






目录
一、简介
逻辑回归是一种广泛使用的统计方法,用于预测二元结果(是/否、成功/失败、阳性/阴性等)。尽管其名称包含“回归”,但逻辑回归实际上是一种分类方法,而不是回归方法。
二、概念
逻辑回归是一种广泛应用于分类问题的统计方法,特别是在处理二分类问题(即输出只有两个可能值的问题)时。它通过使用逻辑函数(也称为sigmoid函数)来估计一个事件发生的概率。
三、逻辑函数(Sigmoid函数)
1.函数定义
逻辑回归使用sigmoid函数将线性回归的输出映射到0和1之间的概率。sigmoid函数定义为:
其中,z 是特征的线性组合,可以通过以下公式计算:
在这个公式中, 是特征变量,而
是模型参数。
2.函数图像
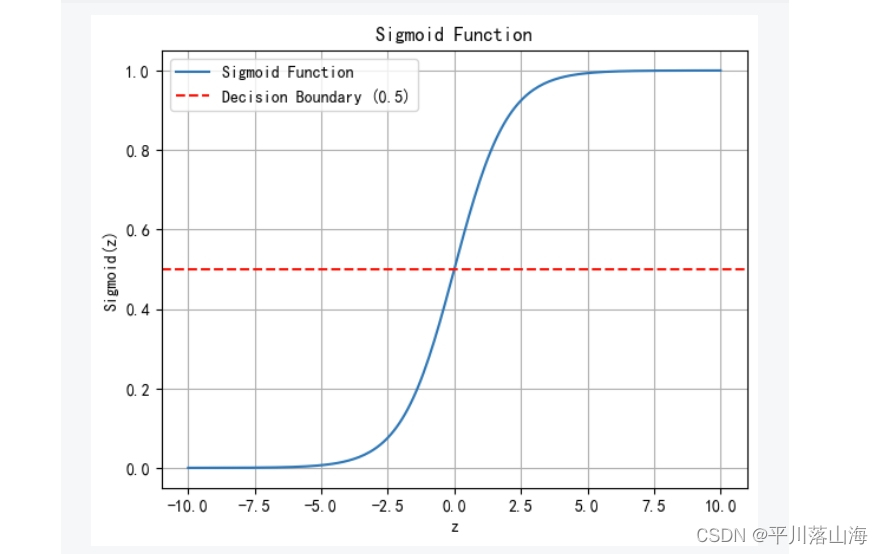
3.模型估计
逻辑回归模型的估计涉及找到最优的参数,使得模型能够最好地拟合训练数据。这通常通过最大似然估计来实现,即找到一组参数,使得观察到的数据出现的概率最大。
4.决策规则
逻辑回归使用一个简单的决策规则来对新的数据点进行分类:
- 如果
,则预测类别为1。
- 如果
,则预测类别为0。
5.模型训练
逻辑回归模型的训练通常涉及优化一个目标函数,如交叉熵损失函数,来估计模型参数。这个过程可以使用各种优化算法,如梯度下降法。
6.概率解释
逻辑回归的一个重要特性是它提供概率估计。sigmoid函数的输出可以直接解释为预测类别为1的概率
7.Sigmoid函数的特点
范围:Sigmoid函数的输出始终位于0和1之间,非常适合描述概率。
对称性:函数在 z = 0 处对称,即 S(0) = 0.5。
渐近线:随着 z增大,S(z) 接近1;随着 z 减小,S(z) 接近0。
单调性:函数在整个定义域上是单调增加的。
四、代码实现
1.逻辑回归部分
# 逻辑回归部分
from sklearn.linear_model import LogisticRegression
def train_logistic_regression(X, y):
"""
创建并训练逻辑回归模型
:param X: 特征数据
:param y: 标签数据
:return: 训练好的逻辑回归模型
"""
model = LogisticRegression()
model.fit(X, y)
return model2.数据集生成部分
# 数据集生成部分
from sklearn.datasets import make_classification
def generate_data():
"""
生成模拟数据集
:return: 特征数据集和标签数据集
"""
X, y = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2, random_state=42, n_clusters_per_class=1)
return X, y
3.总代码
# 逻辑回归部分
from sklearn.linear_model import LogisticRegression
def train_logistic_regression(X, y):
"""
创建并训练逻辑回归模型
:param X: 特征数据
:param y: 标签数据
:return: 训练好的逻辑回归模型
"""
model = LogisticRegression()
model.fit(X, y)
return model
# 数据集生成部分
from sklearn.datasets import make_classification
def generate_data():
"""
生成模拟数据集
:return: 特征数据集和标签数据集
"""
X, y = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2, random_state=42, n_clusters_per_class=1)
return X, y
# 图像生成部分
import numpy as np
import matplotlib.pyplot as plt
def plot_decision_boundary(model, X, y):
"""
绘制决策边界和数据点
:param model: 训练好的逻辑回归模型
:param X: 特征数据
:param y: 标签数据
"""
h = .02
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=.8)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o', cmap=plt.cm.Paired)
plt.title("逻辑回归决策边界")
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.show()
# 组合各部分并生成图像
X, y = generate_data()
model = train_logistic_regression(X, y)
plot_decision_boundary(model, X, y)
4.函数图像

五、优缺点分析
1.优点
简单明了:线性分类器的设计非常简单,只需要一个直线或超平面就可以将数据分为两类。
计算高效:线性分类器的计算复杂度相对较低,尤其是在大规模数据集上进行批量处理时。
可解释性:线性分类器的决策过程通常是透明的,易于理解和解释。
适用于某些场景:在某些特定的场景下,如当特征之间存在明显的线性关系时,线性分类器表现良好。
2.缺点
非线性可变性:线性分类器无法处理非线性的数据分布,这意味着它们可能无法捕捉到数据的复杂模式。
敏感性差:线性分类器对特征的变化不够敏感,可能导致分类不准确。
需要大量样本:线性分类器通常需要大量的样本才能达到较好的性能,特别是在类别不平衡的情况下。
鲁棒性差:线性分类器对噪声和异常值较为敏感,可能会影响其准确性。
六、总结
逻辑函数是一种非常重要和实用的函数,它提供了一种简单而有效的方法来处理概率估计和二分类问题。通过将输入值映射到0和1之间的概率,逻辑函数为多种统计模型和机器学习算法提供了基础。尽管逻辑函数具有一些局限性,但其在实际应用中的广泛性和有效性使其成为数据分析不可或缺的工具之一。















 4383
4383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









