






『Python | 预备基础』学海拾遗
- 本系列请配合 Jupyter Notebook & Pycharm 食用
- 本文适合novice
- 宕开一笔:Jupyter = Julia+ Python+R,与“木星(jupiter)“谐音,开发者Fernando Pérez旨在集合上述三种编程语言的平台
如何打开Jupyter Notebook?
- 在开始菜单中找到Anaconda3-Jupyter notebook,单击打开
- 系统会自动打开一个命令窗口,不要关闭,不要关闭,不要关闭!
- 同时打开浏览器,文件夹默认为Anaconda3所在根目录,故所需.ipynb应下载在同一目录下
- 新建.ipynb:右上角New,新建Python3文件

查看新文件的绝对路径:
在cell中输入
pwd
ls
基本使用方法
Getting Help:
#help(函数名)
help(print)
?int
查询“方法”:
a.sort?
Python使用**<变量名>=<表达式>**的方式来赋值变量
greeting="Hello Meruem!"
print(greeting)
- Python命名规则 Naming rules
- 开头:必须以字母或下划线(_),不能用数字。
- 变量名只能包含字母、数字和下划线。
- 大小写敏感,即变量名My和my是不同的。
- 使用有意义的单词,便于查看。
- 尽量使用驼峰命名法或下划线命名法,以提高代码的可读性。
存在NameError: name ‘Meruemm’ is not defined
数据类型
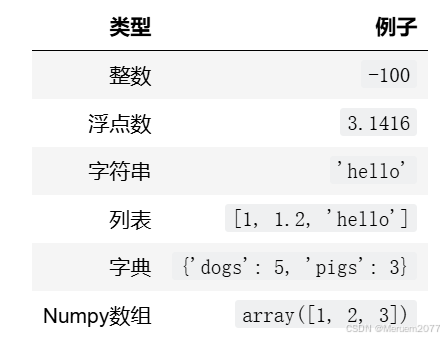
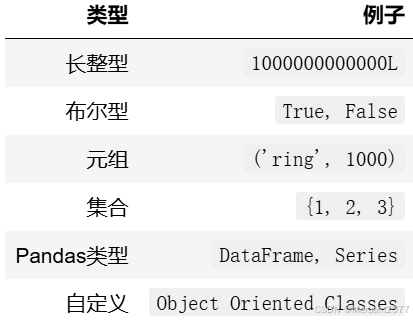
字符串string
简单操作
#索引
s='1234'
s[0]
>>>'1'
#连接
s = 'hello' + 'world'
>>>'helloworld'
m = 'hello'+' '+'world'
>>>'hello world'
#字符串与数字相乘:
"echo" * 3
#长度
len(s)
#查看type
type(s)
#添加空白
print('\npython\nR\nC++')
字符串方法
- 改变大小写
- .title()
- .upper()/.lower()
-
去除空格
.strip()
.lstrip()、.rstrip() -
切片+连接+替换
.split(seq)以给定的sep为分隔符对s进行分割,default:空格
line='1 2 3 4 5'
print(line.split())
sentence='1,2,3,4,5'
print(sentence.split(','))
['1', '2', '3', '4', '5']
['1', '2', '3', '4', '5']
s.join(str)的作用是以s为连接符将字符串序列str中的元素连接起来
number=','.join('12345')#将字符串各元素中间用‘,’连接
print(number)
>>>1,2,3,4,5
fomula='*'.join('12345')
print(fomula)
>>>1*2*3*4*5
string_var = "*".join(("lo", "ve", "!"))#拆分元组,将各元素用*连接,输出仍然是str
print(string_var)
type(string_var)
>>>lo*ve*!
>>>str
s.replace(A, B) part1替换成–>part2
即replace A to B
s = "hello world"
s.replace('world', 'python')
>>>'hello python'
print(S)
>>>"hello world"
需要注意的是,s 作为 str 不可变,只是临时输出了替换后的新字符串
其他方法
dir函数查看所有可以使用的方法:
dir(S)
[‘add’,
‘class’,
‘contains’,
‘delattr’,
‘dir’,
‘doc’,
'eq’等
格式化字符串 .format
{<参数序号>: <格式控制标记>}
<填充><对齐><宽度>,<.精度><类型>

print('{:.<10}{:.>20.2f}'.format("保险科技",100.12345))
print('{:.<10}{:.>20.2f}'.format("保险科技科技",10.12345))
print('{:.<10}{:.>20.2f}'.format("保险",1000.12345))
print('{:.<10}{:.>20.2f}'.format("科技",108.12345))
保险科技…100.12
保险科技科技…10.12
保险…1000.12
科技…108.12
'{} {} {}'.format('a', 'b', 'c')
'{2} {1} {0}'.format('a', 'b', 'c')
‘a,b,c’
‘c,b,a’
更复杂一点,引用变量
'{color} {n} {x}'.format(n=10, x=1.5, color='blue')
elements=['w','h','o']
'the first element is {el[0]}'.format(el=elements)
简化:使用f-string
name = 'Alan'
grade = '3'
f'hello,my name is {name},on grade {grade}'
##f大写也可以
F'hello,I am {name},on grade {grade}'
只会输出最新的f-string
'hello,I am Alan,on grade 3'
Because f-strings are evaluated at runtime, you can put any and all valid Python expressions in them. This allows you to do some nifty things.
f"{2*37}"
'74'
Numbers (int+float)
#取余%
#取商//
#四舍五入
round(3.43 - 3.2,1)
#绝对值
abs(-1.56)
#最大最小值
print(min(2, 3, 4, 5))
print(max(2, 4, 3))
0.2
1.56
2
4
List
有序
- 生成列表
- 加法&乘法(和字符串原理相同)
- 分片 [lower : upper : step]
不包括末尾值,== [ , ) ==
s = "hello world"
s[::-1]#仅能倒序字符串
‘dlrow olleh’
修改
# 把开头的 h 改成大写
s[0] = 'H'
#连续替换
s[1:3] = [1, 2]
#空格替换(即删除)
整段替换的方法,两者的元素个数并不需要相同,例如,将 [11,12] 替换为[1,2,3,4]
append()列表后面加元素l.insert(idx, var)在索引idx处插入var,之后的元素依次后移。- 删除
del(完全删除)l.remove(var)将列表中第一个出现的var删除,如果var不在 l 中会报错。l.pop(idx)会将索引 idx 处的元素**“弹出”,并且删除**,默认值为[-1]l.clear()
#删除第2到最后一个元素:
a = [1002, 'a', 'b', 'c']
del a[1:]
>>>[1002]
# 移除了第一个 11
s = [10, 11, 12, 13, 11]
s.remove(11)
>>>[10, 12, 13, 11]
# pop默认值
l= [10, 11, 12, 13, 11]
l.pop()
>>>[11]
#clear()清除
stock_name = ['浦发银行','招商银行','平安银行']
stock_name.clear()
>>>[]
列表内元素计数
a=['I','like','python','like','I']
a.count('I')
>>>2
- 索引

排序l.sort()
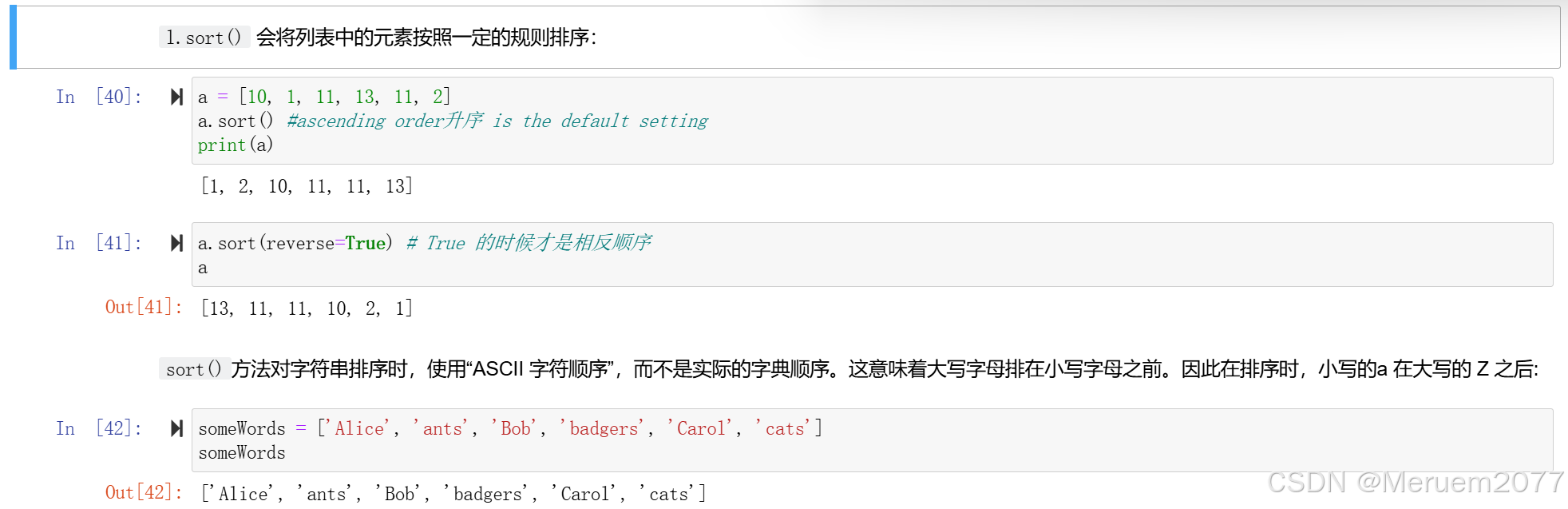
如果不想改变原来列表中的值,可以使用 sort ed 函数:

此时a依旧是a,新列表被存入b
反向
l.reverse() 会将列表中的元素从后向前排列

列表推导式
列表推导式相较于循环的效率更高,但占用内存较大。

END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









