






什么是ELK
ELK:
E:Elasticsearch 全文搜索引擎
L:logstash 日志采集工具
K:Kibana ES的可视化工具
ELK是当今业界非常流行的日志采集保存和查询的系统
我们编写的程序,会有很多日志信息,但是日志信息的保存和查询是一个问题
idea控制台是临时显示的位置,我们可以将它保存在文件中
但是即使保存在文件中,海量日志信息要想查询需要的条目也是问题
所以我们使用ELK来保存
为什么需要ELK
保存并能够快速便捷的查询查看日志信息就是新出现的需求了
ELK这个组合可以完成这个任务
Elasticsearch负责将日志信息保存,查询时可以按关键字快速查询
那么这些日志怎么收集呢?
利用logstash这个软件可以监听一个文件,将这个文件中出现的内容经过处理发送到指定端口
我们就可以监听我们程序输出的日志文件,然后将新增的日志信息保存到ES中
Kibana来负责进行查询和查看结果
日志的管理工具还有一套叫链路追踪
和ELK有类似的效果,感兴趣的同学可以自己搜索
Logstash
什么是logstash
Logstash是一款开源的日志采集,处理,输出的软件,每秒可以处理数以万计条数据,可以同时从多个来源采集数据,转换数据,然后将数据输出至自己喜欢的存储库中(官方推荐的存储库为Elasticsearch)
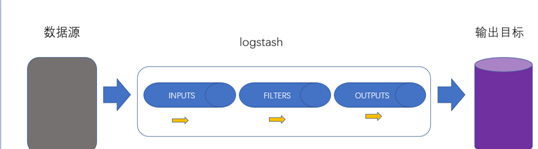
上面图片数据源可以是任何产生数据的介质,数据库,redis,java的日志文件均可
输出目标一般也是能够保存数据的媒体,数据库,redis,ES等
Logstash内部有3个处理数据的步骤
input 将数据源的数据采集到Logstash
filter (非必要)如果需要可以对采集到的数据进行处理
output 将处理好的数据保存到目标(一般就是ES)
其中采集数据的用法比较多样,还支持各种插件
logstash实现数据库和ES数据的同步
logstash还有一个非常常见的用法
就是能够自动完成数据库数据和ES中数据的同步问题
实现原理
我们可以配置logstash监听数据库中的某个表
一般设计为监听表中数据的变化,在规范的数据表结构中,logstash可能监听gmt_modified列
只要gmt_modified列数据有变化,就收集变化的数据行,将这行数据的信息更新到ES
下面我们就在虚拟机环境下实现搜索操作
实现虚拟机ES搜索功能
之前我们已经修改了yml文件,将搜索的目标更换为虚拟机中的ES
在虚拟机的连接环境中,我们使用SpuEntity来实现ES的连接
我们可以看到SpuEntity类中没有任何编写分词的属性
原因是为了更高效的实现分词,logstash将所有需要分词的列拼接组合成了一个新列search_text
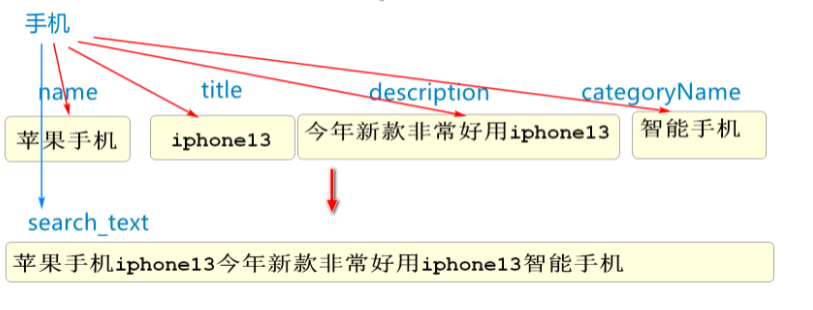
当需要查询时只需要查询search_text字段即可
添加新的持久层
在search-webapi模块中的repository包下,创建新的持久层接口SpuEntityRepository
@Repository
public interface SpuEntityRepository extends ElasticsearchRepository<SpuEntity,Long> {
// 要实现根据用户输入的关键字,查询ES中的商品列表
// logstash将所有商品的spu信息(name,title,description,category_name)拼接成了一个字段
// 这个字段叫search_text,我们搜索时只需要搜索这一个字段,就满足了之前设计的搜索需求
// 因为search_text字段并没有在SpuEntity中声明,所以不能用方法名称查询,只能使用查询语句
@Query("{\"match\":{\"search_text\":{\"query\":\"?0\"}}}")
Page<SpuEntity> querySearchByText(String keyword, Pageable pageable);
}Logstash下ES的运行流程
安装配置好相关软件后
logstash会自动监听指定的表(一般指定监听gmt_modified列)
当gmt_modified列值变化时,logstash就会收集变化的行的信息
周期性的向ES进行提交
数据库中变化的数据就会自动同步到ES中了
这样,我们在程序中,就无需编写任何同步ES和数据库的代码















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









