第一题

for line in f1:
nf = line[11:15]
yf = line[15:17]
lx= line[17:21]
if "s" in line:
sj=line[22:].strip().split("s")
else:
sj=line[22:].strip().split("S")
for i in range(0, len(sj)):
if i+1<10:
rq = nf+"-"+yf + '-0' + str(i+1)
else:
rq = nf+"-"+yf+ '-' + str(i+1)
sj[i]=sj[i].strip().replace("T","")
if len(sj[i])>0 and not ("-9999" in sj[i]):
js= float(sj[i])/10
if lx=="TMAX" :
zd[rq]=[js]
else:
zd[rq].append(js)
第二题
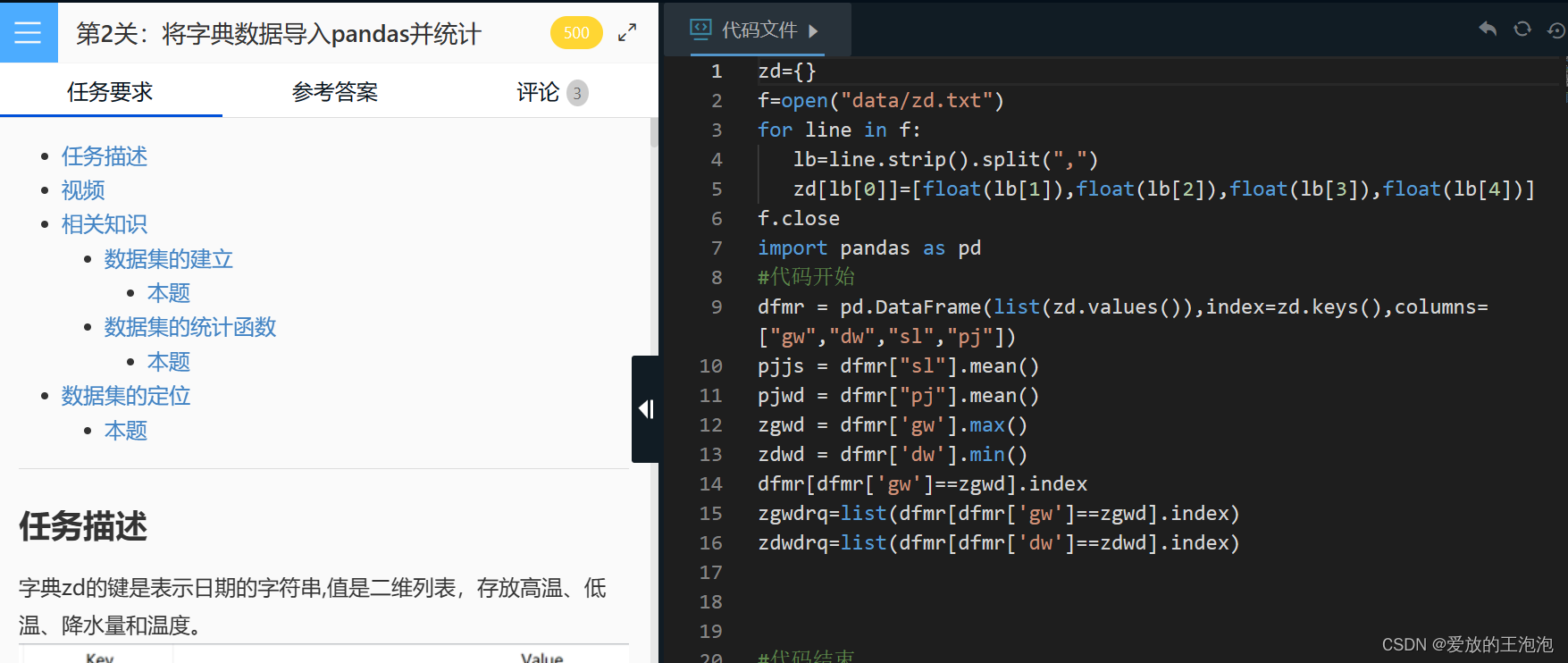
dfmr = pd.DataFrame(list(zd.values()),index=zd.keys(),columns=["gw","dw","sl","pj"])
pjjs = dfmr["sl"].mean()
pjwd = dfmr["pj"].mean()
zgwd = dfmr['gw'].max()
zdwd = dfmr['dw'].min()
dfmr[dfmr['gw']==zgwd].index
zgwdrq=list(dfmr[dfmr['gw']==zgwd].index)
zdwdrq=list(dfmr[dfmr['dw']==zdwd].index)
第三题

dfmr = pd.read_csv('data/zd.txt', index_col=0,header=None,names=["gw","dw","sl","wd"])
df_yftj=dfmr.groupby(dfmr.index.str[5:7]).agg({'sl':'mean','wd':'mean',"gw":"mean","dw":"mean"})
第四题

plt.figure(figsize=(20,10))
sj=range(1,13,1)
plt.bar(sj,df_yftj["sl"])
for i in range(12):
plt.text(i+0.9,df_yftj["sl"][i]+0.2,"{:.2f}".format(df_yftj["sl"][i]))
plt.xlabel("月")
plt.ylabel("雨量")
plt.title("各月日均降水量")
plt.xticks(sj)
plt.ylim(0,8)
plt.grid(True)
第五题

sj=range(1,13)
plt.figure(figsize=(20,10))
plt.plot(sj,df_yftj["wd"],label="平均温度")
plt.plot(sj,df_yftj["gw"],"r",label="最高温度")
plt.plot(sj,df_yftj["dw"],"g",label="最低温度")
for i in range(12):
plt.text(i+0.8,df_yftj["wd"][i]+1,"{:.2f}".format(df_yftj["wd"][i]))
plt.xlabel("月")
plt.ylabel("气温")
plt.title("各月日均温度")
plt.xticks(sj)
plt.grid()
plt.xlim(1,12)
plt.legend(loc="upper right")
第六题

wd=[]
f2=open("data2/wdyc.txt","w")
for line in f1:
lx= line[17:21]
if lx=="TAVG" :
if "s" in line:
sj=line[22:].strip().split("s")
else:
sj=line[22:].strip().split("S")
for i in range(0, len(sj)):
sj[i]=sj[i].strip().replace("T","")
if len(sj[i])>0 and not ("-9999" in sj[i]):
js= float(sj[i])/10
wd.append(str(js))
if len(wd)==11 :
f2.write(",".join(wd)+"\n")
wd.pop(0)
f2.close()
第七题
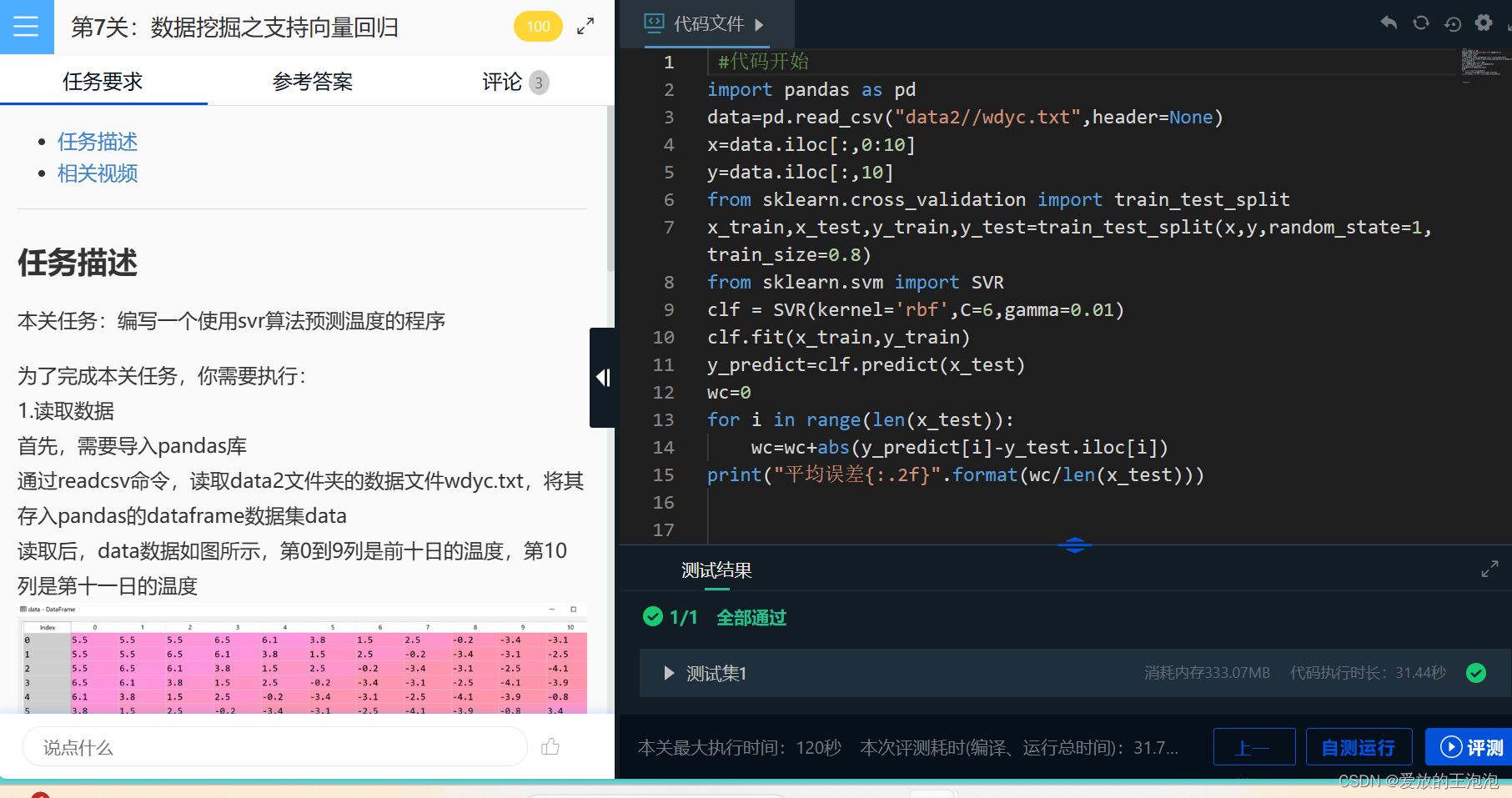
import pandas as pd
data=pd.read_csv("data2//wdyc.txt",header=None)
x=data.iloc[:,0:10]
y=data.iloc[:,10]
from sklearn.cross_validation import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=1,train_size=0.8)
from sklearn.svm import SVR
clf = SVR(kernel='rbf',C=6,gamma=0.01)
clf.fit(x_train,y_train)
y_predict=clf.predict(x_test)
wc=0
for i in range(len(x_test)):
wc=wc+abs(y_predict[i]-y_test.iloc[i])
print("平均误差{:.2f}".format(wc/len(x_test)))






















 9537
9537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









