






目录
前言
在上一篇文章主要去讲解了多线程的创建,使用 和 多线程中的一些特性,本篇文章主要是针对在我们实际工作中会出现一些场景任何使用多线程快速解决,也就是一些代码模型,而且我在这里会对一些典型但是Java标准库中已经实现的模型进行再次人工实现逻辑。

1.单例模式
所谓的单例模式是一种设计模式,设计模式就相当于程序在编程的时候的“棋谱”,而这里的单例模式对应的使用场景就是有些时候希望在整一个程序在执行的过程中只能被实例化(对象)(new一次),此时就需要编译器进行严格的检查了,在这里有两种实现逻辑 --- 饿汉模式和懒汉模式(没有痴汉模式别想了)
1.1饿汉模式
饿汉模式,从字面上来看是不是有点能看出一种迫切的感觉(就像你饿了一天了,有一份丰盛的大餐在你面前的那种感觉),对饿汉模式就是就是就是这样的,饿汉模式在程序启动的时候(类加载之后)就立即创建出实例化了,让我们来看一下代码实现
//单例模式 --- 饿汉模式
class Singleton {
//代码的执行时机,是在类被jvm加载的时候
private static Singleton ingleton = new Singleton();
public static Singleton getSingleton() {
return ingleton;
}
// 做出一个限制,禁止别人去new 这个实例
private Singleton() {}//给一个空的构造方法
}像上面的代码要想实现单例模式,类的构造方法一定是被private修饰的,不能开放出去给类外使用的。像这里的饿汉模式就在创建成员变量的时候就已经把这个类给实例化了,后续想要获取这个类的实例化对象就只能通过getSingleton方法去获取,来让我们验证一下
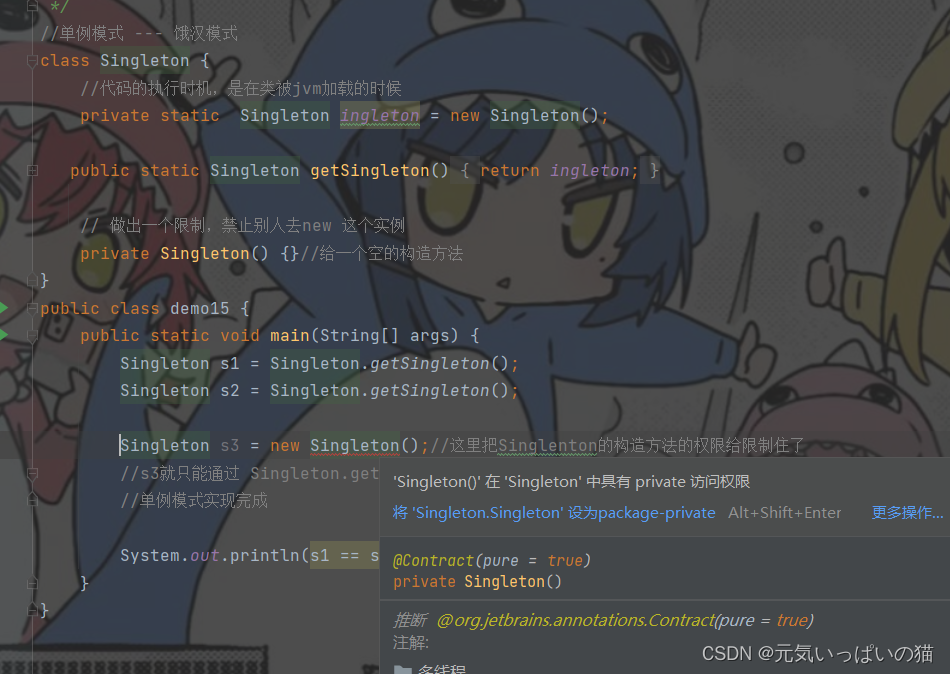

很好的实现了我单例模式的要求,但是这里会有个缺点,就是如果我在整一个程序在执行的过程中都不需要使用到你这里类的实例化对象,这里的提前实例化对象岂不是有点亏了。
1.2懒汉模式
相对于上面显得非常急促的饿汉模式,懒汉模式又给人一种你不来让它工作就会一直摆下去的样子,懒汉模式的实现逻辑于饿汉模式一开始就把对象给实例化有很大的区别,懒汉模式在你为调用的时候,是不会把实例化出对象出来的,当程序第一次调用get方法的时候才会进行实例化,后续的调用get都会直接return之前第一次实例化的对象(上代码)
class Singletonlazy {
public static Singletonlazy singletonlazy = null;
public static Singletonlazy getSingletonlazy() {
if(singletonlazy == null) {
//第一次调用get方法 就实例化对象给 singletonlazy
singletonlazy = new Singletonlazy();
}
return singletonlazy;
}
private Singletonlazy() {};
}从上述代码可以很容易观察出懒汉模式相比于饿汉模式的优点就是只有你调用对应的方法的时候,才会被实例化对象出来,当整一个程序始终没有去调用的时候就静静的呆在那不会有任何影响。
1.3单例模式在多线程中可能会出现的问题
通过上述的介绍应该已经对单例模式有了一定的了解了,这里就需要把单例模式提升一个高度了,我们在编程的时候大多情况是会去使用我们之前介绍的多线程并发编程的模式编程,要想进行多线程编程的一个前提就是这段代码在多线程运行的情况下是否安全(线程安全问题)。
先来看看饿汉模式,饿汉模式的实现的逻辑思路是提前把类的对象提前实例化出来,后续的get操作只要把实例化出来的对象直接return返回就好了,就以为着多线程在使用懒汉模式去实现单例模式的时候,线程只会使用带读取提前实例化的功能,不存在有的线程要去修改线程的操作,多个线程同时进行读操作是不会存在线程安全的。
再来看一下懒汉模式,懒汉模式的实现逻辑是先不实例化出对象,等到有线程去调用get方法的时候,才会去判定是否要实例化新的对象,生产新的实例化对象之后的线程调用的时候才会只设计return去读取数据,这里就很明显了,在多线程中有涉及对数据的修改又涉及对数据的读取,是很容易出现线程安全问题的,这里就跟上一篇文章一开始想对一个成员变量进行两个线程的加1操作,到最后未能达到预期的结果,这里就画个图去描述这里出现的第一个问题。
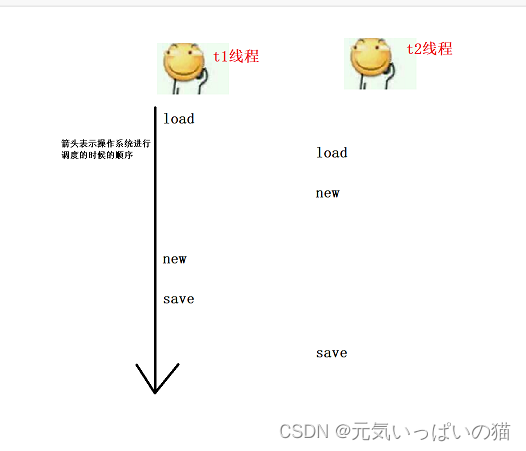
这里就会出现线程安全问题,这也是操作系统的随机调度产生的问题,我们针对这一问题往往是采用会出现线程安全的地方进行加锁操作(这里直接对Singletonlazy的class文件进行加锁了)。
//单例模式 --- 懒汉模式 (重点)
class Singletonlazy {
private static Singletonlazy singletonlazy = null;
public static Singletonlazy getSingletonlazy () {
//先判断是先判断是否要加锁
if(singletonlazy == null) {
synchronized (Singletonlazy.class) {
//这里的if是有个加锁操作的 可能会阻塞
//在这个阻塞的过程中别的线程可能就把这个变量的值修改了
//因此你第一个if进的来,第二个if可能就进不去了
if(singletonlazy == null) {
singletonlazy = new Singletonlazy();
}
}
}
return singletonlazy;
}
private Singletonlazy() {}
}在上述的synchronized加锁的时候一定要注意要把if语句也给放到synchronized里面,不然还是一样会出现线程安全问题的。
观察我给代码会发现,蛙趣这里怎么又多出来一个if判断语句了,这里是不是博主脑子瞅瞅了多写了一个if判断,其实这里的双重if判断不但不是多余的,反而还能起到提高运行效率的功能,你想想嗷,就是我们已经对singletonlazy进行实例化操作了,我后续不管怎么玩都不会出现线程安全问题的了,但是我每次使用get方法的时候都要在synchronized这里堵一下,线程少的情况下还好,但是线程如果一旦多起来的话,岂不是我调度到最后一个线程的时候要阻塞很久。所以这两个if的含义是不一样的第一个if判断的是你是否要进行加锁操作,第二个if语句判断的是,你能不能进行加锁,如果线程通过了第一个if语句也不一定可以通过第二个if语句的。
这里还有预防内存可见性的问题(因为会同时涉及读写操作),所以懒汉模式在多线程中最后的代码展示应该是酱紫的
//单例模式 --- 懒汉模式 (重点)
class Singletonlazy {
//加多一个volatile多一个保险(避免出现内存可见性问题(风险))
private volatile static Singletonlazy singletonlazy = null;
//这里这个volatile一是避免内存可见性问题,另外一点是避免指令重排序问题
public static Singletonlazy getSingletonlazy () {
//先判断是先判断是否要加锁
if(singletonlazy == null) {
synchronized (Singletonlazy.class) {
//这里的if是有个加锁操作的 可能会阻塞
//在这个阻塞的过程中别的线程可能就把这个变量的值修改了
//因此你第一个if进的来,第二个if可能就进不去了
if(singletonlazy == null) {
singletonlazy = new Singletonlazy();
}
}
}
return singletonlazy;
}
private Singletonlazy() {}
}要特别补充的一点就是这里的volatile不仅仅是只为了防止内存可见性问题,还是为去避免指令重排序的问题,在操作系统的随机调度指令的过程中可能会出现一种情况,就是一套完整的指令在调度的过程中出现了指令执行顺序的变化,就比如 实例化对象 new操作,new操作先是向内存申请一片空间,然后对这块空间进行赋值操作,最后在放回这一块空间,但是如果出现指令重排序使得我在申请完一片空间之后就直接返回给变量岂不是就相当于跟没有一样,所以这里volatile就起到了避免内存可见性和指令重排序两个问题点。
2.阻塞队列
说到队列我们在之前数据结构的学习过程中有接触到 队列和优先级队列(堆),这里我们又会认识队列的一种衍生阻塞队列,阻塞队列在多线程中有一个对应的生产模型 --- 生产者消费者模式,在这里我们先会对生产者消费者模式进行解释,再去使用Java中提供好的类,最后就是阻塞队列的核心代码的实现
2.1生产者消费者模型
这里先拿包饺子这一大家都熟悉的事情来举个栗子。在包饺子的时候当把饺子的馅料都调好的之之后,就进入到擀饺子皮和包饺子的两个动作中,假设我有3个人但是只有一根擀面杖,此时有两种包饺子的方式,一是每个人轮流使用擀面杖,自己使用擀面杖搞好自己的饺子皮然后自己去包饺子;二是有一个人专门去使用擀面杖去擀饺子皮,剩下两个人就只用负责等待擀好的饺子皮把馅料包进去就行了。这里很明显第二种方法的效率会高很多。
但是这里很可能会出现一些问题,1)是当我这个专门去擀饺子皮的人家里有事要退出的时候,那么整一个流程不就挂掉了吗,这里换一个栗子来说明这个问题(充值系统(分布式系统)),
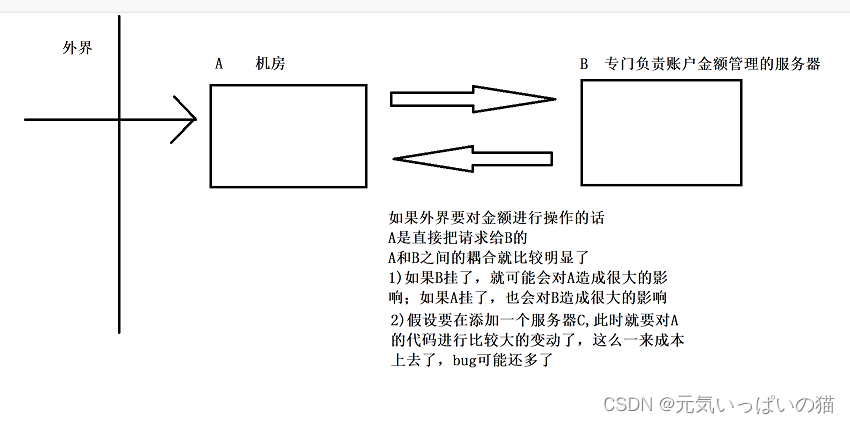
这里就出现一个问题,如果代码的耦合性太高是会很容易出现上述的情况的,阻塞队列在这一过程中可以起到解耦合的效果了
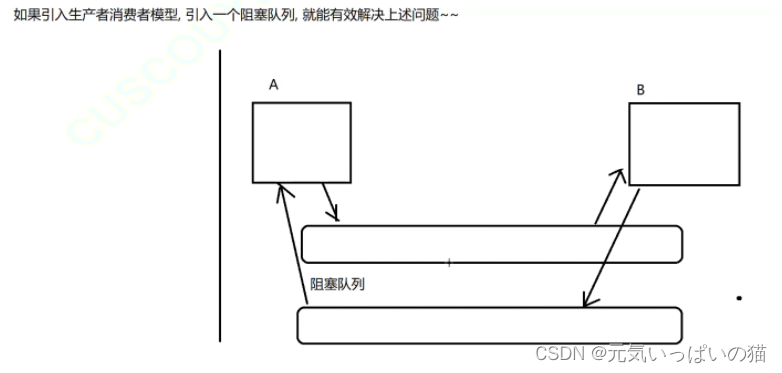
此时我把A和B的数据的交流通过一个阻塞队列去完成就可以很好的解决耦合新太高的问题了, 此时尽管你A或者B挂了,由于它们彼此之间不会进行交互,没有啥太大的影响。而且如果我后续要新增服务器的话,A服务器不用进行任何的修改,只需要多开一组阻塞队列给C从A中获取元素了。
此时在这肯定会有一个疑惑,这不是使用普通的队列就可以实现解耦合的效果吗,这个博主是不是暗夹私货就讲阻塞队列,其实这里使用阻塞队列的原因不只是解决耦合性高的问题,在上述的栗子中还存在一种比较不容易发现的问题:如果我服务器A收到来自客户端(用户)的请求暴增(学校的抢课系统),此时使用普通的队列一定会出现问题的,一台服务器,同一时刻能处理的请求数量是有限的(机器的硬件资源有限)
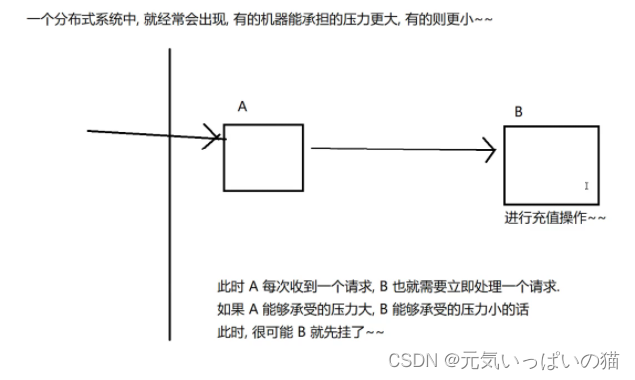
此时阻塞队列的阻塞就展示了它在的特殊之处,我A服务器接收的请求的速度和B服务器处理的请求的速度肯定是不一样的,如果我A服务器接收的请求速度十分块,但是它是先把B要处理的指令先放到阻塞队列中,至于B是否在何时处理完就是B的事情了,如果阻塞队列中已经给塞满了,阻塞队列就会对添加元素的操作进行wait进入阻塞状态,在B处理之前(队列中有空位之前)不可能有指令会进入队列,那如果我B处理请求的速度比A接收并发送给队列的速度快上很多的话,此时如果队列中没有元素,也会对读取队列中元素的操作进行wait操作,使该条指令进入阻塞状态(但是这种情况比较少出现)
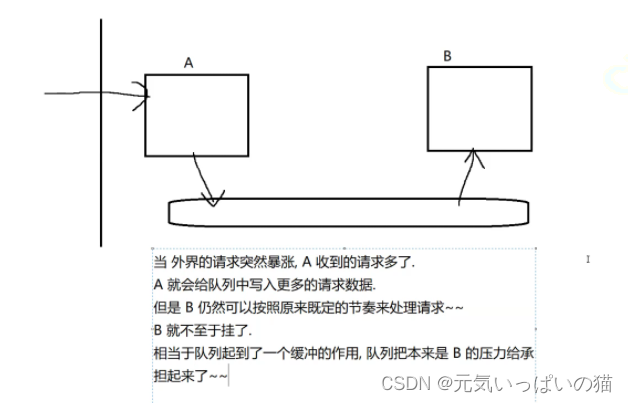
这里阻塞队列就起到了另外一个作用 ---- 削峰填谷:服务器收到的来自客户端/用户的请求,不是一成不变的,可能会因此一些突发事件,引起请求数目暴增而且峰值在很多时候只是暂时的,相当于队列起到了一个缓冲的作用,队列把本来是 B 的压力给承担起来了~~(削峰), 当峰值消退的时候,A 收到的请求少了,B 还是按照既定的节奏来处理~~ B 也不至于太空闲~~(填谷)
2.2阻塞队列的使用
在Java标准库中提供的阻塞队列的类有以下实现的类

以上三种是基于不同的数据结构实现的阻塞队列

我们接着来看一下阻塞队列方法的使用
public static void main(String[] args) throws InterruptedException {
//基于链表实现的
BlockingDeque<String> deque = new LinkedBlockingDeque<>(10);//可以设置最大容量
deque.put("hello");
String s1 = deque.take();//去队首元素
System.out.println(s1);
s1 = deque.take();//由于队列中已经没有元素了,所以线程运行到这里的时候会进行阻塞
// 而且如果时候 offer 和 poll 是不带有阻塞功能的
System.out.println(s1);
}在阻塞队列中也是实现了offer和poll方法的,但是使用了offer和put是不带有阻塞队列的功能的,既然如此就没必要使用阻塞队列了,切记在阻塞队列中要使用out和task方法
来康康代码执行的结构
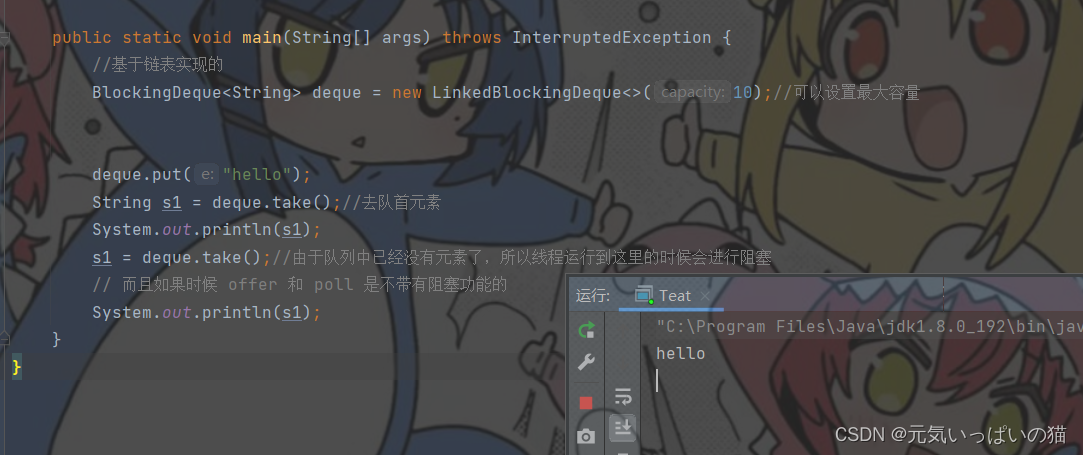
可以看出当阻塞队列中没有元素的时候再次进行task操作整个线程进入了阻塞状态
我们模拟实现一种生产者消费者的模型,就是一个线程A专门负责往阻塞队列中生产元素生产 素 另外一个线程B就专门冲阻塞队列中取走元素。
public static void main(String[] args) {
BlockingDeque<Integer> queue = new LinkedBlockingDeque<>(1000);
//生产元素
Thread t1 = new Thread(() -> {
int count = 0;
while (true) {
try {
queue.put(count);
System.out.println("生产元素" + count);
count++;
//Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//负责消费元素
Thread t2 = new Thread(()-> {
while (true) {
try {
Thread.sleep(1000);
Integer integer = queue.take();
System.out.println("消费元素" + integer);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}
我上面实现的代码中在消费元素的时候加了一个sleep操作就是为了展示阻塞队列的效果
我们看一下代码的执行结果就会发现阻塞的效果在哪
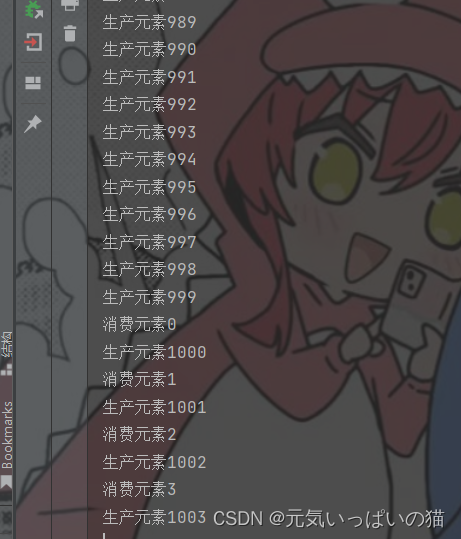
通过执行的结果来看,生产元素的线程确实比消费元素的线程快了很多,但是到达阻塞数组的上线的时候,就只能被迫的进入等待,等线程2取一个元素线程1才能添加下一个元素,后面代码的执行速度会很明显的下降了很多。
2.3阻塞数组的实现
通过上面描述阻塞队列中的put方法和task方法就可以很容易的发现这两个方法肯定是针对同一个对象进行了加锁,并且是相互解锁,这里我展示一下我在这块的代码实现
//基于数组,循环队列,来实现阻塞队列
public class MyBlockingQueue {
private String[] items = new String[100];
//指向队列的头部
private volatile int head;
//指向队列的尾部的下一个元素,队列中的元素范围为[ head , tail)
//当head 和 tail 重合的时候,就相当于队列为空
private volatile int tail;
//使用size来表示元素个数
private volatile int size = 0;
//入队列
public void put(String s) throws InterruptedException {
//先确保线程安全 --- 加synchronized
synchronized (this) {
while (size >= items.length) {
//这里的while是为了wait被唤醒之后,能够再次确认一下条件
//队列满了,这里补充阻塞效果
this.wait();//wait notify
}
items[tail] = s;
tail = (tail+1)%items.length;
size++;
this.notify();//这个notify是用来唤醒下面的take因为队列为空而进入的阻塞状态
}
}
//出队列
public String take() throws InterruptedException {
//先确保线程安全
synchronized (this) {
//if换成while ---- 使用wait的时候建议搭配while进行条件判定
while(size == 0) {
//队列为空,暂时不能出队列
this.wait();
}
String elem = items[head];
head = (head+1)%items.length;
size--;
this.notify();//使用这个notify 去唤醒上面因为队列满的时候进入的阻塞状态
return elem;
}
}
}
其实难点也不是很多,只要能够清楚的认识阻塞队列在执行过程中的一个具体逻辑就可以去尝试实现以下了,
先去使用一下这个自己实现的效果到底能不能达成我阻塞数组的效果
public static void main(String[] args) {
MyBlockingQueue queue = new MyBlockingQueue();
Thread t1 = new Thread(() -> {
int count = 0;
while (true) {
try {
queue.put(count + "");
System.out.println("生产元素 = " + count);
count++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(() -> {
while (true) {
try {
String count = queue.take();
System.out.println("消费元素 =" + count);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}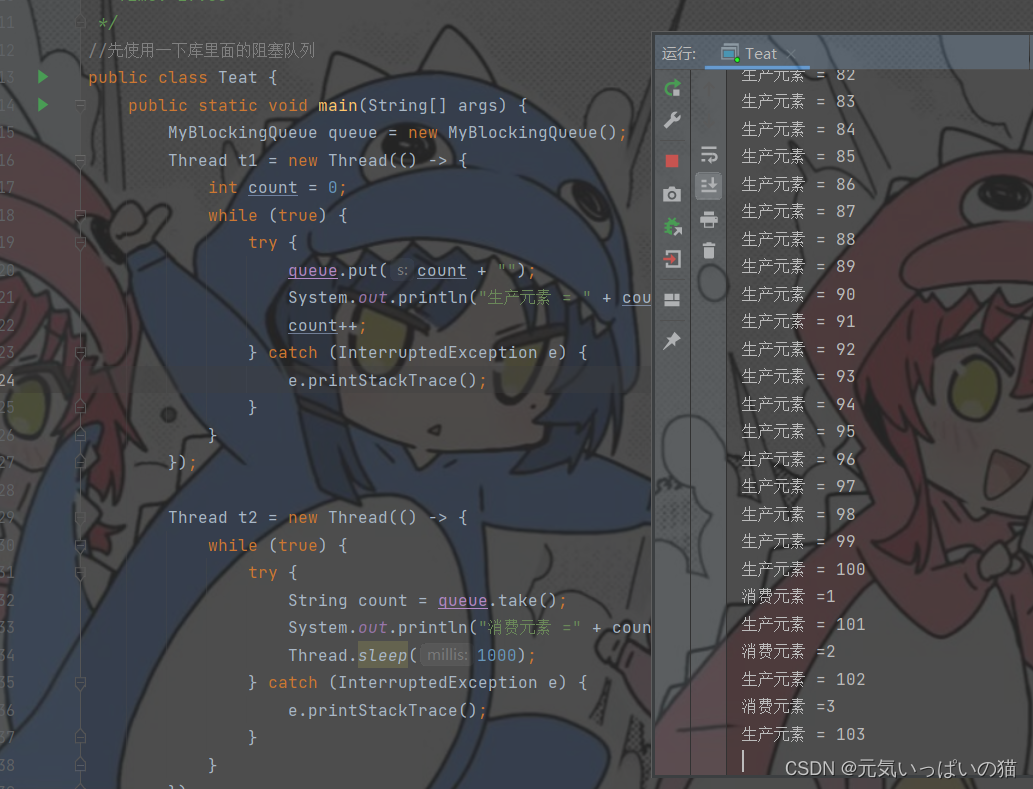
完全没有问题的。
3.定时器
在我们日常生活中经常会使用到闹钟这一个东西来提醒某个时间段我们应该于做什么,并不是早上一起床就把一天要做的事情一下子就全部完成的,在多线程中也是如此,我们往往会先让某个线程(任务)在特定的时间去执行对应的操作,这个时候我们就需要上述“闹钟”这一类的事物去进行管理了,在对线程中我们使用定时器这一概念去完成对线程执行的规划
在Java标准库中提供了Timer类实现了定时器的功能
![]()
我们先来尝试使用一下Java为我们提供的。
public static void main1(String[] args) {
Timer timer = new Timer();
//给timer中注册的这个任务,不是在 调用schedule的线程中执行的,而是通过timer内置的线程中执行的
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello Timer");
}
//这里类似于Runnable 但是比Runnable 多了一个时间(启动的时间)
},3000);//schedule 安排
}在这里很关键的一个方法就是schedule,这个方法的功能是往定时器(timer)中添加线程任务,schedule在中文中也有安排这一意思,我们还可以看到在schedule中有两个参数,一个是TimerTask实例化的对象,其实这个跟在之前讲到创建线程的中匿名内部类的Runnable方法来创建线程是差不多的,在Timer中Timer是一个多个线程的管理器,我们肯定是要去创建一个类去描述Timer中每一任务的基本信息的,TimerTask中的run方法跟前面的线程中的一样,都是在描述该线程要执行的任务,接下来就是第二个参数了,它是用来描述进程从开始之后过了多久才能执行这一段线程(注意了,设定的时间是相对时间,进程啥时候开始就从啥时候开始算),接下来我们展示一下定时器的功能就去尝试实现一下定时器。
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello 3");
}
},3000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello 2");
}
},2000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello 1");
}
},1000);
}
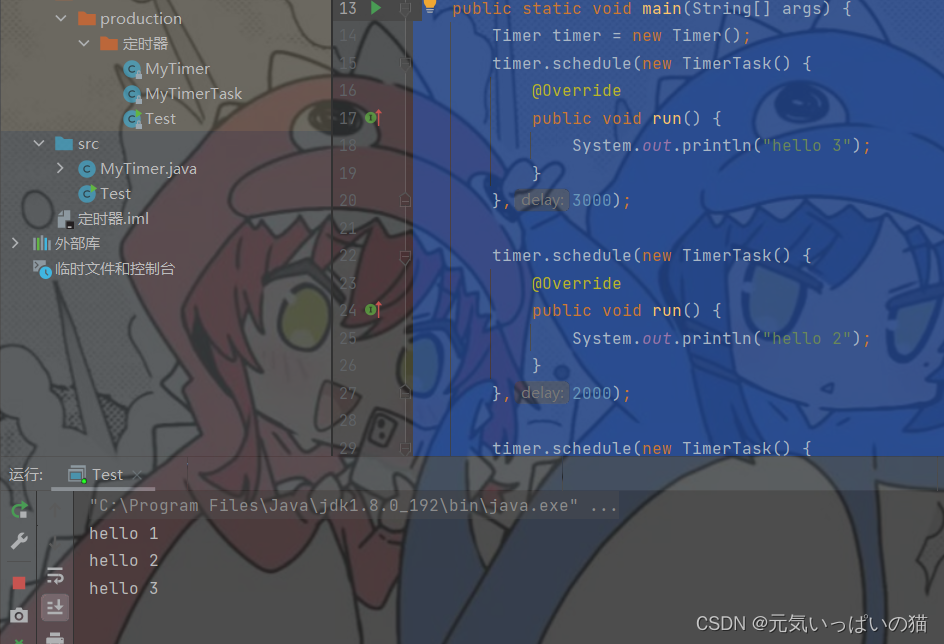
它这里的执行结果是按照设定的时间在进行的
3.1定时器的实现
定时器的功能实现跟我们在多线程中大部分的功能实现差不多的先描述再组织这一逻辑,我们先说说描述,再上面对定时器进行介绍的时候我特别说了,TimerTask是专门用来去描述定时器中一个任务的类,所以我们在实现定时器的时候也要去创建一个类似TimerTask这样的类去描述一个任务的执行内容和实际执行时间(在实现的时候要使用时间戳来表示,在schedule的时候先获取到当前系统时间,在这个基础上,加上delay时间间隔,得到了真实要执行这个任务的时间)。
讲完描述接下来就到组织这一块了,组织这一功能肯定的要在Timer内部中实现的,在这我们需要使用一些数据结构把TimerTask中描述的任务给组织起来,如果这里使用List组织TimerTask的话,假设任务特别多,该如何确定哪个任务到点该执行了呢,如果是这样的话,我们要额外去搞一个线程去专门遍历List,去看这里面的每个元素,是否到达了执行时间,时间到了就执行,实现没到就去遍历下一个,通过上述假设使用List去组织可以很明显的看出这种组织的效率非常低下,而且还不科学(如果我设定的任务都是在一个小时后执行,那岂不是我遍历List的线程要在这一个钟内无效的扫描,这样的无效扫描是不是没有意义而且非常低效)。
组织任务代码的优化点
1)在看是否有线程到达了运行时间的时候,并不用像上面去额外去创建一个线程去重复的扫描所有线程,在这里我们要明白一个点就是我最早要执行的任务还没开始执行是不是我之后的任务是不可能执行的,所以我们只需要盯着执行时间最早的线程就可以了,这里想一想我们学习的数据结构中哪种是可以快速找到存储元素的最大最小值,很明显就是优先级队列(堆)了(队首就是执行时间最短的)
2)就是当所有线程中执行执行最早的线程还没到执行时间没有必要去重复扫描等扫描到执行时间,这样做比较低效,我们可以让它进入阻塞(休眠)状态,当然这里的阻塞等待不是死等,我们可以然当前的时间和线程的执行时间差作为我们的阻塞最大等待时间
3)搞一个扫描线程,负责监控队首任务的执行时间到了没有
在上面的优化点说明完成之后,我这里提出3个问题
1)你觉得如果直接去实现上述的代码,线程是安全的吗?
大部分数据结构在多线中是线程不安全的,只有少数的数据结构是可以在多线程中安全使用的,这个点我们后面的文章会进行说明,如果使用优先级队列实现的话,在多线程运行的时候可能既会在主线程中使用,也会在扫描线程中使用 ,所以我们这里要针对优先级队列的方法使用进行加锁
2)如果在线程还没有到执行的时间的时候我们使用sleep进行阻塞等待,不方便提前中断.(虽然可以使用 interrupt 来中断,但是 nterrupt 意味着线程应该要结束了),而且如果是使用sleep进行阻塞等待的话,在阻塞这一段时期期间假设我如果通过schedule加入了一个比当前所有待执行的线程执行时间还有早的话,由于扫描线程还在进行休眠,所以如果后续添加执行时间更早的线程不能及时的完成
这里的解决方法就是使用wait进行等待,wait也有等待最大时间的版本,每当外面schedule添加新的TimerTask的时候我们就接触阻塞状态然后重新对优先级队列队首的元素进行执行时间的判断,这样做就可以很好的满足了我上述的所有要求
3)这个问题说的是TimerTask类实现的时候的一些细节问题,TimerTask类实例化的对象在后续是需要放入优先级队列中的,所以需要实现Comparable这个接口的compareTo方法
欧克克细节问题就已经说明完了,接下来就是上手实现了。
先来看一下组织任务的TimerTask实现要达到的效果是啥样的
//先创建一个类去描述单个任务
class MyTimerTask implements Comparable<MyTimerTask> {
private Runnable runnable;
private long time;//任务的执行时间
MyTimerTask(Runnable runnable,long time) {
this.runnable = runnable;
this.time = System.currentTimeMillis() + time;
}
public Runnable getRunnable() {
return runnable;
}
public void setRunnable(Runnable runnable) {
this.runnable = runnable;
}
public long getTime() {
return time;
}
public void setTime(long time) {
this.time = time;
}
//这里由于是要把任务存入优先级队列中,所以要在MyTimerTask内部去实现compareTo方法
@Override
public int compareTo(MyTimerTask o) {
return (int) (this.time - o.time);
}
}
再来看看Timer的实现
//定时器实现
class MyTimer {
//在定时器中我们是按照执行时间去运行到达时间的任务的,假设一组数据中执行时间最早的任务都没有到点,其他的就不用看了
//所以这里采用优先级队列的方式去对MyTimerTask进行存储
PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();
//接下来要实现schedule方法把任务添加到优先级队列中
public void schedule(Runnable runnable,long time) {
synchronized(this) {
MyTimerTask myTimerTask = new MyTimerTask(runnable,time);
queue.add(myTimerTask);
//这里要进行针对this进行notify操作(原因下述有进行解释)
this.notify();
}
}
//核心方法
MyTimer() {
Thread thread = new Thread( () -> {
while (true) {
synchronized (this) {
try {
while(queue.isEmpty()) {
//这里如果优先级队列中没有存储数据就进入睡眠状态
//等有新的元素进入的时候 在将他唤醒
this.wait();
}
MyTimerTask myTimerTask = queue.peek();
long curtime = System.currentTimeMillis();
if(curtime >= myTimerTask.getTime()) {
//系统时间到了线程的执行时间就把任务执行了然后抛出
myTimerTask.getRunnable().run();
queue.poll();
} else {
//如果还没有到就让它进入阻塞等待状态
//注意这里要尽量避免死等,我们已知最早的线程执行时间和当前系统的时间,
//我们就让它的最大等待时间为这两者的差值就欧克克了
//另外这里不要使用sleep进行阻塞,sleep一旦进行阻塞了我schedule也会被影响到,就使用wait()就欧克了
//这里使用wait的另外一个原因是,如果在休眠等待的时期,schedule加进一个新的线程,这个线程的执行时间比我目前队列
// 最早的线程还要早,那是不是要被唤醒重新执行一次while循环
this.wait(myTimerTask.getTime() - curtime);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
thread.start();
}
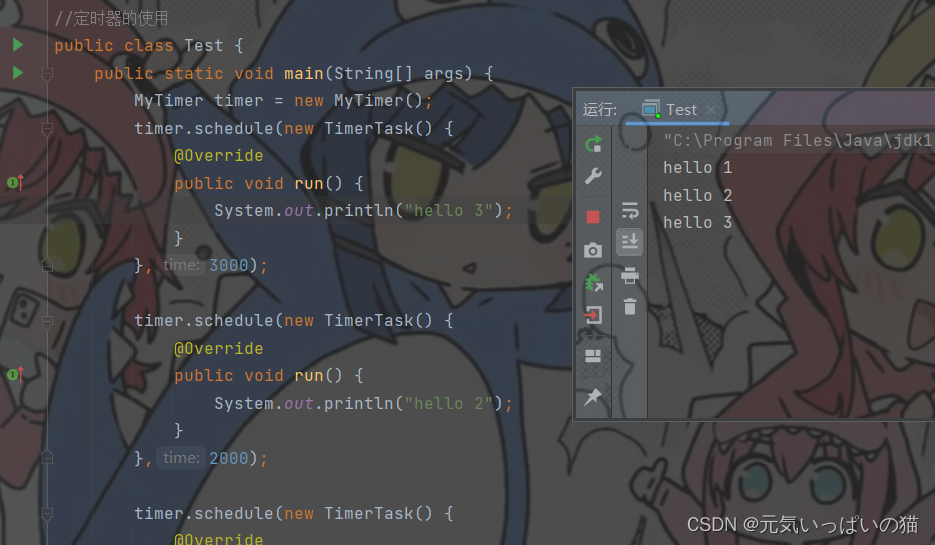
}接下来我们看一下我实现的TImer的运行结果,就结束定时器的内容了嗷。
public static void main(String[] args) {
MyTimer timer = new MyTimer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello 3");
}
},3000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello 2");
}
},2000);
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello 1");
}
},1000);
}
4.线程池
在编写代码的时候如果我们需要频繁的创建销毁线程,此时创建和销毁线程的成本,就不能忽视,因此就可以使用线程池,提前创建好一波线程,后续需要使用线程,就直接从池子里面拿一个即可,当线程不再使用,就放回池子里,这也就是我们的池化思想,在前面的学习中我们也接触过常量池这一概念,都是为了去减低频繁创建和销毁变量导致成本的飙升。
如果是从系统这里创建线程,需要调用系统api,进一步的由操作系统内核 完成线程的创建过程(内核是给所有的进程提供服务)---- 不可控的
如果是从线程池这里获取线程,上述的内核中进行的操作,都提前做好了,现在的取线程的过程,纯粹的用户代码完成(纯用户态) ---- 可控的
4.1工厂方法
在讲Java提供的线程池类之前,我们先了解一下工厂方法这一概念
构造方法的名字固定就是类名, 有的类需要有多种不同的构造方式(但是构造方法的名字又固定,就只能使用方法重载的方式来实现了 参数的个数和类型需要有差别)

使用工厂模式来解决上述问题,不是用构造方法了,就使用普通的方法来构造对象,这样的方法名字就可以是任意的了,普通方法内部,再来new对象 ---- 由于普通方法的目的是为了创建出对象来,这样的方法一般是静态的

4.2线程池的方法使用和讲解
//创建一个固定线程数量的线程池
ExecutorService executorService = Executors.newFixedThreadPool(4);这就是线程池中一种创建方法,ExecutorService executorService 就是线程池对象,Executors就是所谓的工厂类,newFixedThreadPool就是工厂方法,在工厂类中的工厂方法不只有这一种
Executors.newCachedThreadPool();这个工厂方法相比于上一个方法的区别就是,上一个工厂方法在使用的时候你需要去传一个整形的参数,这个传的参数就是线程池中的线程数量,而newCachThreadPool就是一个动态的线程池,不需要去手动去设置线程池中的线程数,而是根据情况去自动的增加或者删除线程池中的线程,
Executors.newSingleThreadExecutor();包含单个线程(比原生的创建线程 api 更简单一点)
ExecutorService executorService1 = Executors.newScheduledThreadPool();类似于定时器的效果添加一些任务,任务都在后续的某个时刻再执行被执行的时候不是只有一个扫描线程来执行任务可能是由多个线程共同执行所有的任务.
除了上述这些线程池之外,标准库还提供了一个接口更丰富的线程池类ThreadPoolExecutor
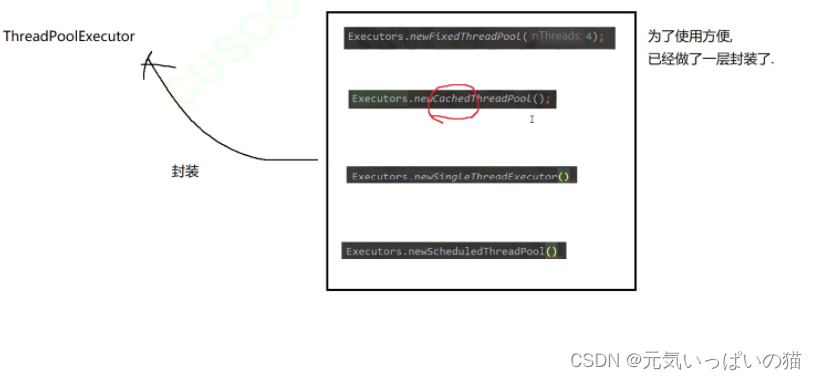
接下来我们去Java官方文档中查看一下查看一下ThreadPoolExecutor的具体内容
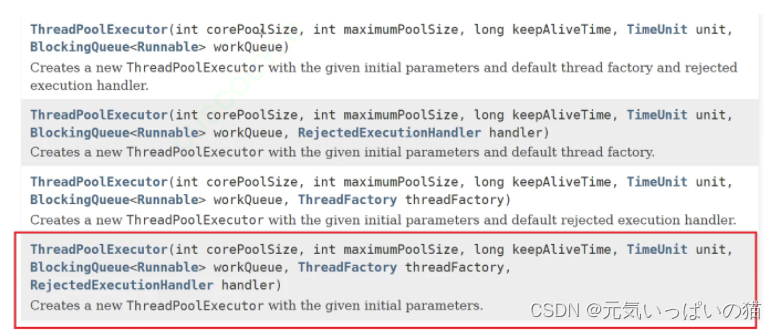
我们发现在ThreadPoolExecutor的构造方法中有4种,而且每一种构造方法都比之前的对出几个参数,我们接下来就去了解一下这些参数的含义
1.corePoolSize 核心线程数 ----- 至少得有这些线程,哪怕你的线程池一点任务也没有
2.maximumPoolSize 最大线程数 ----- ThreadPoolExecutor里面的线程个数,并非是固定不变的,会根据当前情况动态发生变化,最多不能超过这些线程,哪怕线程池忙冒烟了,也不能比这个数目更多了,做到既能保证繁忙的时候高效的处理任务又能保证空闲的时候不会浪费资源~
3.long keepAliveTime,TimeUnit unit ----- 允许实习生摸鱼的最大摸鱼时间,实习生线程 空闲超过指定的时间阈值,就会自动销毁
4.BlockingQueue<Runnable> wirkqueue ------ 线程池内有很多任务,这些任务可以使用 阻塞队列来管理
5.RejectedExecutionHandler handler ---- 线程池有一个阻塞队列,当阻塞队列满了之后,继续添加任务,该任何应对(决策),接下来就是Java给出的一些面对这个情况给出的决策
5.1 ThreadPoolExecutor,AbortPolicy 直接抛出异常,线程池也就寄了(不能进行接下来的工作了)
5.2ThreadPoolExecutor.CallerRunsPolicy 谁是添加这个新的任务的线程,谁就去执行这个任务(我这里做不完了,谁给过来的自己去做)
5.3ThreadPoolExecutor.DiscardoldestPolicy 丢弃最早的任务,去执行新的任务
5.4ThreadPoolExecutor.DiscardPolicy 爱谁谁干,直接无视,接着做自己的事情(跟2是不一样的哦,2是返回个抛出任务的线程让它自己去完成,而4是直接把这个任务挂了,没有人去执行了)
4.3线程池的模拟实现
在这里先说明一下,我在这实现的是初始会设定线程池固定线程数的线程池,其他的方法也是类似的就是需要某些地方进行优化。
public class MyThreadPool {
private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
//通过这个方法,把任务添加到线程池中 --- 生产者
public void submit(Runnable runnable) throws InterruptedException {
queue.put(runnable);
}
//n表示线程池中有几个线程 固定数量的线程池 -- 消费者
public MyThreadPool(int n) {
for (int i = 0; i < n; i++) {
Thread thread = new Thread(() -> {
while (true) {
try {
//取出任务 并执行
Runnable runnable = queue.take();
runnable.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread.start();
}
}
}在实现的时候为了灵活的解决线程安全问题,我在这采用了阻塞队列中讲到的生产者消费者模型,细品还是有点香的
总结
本篇文章到这就该结束了,以上说明的生产模式都是在我们接下来多线程编码的时候常用的一些模式,可以有时间的话可以慢慢去品味,博主在讲解线程池这一概念的时候可能会有一点模糊,如果有这种感觉的话,随时欢迎私信一下博主(毕竟有些时候博主的表达能力有限,需要一点时间去慢慢的优化一下自身对这一块的了解),随时欢迎大伙在评论区讨论或者提出你对本篇文章的疑惑,886啦















 4497
4497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









