






KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。具体实现就是通过一个next数组现,数组本身包含了模式串的局部匹配信息。KMP算法的时间复杂度O(m+n)
P3375 【模板】KMP字符串匹配
题目描述
给出两个字符串 s1 和 s2,若 s1 的区间 [l,r] 子串与 s2 完全相同,则称 s2 在 s1 中出现了,其出现位置为 l。
现在请你求出 s2 在s1 中所有出现的位置。
定义一个字符串 ss 的 border 为 s 的一个非 s 本身的子串 tt,满足 t 既是 s 的前缀,又是 s 的后缀。
对于 s2,你还需要求出对于其每个前缀 s′ 的最长 border t′ 的长度。
输入格式
第一行为一个字符串,即为 s1。
第二行为一个字符串,即为s2。
输出格式
首先输出若干行,每行一个整数,按从小到大的顺序输出 s2 在 s1 中出现的位置。
最后一行输出∣s2∣ 个整数,第 i 个整数表示 s2 的长度为 i的前缀的最长 border 长度。
输入输出样例
输入 #1复制
ABABABC ABA
输出 #1复制
1 3 0 0 1
说明/提示
样例 1 解释
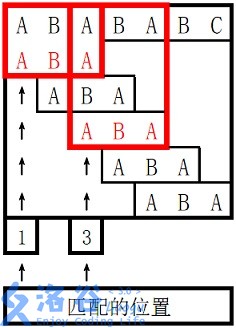
。
对于 s2 长度为 3 的前缀 ABA,字符串 A 既是其后缀也是其前缀,且是最长的,因此最长 border 长度为 1。
数据规模与约定
本题采用多测试点捆绑测试,共有 3 个子任务。
- Subtask 1(30 points):∣s1∣≤15,∣s2∣≤5。
- Subtask 2(40 points):∣s1∣≤10^4,∣s2∣≤10^2。
- Subtask 3(30 points):无特殊约定。
对于全部的测试点,保证 1≤∣s1∣,∣s2∣≤10^6,s1,s2 中均只含大写英文字母。
#include<stdio.h>
#include<string.h>
int next[500000];
char s1[500000],//字串;
s2[500000];//主串;
void kmp(char *s1,char *s2);
void getnext(char *s1,int *next);
int main()
{
int len;
scanf("%s\n%s",s2,s1);
len=strlen(s1);
getnext(s1,next);
kmp(s1,s2);
for(int i=0;i<len;i++)
printf("%d ",next[i]);
return 0;
}
void kmp(char *s1,char *s2)
{
int len1,len2,j=0;
len1=strlen(s1);
len2=strlen(s2);
for(int i=0;i<len2;i++)
{
while(j>0&&s1[j]!=s2[i])
j=next[j-1];//回退;
if(s1[j]==s2[i])
j++;
if(j==len1)
printf("%d\n",i-j+2);//找到后输出子串;
}
}
void getnext(char *s1,int *p)//构建next数组;
{
next[0]=0;
int len,j=0;
len=strlen(s1);
for(int i=1;i<len;i++)
{
while(j>0&&s1[i]!=s1[j])
j=next[j-1];//回退;
if(s1[i]==s1[j])
j++;
next[i]=j;//更新next数组;
}
}















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









