






python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
作用:模拟浏览器发送请求
如何使用requests模块
requests模块编码流程:
- 指定URL(访问浏览器时需要输入具体的网址)
> URL:是web页的地址,这种地址会在浏览器顶部附近的Location或者URL框内显示出来。由两个主要的部分构成:协议(Protocol)和目的地(Destination)。更具体的在<https://zhuanlan.zhihu.com/p/352034056>
- 发起请求(get/post)?https://blog.csdn.net/qq_41547882/article/details/107369980#:~:text=HTTP%20%E7%9A%84%20%E5%85%AB%E5%A4%A7%E8%AF%B7%E6%B1%82%E6%96%B9%E5%BC%8F%201%201.%20GET%20GET%20%E5%8A%A8%E4%BD%9C%EF%BC%9A%E7%94%A8%E4%BA%8E,...%207%207.%20OPTIONS%20...%208%208.%20CONNECT
- 获取响应数据(源码数据?)
- 持久化存储响应数据
案例编写
环境安装:`pip install requests`
实战编码:
- -需求:爬取搜狗首页的页面数据
import requests
if __name__ == '__main__':
#指定URL
url = 'https://www.taobao.com/'
#发起请求
#get方法会返回一个响应对象
response = requests.get(url)
#获取相应数据(在响应对象中)
text = response.text;#获得的是当前网址页面对应的HTML源码数据,以字符串的形式展示
print(text)
#持久化存储
with open('./taobao.html','w',encoding='utf-8') as fp:
fp.write(text)
print('爬取结束')- 爬取搜狗指定词条对应的搜索结果页面(简易网页采集器)
import requests
if __name__ == '__main__':
headers = {#设置请求头,使用了UA伪装技术
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
url = 'https://www.sogou.com/web'
kw = input('enter a word:')
param = {
'query':kw
}
response = requests.get(url=url,params=param,headers=headers)
text = response.text
fileName = kw+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(text)
print(fileName+' is finished!')> UA:User-Agent表示请求载体的身份标识
> UA检测:门户网站的服务器会检测对应请求的载体身份标识。如果检测到请求的身份标识为普通的浏览器则说明该请求是一个正常的请求。否则,该请求是一个爬虫请求。
> UA伪装:爬虫程序使用普通浏览器的UA,就能将爬虫伪装成浏览器
- 破解百度翻译
> AJAX:异步的JavaScript和Xml。<font color = purple>局部刷新界面</font><https://zhuanlan.zhihu.com/p/644908762#>
> 在百度翻译的页面中,输入一个字母就会获得一个AJAX请求,是POST请求,也就是输入一个字母那块区域就会进行一个刷新操作,所以只需要获取最终输入单词的Ajax请求就可以了<font color = purple>如果在一个网页进行输入或者点击发起一个时间,地址栏的URL没有变化,那就是一个Ajax请求,反之则不是</font>
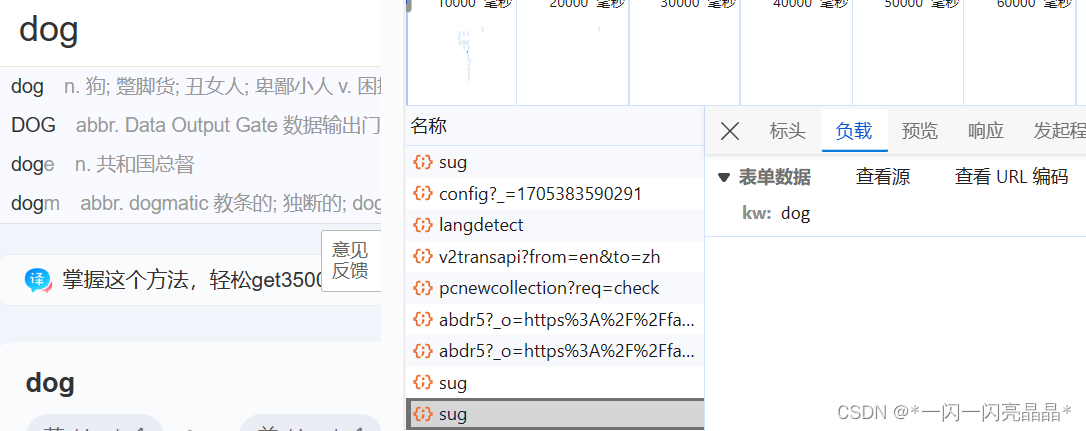
> POST请求(携带了参数kw)
> 响应数据是一组JSON数据(单词对应的翻译结果)
import requests
import json
if __name__ == '__main__':
#1.指定URL
url = 'https://fanyi.baidu.com/sug'
#2.UA伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
#3.输入参数
kw = input('enter a word')
data = {
'kw':kw
}
#4.发送POST请求
reponse = requests.post(url=url,data=data,headers=headers)
json_obj = reponse.json()#响应的数据是JSON类型可以在网站里超找到的
print(json_obj)
#5.持久化JSON对象
fp = open('./'+kw+'.json','w',encoding='utf-8')
json.dump(json_obj,fp,ensure_ascii=False)#中文用ASCII会乱码
print('finished!!!')- 豆瓣电影分类排行榜
<https://movie.douban.com/>中的电影详情数据
import requests
import json
if __name__ == '__main__':
url = 'https://movie.douban.com/j/chart/top_list'
#?type=24&interval_id=100%3A90&action=&start=200&limit=20把后面的参数封装到一个字典中
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
params = {
'type':'24',
'interval_id':'100:90',
'action':'',
'start':'1',#从库中的第几部电影去取#可以动态输入这两个参数
'limit':'20'#一次取出的个数
}
response = requests.get(url=url,params=params,headers=headers)
json_obj = response.json()
fp = open('./豆瓣电影.json','w',encoding='utf-8')
for str in json_obj:
print(str)
json.dump(str,fp,ensure_ascii=False)
fp.write('\n')- 作业:爬取肯德基餐厅查询<http://www.kfc.com.cn/kfccda/index.aspx>中指定地点的餐厅数量
import requests
import json
if __name__ == '__main__':
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0'
}
location = input('输入一个地址')
data = {
'op':'keyword',
'cname':'',
'pid':'',
'keyword':location,
'pageIndex':'1',
'pageSize': '3'
}
response = requests.post(url=url, data=data, headers=headers)
json_obj = response.json()
# print(json_obj)
# fp = open('./' + location + '.json', 'w', encoding='utf-8')
# json.dump(json_obj, fp, ensure_ascii=False) # 中文不能使用ASCII码编码
print(location+'总共有'+str(json_obj['Table'][0]['rowcount'])+'家肯德基')
print('finished!!!')查看参数: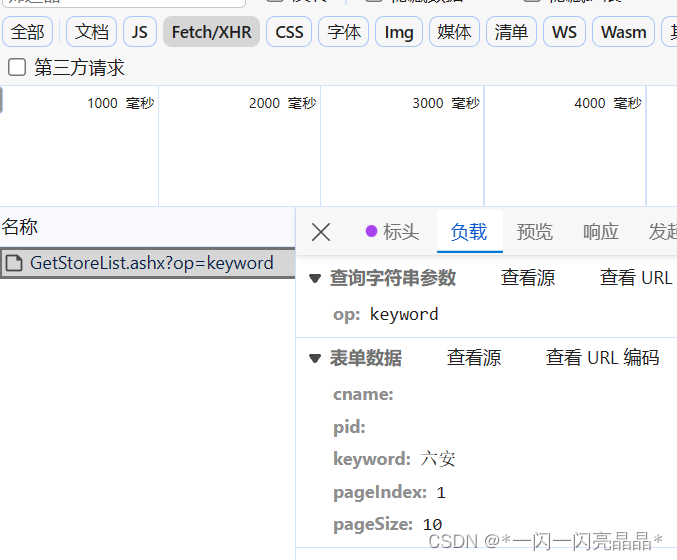
查看响应数据: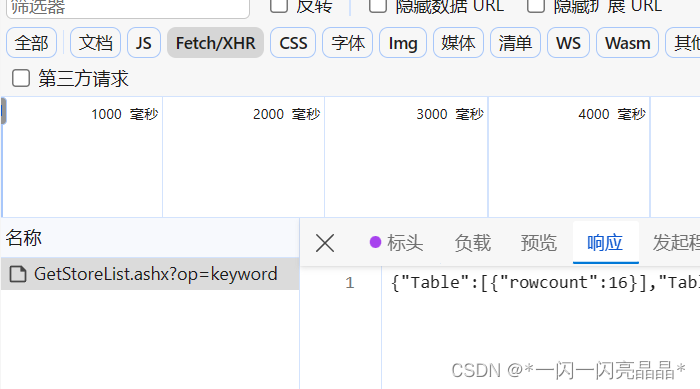
- 需求:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据<http://125.35.6.84:81/xk/>(这个网站现在已经不在了,理解思路就行)
import requests
import json
if __name__=='__main__':
#是一个主页面的Ajax请求用于获取所有子页面的相关信息(子页面不是一开始就有的,它也是通过Ajax请求才有的
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
#封装参数
data = {
'on':'true',
#.........
'page':'1',#加个循环就能够获得所有企业的id
'pageSize':'15
}
headers = {
'User-Agent':'......'
}
id_list = []#存储企业的id(用于获得不同企业的Ajax请求)
all_data_list = []#存储所有的企业详情数据
json_ids = requests.post(url,headers,data).json()
for dic in json_ids['list']:
id_list.append(dic['ID'])
#获取企业详情信息
post_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=......'
#应该给企业页面的Ajax传递的参数就是从主页面Ajax请求中获取的id参数
for id in id_list:
data = {#POST请求对应的参数
'id':id
}
detail_json = requests.post(url = post_url,headers = headers,data = data).json#每家企业的详情数据
all_data_list.append(detail_json)
#持久化存储所有企业的详情信息
fp = open('./allData.json','w')
json.dump(all_data_list,fp,ensure_ascii=False)发起的请求携带参数时才需要传入参数















 1094
1094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









