







第一部分:基础含义
因子分析法(Factor Analysis)是一种多元统计分析方法,主要用于处理多个变量之间的相互关系,通过分析将高度相关的变量归纳为少数几个潜在的、不可观测的因子(也称为主成分或共同因子)。这些因子能够解释变量之间的相关性,从而简化数据结构。
具体例子:
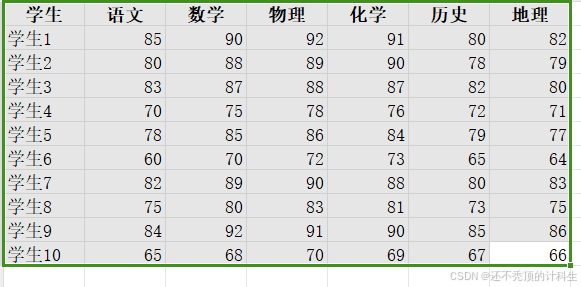
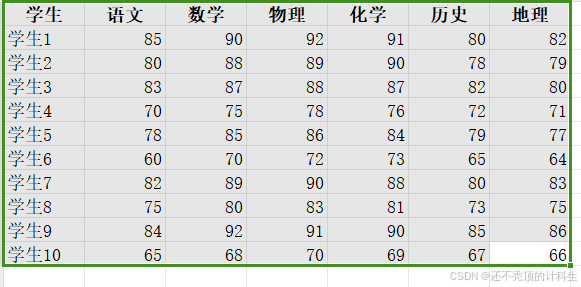
我们要分析是否可以将这些成绩归为"文科"(语文、历史、地理)和"理科"(数学、物理、化学)两个因子。
第二部分:核心思想过程并附python代码实现
(0)数据加载
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
# 读取数据
data = pd.read_excel('before.xlsx')
# Step (1): 构建判断矩阵
# 假设 data 中每一列代表一个指标,每一行代表一个样本
All_data = data.values
All_lebel = data.columns
print("判断矩阵:\n", All_data)
print("所有标签:\n", All_lebel)
Userful_All_data=(data.iloc[:, 1:])
Userful_All_lebel=All_lebel.drop(['学生'])#去掉学生这一列
print("除了第一个标签的所有数据:\n", Userful_All_data)
print("除了第一个标签的所有标签:\n", Userful_All_lebel)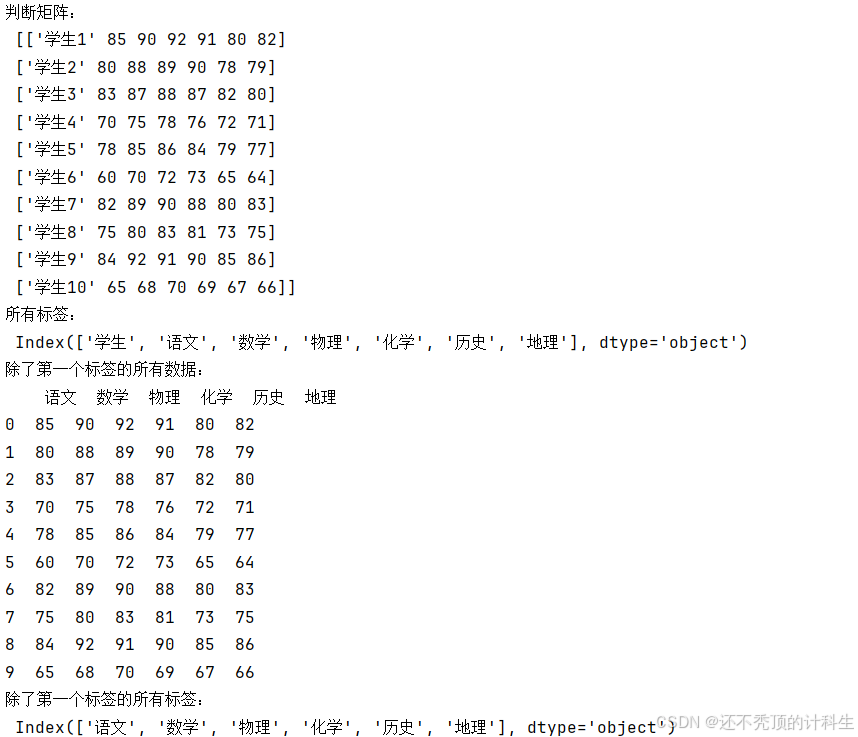 (1)相关性检验
(1)相关性检验
代码执行KMO和Bartlett检验,以检查数据是否适合进行因子分析。

- KMO 检验 主要衡量变量之间的相关性是否足够强。KMO 值越接近 1,数据越适合因子分析。
- Bartlett 球形检验 用于检验变量之间是否具有显著的相关性。显著性水平较低(例如 p < 0.05)则说明变量间存在显著相关性,可以进行因子分析。
# Step (1): 相关性检验
# ① KMO 检验
from factor_analyzer import calculate_kmo
kmo_all, kmo_model = calculate_kmo(Userful_All_data)
print("每个变量的 KMO 值:", kmo_all)
print("整体 KMO 值:", kmo_model)
# ② Bartlett 球形检验
from factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(Userful_All_data)
print("Bartlett 球形检验的卡方值:", chi_square_value)
print("Bartlett 球形检验的 p 值:", p_value)
if kmo_model > 0.7:
print("KMO 检验表明数据适合因子分析(KMO > 0.7)")
else:
print("KMO 检验表明数据可能不适合因子分析(KMO ≤ 0.7)")
if p_value < 0.05:
print("Bartlett 球形检验表明数据适合因子分析(p < 0.05)")
else:
print("Bartlett 球形检验表明数据可能不适合因子分析(p ≥ 0.05)")

如果计算KMO过程中出现nan,见我博客:
或者也可以用下面写的手动计算KMO和球形检验的方法:
#new
# Step (1): 手动计算 KMO 检验
# 计算相关矩阵
n, p = Userful_All_data.shape # 获取样本数量和变量数量
R = Userful_All_data.corr().values
# 计算反相关矩阵
inv_R = np.linalg.inv(R)
# 计算简单相关和偏相关矩阵的平方和
r_ij_sum = np.sum(R ** 2) - np.sum(np.diag(R) ** 2) # 去掉对角线元素
p_ij_sum = np.sum((inv_R / np.sqrt(np.outer(np.diag(inv_R), np.diag(inv_R)))) ** 2) - p # 去掉对角线元素
# 计算 KMO
KMO = r_ij_sum / (r_ij_sum + p_ij_sum)
print("整体 KMO 值:", KMO)
# Step (2): 手动计算 Bartlett 球形检验
# 计算相关矩阵的行列式
det_R = np.linalg.det(R)
# 计算卡方统计量
chi_square_value = -(n - 1 - (2 * p + 5) / 6) * np.log(det_R)
print("Bartlett 球形检验的卡方值:", chi_square_value)
# 通常在库中可以直接得到 p 值,在这里我们可以将计算的卡方值与卡方分布进行比较,以获得 p 值。
# 但没有库的情况下,需要查表获取p值,通常根据 chi_square_value 和自由度(df = p * (p - 1) / 2) 来判断
df = p * (p - 1) / 2 # 自由度
p_value = 1 # 这里p值是根据查表获得的,通常库可以自动生成
# 判断 KMO 值是否合适
if KMO > 0.7:
print("KMO 检验表明数据适合因子分析(KMO > 0.7)")
else:
print("KMO 检验表明数据可能不适合因子分析(KMO ≤ 0.7)")
# 判断 Bartlett 球形检验是否合适
if chi_square_value > 0 and p_value < 0.05:
print("Bartlett 球形检验表明数据适合因子分析(p < 0.05)")
else:
print("Bartlett 球形检验表明数据可能不适合因子分析(p ≥ 0.05)")(2)因子分析的步骤
代码的核心部分执行因子分析,以将科目划分为“文科”和“理科”。
①数据标准化
- 目的:对数据进行标准化,确保因子分析的尺度一致。
- 作用:使用
StandardScaler对数据进行标准化,使分析更加准确。
#2. 因子分析的步骤
from factor_analyzer import FactorAnalyzer
df = pd.DataFrame(Userful_All_data)
#步骤2.1:数据标准化
from sklearn.preprocessing import StandardScaler
# 创建标准化对象
scaler = StandardScaler()
# 对数据进行标准化
scaled_data = scaler.fit_transform(df)
print("标准化后的数据:")
print(scaled_data[:5])
# 创建一个标准化后的DataFrame
scaled_df = pd.DataFrame(scaled_data, columns=df.columns)
# 保存标准化后的数据为 Excel 文件
output_path = "标准化.xlsx"
scaled_df.to_excel(output_path, index=False)
print("已保存到:标准化.xlsx")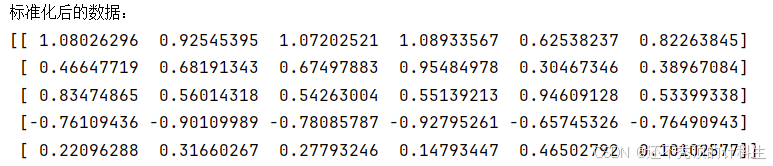 ②因子提取
②因子提取
#步骤2.2:因子提取
# 创建因子分析对象,指定提取2个因子
n_factors = 2
fa = FactorAnalyzer(n_factors, rotation=None) # 无旋转,即因子载荷矩阵未旋转
fa.fit(scaled_data) # 对标准化后的数据进行因子分析- 目的:提取两个主要因子(文科和理科)。
- 作用:初始化
FactorAnalyzer执行无旋转的因子分析,集中于找出主要的潜在因子。
③因子载荷矩阵
- 目的:在旋转前获取因子载荷。
- 作用:将初始因子载荷存储在
loadings_matrix中,以查看各科目对每个因子的影响。
#步骤2.3:因子载荷矩阵
# 获取因子载荷矩阵
loadings_matrix = fa.loadings_
loadings_df = pd.DataFrame(loadings_matrix, index=df.columns, columns=[f"Factor{i}" for i in range(1, n_factors+1)])
print("因子载荷矩阵:")
print(loadings_df)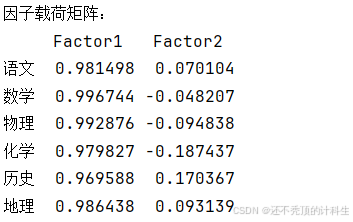
④因子旋转
- 目的:应用Varimax旋转以清晰地区分因子。
- 作用:Varimax旋转使各科目在文科和理科因子中的区分更清晰,便于解释。
#步骤2.4 进行因子旋转(使用Varimax方法)
fa_rotated = FactorAnalyzer(n_factors, rotation="varimax")
fa_rotated.fit(scaled_data) # 对标准化后的数据进行因子分析
loadings_matrix_rotated = fa_rotated.loadings_
loadings_df_rotated = pd.DataFrame(loadings_matrix_rotated, index=df.columns, columns=[f"Factor{i}" for i in range(1, n_factors+1)])
print("旋转后的因子载荷矩阵(Varimax):")
print(loadings_df_rotated)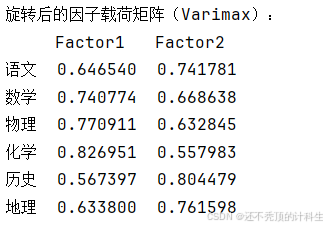
⑤解释因子
列出每个因子中载荷最高的科目,帮助基于因子分析结果将科目划分为文科和理科组(以载荷矩阵值0.7为标准分类)。
#步骤2.5:解释因子
# 解释因子
for i in range(1, n_factors + 1):
print(f"Factor {i}:")
high_loading_vars = loadings_df_rotated[f"Factor{i}"][loadings_df_rotated[f"Factor{i}"] >= 0.7].sort_values(ascending=False).index
low_loading_vars = loadings_df_rotated[f"Factor{i}"][loadings_df_rotated[f"Factor{i}"] < 0.7].sort_values().index
print(f"高载荷变量:{', '.join(high_loading_vars)}")
print(f"低载荷变量:{', '.join(low_loading_vars)}")

(3)完整pycharm代码
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
# 读取数据
data = pd.read_excel('before.xlsx')
# Step (1): 构建判断矩阵
# 假设 data 中每一列代表一个指标,每一行代表一个样本
All_data = data.values
All_lebel = data.columns
print("判断矩阵:\n", All_data)
print("所有标签:\n", All_lebel)
Userful_All_data=(data.iloc[:, 1:])
Userful_All_lebel=All_lebel.drop(['学生'])#去掉学生这一列
print("除了第一个标签的所有数据:\n", Userful_All_data)
print("除了第一个标签的所有标签:\n", Userful_All_lebel)
# Step (1): 相关性检验
# ① KMO 检验
from factor_analyzer import calculate_kmo
kmo_all, kmo_model = calculate_kmo(Userful_All_data)
print("每个变量的 KMO 值:", kmo_all)
print("整体 KMO 值:", kmo_model)
# ② Bartlett 球形检验
from factor_analyzer import calculate_bartlett_sphericity
chi_square_value, p_value = calculate_bartlett_sphericity(Userful_All_data)
print("Bartlett 球形检验的卡方值:", chi_square_value)
print("Bartlett 球形检验的 p 值:", p_value)
if kmo_model > 0.7:
print("KMO 检验表明数据适合因子分析(KMO > 0.7)")
else:
print("KMO 检验表明数据可能不适合因子分析(KMO ≤ 0.7)")
if p_value < 0.05:
print("Bartlett 球形检验表明数据适合因子分析(p < 0.05)")
else:
print("Bartlett 球形检验表明数据可能不适合因子分析(p ≥ 0.05)")
#2. 因子分析的步骤
from factor_analyzer import FactorAnalyzer
df = pd.DataFrame(Userful_All_data)
#步骤2.1:数据标准化
from sklearn.preprocessing import StandardScaler
# 创建标准化对象
scaler = StandardScaler()
# 对数据进行标准化
scaled_data = scaler.fit_transform(df)
print("标准化后的数据:")
print(scaled_data[:5])
#步骤2.2:因子提取
# 创建因子分析对象,指定提取2个因子
n_factors = 2
fa = FactorAnalyzer(n_factors, rotation=None) # 无旋转,即因子载荷矩阵未旋转
fa.fit(scaled_data) # 对标准化后的数据进行因子分析
#步骤2.3:因子载荷矩阵
# 获取因子载荷矩阵
loadings_matrix = fa.loadings_
loadings_df = pd.DataFrame(loadings_matrix, index=df.columns, columns=[f"Factor{i}" for i in range(1, n_factors+1)])
print("因子载荷矩阵:")
print(loadings_df)
#步骤2.4 进行因子旋转(使用Varimax方法)
fa_rotated = FactorAnalyzer(n_factors, rotation="varimax")
fa_rotated.fit(scaled_data) # 对标准化后的数据进行因子分析
loadings_matrix_rotated = fa_rotated.loadings_
loadings_df_rotated = pd.DataFrame(loadings_matrix_rotated, index=df.columns, columns=[f"Factor{i}" for i in range(1, n_factors+1)])
print("旋转后的因子载荷矩阵(Varimax):")
print(loadings_df_rotated)
#步骤2.5:解释因子
# 解释因子
for i in range(1, n_factors + 1):
print(f"Factor {i}:")
high_loading_vars = loadings_df_rotated[f"Factor{i}"][loadings_df_rotated[f"Factor{i}"] >= 0.7].sort_values(ascending=False).index
low_loading_vars = loadings_df_rotated[f"Factor{i}"][loadings_df_rotated[f"Factor{i}"] < 0.7].sort_values().index
print(f"高载荷变量:{', '.join(high_loading_vars)}")
print(f"低载荷变量:{', '.join(low_loading_vars)}")
第三部分:资源获取
通过网盘分享的文件:因子分析法.zip
链接: https://pan.baidu.com/s/1XbN9Sjy0tAhRqt5hZK5P6g?pwd=fjuh 提取码: fjuh
--来自百度网盘超级会员v5的分享



















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











