










 本文介绍了一个利用机器学习技术,特别是CatBoost库在数据挖掘实习项目中开发的民宿价格预测模型。模型考虑了物理属性、位置数据、客户互动指标、便利设施和房主信息等因素,通过特征工程和CatBoost的分类回归功能,对民宿价格进行精准预测。
本文介绍了一个利用机器学习技术,特别是CatBoost库在数据挖掘实习项目中开发的民宿价格预测模型。模型考虑了物理属性、位置数据、客户互动指标、便利设施和房主信息等因素,通过特征工程和CatBoost的分类回归功能,对民宿价格进行精准预测。
项目简介
随着旅游业的蓬勃发展,民宿市场迎来了前所未有的增长机遇。正好最近在参加拓尔思数据挖掘公益实习活动,我的项目将应用机器学习技术开发一个价格预测模型。可以达到更好地理解和预测民宿价格的目的,该模型综合考虑了从容纳人数、便利设施数量到房主回复率等一系列关键数据,目的在于评估并预测不同民宿的潜在价格。
通过分析包括民宿的物理属性(床铺、卧室与洗手间的数量等)、位置数据(维度、经度和邮编等)、客户互动指标(评论个数和房主回复率等)以及提供的便利服务和条件(互联网接入、厨房设施和其他基础设施等),模型旨在捕捉影响价格的各种因素。此外,模型还将探讨民宿的类型、所在城市、清洁费用及即时预订支持等对价格可能产生的影响。最后,通过考察房主的在线呈现,如是否有个人资料图片及身份验证,进一步完善模型预测的准确性。
项目采用CatBoost对数据进行分析,CatBoost(Categorical Boosting)是由 Yandex 开发的一个开源机器学习库,基于梯度提升决策树(Gradient Boosted Decision Trees, GBDT)算法的一种实现,专为处理分类(Categorical)数据而设计,同时也可以完成一些回归任务。CatBoost 可以提供高性能、可扩展性和精确度,尤其运用在是在具有很多类别特征的数据集上表现突出。
数据总览
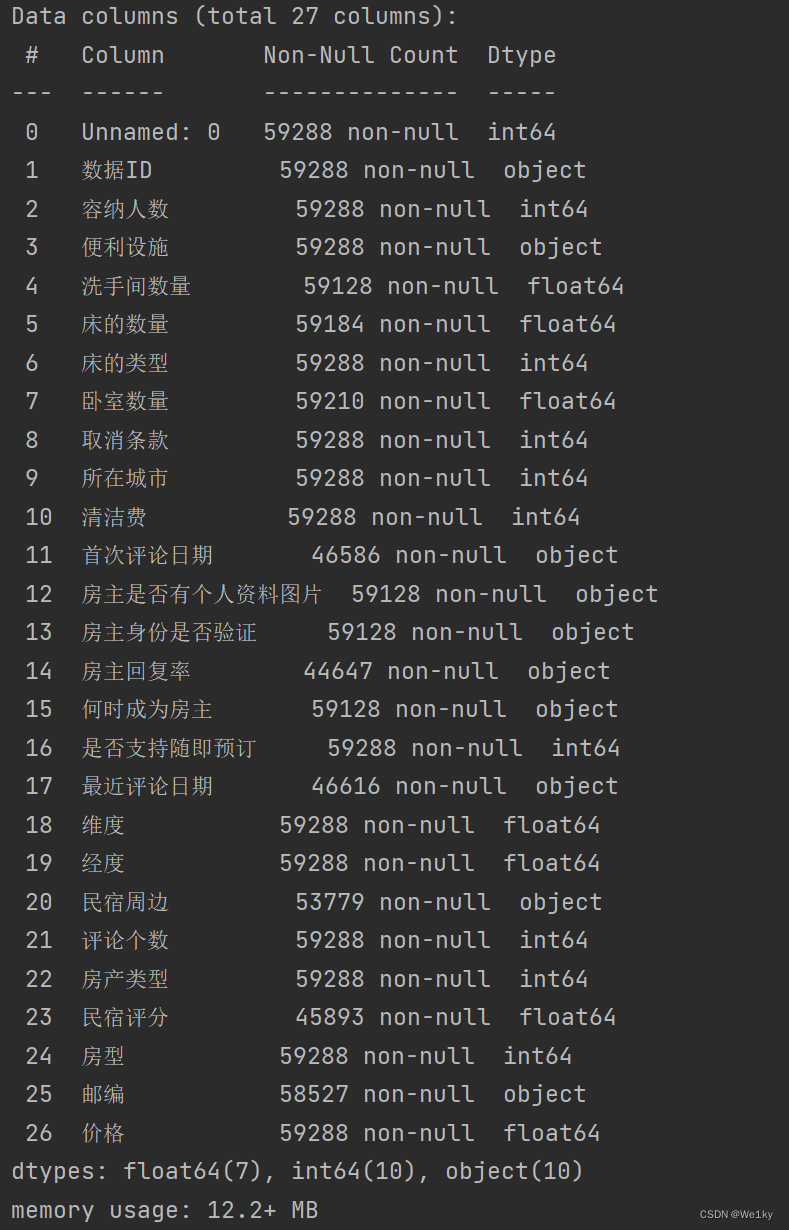
文件包括"train.csv"和"test.csv"两个文件,下面是"trian.csv"的大致含有的特征内容:
代码分析
导入相关python库和数据
# 导入相关库
import pandas as pd
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from catboost import CatBoostRegressor, Pool
from sklearn.metrics import mean_squared_error,r2_score
import warnings
# options
warnings.filterwarnings('ignore')#这行命令将会忽略python警告信息,使得输出结果更加清晰,不被警告打扰。
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)#用来确保在输出DataFrame时能显示所有的行和列。
# 加载数据集
train = pd.read_csv('./train_data.csv')
test = pd.read_csv('./test_data.csv')
# 数据探索
train.info()
train.head()
train.info(),会显示关于DataFrame的一些基本信息,如:列名、非空值数量、每列的数据类型。
train.head(),会显示DataFrame的前几行数据,默认情况下是前5行。这对于快速查看数据集的样本数据以及确保数据被正确加载也是很有用的。
特征工程处理
#添加新特征:便利设施数量
train['便利设施_num'] = train['便利设施'].str.split(',')
int_equipments = []
for item in train['便利设施_num']:
num = len(item)
int_equipments.append(num)
train['便利设施_num'] = int_equipments
test['便利设施_num'] = test['便利设施'].str.split(',')
int_equipments_test = []
for item in test['便利设施_num']:
num = len(item)
int_equipments_test.append(num)
test['便利设施_num'] = int_equipments_test
# 分割'便利设施'
for key_words in ['Internet', 'Kitchen', 'Pets', 'Air', 'Washer', 'Aid', 'Heating', 'Dryer', 'Essentials', 'Hangers','TV','parking', '24-hour']:
train[key_words] = train['便利设施'].str.contains(key_words).astype('str')
test[key_words] = test['便利设施'].str.contains(key_words).astype('str')
# '民宿周边'特征
train['民宿周边'] = train['民宿周边'].fillna(-999) #将NaN填充指定值
test['民宿周边'] = test['民宿周边'].fillna(-999)
surround_train = []
for value in train['民宿周边']:
if value == -999:
new_value = 0
else:
new_value = 1
surround_train.append(new_value)
train['民宿周边'] = surround_train
surround_test = []
for value in test['民宿周边']:
if value == -999:
new_value = 0
else:
new_value = 1
surround_test.append(new_value)
test['民宿周边'] = surround_test
#'房主是否有个人资料图片'和'房主身份是否验证'特征
train['房主是否有个人资料图片'] = train['房主是否有个人资料图片'].fillna('f')
test['房主是否有个人资料图片'] = test['房主是否有个人资料图片'].fillna('f')
train['房主身份是否验证'] = train['房主身份是否验证'].fillna('f')
test['房主身份是否验证'] = test['房主身份是否验证'].fillna('f')
str_cols = ['Internet', 'Kitchen', '房主是否有个人资料图片', '房主身份是否验证', 'Air', 'Pets', 'Washer', 'Aid',
'Heating', 'Dryer','Essentials', 'Hangers', 'TV', 'parking', '24-hour']
le = LabelEncoder()
for col in str_cols:
train[col] = le.fit_transform(train[col])
test[col] = le.fit_transform(test[col])
# '房主回收率'特征
train['房主回复率'] = train['房主回复率'].fillna('20%')
test['房主回复率'] = test['房主回复率'].fillna('20%')
train['房主回复率'] = train['房主回复率'].str[:-1]
#去除数据中的‘%’
test['房主回复率'] = test['房主回复率'].str[:-1]
# '首次评论日期'特征
train['首次评论日期'] = train['首次评论日期'].fillna('2019-1-1')
test['首次评论日期'] = test['首次评论日期'].fillna('2019-1-1')
train['最近评论日期'] = train['最近评论日期'].fillna('2019-1-1')
test['最近评论日期'] = test['最近评论日期'].fillna('2019-1-1')
time_cols = ['首次评论日期', '最近评论日期', '何时成为房主']
for col in time_cols:
train[col] = pd.to_datetime(train[col])
test[col] = pd.to_datetime(test[col])
# '邮编'特征
train['邮编'] = train['邮编'].fillna(0)
test['邮编'] = test['邮编'].fillna(0)
train['邮编'] = train['邮编'].astype('str')
test['邮编'] = test['邮编'].astype('str')
# 特征处理:将特征分为连续变量和分类变量,分别处理
cols = train.columns
cont_cols = ['容纳人数', '便利设施_num', '床的数量', '卧室数量', '洗手间数量', '维度', '经度', '评论个数', '民宿评分','房主回复率']
cate_cols=['邮编','Internet','Kitchen','Air','Pets','Washer','Aid','Heating','Dryer','Essentials','Hangers',"TV",'parking',
'24-hour','床的类型','民宿周边','取消条款','所在城市','清洁费','是否支持随即预订','房产类型','房型','房主是否有个人资料图片', '房主身份是否验证']
#定义了两个列表,分别包含了连续型特征列和分类型特征列的列名
#其他离散型特征的处理
features = cont_cols + cate_cols
train[cate_cols] = train[cate_cols].astype('category')
test[cate_cols] = test[cate_cols].astype('category')
#将训练集和测试集中的分类型特征列的数据类型转换为 'category' 类型。
for col in cate_cols:
train[col]=train[col].fillna(train[col].mode())
test[col] = test[col].fillna(test[col].mode())
#对分类型特征列中的缺失值进行填充,填充的值为该列的众数(mode)。
for col in ['洗手间数量','床的数量','卧室数量','民宿评分']:
train[col]=train[col].fillna(train[col].median())
test[col] = test[col].fillna(test[col].median())
#对指定的连续型特征列中的缺失值进行填充,填充的值为该列的中位数(median)。
train=train.dropna().reset_index()
#特征缩放:其他连续型特征的处理
X_train=train[features]
scaler=RobustScaler()
scaler.fit(X_train[cont_cols])
#使用训练集中的连续型特征列来拟合RobustScaler对象。
X_train[cont_cols]=scaler.transform(X_train[cont_cols])
X_test=test[features]
X_test[cont_cols]=scaler.transform(X_test[cont_cols])
y_train=train['价格'].astype('int')
DateFrame[colum].str.contains(key_words)
方法在列colum中查找是否包含特定关键词 key_words,返回一个布尔类型的 Series。
astype(‘str’)
将项目中上一步生成的布尔类型的 Series 转换为字符串类型,将 True 和 False 分别转换为 ‘True’ 和 ‘False’ 字符串。
LabelEncoder()
LabelEncoder()是sklearn的内容,le = LabelEncoder(),实例化一个LabelEncoder对象,用于对分类特征进行编码。
fit_transform()
fit_transform() 方法会先对指定的列数据进行拟合,然后进行实际的转换操作。在这个过程中,LabelEncoder 会根据指定列的值建立编码规则,并将分类特征转换为数值编码。
to_datetime()
Pandas中的函数,将DataFrame中的当前列col中的日期时间字符串转换为 Pandas datetime 类型。
dropna()
删除训练集中的所有包含缺失值的行
reset_index()
重置 DataFrame 的索引。
RobustScaler()
scaler=RobustScaler(),这行代码实例化了一个 RobustScaler 对象,用于后续的特征缩放。RobustScaler 是一种对异常值有鲁棒性的缩放器,它使用中位数和四分位数范围来缩放特征。
模型训练和拟合
#划分数据集
X_train,X_valid,y_train,y_valid=train_test_split(X_train,y_train,random_state=1025,test_size=0.2)
train_pool=Pool(X_train,y_train,cat_features=cate_cols)
eval_pool=Pool(X_valid,y_valid,cat_features=cate_cols)
#两行代码创建了两个CatBoost数据池,一个用于训练,一个用于评估。
model=CatBoostRegressor()
#实例化CatBoostRegressor对象,用于后续的模型训练。
model.fit(train_pool,eval_set=eval_pool)
#使用训练数据池进行模型训练,并设置了评估数据集。
y_pred_valid=model.predict(X_valid)
#使用训练好的模型对验证集进行预测,将结果存储在y_pred_valid中
print(y_pred_valid)
result_df=X_valid.copy()
result_df['价格']=y_valid
result_df['预测价格']=y_pred_valid
#创建一个新的DataFrame,将实际值、预测值和特征重新集合
result_df.head()
模型评价
mse=mean_squared_error(y_valid,y_pred_valid) #均方误差
r2=r2_score(y_valid,y_pred_valid) #r2系数
print('mse的值为:',mse)
print('r2的值为:',r2)
模型使用
predictions=model.predict(X_test)
#使用训练好的模型对测试集进行预测
new_results_df=X_test.copy()
new_results_df['预测价格']=predictions
new_results_df.head()
#同训练集,构建出测试集DataFrame
结果展示



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









