






一、爬取的网站及数据介绍
本次数据采集项目选择了 水果交易网(https://www.guo68.com)作为目标网站,我们爬取的水果类目为西瓜的销售信息,具体的数据采集网址为 https://www.guo68.com/sell?kw=西瓜&page=。
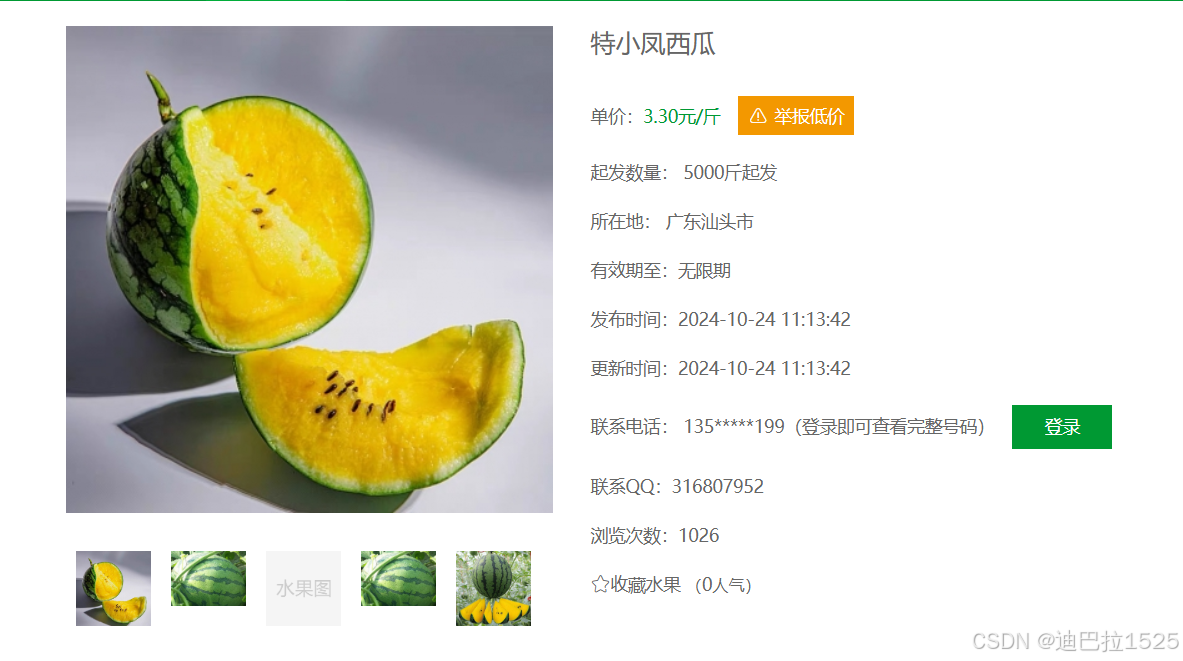
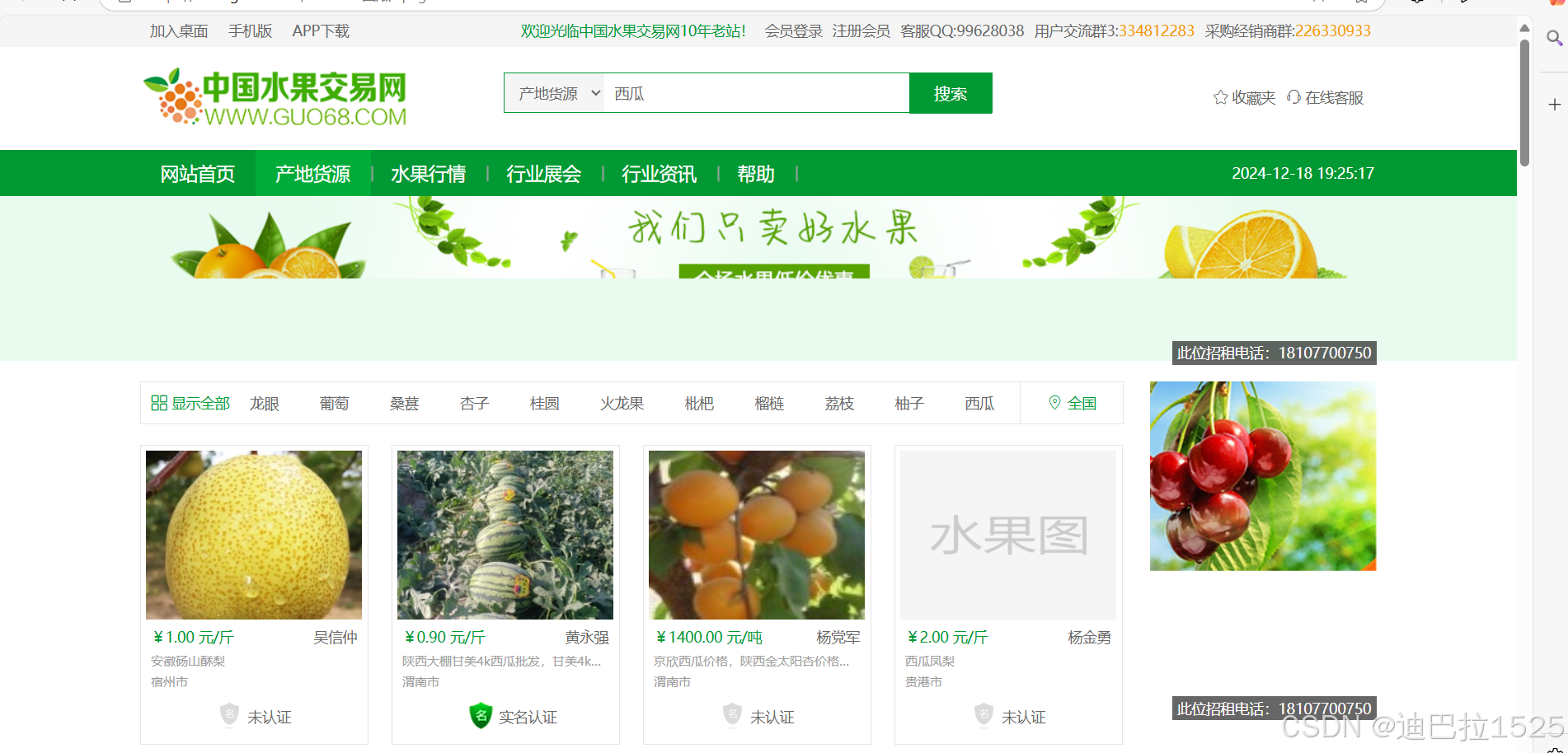 主要爬取的数据包括水果的价格、名称、描述、地址及认证信息。通过对这些数据的收集与分析,旨在了解西瓜在不同地区的销售情况、价格波动趋势,以及消费者对产品的评价,从而为市场分析和商业决策提供数据支持。
主要爬取的数据包括水果的价格、名称、描述、地址及认证信息。通过对这些数据的收集与分析,旨在了解西瓜在不同地区的销售情况、价格波动趋势,以及消费者对产品的评价,从而为市场分析和商业决策提供数据支持。
二、采用的数据采集技术
在本项目中,主要采用了 Python 语言结合 Requests、BeautifulSoup、concurrent.futures、tqdm 和 pandas 库进行数据采集。具体技术如下:
Requests 库:
原理:通过发送HTTP请求获取网页内容。支持多种请求方法,如GET、POST等,能够处理会话、cookies等。
BeautifulSoup 库:
原理:解析HTML和XML文档,提供便捷的文档导航、搜索和修改功能。
concurrent.futures 库:
原理:提供高级接口用于异步执行调用。支持多线程和多进程,能够并行处理多个任务。
tqdm 库:
原理:用于在Python中添加进度条,简化进度跟踪。
pandas 库:
原理:强大的数据处理和分析工具,提供DataFrame结构,便于数据操作和导出。
CSV 库:
原理:用于处理逗号分隔值(CSV)文件的读写操作。
三、实现的功能
在本项目中,通过结合多种Python库和技术,实现了高效、稳定且功能丰富的数据采集工具。具体实现的功能如下:
1. 用户输入页数
程序启动后,首先提示用户输入需要爬取的页数。通过用户输入的页数,动态生成要爬取的页面范围,使爬虫具有灵活性,能够根据需求调整采集规模。
while True:
try:
num_pages = int(input("请输入要爬取的页数:"))
if num_pages < 1:
print("请输入一个正整数。")
continue
break
except ValueError:
print("请输入一个有效的整数。")
2. 多线程并发爬取
为了提升数据采集的效率,采用了多线程技术。使用concurrent.futures.ThreadPoolExecutor创建线程池,并设置max_workers=10,即同时运行10个线程并行处理页面请求。多线程的应用显著减少了整体爬取时间,尤其在处理大量页面时效果尤为明显。
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
for _ in tqdm(executor.map(fetch_page, pages), total=len(pages), desc="爬取进度", unit="页"):
pass
3. 实时进度显示
集成了tqdm库,为爬虫过程添加了实时进度条。进度条能够直观地展示爬取的进度,包括已完成的页数和剩余的页数,提升了用户体验。
from tqdm import tqdm
for _ in tqdm(executor.map(fetch_page, pages), total=len(pages), desc="爬取进度", unit="页"):
pass
4. 数据解析与提取
使用BeautifulSoup库解析每个页面的HTML内容,定位并提取所需的数据字段,包括价格、名称、描述、地址及认证信息。通过分析网页结构,准确定位数据所在的HTML标签和类名,确保数据提取的准确性。
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('li', class_='fruit')
for item in items:
price = item.find('span', class_='price').get_text(strip=True)
name = item.find('span', class_='name').get_text(strip=True)
description = item.find('p', class_='describe').get_text(strip=True)
address = item.find('p', class_='address').get_text(strip=True)
validation = item.find('span', class_='simin').get_text(strip=True)
with data_lock:
data.append([price, name, description, address, validation])
5. 数据存储与导出
通过pandas库,将采集到的数据组织成DataFrame结构,并导出为多种格式的文件,包括TXT、CSV及Excel文件。这样不仅方便数据的存储和管理,也便于后续的数据分析和处理。
# 转换为DataFrame
df = pd.DataFrame(data, columns=['价格', '名称', '描述', '地址', '认证'])
# 保存为TXT文件
df.to_csv('水果.txt', sep='\t', index=False, encoding='utf-8-sig')
# 保存为CSV文件
df.to_csv('水果.csv', index=False, encoding='utf-8-sig')
# 保存为Excel文件
df.to_excel('水果.xlsx', index=False)
6. 异常处理与重试机制
在数据采集过程中,可能会遇到网络请求超时、连接失败等问题。为此,程序设计了异常处理和重试机制。每个页面请求失败时,程序会尝试重新请求最多3次,并在每次失败后等待2秒再重试。如果所有重试均失败,程序将跳过该页面,继续爬取其他页面,确保整个爬取过程的稳定性。
def fetch_page(page, retries=3):
url = base_url + str(page)
attempt = 0
while attempt < retries:
try:
response = requests.get(url, headers=headers, timeout=20) # 增加超时时间
response.raise_for_status()
break # 请求成功,跳出重试循环
except requests.exceptions.RequestException as e:
attempt += 1
print(f"请求页面 {url} 时出错: {e}。尝试重新请求 ({attempt}/{retries})...")
time.sleep(2) # 等待2秒后重试
else:
print(f"请求页面 {url} 失败,跳过。")
return
# 数据解析部分
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('li', class_='fruit')
if not items:
print(f"页面 {page} 没有找到任何数据。")
return
for item in items:
price = item.find('span', class_='price').get_text(strip=True)
name = item.find('span', class_='name').get_text(strip=True)
description = item.find('p', class_='describe').get_text(strip=True)
address = item.find('p', class_='address').get_text(strip=True)
validation = item.find('span', class_='simin').get_text(strip=True)
with data_lock:
data.append([price, name, description, address, validation])
7. 线程安全的数据管理
在多线程环境下,多个线程同时访问和修改共享数据列表data,可能会导致数据竞争和不一致的问题。为此,程序使用了threading.Lock()创建了线程锁data_lock,在向data列表添加数据时,通过锁机制确保线程安全,避免数据丢失或重复。
data_lock = threading.Lock() # 线程锁,确保线程安全
with data_lock:
data.append([price, name, description, address, validation])
8. 数据去重与清洗(可选)
为了确保数据的准确性和唯一性,程序可以在数据存储前进行去重和清洗操作。例如,使用pandas的drop_duplicates方法去除重复记录,或根据具体需求对数据进行格式化和修正。
# 去除重复记录
df.drop_duplicates(inplace=True)
# 数据清洗示例
df['价格'] = df['价格'].str.replace('¥', '').astype(float)
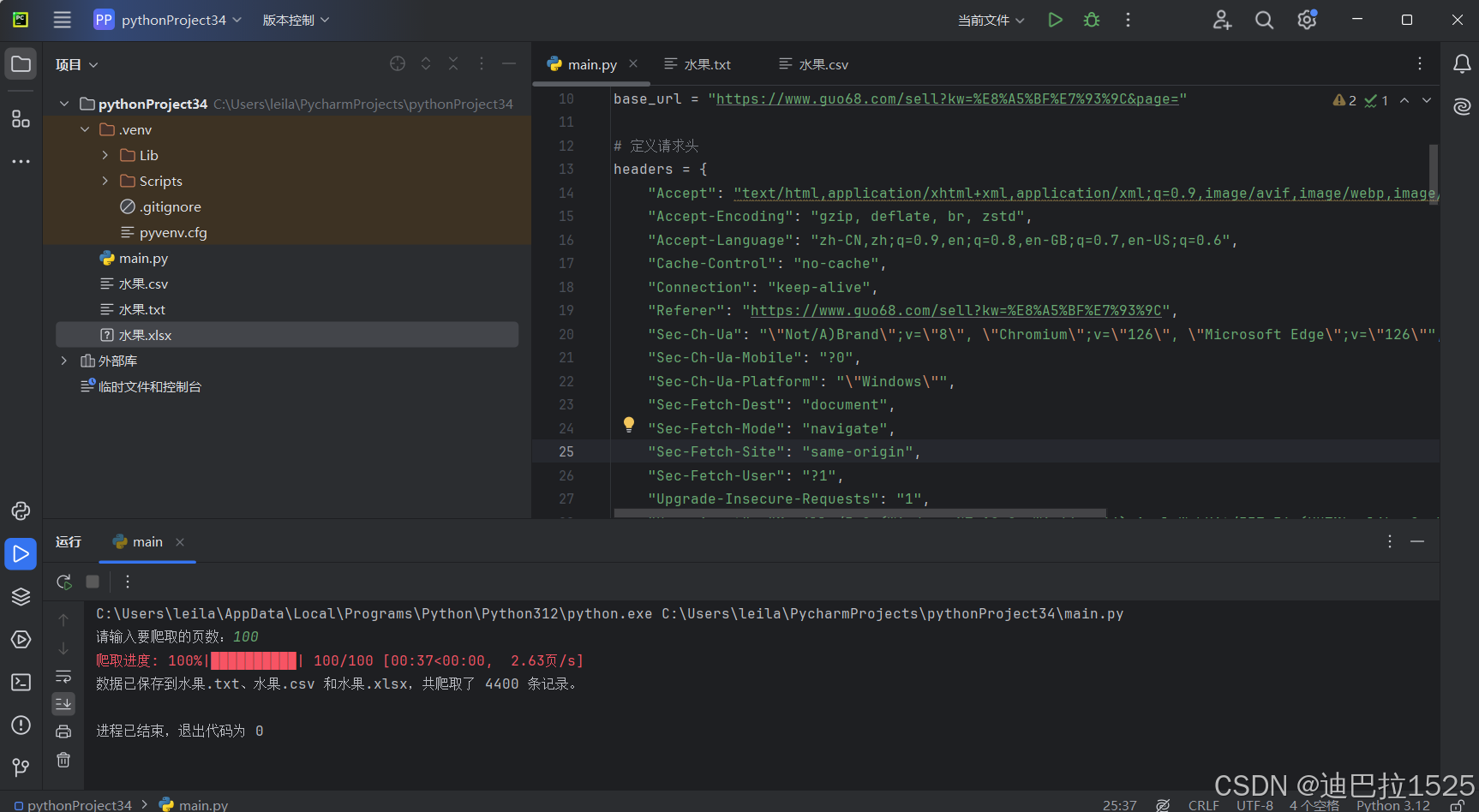
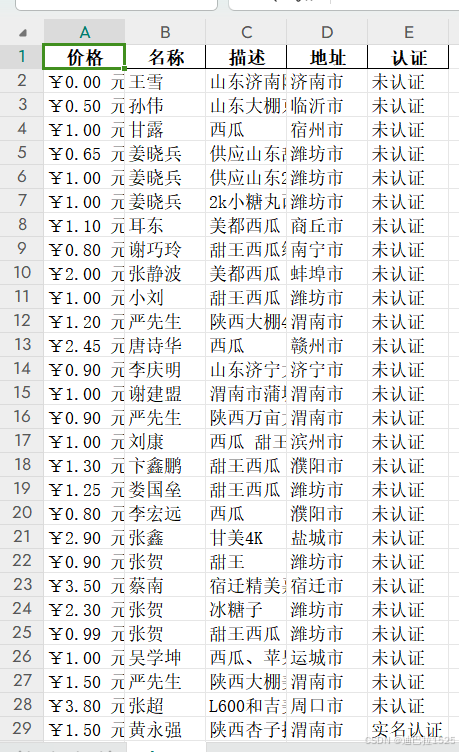
四、运行结果展示
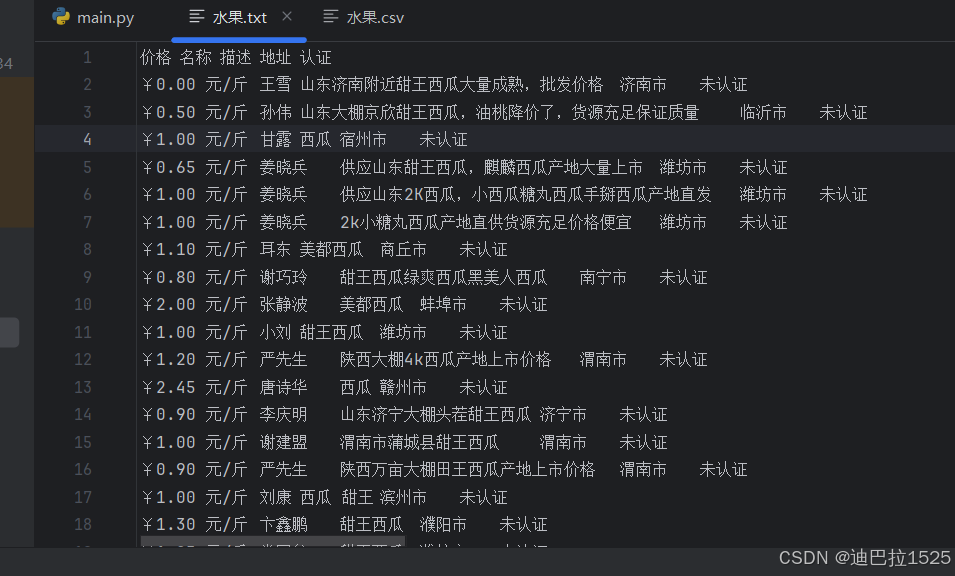
五、完整代码
import requests
from bs4 import BeautifulSoup
import concurrent.futures
import threading
from tqdm import tqdm
import pandas as pd
import time
# 定义基本URL
base_url = "https://www.guo68.com/sell?kw=%E8%A5%BF%E7%93%9C&page="
# 定义请求头
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Referer": "https://www.guo68.com/sell?kw=%E8%A5%BF%E7%93%9C",
"Sec-Ch-Ua": "\"Not/A)Brand\";v=\"8\", \"Chromium\";v=\"126\", \"Microsoft Edge\";v=\"126\"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "\"Windows\"",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
data = []
data_lock = threading.Lock() # 线程锁,确保线程安全
def fetch_page(page, retries=3):
"""
爬取指定页码的数据并添加到全局数据列表中。
"""
url = base_url + str(page)
attempt = 0
while attempt < retries:
try:
response = requests.get(url, headers=headers, timeout=20) # 增加超时时间
response.raise_for_status()
break # 请求成功,跳出重试循环
except requests.exceptions.RequestException as e:
attempt += 1
print(f"请求页面 {url} 时出错: {e}。尝试重新请求 ({attempt}/{retries})...")
time.sleep(2) # 等待2秒后重试
else:
print(f"请求页面 {url} 失败,跳过。")
return
soup = BeautifulSoup(response.text, 'lxml')
items = soup.find_all('li', class_='fruit')
if not items:
print(f"页面 {page} 没有找到任何数据。")
return
for item in items:
price = item.find('span', class_='price').get_text(strip=True)
name = item.find('span', class_='name').get_text(strip=True)
description = item.find('p', class_='describe').get_text(strip=True)
address = item.find('p', class_='address').get_text(strip=True)
validation = item.find('span', class_='simin').get_text(strip=True)
with data_lock:
data.append([price, name, description, address, validation])
def main():
"""
主函数,负责获取用户输入的页数,启动多线程爬取,并保存数据。
"""
while True:
try:
num_pages = int(input("请输入要爬取的页数:"))
if num_pages < 1:
print("请输入一个正整数。")
continue
break
except ValueError:
print("请输入一个有效的整数。")
pages = list(range(1, num_pages + 1))
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
# 使用tqdm包裹executor.map以显示进度条
for _ in tqdm(executor.map(fetch_page, pages), total=len(pages), desc="爬取进度", unit="页"):
pass
if data:
# 转换为DataFrame
df = pd.DataFrame(data, columns=['价格', '名称', '描述', '地址', '认证'])
# 保存为TXT文件
df.to_csv('水果.txt', sep='\t', index=False, encoding='utf-8-sig')
# 保存为CSV文件
df.to_csv('水果.csv', index=False, encoding='utf-8-sig')
# 保存为Excel文件(移除encoding参数)
df.to_excel('水果.xlsx', index=False)
print(f"数据已保存到水果.txt、水果.csv 和水果.xlsx,共爬取了 {len(data)} 条记录。")
else:
print("没有爬取到任何数据。")
if __name__ == "__main__":
main()
六、联系作者
作者微信17396163420

















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









