






为了使同学们使同学们尽可能地把精力放在研究更好的模型或更有效的数据预处理方法上,本帖分享了自编写的baseline代码以供参考;同时也是抛砖引玉,鼓励同学们积极分享自己在本赛题上的心得体会.以下是对原始文件的解释以及详细代码.
所有的外部库都是使用清华镜像源进行下载最新的版本,如果无法调用,请激活虚拟环境进行下载,示例命令行如下:
pip install numpy -U -i https://pypi.tuna.tsinghua.edu.cn/simple/model.py文件:其中包含了数据读取和预处理, 模型构建, 训练和测试模块,建议在实际使用时将这几个模块分开在多个.py文件中,增强项目可读性和可修改性.
import torch
from PIL import Image
import pandas as pd
import torchvision.models as models
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
from torch.utils.data.dataset import Dataset
# 根据自身实际调整参数
class Params():
data_dir = './train' # 数据集存储的位置
batch_size = 8 # 批处理大小,根据所用设备算力适当调整
train_data = pd.read_csv('train_labels.csv') # 文件路径-标签文档存储的路径
epoch_num = 1 # 训练轮数
learning_rate=1e-3
class Mydataset(Dataset):
def __init__(self, dataframe, transform=None):
self.data = dataframe
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, idx):
row = self.data.iloc[idx]
i = row['image']
img = Image.open(f'{Params.data_dir}/{i}').convert('RGB')
if self.transform is not None:
img = self.transform(img)
label=row['category_id']
return img, label
def __len__(self):
return len(self.data)
def train():
# 数据准备
dataset = Mydataset(Params.train_data,
transforms.Compose([transforms.Resize((64, 128)),
transforms.ToTensor()]))
# 随机划分数据集为训练集和测试集
test_ratio = 0.1
test_size = int(len(dataset) * test_ratio)
train_dataset, test_dataset = torch.utils.data. \
random_split(dataset, [len(dataset) - test_size, test_size])
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=Params.batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=Params.batch_size,
shuffle=True)
print('数据已就绪')
# 超参数的准备
if torch.cuda.is_available():
device="cuda"
print('将在GPU上训练')
else:
device="cpu"
print('将在CPU上训练')
epoch_num = Params.epoch_num
lr = Params.learning_rate
# 模型准备
model = models.resnet18(num_classes=10000).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr)
# 模型训练
for epoch in range(epoch_num):
running_loss = 0.0
num=1
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"第{epoch+1}轮训练,第{num}批次loss:{loss.item()}")
num+=1
epoch_loss = running_loss / len(train_loader)
print(f'--------第{epoch+1}轮训练完成---------')
print(f"Epoch [{epoch + 1}/{epoch_num}], Loss: {epoch_loss:.4f}")
print(f'---------模型已训练完成---------')
# 测试模型
try:
model.eval()
total_correct = 0
total_samples = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 此处将单标签修改为所有标签概率
total_samples += labels.size(0)
total_correct += (predicted == labels).sum().item()
test_accuracy = total_correct / total_samples
print(f"测试集准确率: {test_accuracy:.4f}")
except:
print('测试模型时发生异常!')
# 保存模型
try:
torch.save(model, 'Resnet.pt')
print('模型已保存')
except:
print('模型保存失败')
if __name__ == '__main__':
train()
pre.py文件:制作出基本的提交文件的模板(原始的submission_example文件仅有十行,只是用于参考文件的提交格式)
import pandas as pd
submit={'image': [],
'category_id': []}
submit=pd.DataFrame(submit)
sub=pd.read_csv('train_labels.csv')
submit['image']=sub['image'][:30000]
submit.to_csv('submit.csv', index=False)
answer.py文件:用于回答测试集并保存可提交结果
import torch
import pandas as pd
from PIL import Image
import torchvision.transforms as transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=torch.load('Resnet.pt').to(device) # 加载自己的模型
print(f'模型已加载到{device}上')
submit=pd.read_csv('submit.csv')
test_dir='./test' # 测试集保存路径
answer=[]
for idx in range(len(submit)):
row = submit.iloc[idx]
i = row['image']
transform = transforms.Compose(
[
transforms.Resize((64, 128)),
transforms.ToTensor()
]
) # 此处的预处理需要根据实际进行修改
# 将图片读取为张量
img = Image.open(f'{test_dir}/{i}').convert('RGB')
img_tensor=transform(img).to(device)
img_tensor=torch.unsqueeze(img_tensor, dim=0)
# 预测并保存结果
outputs = model(img_tensor)
_, predicted = torch.max(outputs.data, 1)
submit.loc[idx, 'category_id'] = int(predicted.tolist()[0])
print(f'第{idx+1}条问题已回答')
# 保存结果
submit.to_csv('submission.csv', index=False)
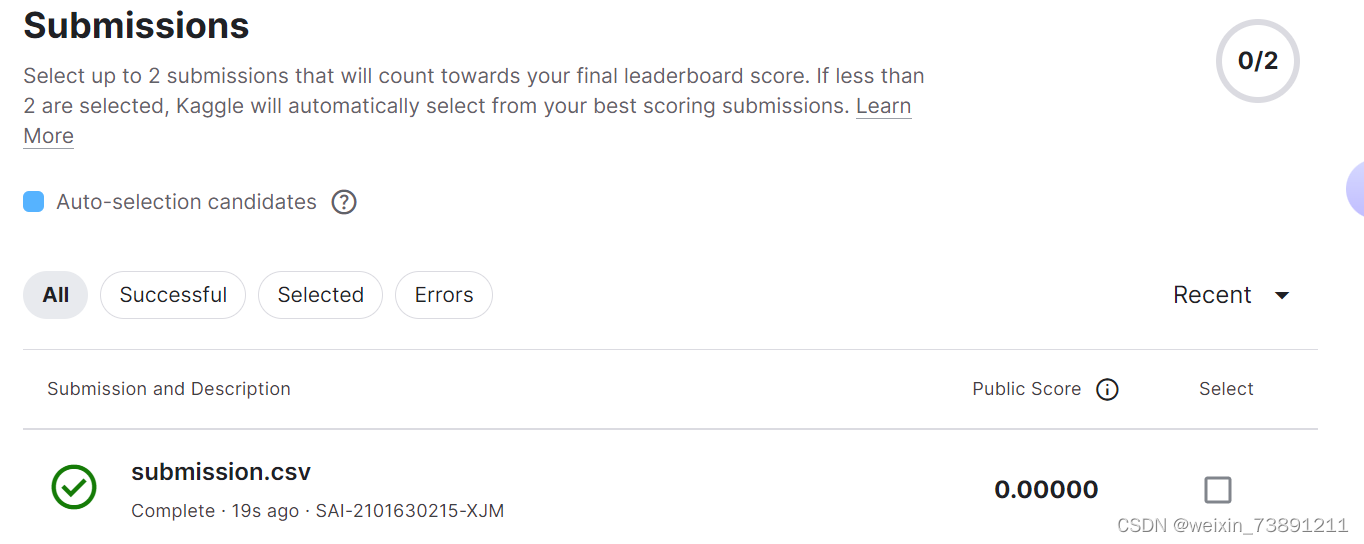
由于几乎没有进行数据预处理, 选择的模型又过于简单, 结果当然是惨不忍睹
不过一开始也说了, 本帖仅供参考, 不建议将本文的结果作为最终结果提交(应该也没人想交个零分上去吧/doge)
最后祝愿同学们能取得一个好名次, 顺利进行下周的任务!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









