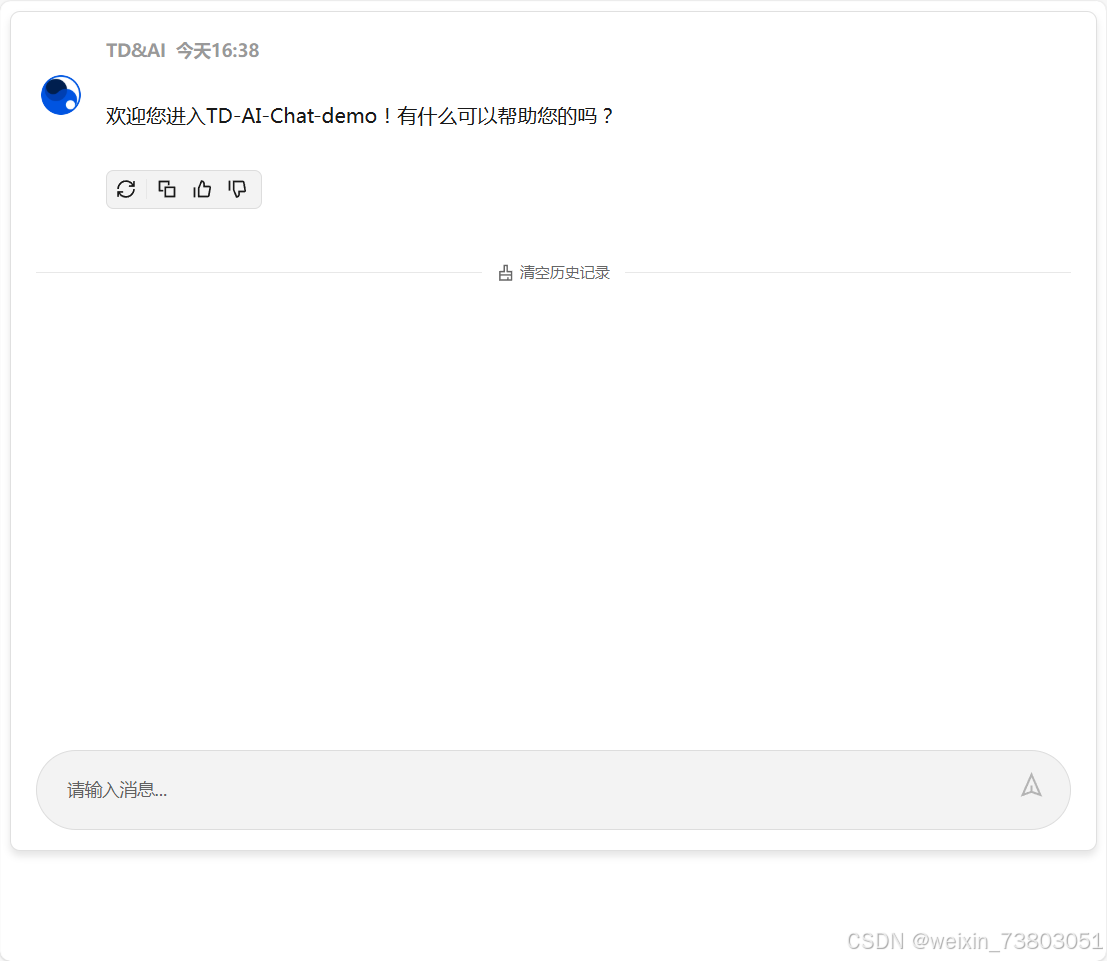
根据AI提供代码修改后:
3)可以显示对话时间
在初始的代码中,第一句对话时间是写死的,之后的对话时间用new Date().toDateString()表示,不符合普通中国用户的阅读习惯,我让AI进行修改,将时间转为中文: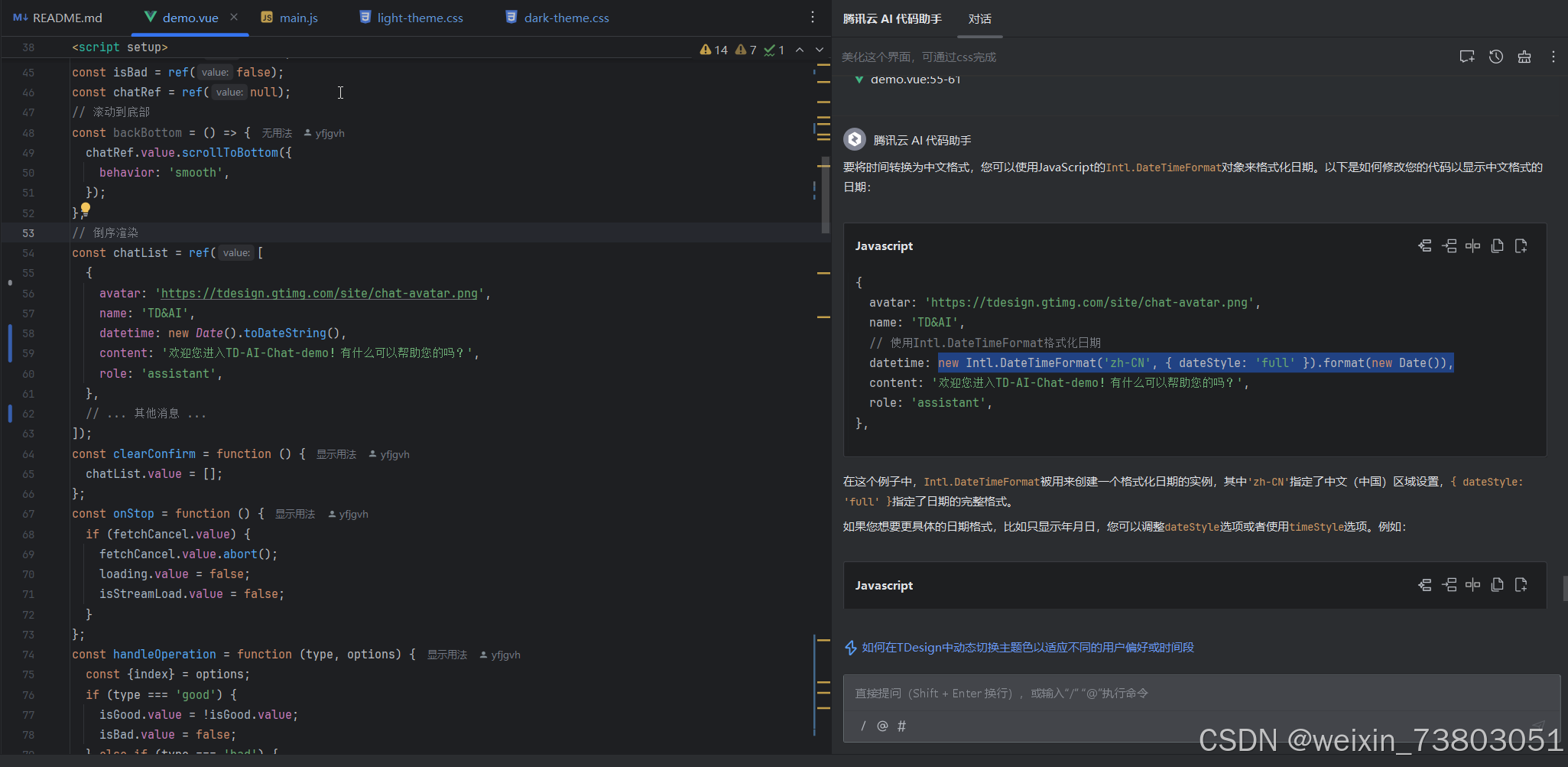
下面是实现效果: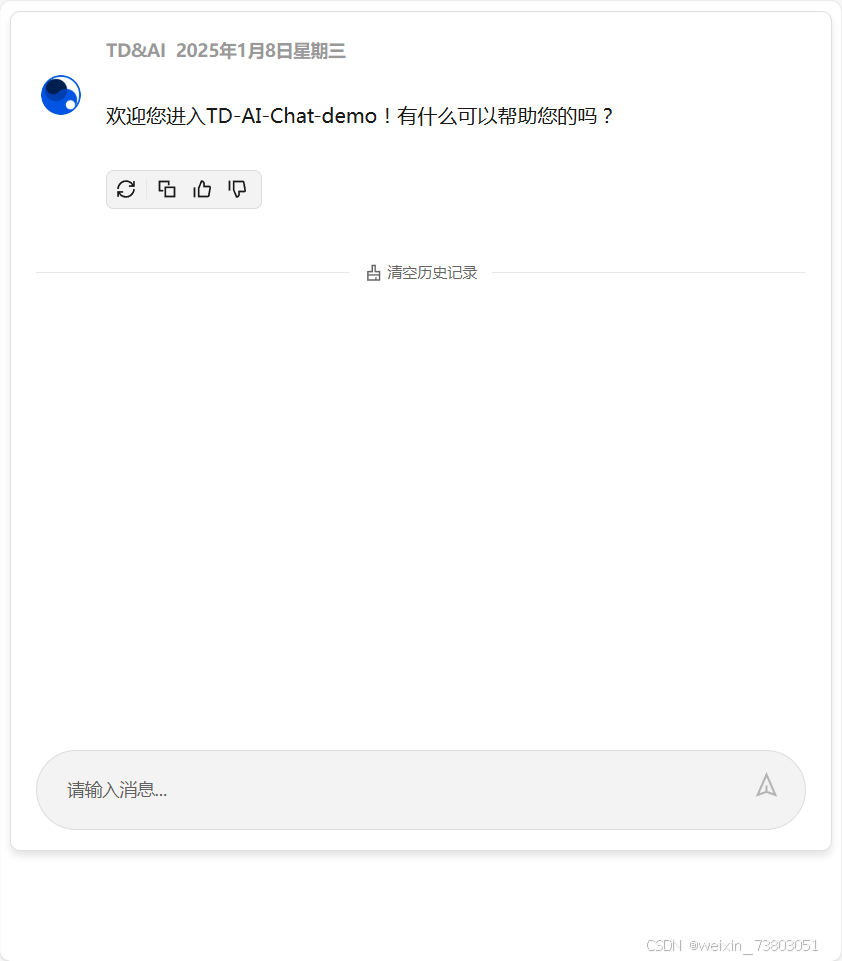
3.聊天记录导出功能
为了进一步完善用户体验,我决定加入导出聊天记录功能:
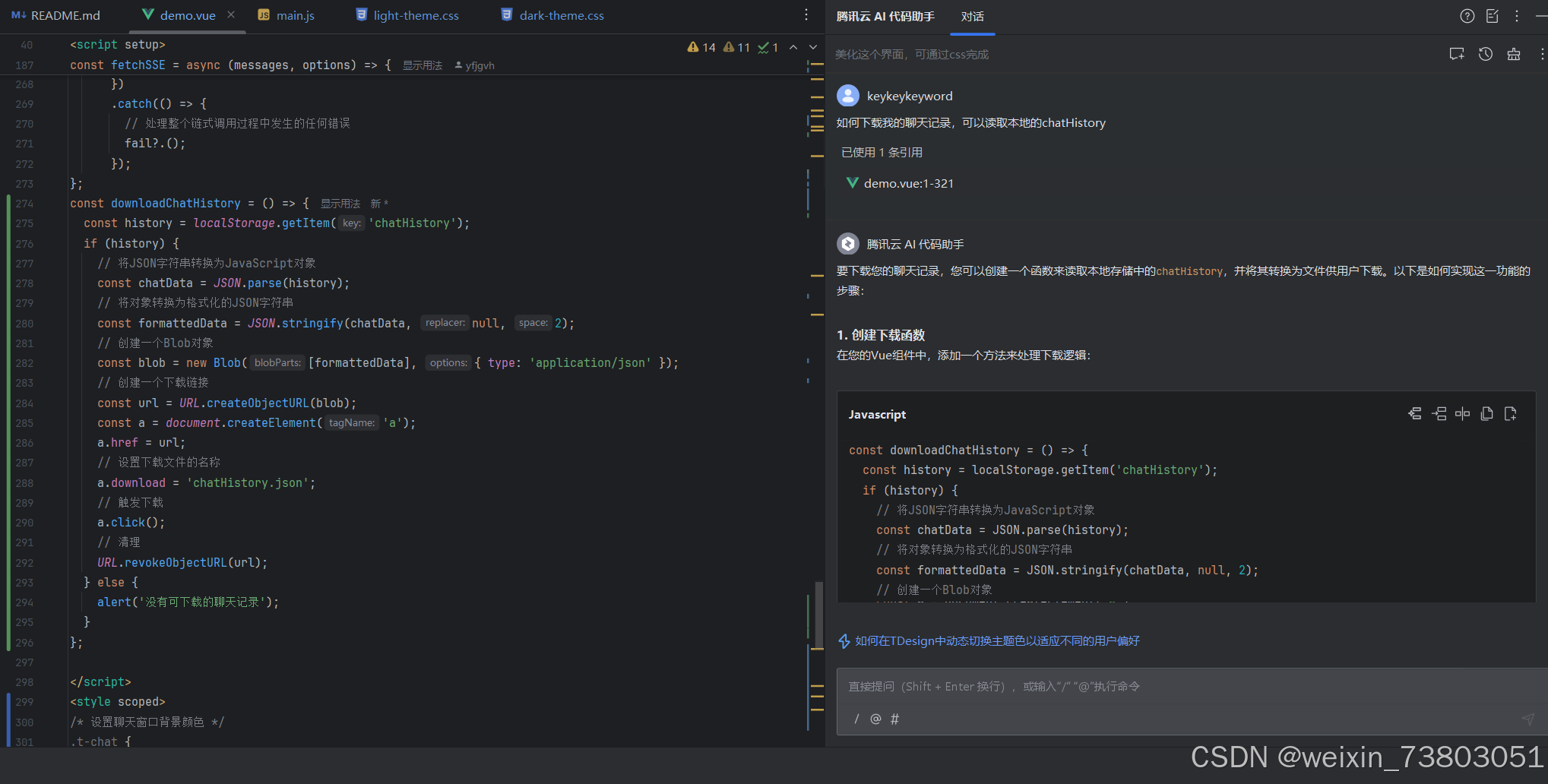
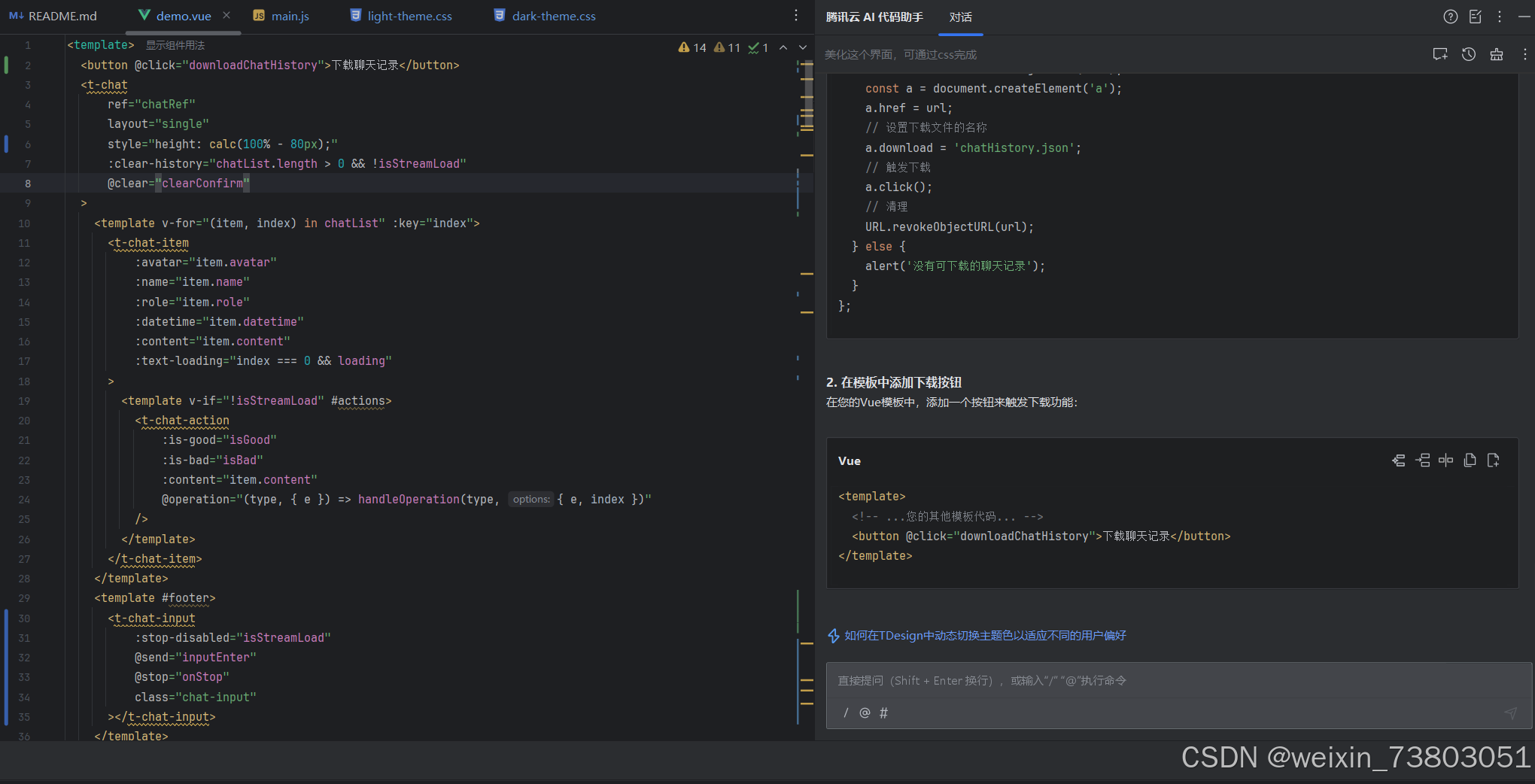
替换代码后成功完成下载:
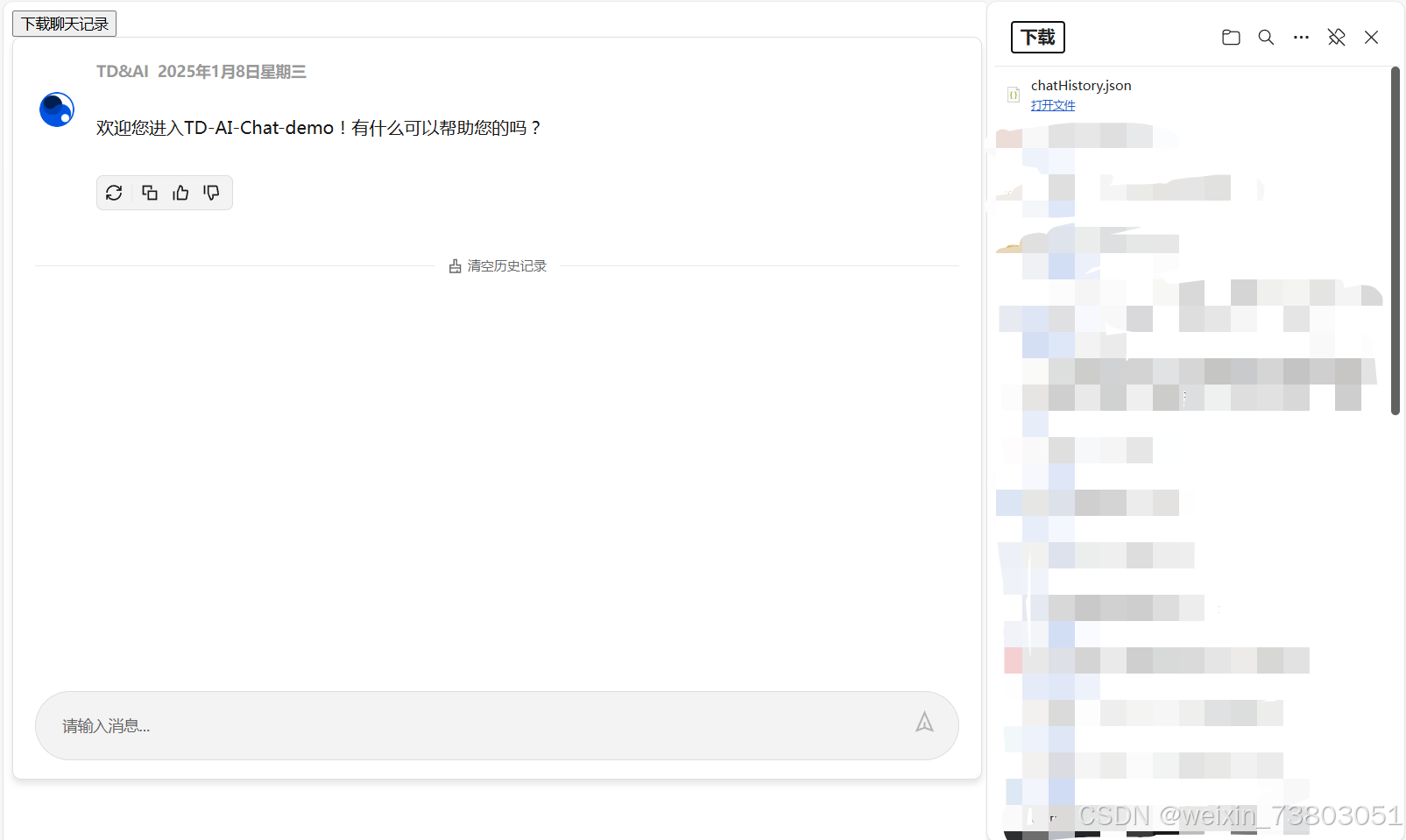
但这按钮实在是太丑了: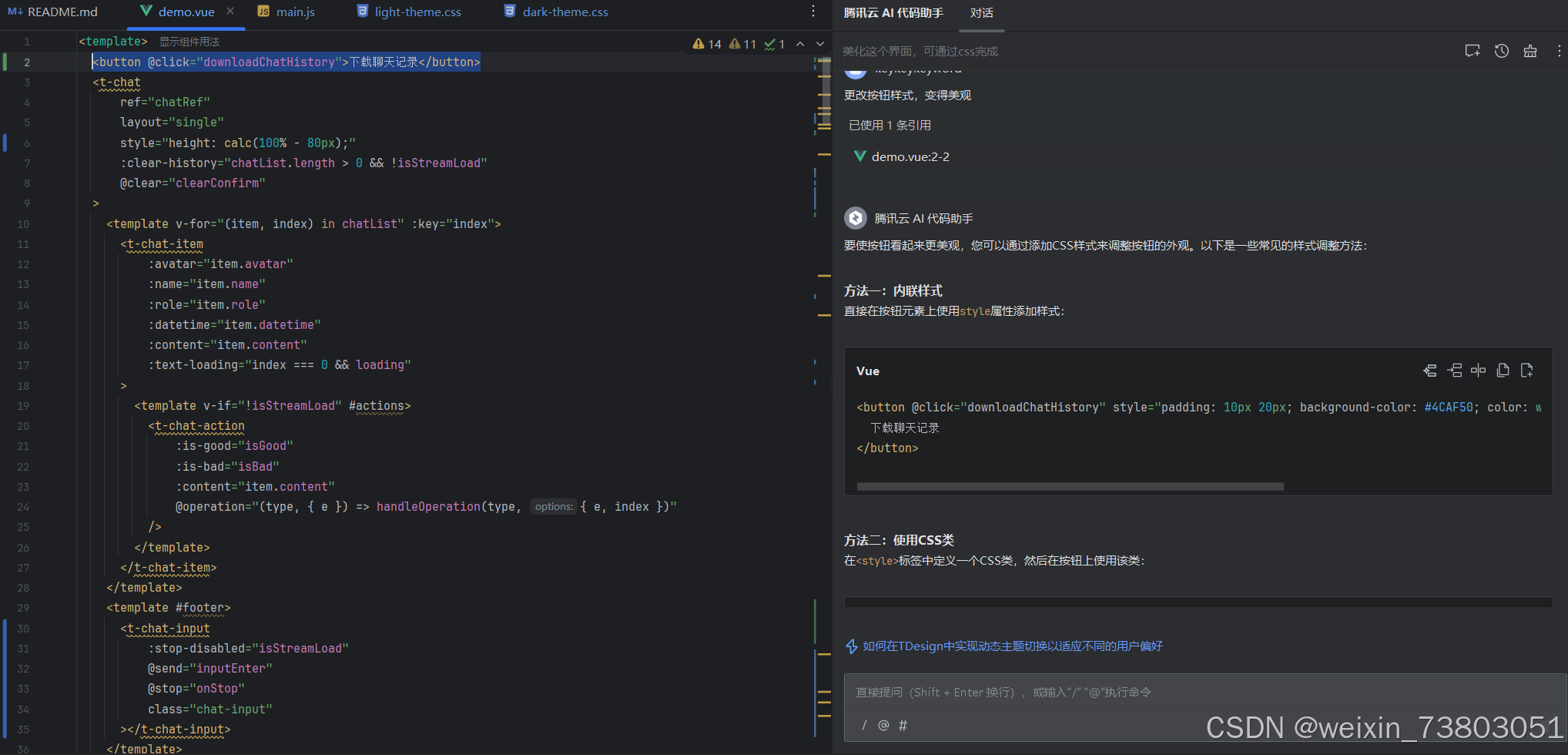
修改后还可以接受: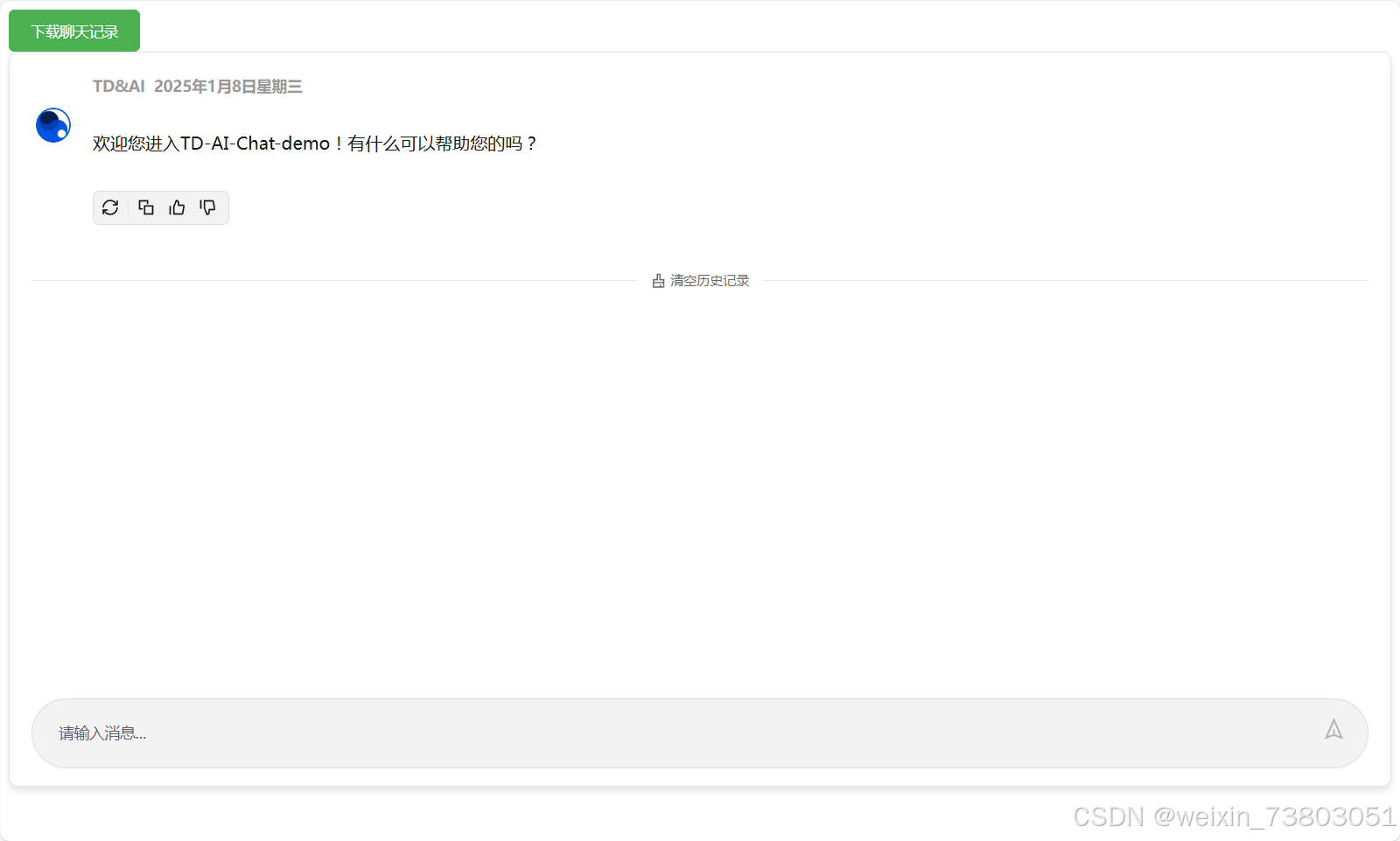
4.文字转语音功能
为了丰富用户的体验,我决定加入重磅功能,用腾讯云的文字转语音服务和我的项目相结合,实现文字转语音功能。
我初步计划使用Python程序作为后端,vue发送请求到后端,后端再去调用腾讯云api。
1)实现过程
我把腾讯云官方的接口文档也发给了代码助手,下面是提供的代码:
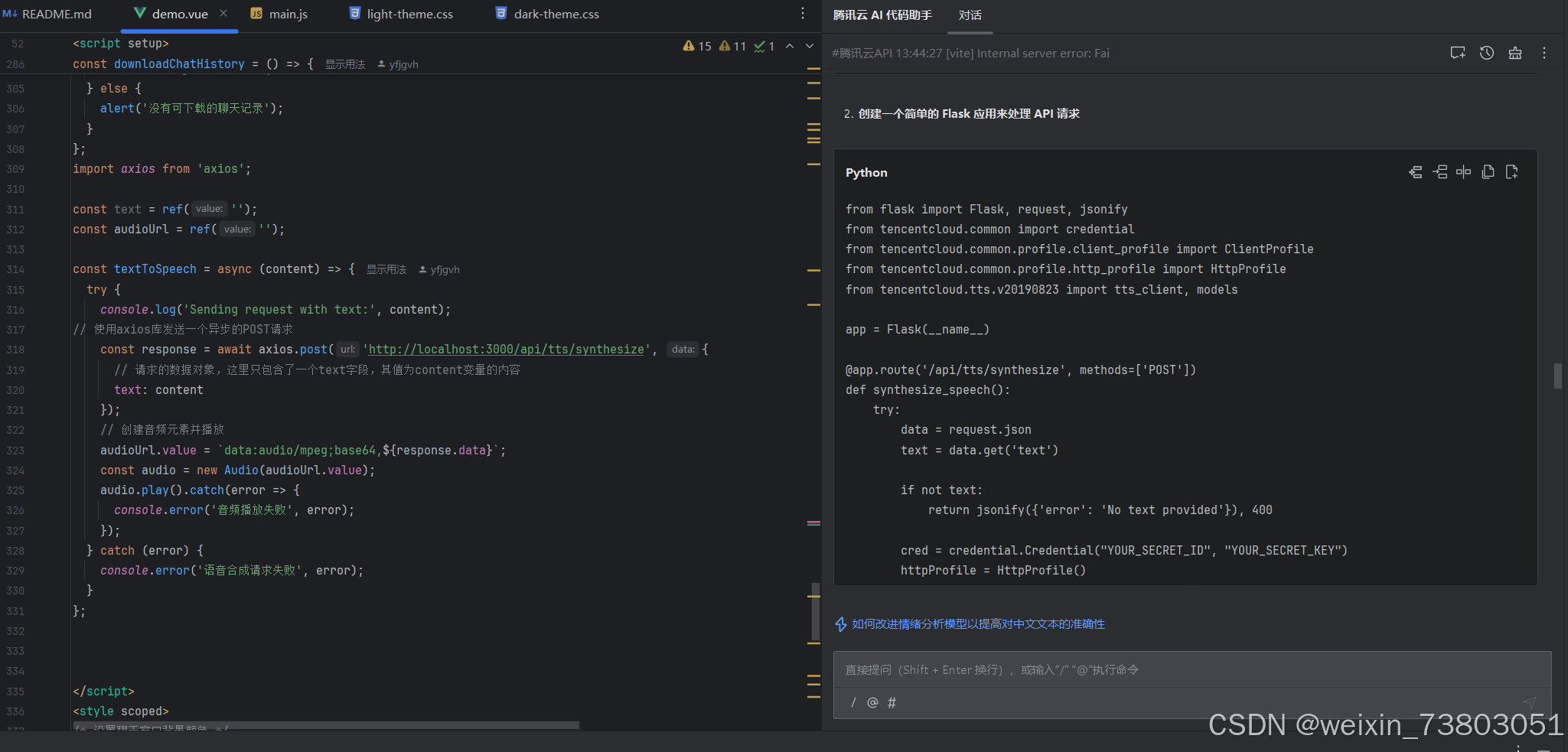

在这里我省去了中间调试的过程(不然图片实在太多了),因为运行后难免有些报错,我不停把报错信息复制给AI,在跟着AI的建议一直修改后,我实现了下面的效果。
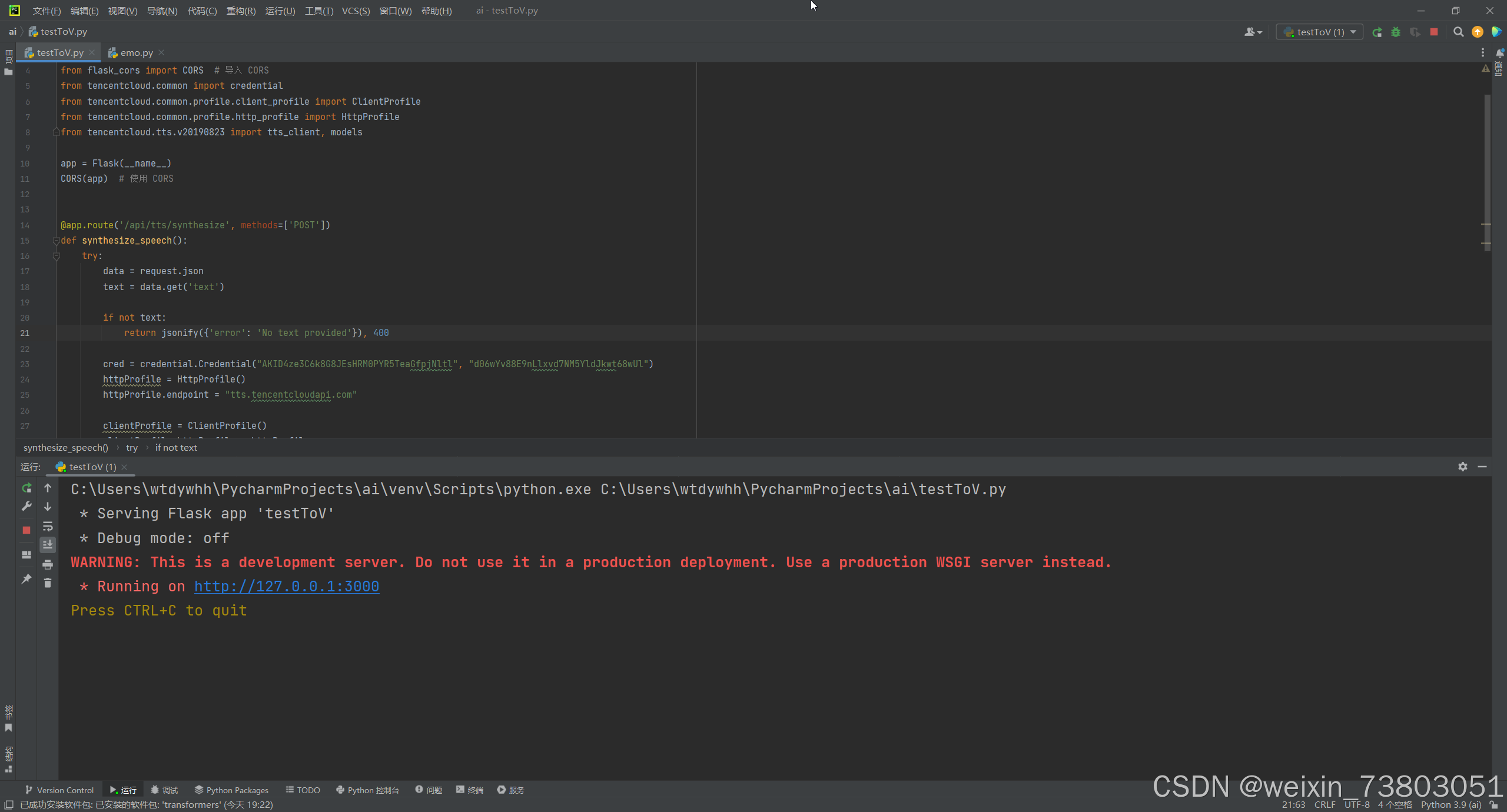
具体的声音效果请参见我发布的演示视频:腾讯云AI代码助手编程挑战赛-“情声共鸣”演示视频-CSDN直播
2)技术解析
1. Flask框架
Flask 是一个轻量级的 Python Web 框架,用于快速构建 Web 应用。在本项目中,Flask 被用作后端框架,负责接收来自前端的 POST 请求,调用腾讯云的文字转语音(TTS)API,并返回语音数据。
-
request.json: 用于解析接收到的 JSON 格式的请求数据。这里提取了text字段,代表要转换为语音的文本内容。 -
jsonify: 用于将 Python 字典或列表转换为 JSON 格式并发送到前端。当请求缺少文本或者发生异常时,返回适当的错误信息。
2. CORS
-
CORS(app): 允许跨域资源共享,解决了浏览器因同源策略阻止跨域请求的问题。在实际开发中,前端和后端可能会部署在不同的域名或端口上,启用 CORS 可以使前端与后端顺利进行数据交互。
3. 腾讯云 TTS API
腾讯云的文字转语音服务 (TTS) 可以将文本内容转换为语音,并返回音频数据。在该项目中,调用腾讯云 TTS API 将输入的文本合成语音,返回音频流给前端。
核心流程:
-
腾讯云认证:使用腾讯云的 API 密钥(
AKID和SecretKey)来进行身份验证。这里的credential.Credential是用来创建认证信息的关键类。 -
配置 HTTP 连接:
-
httpProfile.endpoint = "tts.tencentcloudapi.com":设置腾讯云 TTS 服务的 API 端点地址,确保请求能够发送到正确的服务。
-
-
创建
TtsClient客户端:-
使用
ClientProfile来配置客户端,包括 HTTP 配置信息。 -
TtsClient是实际与腾讯云 TTS API 进行交互的客户端类。
-
请求参数:
-
Text: 要转换为语音的文本。 -
VoiceType: 指定语音的类型,这里使用的是 ID 为 101018 的语音模型。腾讯云提供了多种语音模型,包括男性、女性等不同类型。 -
Codec: 设置输出音频的编码格式,这里选择了mp3格式。其他支持的格式可能包括wav。 -
SessionId: 会话 ID,可以用来标识不同的转换请求,帮助用户进行跟踪和记录。
语音合成:
-
TextToVoiceRequest: 构建一个请求对象,将文本和相关参数传递给 API。 -
req.from_json_string(json.dumps(params)): 将请求参数转化为 JSON 格式,然后填充到TextToVoiceRequest对象中。 -
client.TextToVoice(req): 发送请求并等待响应,resp对象包含了音频数据。 -
resp.Audio: 这是腾讯云返回的音频数据,它是以二进制格式存储的音频流,可以直接发送给前端。
错误处理:
-
使用
try-except语句捕捉异常,确保即使发生错误时,系统也能返回适当的错误信息,避免服务崩溃。
4. 音频返回与前端交互
-
返回音频数据:语音合成成功后,通过 Flask 的
return audio_data, 200, {'Content-Type': 'audio/mpeg'}将合成的音频数据以audio/mpeg格式返回。200表示成功的 HTTP 状态码,Content-Type: audio/mpeg告诉前端这是一段音频文件。-
前端收到后,可以通过
<audio>标签或其他音频播放方式播放音频。
-
5.情感分析和可视化
由于通过实时监测和显示用户的情绪曲线,可以让用户感觉到AI更加智能和贴心。用户可以看到自己的情绪变化,并与AI进行更有趣的互动。另外,根据用户的情绪波动,AI可以调整响应方式。例如,当用户情绪低落时,AI可以提供安慰或者更温和的语言;当用户情绪高涨时,AI可以更加活跃和积极回应,从而使对话更加人性化。
我计划添加“查看情绪曲线”按钮,实现情感分析和可视化功能:
1)初步完成曲线
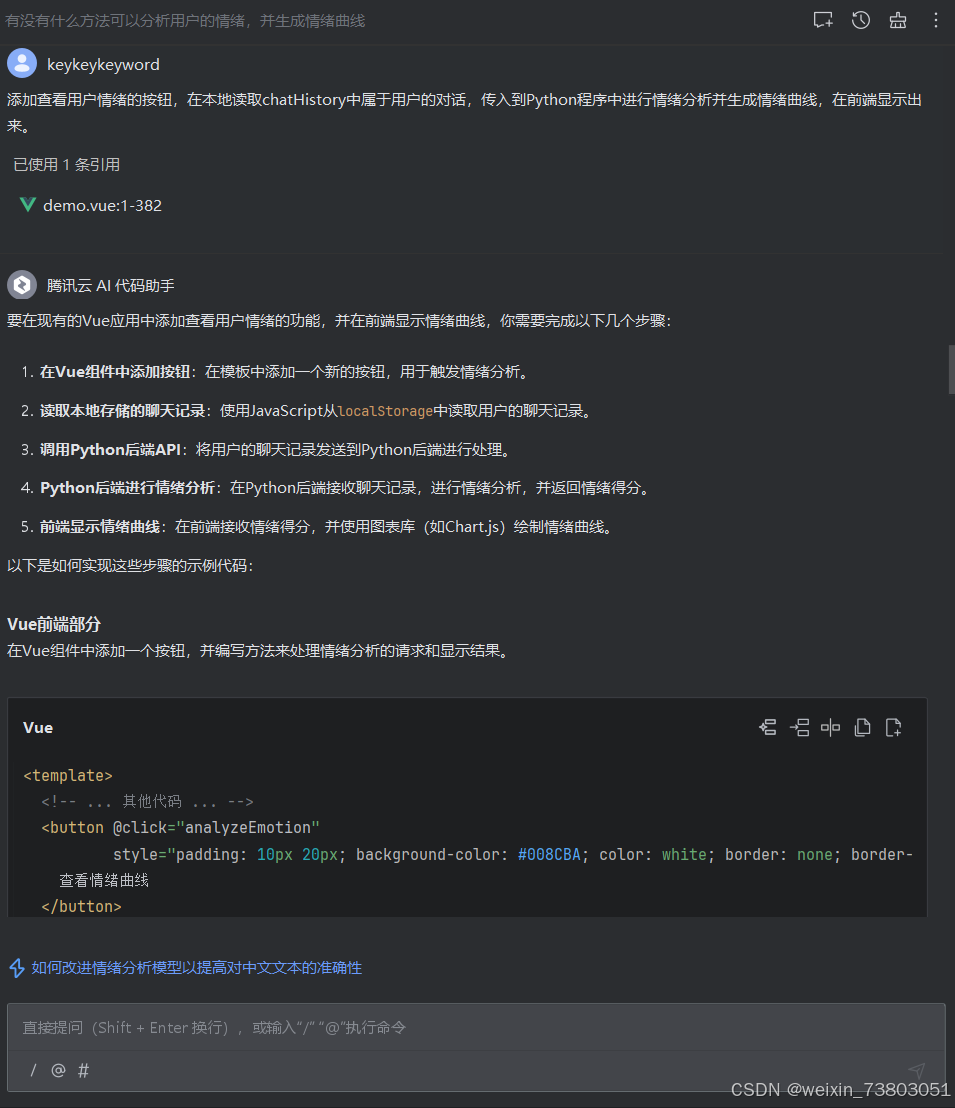
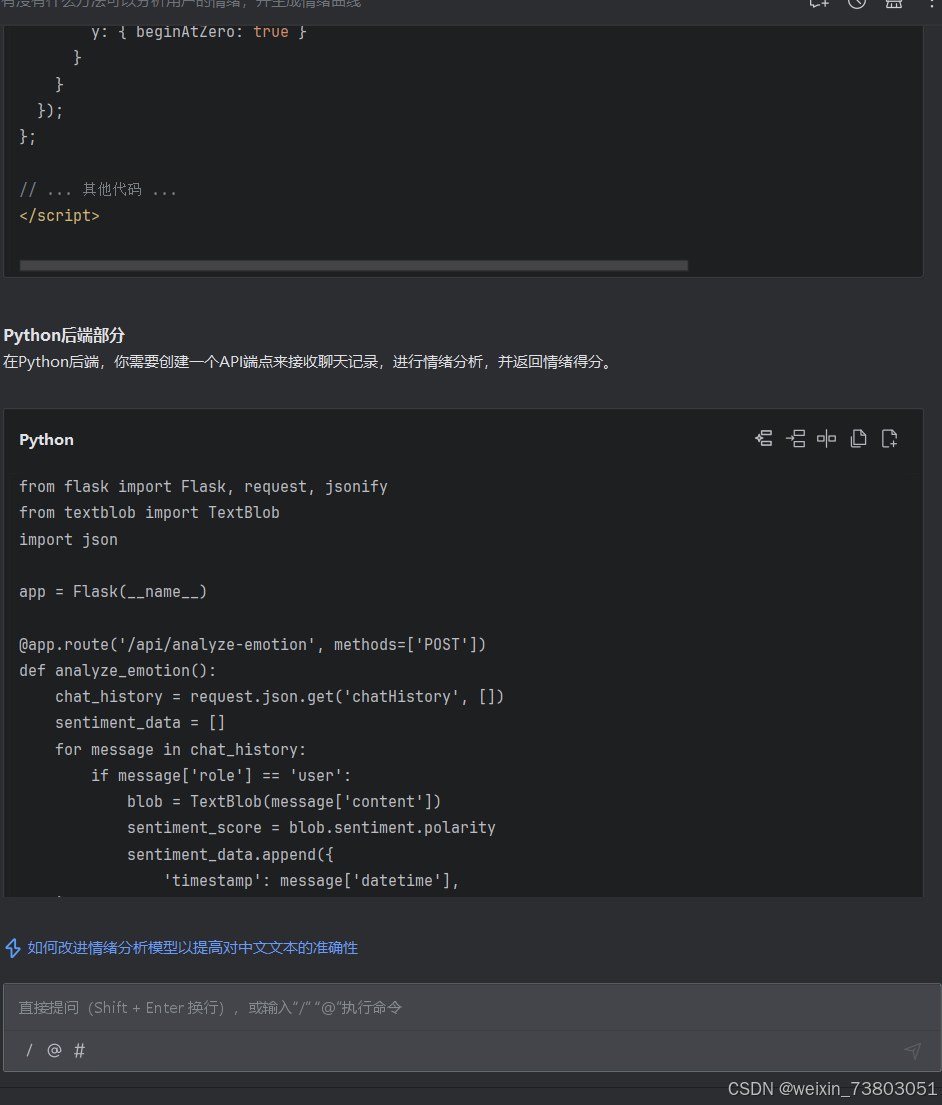
但是运行后发现,曲线的各点始终是0.0,询问AI:
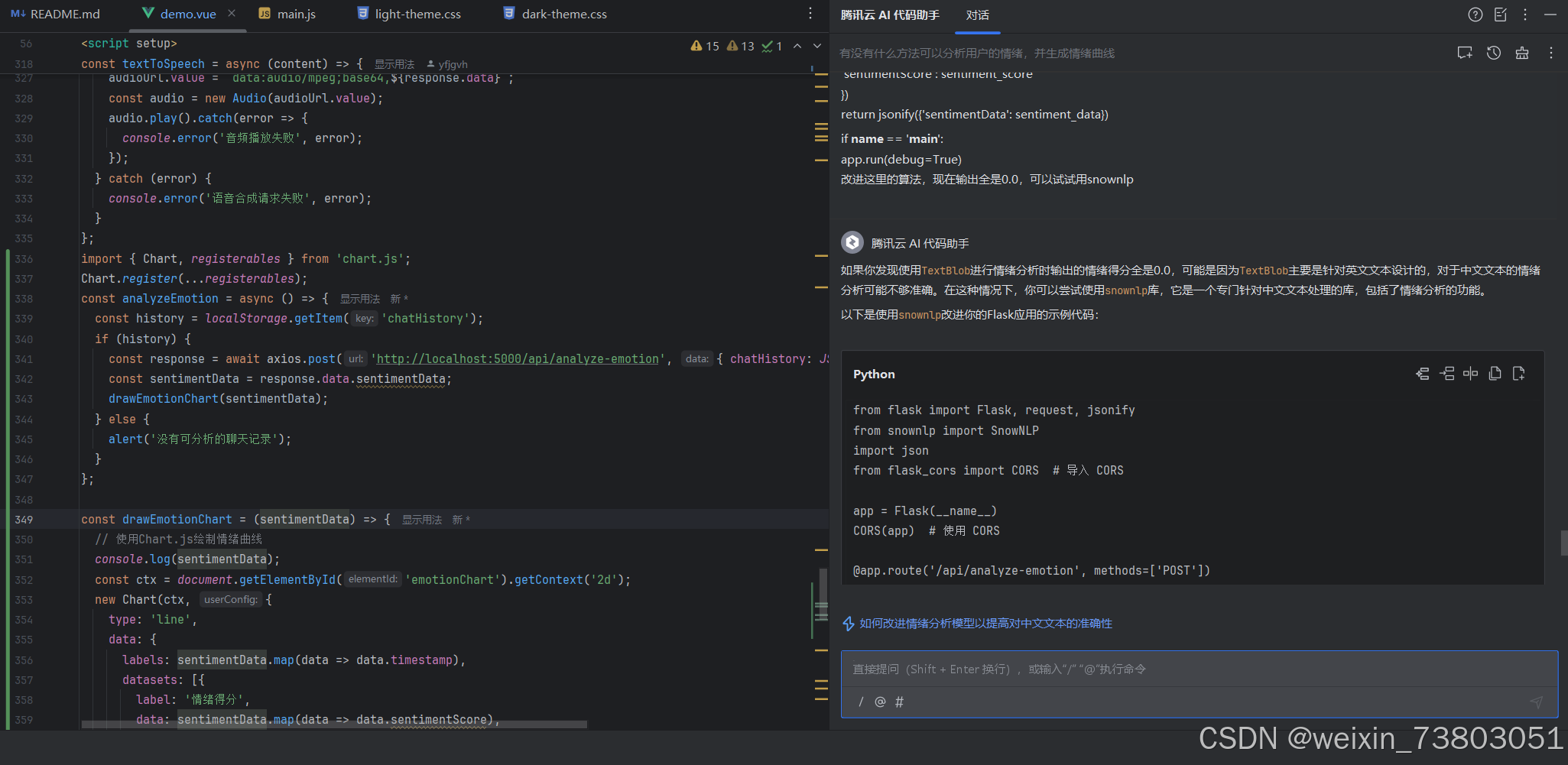
更改情绪算法后,完成初步的情绪曲线:
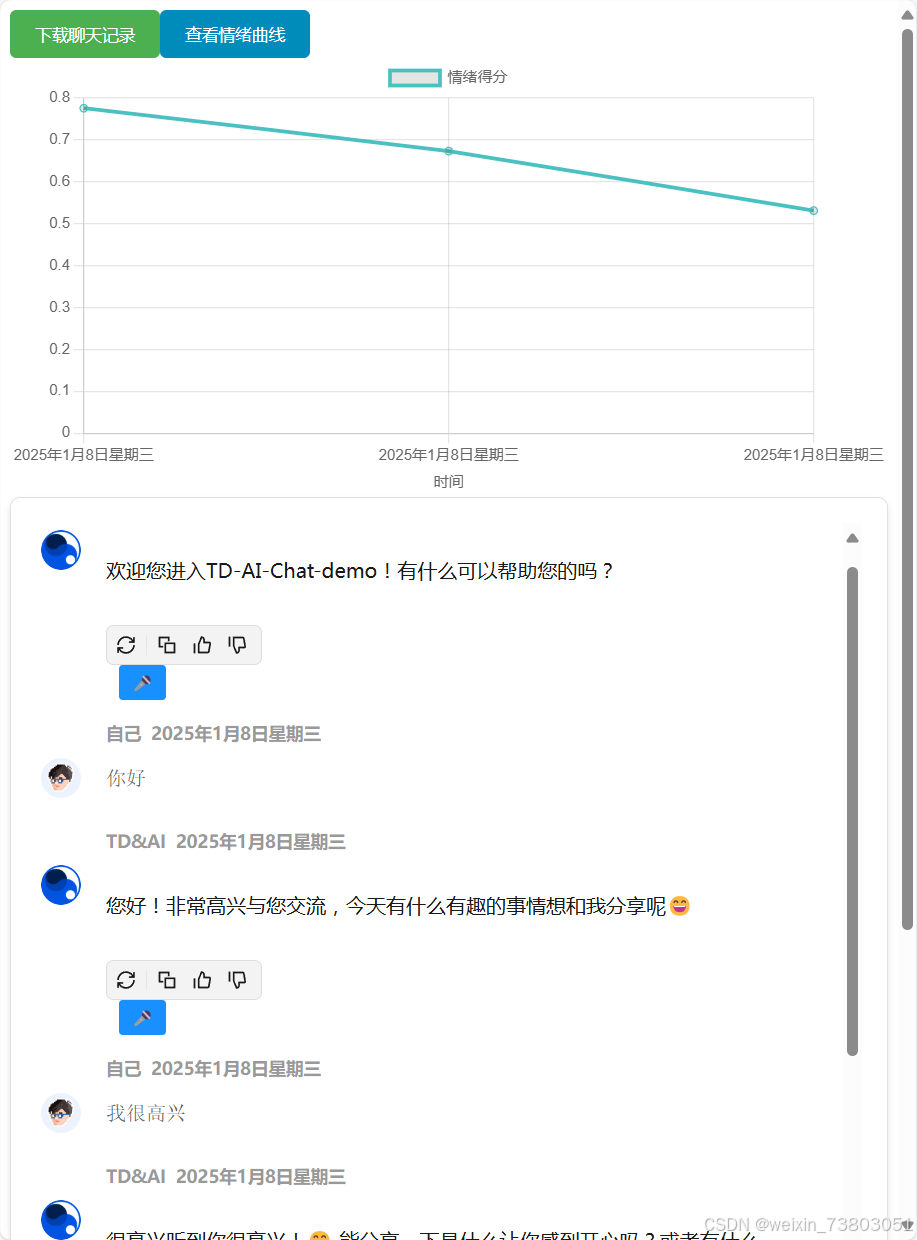
2)修改为浮动窗口
目前的实现方式太占页面,把对话界面都顶到下面去了,我这个项目的重点应该是对话界面,所以我打算把曲线作为浮动窗口显示。
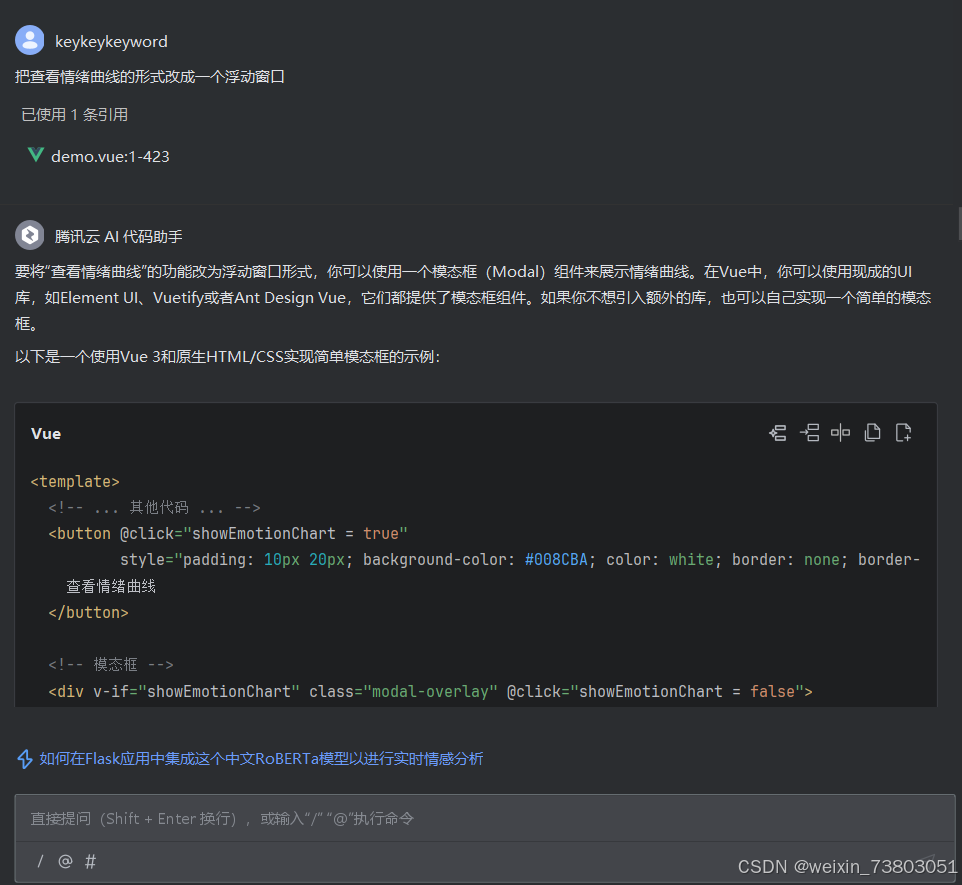
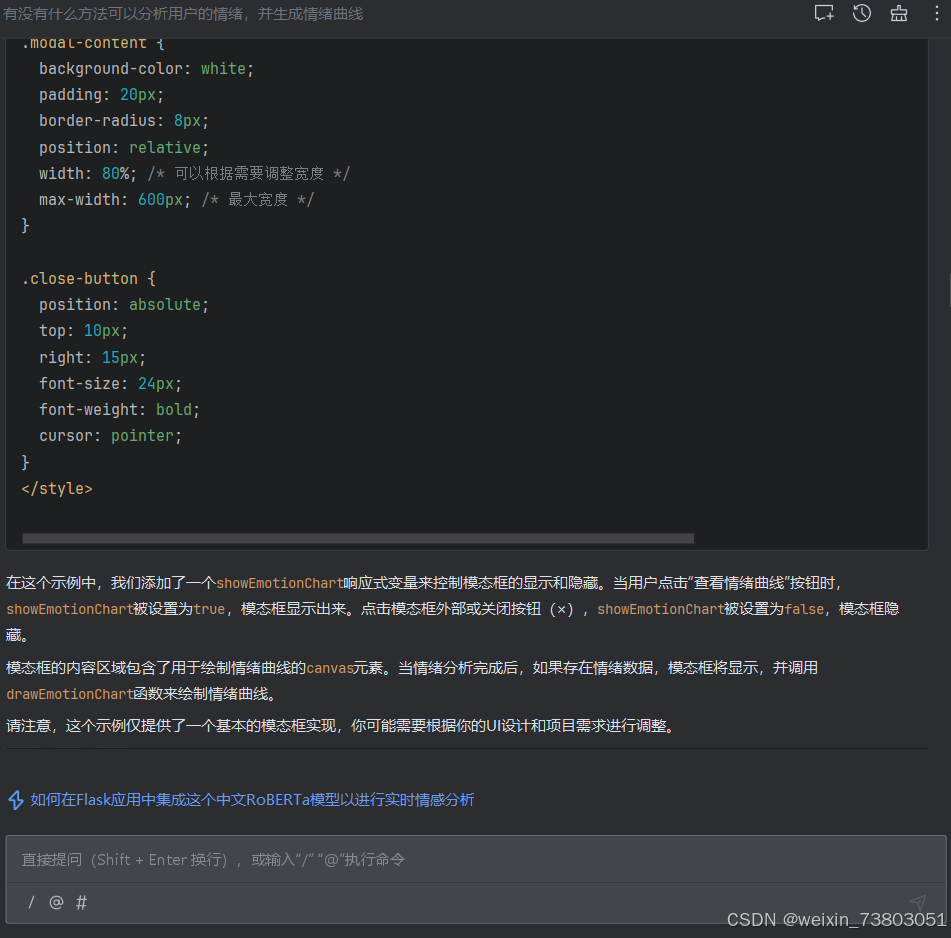
应用后,成功实现了浮动效果:
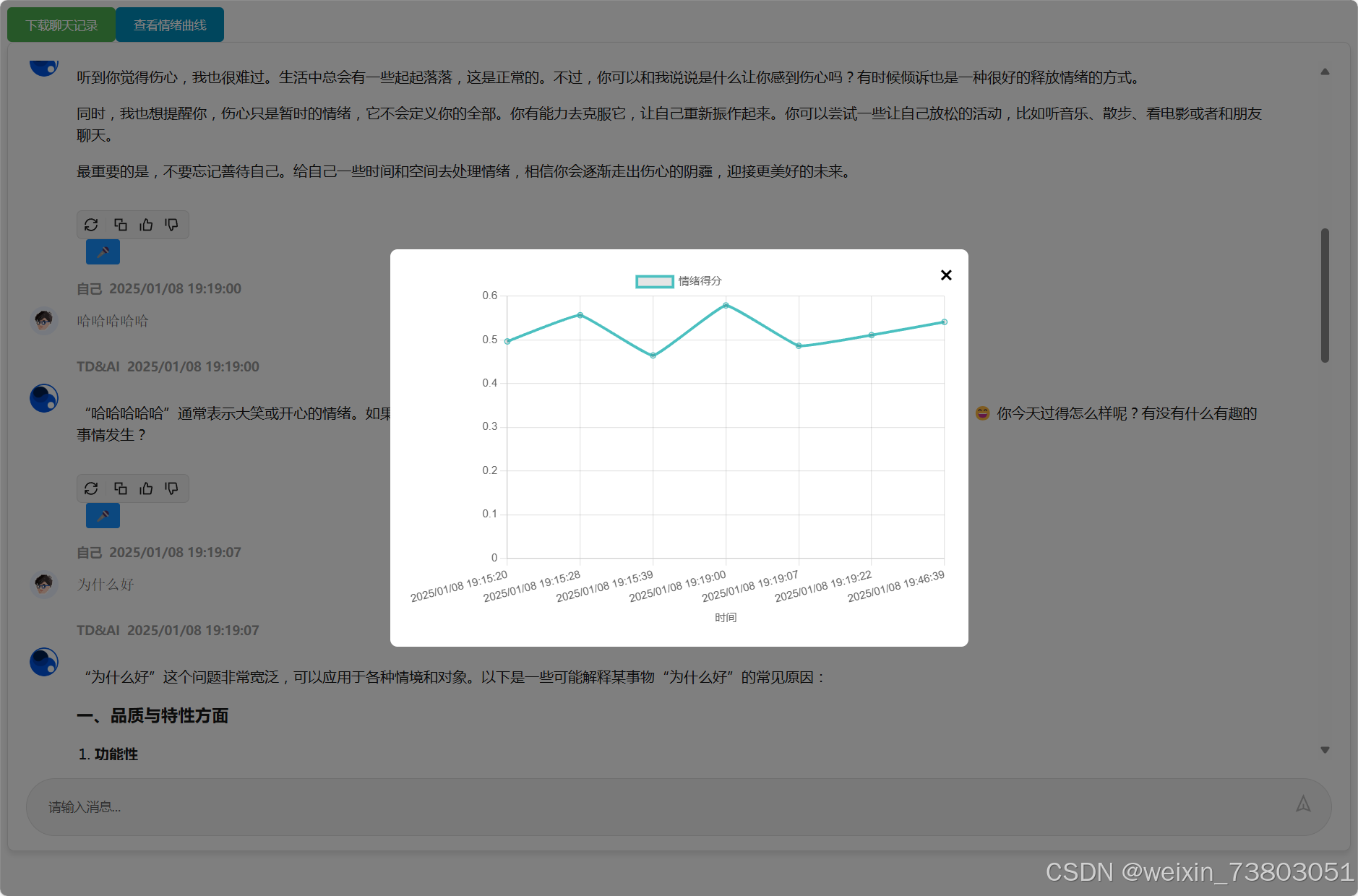
3)优化情绪算法
我打算进一步打磨情绪算法
根据AI的建议,我最终选择了hfl/chinese-roberta-wwm-ext这个模型:hfl/chinese-roberta-wwm-ext 这个模型非常适合用于中文情感分析任务。它在中文文本处理上具有很好的性能和鲁棒性,能够提高情感分析的准确性。
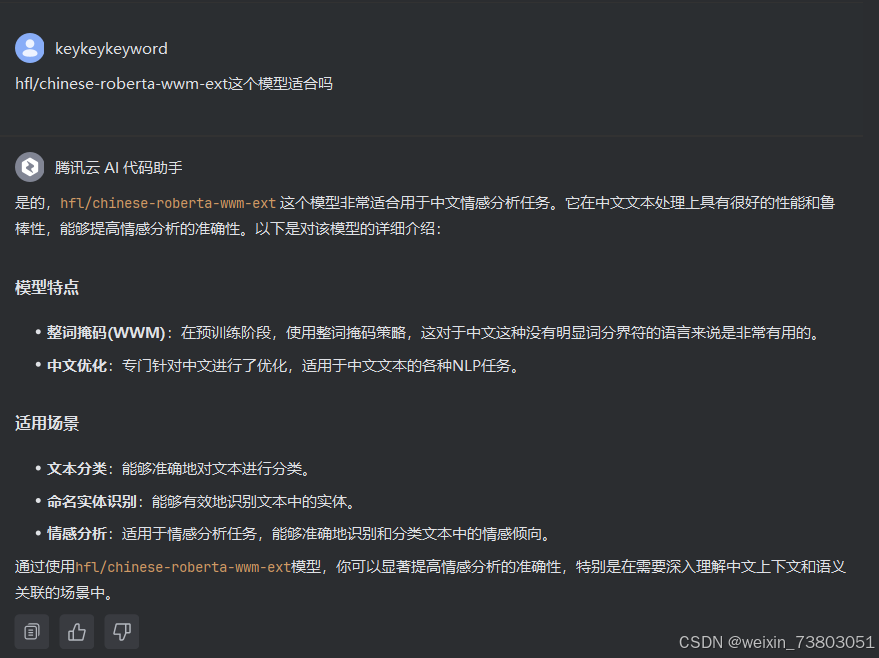
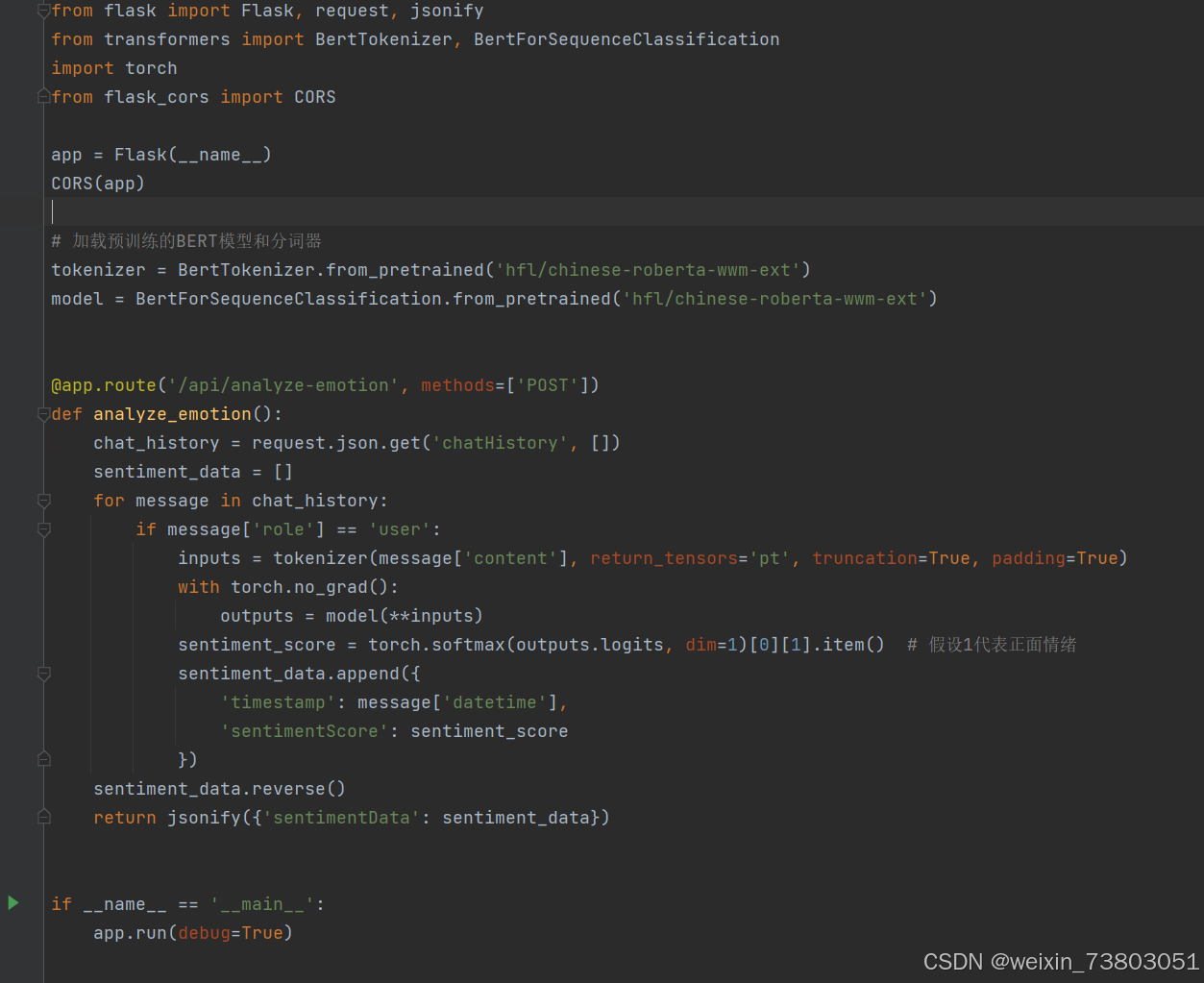
现在对情绪的识别有显著提升。
4)技术解析
以下是对该功能的完整技术解析:
1. Flask框架
-
Flask 是一个轻量级的 Python Web 框架,常用于快速构建小型的 web 应用和服务。在这个项目中,Flask 被用作后端框架,负责处理来自前端的请求,并将情感分析的结果返回给前端。
-
request: 用于从前端获取数据。在这个应用中,request.json用于获取前端传递的 JSON 数据,包括聊天记录(chatHistory)。 -
jsonify: 用于将数据结构(如字典、列表等)转换为 JSON 格式,并作为 HTTP 响应返回给前端。 -
CORS:CORS是跨域资源共享(Cross-Origin Resource Sharing)的缩写,允许前端与后端进行跨域请求。这对于前端和后端部署在不同服务器上的情况非常重要。在本项目中,CORS使得前端(可能使用 Vue 3 等框架)可以访问后端的 API。
2. BERT模型与分词器
-
BERT(Bidirectional Encoder Representations from Transformers)是一个基于 Transformer 的预训练语言模型,通过对大量文本数据进行预训练,能够捕捉上下文信息和语言的深层次关系。本项目使用的是 RoBERTa 变种,即
hfl/chinese-roberta-wwm-ext,专门针对中文文本处理进行优化。 -
Tokenizer:
-
BertTokenizer.from_pretrained('hfl/chinese-roberta-wwm-ext'): 这个步骤加载了 RoBERTa 模型的分词器。分词器的作用是将输入文本转换为模型可以理解的数字化格式(token)。例如,将中文文本切分成子词或字符,并为每个子词分配一个唯一的编号。 -
在代码中,
tokenizer(message['content'], return_tensors='pt', truncation=True, padding=True)对每条用户输入的消息进行编码,处理文本的截断(truncation=True)和填充(padding=True),确保每条输入的长度一致,适合输入到模型。
-
3. 情感分析
-
情感分类模型:
-
BertForSequenceClassification.from_pretrained('hfl/chinese-roberta-wwm-ext'): 这一步加载了预训练的 RoBERTa 模型,它已经在大量中文文本数据上进行了训练,能够执行如情感分析、文本分类等任务。加载的模型是专门用于文本分类的变种,可以根据输入文本输出情感分类的标签或分数。
-
-
情感得分计算:
-
outputs.logits: 在执行推理时,模型返回的是 logits,即未经过归一化的预测分数。这些分数表示文本属于各个类别的可能性。 -
torch.softmax(outputs.logits, dim=1):softmax函数将 logits 转换为概率分布,表示每个类别的预测概率。在情感分析中,假设1代表正面情绪,0代表负面情绪,那么outputs.logits中的第二个位置(即outputs.logits[0][1])即为正面情绪的概率。 -
sentiment_score = torch.softmax(outputs.logits, dim=1)[0][1].item(): 从模型输出的结果中获取正面情绪的概率,并通过.item()方法将其从张量转换为 Python 数值类型(float)。
-
4. API设计
-
情感分析接口 (
/api/analyze-emotion):-
该接口采用
POST方法,接收一个包含聊天历史记录(chatHistory)的 JSON 请求。每条消息包含以下信息:-
role: 消息的角色,可能是user或system。 -
content: 消息的文本内容。 -
datetime: 消息发送的时间戳,用于在返回结果中展示每条消息的情感分析时间。
-
-
-
情感分析数据的返回:
-
后端通过循环处理每条用户输入的消息,并调用预训练的 RoBERTa 模型进行情感分析,最后将每条消息的情感得分(
sentimentScore)和时间戳(timestamp)返回给前端。返回数据格式为 JSON,前端可以根据这些数据来展示用户的情感波动。
-
5. PyTorch与Tensor处理
-
PyTorch: 是一个开源的深度学习框架,用于训练和推理。它支持 GPU 加速,在这个项目中被用于执行 BERT 模型的推理任务。
-
torch.no_grad(): 在进行推理时,我们不需要计算梯度,因此可以通过torch.no_grad()来禁用梯度计算,以节省内存和计算资源。
六、代码评审
到这里,新增功能已经全部做完,最后我使用腾讯云AI的代码评审功能,最后检查一下我的代码:
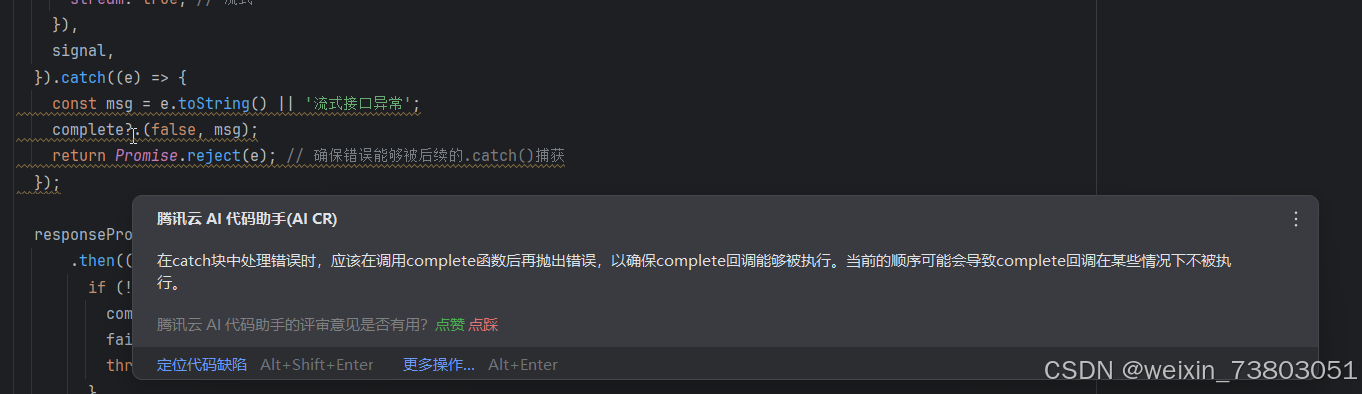
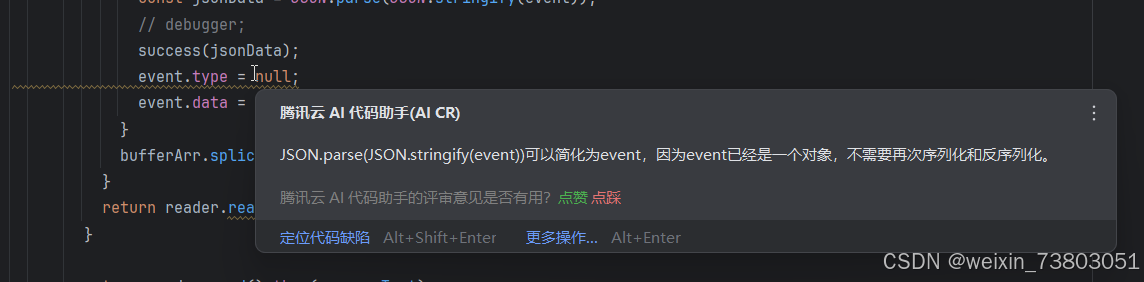
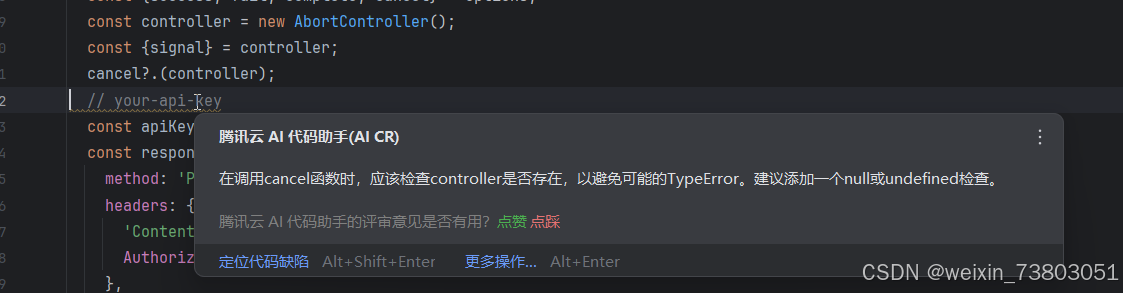
鼠标在代码上停留就能查看评审结构,确实写的不错,但是我都懒得改了(代码能跑就行)。
七、生成单元测试
我对项目的核心功能做了单元测试,生成的方式也很简单,选中想测试的代码后右击,选择生成单元测试就行:
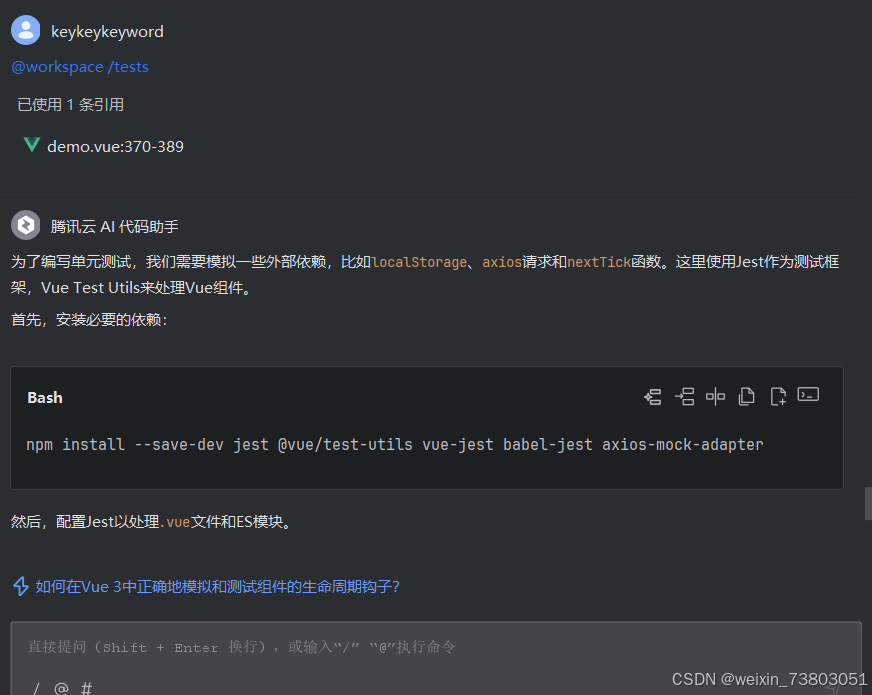
八、总结
以上的修改90%都是腾讯云AI代码助手实现的,另外还提供了这些功能:智能补全代码信息,精准修复错误代码,清晰解释既有代码,按需生成单元测试,人工智能技术对话,按RAG知识库查询。
腾讯云AI代码助手作为一个idea里的插件,在使用AI时不用在浏览器和idea之间来回切换,也不用把代码粘贴来粘贴去,可以在idea里完成一站式编程,极大地提高了编程的速度。
以下这几个操作是我最常用的:
在使用过程中先选中代码,然后再在右边对话框输入问题,这样可以让AI读到你的代码,如下:
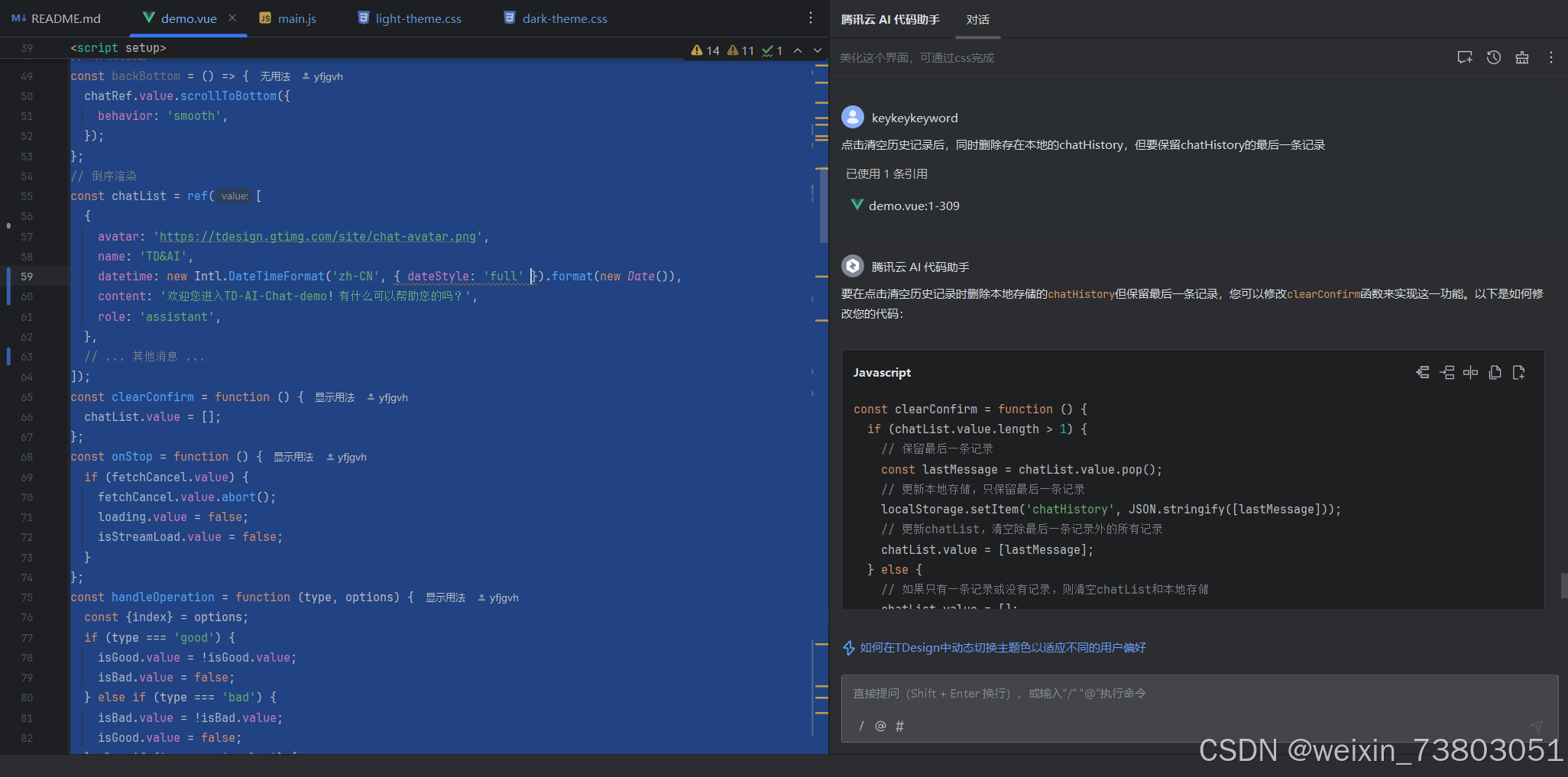
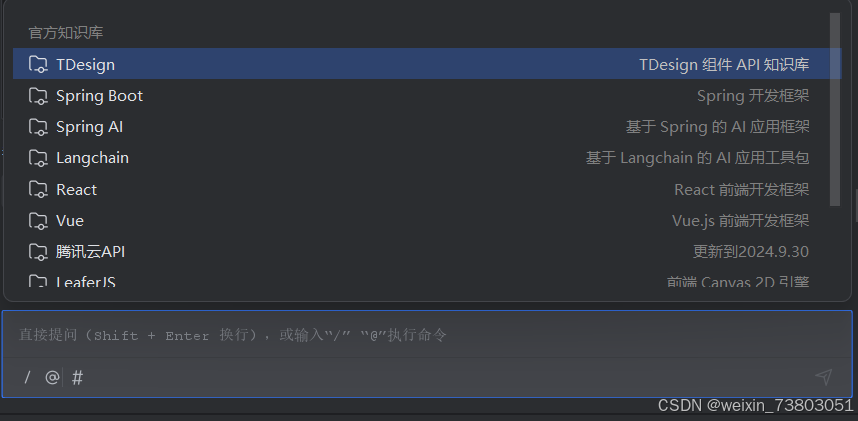
然后就是使用RAG知识库回答,选择对应的知识库后,回答准确率有明显提高:
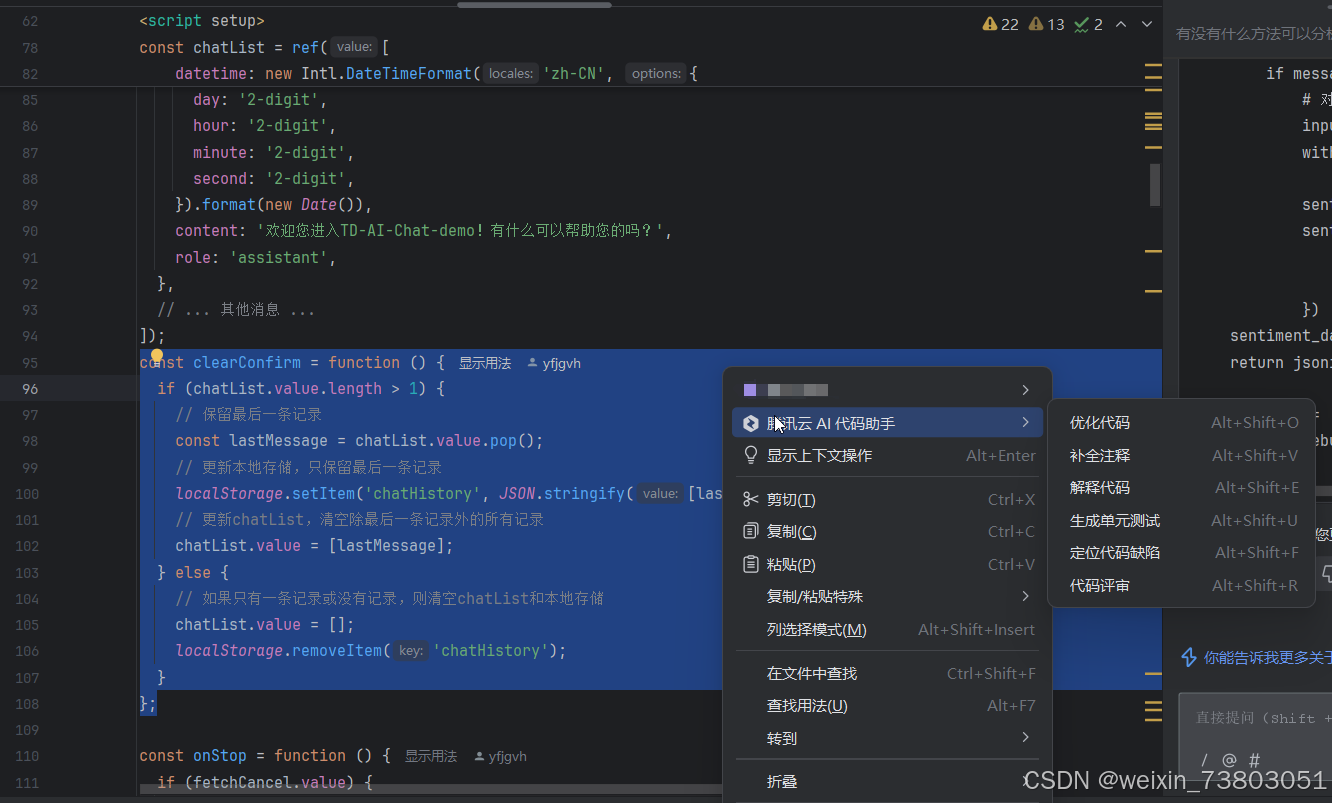
另外,在选择一段代码后右键,可以进行对选中代码的一系列问答:
以下是最终的项目演示视频。腾讯云AI代码助手编程挑战赛-“情声共鸣”演示视频-CSDN直播
九、使用方法
我已经把我的项目发送到gitee,有兴趣可以下载下来看看:yfjgvh/TD-AI
注意阅读我的README.md文件,里面有如何运行我的项目的详细说明。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









