






文章目录
排序的概念
排序:将一组杂乱无章的数据按一定规律顺次排序起来。即,将无序序列排成一个有序序列(由小到大或由大到小)的运算
排序方法分类:

按存储介质分为:
- 内部排序:数据量不大,数据在内存,无需内外存交换数据
- 外部排序:数据量较大,数据在外存(文件排序);外部排序时,要将数据分批调入内存来排序,中间结果还要及时放入内存,显然外部排序要复杂得多
按比较器个数分为:
- 串行排序:单处理机(同一时刻比较一对元素)
- 并行处理:多处理机(同一时刻比较多对元素)
按主要操作分为:
-
比较排序:用比较的方法,插入排序,交换排序,选择排序,归并排序
-
基数排序:不比较元素的大小,仅仅根据元素本身的取值确定其有序位置
按辅助空间分为:
-
原地排序:辅助空间用量为O(1)的排序方法(所占的辅助空间与参加排序的数据量大小无关)
-
非原地排序:辅助空间用量超过O(1)的排序方法
按稳定性分为:
- 稳定排序:能够使任何数值相等的元素,排序以后相对次序不变
- 非稳定性排序:不是稳定排序的方法
按自然性分为:
- 自然排序:输入数据越有序,排序的速度越快的排序方法1
- 非自然排序:不是自然排序的方法
按排序依据原则:
- 插入排序:直接插入排序,折半插入排序,希尔排序
- 交换排序:冒泡排序,快速排序
- 选择排序:简单选择排序,堆排序
- 归并排序:2-路归并排序
- 基数排序
按排序所需工作量:
- 简单的排序方法: T(n)=O(n2)
- 基数排序:T(n)=O(d.n)
- 先进的排序方法:T(n)=O(nlogn)
存储结构
记录序列以顺序表存储
#define MAXSIZE 20 //设记录不超过20个
typedef int KeyType; //设关键字为整型量(int型)
Typedef struct{ //定义每个记录(数据元素)的结构
int key; //关键字
InfoType otherinfo; //其他数据项
}RedType;
Typrdef struct{ //定义顺序表的结构
RedType r[MAXSIZE+1]; //存储顺序表的向量,r[0]一般作哨兵或缓冲区
int length; //顺序表的长度
}SqList;
一. 插入排序
基本思想:每步将一个待排序的对象,按其关键码大小,插入到前面已经排好序的一组对象的适当位置上,直到对象全部插入为止。
即边插入边排序,保证子序列中随时都是排好序的

基本操作:有序插入
- 在有序序列中插入一个元素,保持序列有序,有序长度不断增加
- 起初,a[0]是长度为1的子序列。然后,逐一将a[1]至a[n-1]插入到有序子序列中
有序插入方法:
- 在插入a[i]前,数组a的前半段(a[0]-a[i-1])是有序段,后半段(a[i]~a[n-1])是停留于输入次序的”无序段“
- 插入a[i]使a[0]~a[i-1]有序,也就是要为a[i]找到有序位置j(0<=j<=i),将a[i]插入在a[j]的位置上
插入位置图示:
(a)插在中间
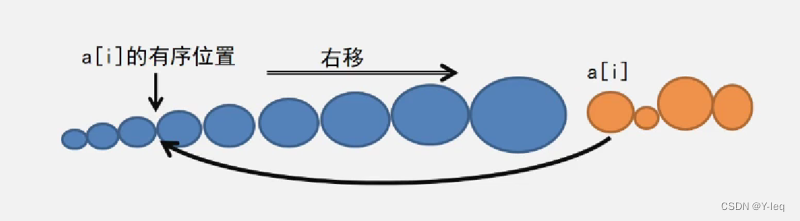
(b)插在最前面
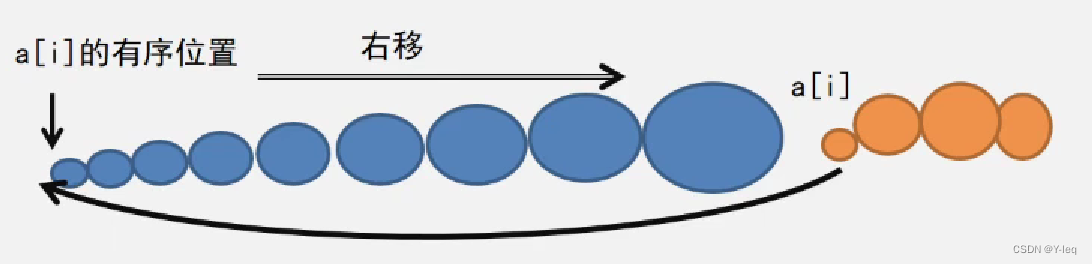
(c)插在最后面
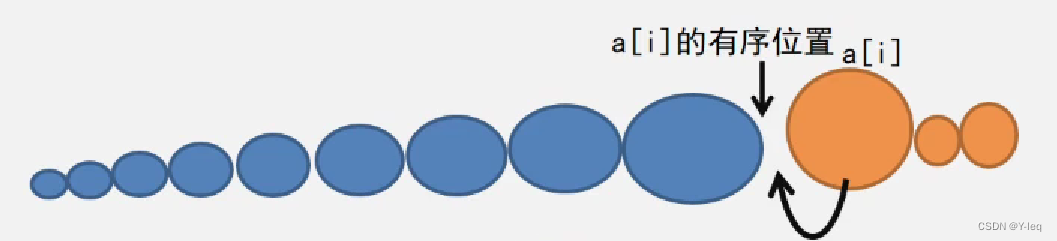
插入排序的种类:
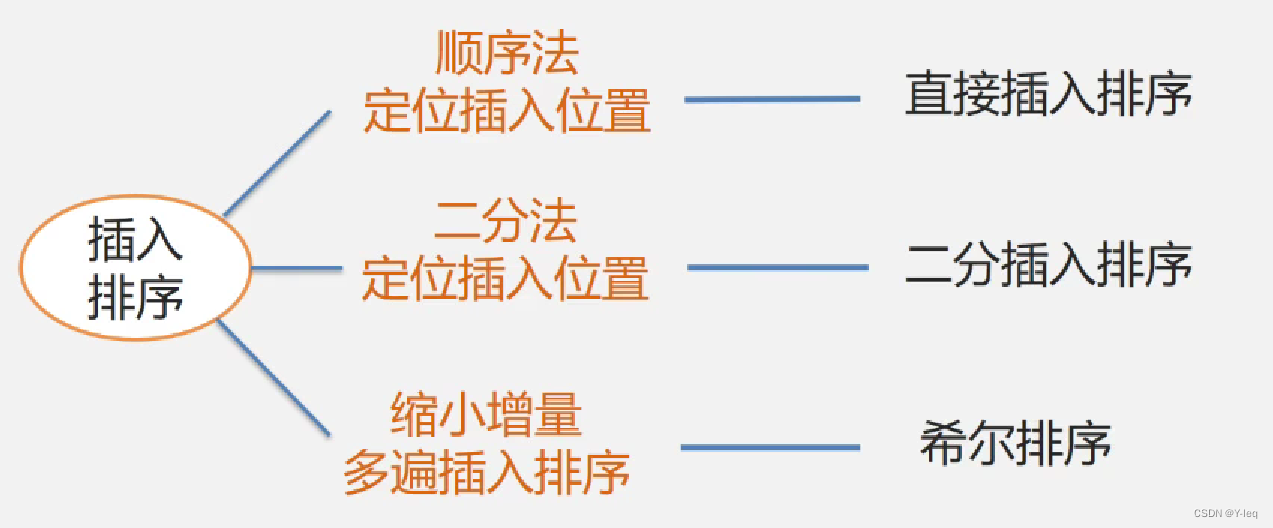
1. 直接插入排序
采用顺序查找法查找插入位置,使用哨兵
具体思路:
- 复制为哨兵:L.r[0]=L.r[i];
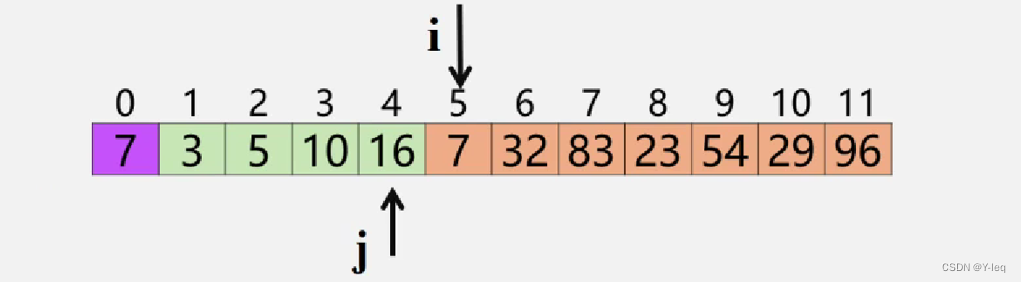
- 记录后移,查找插入位置:for ( j = i-1; L.r[0].key < L.r[j].key; --j ) { L.r[j+1] = L.r[j]; }
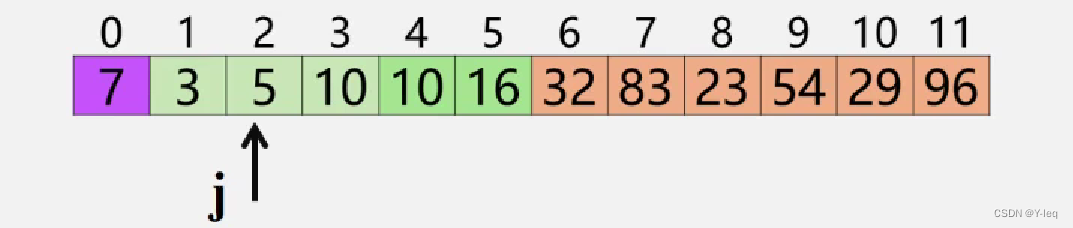
- 插入到正确位置:L.r[j+1] = L.r[0];

算法实现:
void InsertSort(SqList &L){
int i,j;
for(i=2;i<=L.length;++i){
if(L.r[i],key<L.r[i-1],key){ //若"<",需将L.r[i]插入有序子表
L.r[0]=L.r[i]; //复制为哨兵
for(j=i-1;L.r[0].key<L.r[j].key;--j){
L.r[j+1]=L.r[j]; //记录后移
}
L.r[j+1]=L.r[0]; //插入到正确位置
}
}
}
性能分析:
实现排序的基本操作有两个:
(1)"比较"序列中两个关键字的大小
(2)"移动"记录
- 最好的情况(关键字在记录序列中顺序有序):11 25 32 48 56 69 77 85 99
"比较"次数: ∑ i = 2 n 1 = n − 1 \sum_{i=2}^n 1=n-1 i=2∑n1=n−1
"移动"次数:0
- 最坏的情况(关键字在记录序列中逆序有序):85 74 66 52 45 41 22 12
"比较"次数: ∑ i = 2 n i = ( n + 2 ) ( n − 1 ) 2 \sum_{i=2}^n i = \frac{(n+2)(n-1)}{2} i=2∑ni=2(n+2)(n−1)
"移动"次数: ∑ i = 2 n ( i + 1 ) = ( n + 4 ) ( n − 1 ) 2 \sum_{i=2}^n (i+1) = \frac{(n+4)(n-1)}{2} i=2∑n(i+1)=2(n+4)(n−1)
- 平均的情况
比较次数: ∑ i = 1 n − 1 i + 1 2 = ( n + 2 ) ( n − 1 ) 4 \sum_{i=1}^{n-1} \frac{i+1}{2} = \frac{(n+2)(n-1)}{4} i=1∑n−12i+1=4(n+2)(n−1)
移动次数: ∑ i = 1 n − 1 ( i + 1 2 + 1 ) = ( n + 6 ) ( n − 1 ) 4 \sum_{i=1}^{n-1} (\frac{i+1}{2}+1) = \frac{(n+6)(n-1)}{4} i=1∑n−1(2i+1+1)=4(n+6)(n−1)
时间复杂度:
原始数据越接近有序,排序速度越快
最好情况下(输入数据是顺序有序的)Tb(n) = O(n)
最坏情况下(输入数据是逆序有序的) Tw(n) = O(n2)
平均情况下,耗时差不多是最坏情况的一半 Te(n) = O(n2)
要提高查找速度:① 减少元素的比较次数 ②减少元素的移动次数
空间复杂度:辅助存储O(1)——需要一个哨兵
稳定性:稳定
2. 折半插入排序
查找插入位置时采用折半查找法
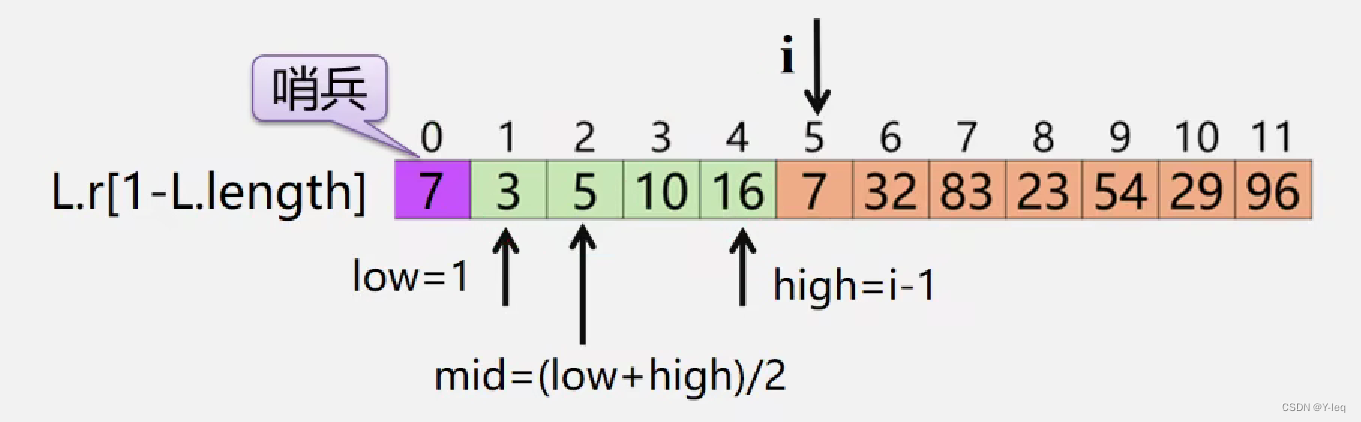
算法实现:
void BInsertSort(SqList &L){
for(i=2;i<=L.length;++i){ //依次插入第2~第n个元素
L.r[0]=L.r[i]; //当前插入元素存到"哨兵"位置
low=1; high=i-1; //采用二分查找法查找插入位置
while(low<high){
mid=(low+high)/2;
if(L.r[0].key<L.r[mid],key) high=mid-1;
else low=mid+1;
}//循环结束,high+1则为插入位置
for(j=i-1;j>=high+1;--j) L.r[j+1]=L.r[j]; //移动元素
L.r[high+1]=L.r[0]; //插入到正确位置
}
}
算法分析:
折半查找比顺序查找快,所以折半插入排序就平均性能来说比直接插入排序要快
它所需要的关键码比较次数与待排序对象序列的初始排列无关,仅依赖于对象个数。在插入第i个对象时,需要经过 ⌊ l o g 2 i ⌋ \lfloor log_{2}i \rfloor ⌊log2i⌋+1次关键码比较,才能确定其插入位置
-
当n较大时,总关键码比较次数比直接插入排序的最坏情况要好得多,但比其最好情况要差
-
在对象的初始排列已经按关键码排好序或接近有序时,直接插入排序比折半插入排序执行的关键码比较次数要少
折半插入排序的对象移动次数与直接插入排序相同,依赖于对象的初始排列
- 减少了比较次数,但没有减少移动次数
- 平均性能优于直接插入排序
时间复杂度:O(n2)
空间复杂度:辅助存储O(1)——需要一个哨兵
稳定性:稳定
3. 希尔排序
基本思想:
先将整个待排记录序列分割成若干个子序列,分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序
希尔排序算法特点:
(1)缩小增量
(2)多遍插入排序
- 定义增量序列 D k D_{k} Dk: D M D_{M} DM > D M − 1 D_{M-1} DM−1 > … > D 1 D_{1} D1=1
- 例子: D 3 D_{3} D3=5, D 2 D_{2} D2=3, D 1 D_{1} D1=1
- 对每个 D k D_{k} Dk进行“ D k D_{k} Dk-间隔” 插入排序(k=M,M-1,…,1)
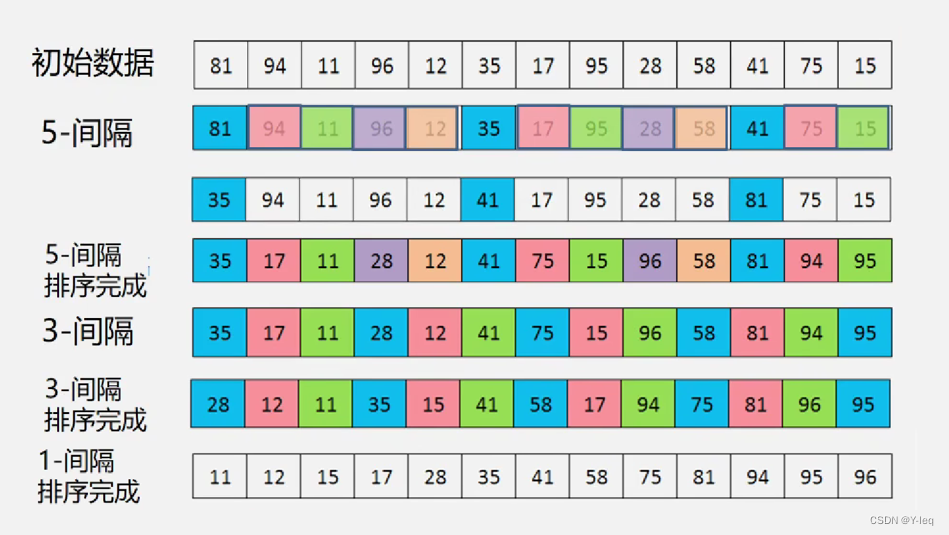
- 一次移动,移动位置较大,跳跃式地接近排序后地最终位置
- 最后一次只需要少量移动
- 增量序列必须是递减的,最后一个必须是1
- 增量序列应该是互质的
算法实现:
void ShellSort(Sqlist &L,int dlta[],int t){
//按增量序列dlta[0..t-1]对顺序表L作希尔排序
for(k=0;k<t;++k)
ShellInsert(L,dlta[k]); //一趟增量为dlta[k]的插入排序
}
void ShellInsert(SqList &L,int dk){
//对顺序表L进行一趟增量为dk的Shell排序,dk为步长因子
for(i=dk+1;i<=L.length;++i){
if(r[i].key<r[i-dk].key){
r[0]=r[i];
for(j=i-dk;j>0&&(r[0].key<r[j].key);j=j-dk)
r[j+dk]=r[j];
r[j+dk]=r[0];
}
}
}
算法分析:
希尔排序算法效率于增量序列的取值有关
时间复杂度:
最好情况:O(n)
最坏情况:O(n2)
平均情况:~O(n1.3)
空间复杂度:O(1)
稳定性:不稳定
二. 交换排序
两两比较,如果发生逆序则交换,直到所有记录都排好序为止
常见交换排序方法:① 冒泡排序O(n2) ②快速排序O(n l o g 2 log_{2} log2n)
1. 冒泡排序
基本思想:每趟不断将记录两两比较,并按“前小后大”规则交换

算法实现:
void bubble_sort(SqList &L){
int i,j,flag; //flag作为是否有交换的标记
RedType x; //交换时临时存储
for(i=1; i<=n-1 && flag==1; m++){
flag=0;
for(j=1;j<n-i;j++){
if(L.r[j].key>L.r[j+1].key){ //发生逆序
flag=1; //发生交换,flag设置为1,若没有发生交换,flag保持为0
x=L.r[j]; L.r[j]=L.r[j+1]; L.r[j+1]=x; //交换
}
}
}
}
优点:每趟结束时,不仅能挤出一个最大值到最后面位置,还能同时部分理顺其他元素;
一旦某一躺比较时不出现记录交换,说明已排好序了,就可以结束算法
时间复杂度:
最好情况(正序):O(n)
比较次数:n-1;
移动次数:0
最坏情况(逆序):O(n2)
比较次数: ∑ i = 1 n − 1 ( n − i ) = n 2 − n 2 \sum_{i=1}^{n-1} {(n-i)}= \frac{ n^2 - n }{2} i=1∑n−1(n−i)=2n2−n ;
移动次数: 3 ∑ i = 1 n − 1 ( n − i ) = 3 ( n 2 − n ) 2 3\sum_{i=1}^{n-1} {(n-i)}= \frac{3( n^2 - n) }{2} 3i=1∑n−1(n−i)=23(n2−n)
平均情况:O(n2)
空间复杂度:
冒泡排序算法中增加一个辅助空间temp,辅助空间为S(n)=O(1)
稳定性:稳定
2. 快速排序
任取一个元素为中心(枢轴),所有比它小的元素一律前放,比它大的元素一律后放,形成左右两个子表,对各子表重新选择中心元素并依此规则调整,直到每个子表的元素只剩一个(递归思想)
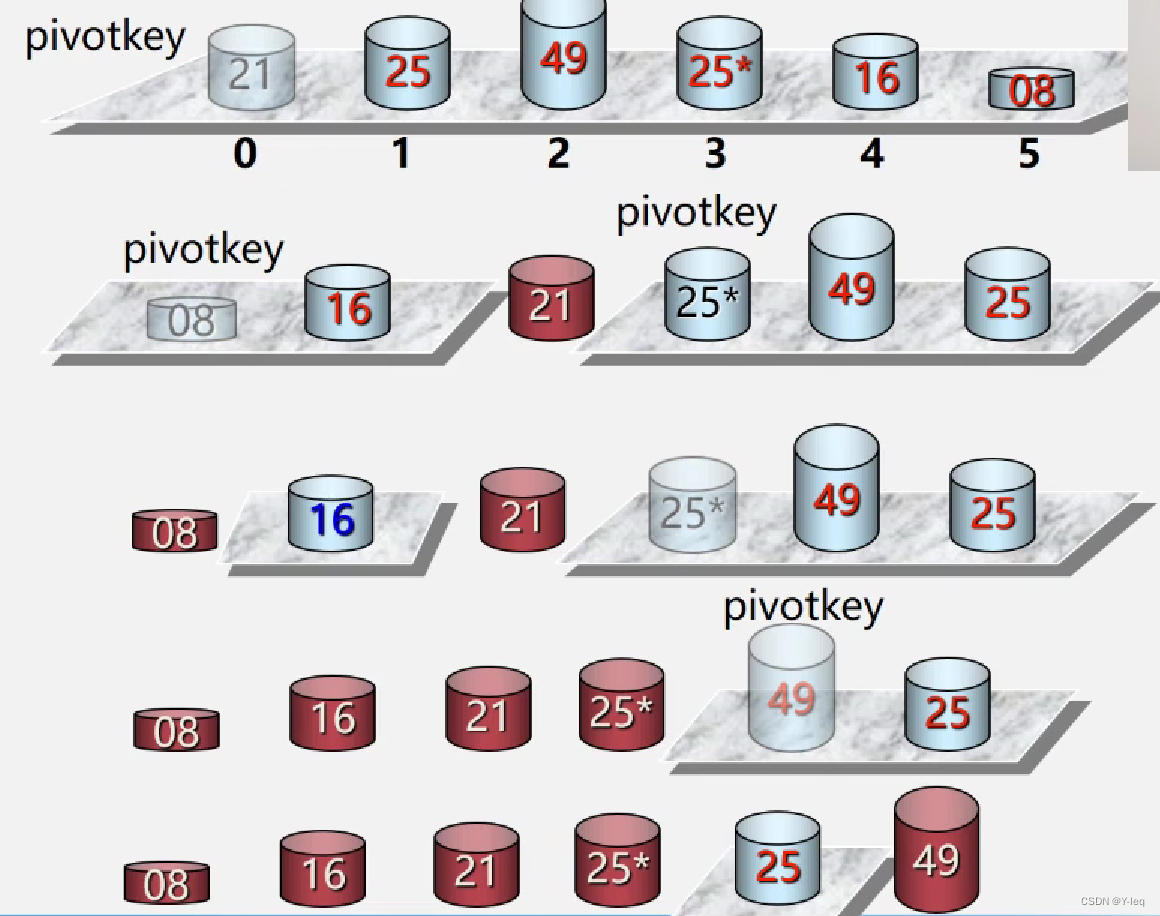
基本思想:通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录进行排序,以达到整个序列有序
具体实现:选定一个中间数作为参考,所有元素与之比较,小的调到其左边,大的调到其右边
中间数:可以是第一个数,最后一个数,最中间一个数,任选一个数等
算法实现:
① 每一趟的子表的形成是采用从两头向中间交替式逼近法
②由于每趟中对各子表的操作都相似,可采用递归算法
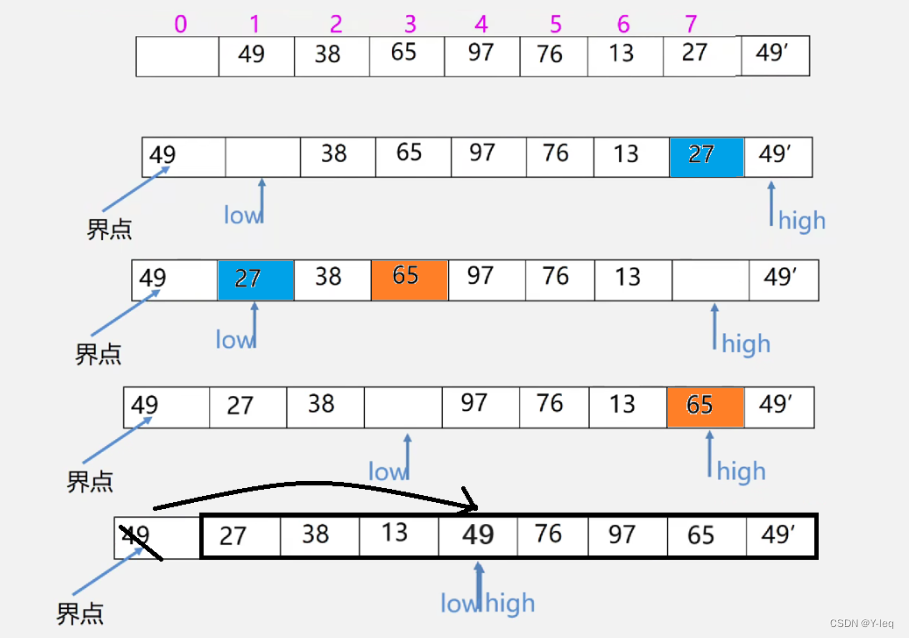
void QSort(SqList &L,int low,int high) {
if(low<high){
pivotloc=Partition(L,low,high);
//将L.r[low..high]一分为二,pivotloc为枢轴元素排好序的位置
QSort(L,low,pivotloc-1); //对低子表递归排序
QSort(L,pivotloc++1,high); //对高子表递归排序
}
}
int Partition(SqList &L,int low, int high){
L.r[0]=L.r[low];
pivotkey=L.r[low].key;
while(low<high){
while(low<high&&L.r[high].key>=pivotkey) --high;
L.r[low]=L.r[high];
while(low<high&&L.r[low].key>=pivotkey) ++low;
L.r[high]=L.r[low];
}
L.r[low]=L.r[0];
return low;
}
void main(){
QSort(L,1,L.length);
}
算法分析:
时间复杂度:
- 平均计算时间为 O(n l o g 2 log_{2} log2n)
- 最好情况下:O(n l o g 2 log_{2} log2n)
- 最坏情况下:O(n2)
就平均计算时间而言,快速排序是所讨论的所有内排序方法中最好的一个
空间复杂度:快速排序不是原地排序(由于使用了递归调用了栈,而栈的长度取决于递归调用的深度)
- 在平均情况下:需要O( l o g 2 log_{2} log2n)的栈空间
- 最坏情况下:栈空间可达O(n)
稳定性:不稳定
快速排序不适于对原来有序或基本有序的记录序列进行排序
划分元素的选取是影响时间性能的关键
- 输入数据次序越乱,所选划分元素值的随机性越好,排序速度越快,快速排序不是自然排序方法
- 改变划分元素的选取方法,至多只能改变算法平均情况下的时间性能,无法改变最坏情况下的时间性能,即最坏情况下,快速排序的时间复杂度总是O(n2)
三. 选择排序
1. 简单选择排序
基本思想:在待排序的数据中选出最大(小)的元素放在其最终的位置
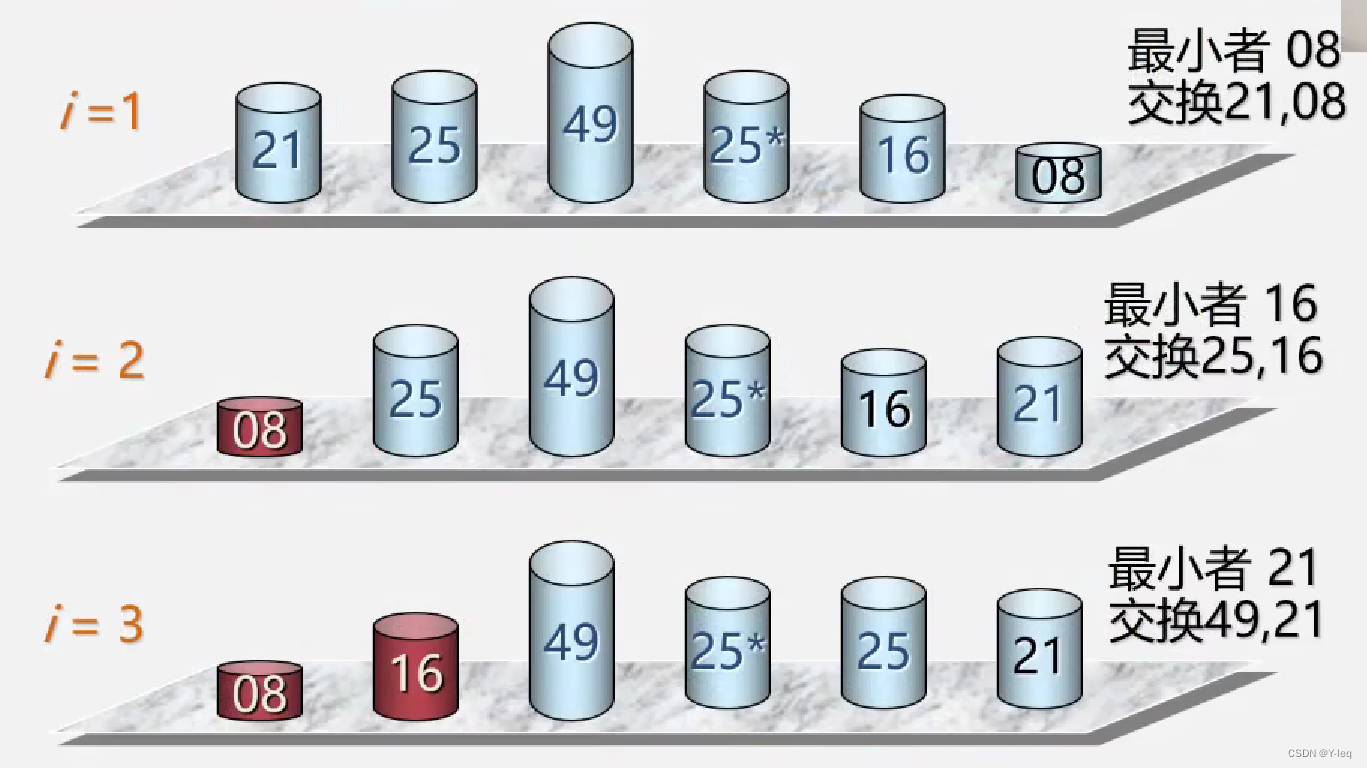
算法实现:
void SelectSort(SqList &K){
for(i=1;i<L.length;++i){
k=i;
for(j=i+1;j<=L.length;j++){
if(L.r[j].key<L.r[k].key) k=j; //记录最小值位置
if(k!=i) L.r[i]<-->L.r[k]; //交换
}
}
}
算法分析:
时间复杂度:O(n2)
① 记录移动次数
- 最好情况:0
- 最坏情况:3(n-1)
②比较次数:无论待排序列处于什么状态,选择排序所需进行的“比较”次数都相同
空间复杂度:O(1)
稳定性:不稳定
2. 堆排序
堆的定义:若n个元素的序列{a1,a2…an}满足

则分别称该序列{a1,a2…an}为小根堆和大根堆
从堆的定义可以看出,堆实质是满足如下性质的完全二叉树:二叉树中任一非叶子结点均小于(大于)它的孩子结点
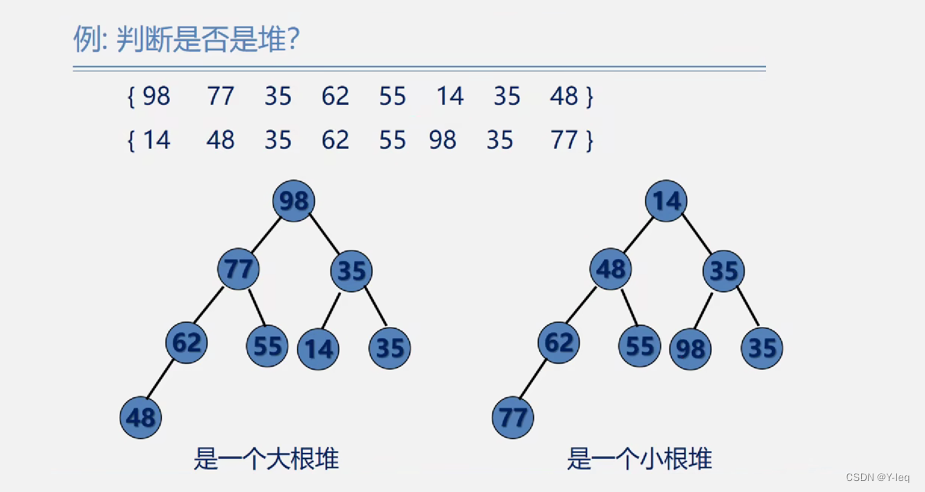
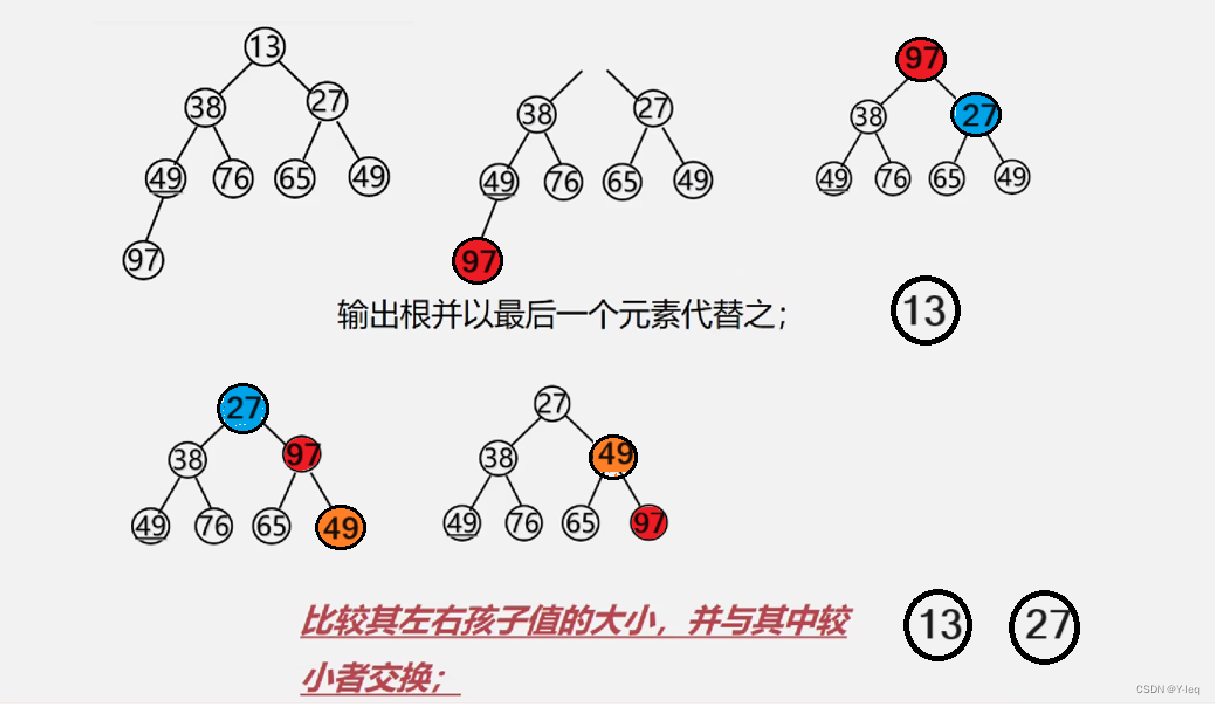
若在输出堆顶的最小值(最大值)后,使得剩余n-1个元素的序列又建成一个堆,则得到n个元素的次小值(次大值)…如此反复,便能得到一个有序序列,这个过程称之为堆排序。
堆的调整
如何在输出堆顶元素后,调整剩余元素为一个新的堆?
小根堆:
1.输出堆顶元素之后,以堆中最后一个元素替代之:
2.然后将根结点值与左、右子树的根结点值进行比较,并与其中小者进行交换,
重复上述操作,直至叶子结点,将得到新的堆,称这个从堆顶至叶子的调整过程为“筛选“
算法实现:
void HeapAdjust(elem R[],int s,int m){
rc=R[s];
for(j=2*s;j<=m;j*=2){
if(j<m&&R[j]<R[j+1]) ++j; // 沿key较大的孩子结点向下筛选
if(rc>=R[j]) break; //j为key较大的记录的下标
R[s]=R[j]; s=j; //rc应插入在位置s上
}
R[s]=rc; //插入
}
对一个无序序列反复“筛选”就可以得到一个堆,即:从一个无序序列建堆的过程就是一个反复“筛选”的过程
显然:
单结点的二叉树是堆;
在完全二又树中所有以叶子结点(序号i>n/2)为根的子树是堆。这样,我们只需依次将以序号为n/2,n/2-1,……1的结点为根的子树均调整为堆即可。
即:对应由n个元素组成的无序序列,“筛选”只需从第n/2个元素开始。
由于堆实质上是一个线形表,那么我们可以顺序存储一个堆。
将初始无序的R[1]到R[n]建成一个小根堆,可用以下语句实现:
for(i=n/2;i>=1;i--) HeapAdjust(R,i,n);
堆排序算法如下:
void HeapSort(elem R[]){ //对R[1]到R[n]进行堆排序
int i;
for(i=n/2;i>=1;i--){
HeapAdjust(R,i,n); //建初始堆
}
for(i=n;i>1;i--){ //进行-1趟排序
Swap(R[1],R[i]); //根于最后一个元素交换
HeapAdjust(R,1,i-1); //对R[1]到R[i-1]重新建堆
}
}
算法分析:
初始堆化所需时间不超过O(n)
排序阶段(不含初始堆化)
-
一次重新堆化所需时间不超过O( l o g 2 log_{2} log2n)
-
n-1次循环所需时间不超过O(n l o g 2 log_{2} log2n)
-
堆排序的时间主要耗费在建初始堆和调整建新堆时进行的反复“筛选”上。堆排序在最坏情况下,其时间复杂度也为0(n l o g 2 log_{2} log2n),这是堆排序的最大优点。无论待排序列中的记录是正序还是逆序排列,都不会使堆排序处于"最好"或“最坏“的状态。
堆排序仅需一个记录大小供交换用的辅助存储空间
稳定性:不稳定
堆排序不适用于待排序记录个数n较少的情况,但对于n较大的文件还是很有效的
四. 归并排序
基本思想:将两个或两个以上的有序子序列“归并”为一个有序序列
在内部排序中,通常采用的是2-路归并排序
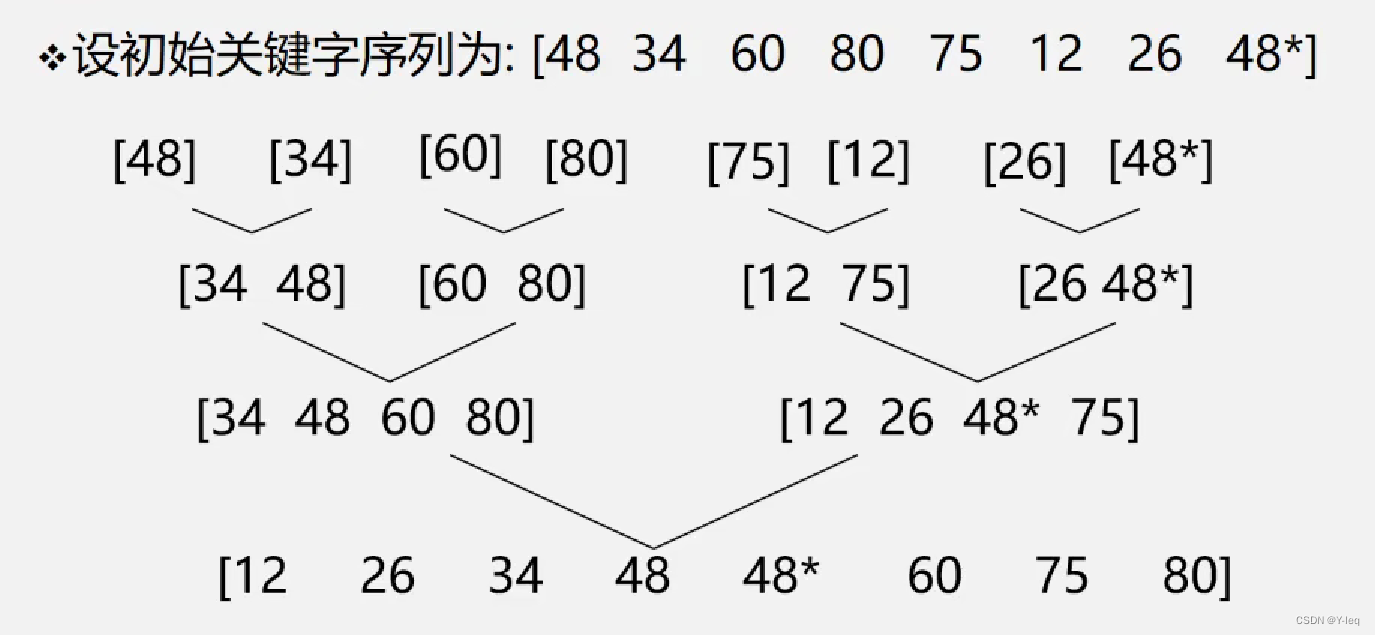
如上称为归并树,整个归并排序仅需 ⌈ l o g 2 n ⌉ \lceil log_{2} n \rceil ⌈log2n⌉趟
算法实现:
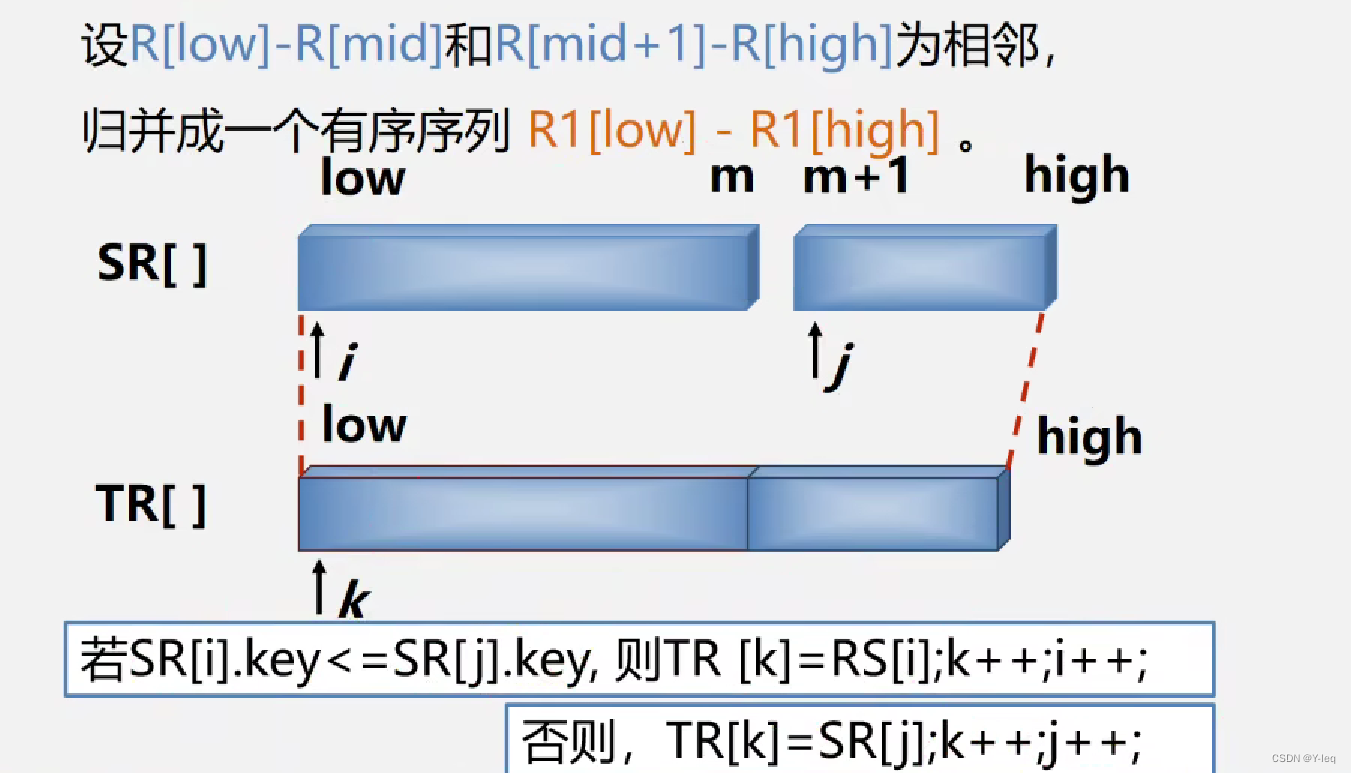
算法分析:
时间复杂度:O(n l o g 2 log_{2} log2n)
空间复杂度:O(n)——需要一个与原始序列同样大小的辅助序列(R1),此算法的缺点
稳定性:稳定
五. 基数排序
基本思想:分配+收集
也叫桶排序或箱排序:设置若干个箱子,将关键字k的记录放入第k个箱子,然后在按序号将非空的连接
基数排序:数字是有范围的,均由0-9这十个数字组成,则只需设置十个箱子,相继按个、十、百…进行排序
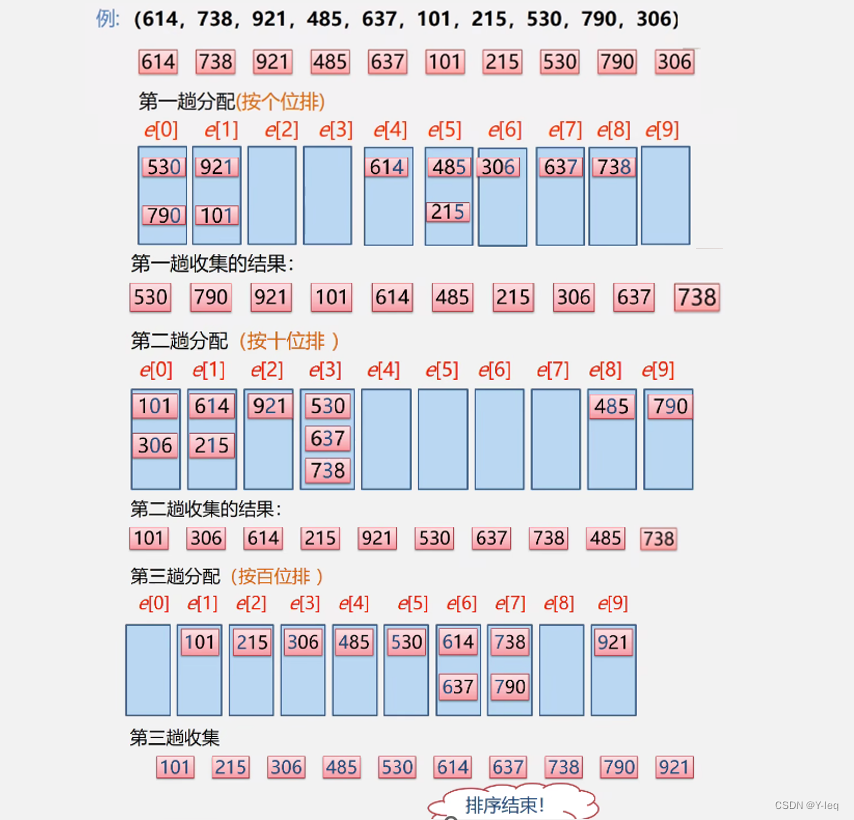
算法分析:
时间复杂度:O(k*(n+m))
- k:关键字个数
- m:关键字取值范围为m个值
空间复杂度:O(n+m)
稳定性:稳定
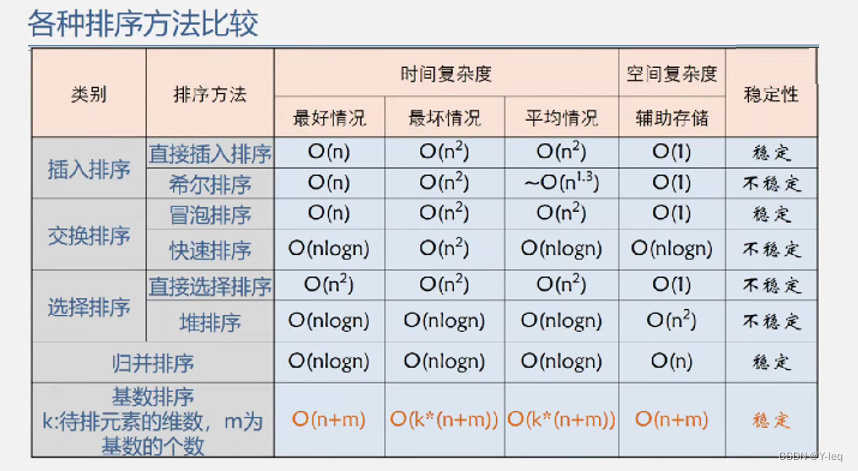
各排序方法综合比较
一.时间性能
1.按平均的时间性能来分,有三类排序方法:
- 时间复杂度为O(nlogn)的有:快速排序,堆排序和归并排序,其中快速排序为最好
- 时间复杂度为O(n2)的有:直接插入排序,冒泡排序和简单选择排序,其中直接插入最好
- 时间复杂度为O(n)的有:基数排序
2.当待排记录序列按关键字顺序有序时,直接插入排序和冒泡排序能达到O(n)的时间复杂度;而对于快速排序而言,这是最不好的情况,此时的时间性能退化为O(n2),因此是应该尽量避免的情况。
3.简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变。
二、空间性能
指的是排序过程中所需的辅助空间大小
1.所有的简单排序方法(包括:直接插入、冒泡和简单选择)和堆排序的空间复杂度为O(1)
2.快速排序为O(logn),为栈所需的辅助空间
3.归并排序所需辅助空间最多,其空间复杂度为O(n)
4.链式基数排序需附设队列首尾指针,则空间复杂度为O(rd)
三、排序方法的稳定性
1.稳定的排序方法指的是,对于两个关键字相等的记录,它们在序列中的相对位置,在排序之前和经过排序之后,没有改变。
2.当对多关键字的记录序列进行LSD方法排序时,必须采用稳定的排序方法。
3.对于不稳定的排序方法,只要能举出一个实例说明即可。
4.快速排序和堆排序是不稳定的排序方法。
四、关子“排序方法的时间复杂度的下限“
本章讨论的各种排序方法,除基数排序外,其它方法都是基于“比较关键字”进行排序的排序方法,可以证明,这类排序法可能达到的最快的时间复杂度为O(nlogn)。
(基数排序不是基于“比较关键字”的排序方法,所以它不受这个限制)。
可以用一棵判定树来描述这类基于“比较关键字”进行排序的排序方法。















 4006
4006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









