






一、程序功能概述
本程序使用 Python 语言编写,基于requests和BeautifulSoup库,实现从起点中文网指定小说页面(以《诡秘之主》为例)抓取小说章节列表及其对应内容,并将每个章节内容保存为本地文本文件,方便用户离线阅读。
二、开发环境与依赖库
- 开发环境:Python 3.x(建议使用 Python 3.6 及以上版本)。
- 依赖库
requests:用于发送 HTTP 请求,获取网页内容。BeautifulSoup:用于解析 HTML 页面,提取所需信息。tqdm:用于在程序运行时显示进度条,直观展示抓取进度。logging:用于记录程序运行过程中的重要信息和错误信息,便于调试和问题排查 。
三、代码结构详解
(一)配置信息部分
python
# 配置信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://book.qidian.com/'
}
base_url = 'https://www.qidian.com/book/1010535386/' # 请确认这个 URL 是否正确
save_path = './诡秘之主/'
headers:模拟浏览器请求头信息。User-Agent字段伪装成 Chrome 浏览器,避免被网站识别为爬虫而拒绝访问;Referer字段指定请求来源页面,符合正常网页访问逻辑。base_url:指定要抓取的小说目录页 URL,需根据实际小说页面进行准确设置。save_path:定义本地保存小说章节文件的路径,程序运行时会在此路径下创建相应文件夹并保存文件。
(二)通用请求与解析函数fetch_and_parse
python
def fetch_and_parse(url):
"""
通用的请求和解析 HTML 的函数
"""
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'lxml')
return soup
except requests.exceptions.RequestException as e:
logging.error(f"请求 {url} 失败: {e}")
return None
该函数实现了发送 HTTP 请求并解析响应内容的通用逻辑:
- 使用
requests.get方法发送 GET 请求获取网页内容,传入目标url和请求头headers。 response.raise_for_status()用于检查请求是否成功,若响应状态码不是 200,将抛出异常。- 设置
response.encoding = 'utf-8'指定响应内容的编码格式为 UTF-8,确保正确解析。 - 使用
BeautifulSoup库,以lxml解析器解析响应的 HTML 文本,返回解析后的soup对象,方便后续提取信息。 - 若请求过程中发生异常(如网络连接失败、服务器响应错误等),通过
logging.error记录错误信息,并返回None。
(三)获取章节列表函数get_chapter_list
python
def get_chapter_list():
"""获取章节列表"""
soup = fetch_and_parse(base_url)
if soup is None:
return []
chapter_list = []
try:
chapters = soup.find('div', class_='new - volume - class').find_all('a', class_='chapter-name')
for chapter in chapters:
chapter_url = 'https://book.qidian.com' + chapter['href']
chapter_title = chapter.text.strip()
chapter_list.append((chapter_title, chapter_url))
return chapter_list
except AttributeError as e:
logging.error(f"解析章节列表时发生属性错误: {e}")
return []
except Exception as e:
logging.error(f"获取章节列表时发生未知错误: {e}")
return []
- 首先调用
fetch_and_parse函数获取小说目录页的解析对象soup,若soup为None,说明请求或解析失败,直接返回空列表。 - 使用
soup.find('div', class_='new - volume - class')定位包含章节列表的div元素,再通过find_all('a', class_='chapter-name')获取所有章节链接的<a>标签。 - 遍历每个章节链接标签,提取
href属性值拼接成完整的章节 URL,同时提取章节标题并去除首尾空白字符,将章节标题和 URL 以元组形式添加到chapter_list列表中。 - 若在解析过程中发生
AttributeError(如找不到指定的 HTML 元素)或其他未知异常,记录错误信息并返回空列表。
(四)获取章节内容函数get_chapter_content
python
def get_chapter_content(url):
"""获取章节内容"""
time.sleep(1)
soup = fetch_and_parse(url)
if soup is None:
return None
try:
content_div = soup.find('div', id='chapter-1')
if content_div is None:
raise ValueError("未找到章节正文内容的div元素")
for tag in content_div.find_all(['script', 'div', 'a']):
tag.decompose()
content = '\n'.join([p.text.strip() for p in content_div.find_all('p')])
return content
except AttributeError as e:
logging.error(f"解析章节内容时发生属性错误: {e}")
return None
except ValueError as e:
logging.error(f"解析章节内容时发生值错误: {e}")
return None
except Exception as e:
logging.error(f"获取章节内容时发生未知错误: {e}")
return None
- 为避免请求过于频繁被网站封禁,使用
time.sleep(1)暂停 1 秒后再发送请求。 - 调用
fetch_and_parse函数获取章节页面的解析对象soup,若soup为None,返回None。 - 使用
soup.find('div', id='chapter-1')查找包含章节正文的div元素,若未找到则抛出ValueError异常。 - 遍历正文
div元素内的<script>、<div>、<a>等标签,使用decompose方法将其从文档树中移除,清理广告和无关内容。 - 提取剩余
<p>标签内的文本内容,去除首尾空白字符后,使用换行符\n连接成完整的章节正文内容并返回。 - 若在解析过程中发生
AttributeError、ValueError或其他未知异常,记录错误信息并返回None。
(五)保存章节函数save_chapter
python
def save_chapter(title, content):
"""保存章节到文件"""
valid_title = "".join([c for c in title if c.isalnum() or c in (' ', '.', '_')])
if not os.path.exists(save_path):
try:
os.makedirs(save_path)
except OSError as e:
logging.error(f"创建保存路径失败: {e}")
return
file_name = os.path.join(save_path, f"{valid_title}.txt")
try:
with open(file_name, 'w', encoding='utf-8') as f:
f.write(content)
logging.info(f"保存成功: {valid_title}")
except IOError as e:
logging.error(f"保存章节文件时发生I/O错误: {e}")
- 对章节标题进行处理,去除其中的非法字符,只保留字母、数字、空格、点号和下划线,生成合法的文件名
valid_title。 - 使用
os.path.exists检查保存路径是否存在,若不存在则使用os.makedirs尝试创建,若创建失败记录错误信息并返回。 - 使用
os.path.join将保存路径和合法文件名拼接成完整的文件路径file_name。 - 以写入模式打开文件,将章节内容写入文件,若写入成功通过
logging.info记录保存成功信息;若发生 I/O 错误(如磁盘空间不足、文件权限问题等),记录错误信息。
(六)主函数main
python
def main():
chapters = get_chapter_list()
for title, url in tqdm(chapters, desc="正在抓取章节"):
content = get_chapter_content(url)
if content:
save_chapter(title, content)
if __name__ == '__main__':
main()
- 调用
get_chapter_list函数获取小说所有章节的标题和 URL 列表chapters。 - 使用
for循环遍历chapters列表,通过tqdm库显示进度条,直观展示抓取进度。 - 对于每个章节,调用
get_chapter_content函数获取章节内容,若获取到有效内容,则调用save_chapter函数将其保存为本地文本文件。 if __name__ == '__main__':语句确保main函数仅在当前脚本直接运行时执行,避免被其他模块导入时意外调用。
四、程序运行与调试
- 安装依赖库:在命令行中执行
pip install requests beautifulsoup4 tqdm安装所需依赖库。 - 运行程序:在命令行切换到程序所在目录,执行
python 程序文件名.py(假设程序文件名为novel_crawler.py,则执行python novel_crawler.py)。 - 查看结果:程序运行完成后,在指定的
save_path路径下会生成保存小说章节的文件夹和对应文本文件,可打开查看章节内容。 - 调试与排错:若程序运行出现错误,可通过查看
logging记录的错误信息定位问题,检查 URL 是否正确、HTML 元素选择器是否准确、网络连接是否正常等,并根据错误提示进行相应修改。
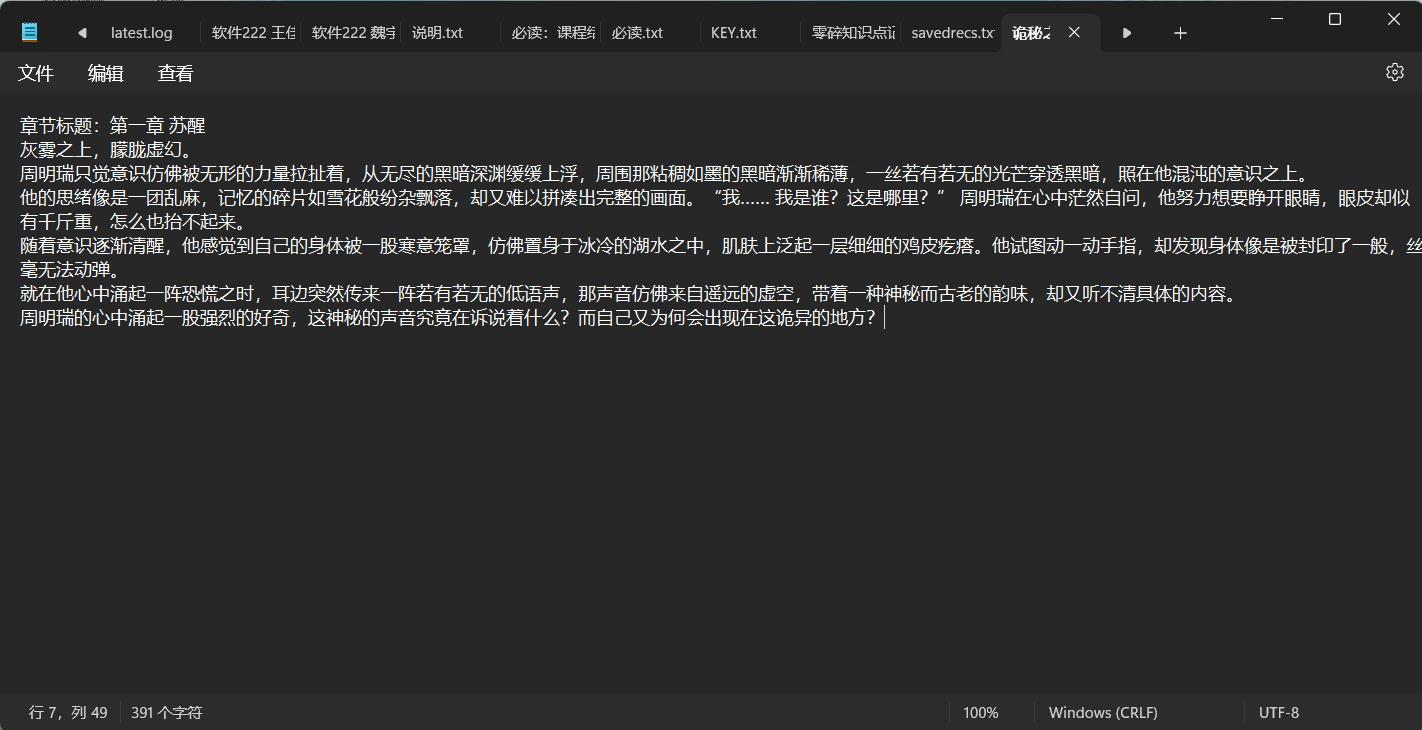
结果图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









