







 本文详细介绍了无头单向非循环链表的实现,包括结构体设计、打印、创建新节点、头插、尾插、指定位置插入、删除、查找和修改数据等操作,强调了链表在逻辑结构上的连续性和使用二级指针的原因。
本文详细介绍了无头单向非循环链表的实现,包括结构体设计、打印、创建新节点、头插、尾插、指定位置插入、删除、查找和修改数据等操作,强调了链表在逻辑结构上的连续性和使用二级指针的原因。
完整代码链接:DataStructure: 基本数据结构的实现。 (gitee.com)
目录
一、链表的含义:
链表在存储结构上是非连续、非顺序的(每次只在堆上开辟一个结点的特性决定),在逻辑结构上,各数据元素之间的连接,是通过链表中的指针实现的(通过获得下一个结点的地址找到下一个结点)。总的来说:链表在逻辑结构上连续,在物理结构上不一定连续。
二、链表产生的原因:
弥补顺序表的不足。
三、链表的分类:
链表可以分为:单向 / 双向链表;带头结点 / 不带头结点的链表;循环 / 非循环链表。
我们主要学习两种:
①.无头单向非循环链表:结构简单,一般不会单独用来存数据。而是更多的作为其他数据结构的子结构,如哈希桶、图的邻接表等。这种结构在笔试面试的时候经常出现。
②.带头双向循环链表:结构最复杂,一般用在单独存储数据。在实际中使用中,几乎都是带头双向循环链表,使用起来很方便。
无头单向非循环链表:

带头双向循环链表:

四、无头单向非循环链表的实现:
1.结构体设计:
对于链表的学习,我们可以参照顺序表。我们在现实世界中,要获得数据(比如一个学校的所有学生数据),肯定不是只要一个就行了,而是要一些(有可能不准确,懂我意思就行,(∩_∩) )。而对于顺序表,由于所有数据在内存空间上都是连续的,我们只需要 ++(或 -- )就直接可以找到下一个(或上一个)数据。但是链表不一样,它的产生就是为了节约空间(应该不止这一点),所以它们每个数据很有可能不在同一块内存空间上,但是这些数据在内存空间上都存在自己的地址,所以我们只要知道了它们各自的地址,我们就可以访问到它们了,链表的设计就遵循这一点。
typedef int SLDataType;
typedef struct SingleListNode
{
SLDataType data;
struct SingleListNode* next;
}SLNode;//将struct SingleListNode类型重命名为SLNode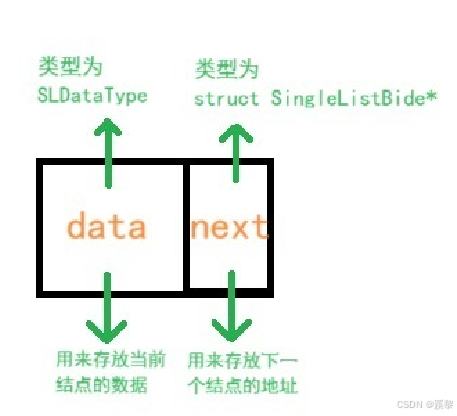

2.打印:
void SingleListPrint(SLNode* phead)
{
SLNode* cur = phead;//定义一个指针遍历所有结点
while (cur != NULL)
{
printf("%d ", cur->data);
cur = cur->next;
}
}3.创建新结点:
SLNode* CreateSingleListNode(SLDataType x)
{
//创建新结点
SLNode* newNode = (SLNode*)malloc(sizeof(SLNode));
if (newNode == NULL)
{
printf("申请结点失败\n");
exit(-1);//堆上开辟空间都能失败,就应该终结程序了
}
newNode->data = x;
newNode->next = NULL;
return newNode;
}4.增加数据:
①.头插:
void SingleListPushFront(SLNode** pphead, SLDataType x)
{
SLNode* newNode = CreateSingleListNode(x);
newNode->next = *pphead;
*pphead = newNode;
}
在这里,大家可能会有个大大的疑惑:为什么传入的是二级指针?
我觉得这句对理解这里应该很重要:二级指针就是指向指针的指针。
首先,我们可以看到这个接口的返回类型是void而不是SLNode*,如果这里的返回类型是SLNode*类型(也就是返回这个链表的头结点),我们就可以不使用传二级指针的方式(因为我们可以直接把这个头结点返回出去,在函数外面用一个相同类型的变量接收它就可以了)。
回到这里,当我们访问一个链表的时候,往往都是通过头结点来进行访问的,所以说,只要我们有了头结点,就可以访问一个链表。
这里我们先假设已经存在一个链表了,我们只需要对其进行头插就可以了。
执行头插操作会使链表的头结点的地址发生变化,头结点的地址是什么?不就是一个一级指针吗。所以,我们的最终目标就确定了——修改头结点的地址(一级指针)。
我们应该知道:我们可以通过一级指针修改它所指向的值(通过解引用)。那么自然而然我们也可以通过二级指针修改它所指向的值(也就是一级指针),这样,我们就可以通过二级指针来修改头结点的地址了,真棒!
最后,我们只需要在新的头结点后面接上原来的链表,然后把原来头结点的地址改为新的头结点的地址就行了。

②.尾插:
void SingleListPushBack(SLNode** pphead, SLDataType x)
{
SLNode* newNode = CreateSingleListNode(x);
if (*pphead == NULL)
{
//当链表还没有结点时
*pphead = newNode;
}
else
{
//找到链表的尾
SLNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newNode;
}
}
可能大家这里又有疑惑了:我尾插又不会影响头结点,那我为什么还要传二级指针呢?
真的吗?那万一这个链表一开始就没有一个结点呢?那我此时执行尾插,头结点会不会变呢?
③.指定结点位置后面插入
void SingleListInsertAfter(SLNode* pos, SLDataType x)
{
assert(pos);
SLNode* newNode = CreateSingleListNode(x);
newNode->next = pos->next;//①
pos->next = newNode;//②
}在目标结点后面插入一个数据为 6 的结点:

这里可以不使用二级指针,因为这个接口是在一个链表已经存在结点的情况下才使用的,并且没法头插(因为是在目标结点后面插入)。
5.删除数据:
①.头删:
void SingleListPopFront(SLNode** pphead)
{
if (*pphead == NULL)//空
{
printf("没有可删除的结点\n");
return;
}
else //一个结点+一个以上结点
{
SLNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
}
为什么这里(*pphead)要加(),因为这里存在运算符的优先级问题。
②.尾删:
void SingleListPopBack(SLNode** pphead)
{
if (*pphead == NULL)//空
{
printf("没有可删除的结点\n");
return;
}
else if ((*pphead)->next == NULL)//一个结点
{
free(*pphead);
*pphead = NULL;
}
else//一个结点以上
{
SLNode* tail = *pphead;
SLNode* prev = NULL;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;
}
}
当我们删到最后一个结点,并且要把它也删了的时候,头指针会变。
最后,我们总结一下:只要涉及到会对头指针进行改变的时候,就需要传二级指针(如果有虚拟头结点,或者函数返回类型是指针类型就不需要)。
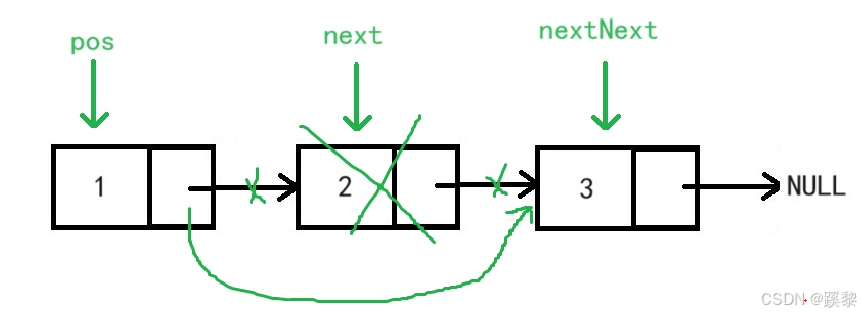
③.指定结点位置后删除:
void SingleListEraseAfter(SLNode* pos)
{
SLNode* next = pos->next;
SLNode* nextNext = next->next;
pos->next = nextNext;
free(next);
next = NULL;
}
6.查找数据:
SLNode* SingleListFind(SLNode* phead, SLDataType x)
{
SLNode* cur = phead;
while (cur != NULL)
{
if (cur->data == x)
{
return cur;//返回目标数据所在的结点
}
else
{
cur = cur->next;
}
}
return NULL;//没找到
}7.修改数据:
我们要修改数据,可以先查找到该数据所在结点,然后再对其数据进行更改。
void SingleListModify(SLNode* phead, SLDataType pre,SLDataType x)
{
//pre表示该结点原来的值
SingleListFind(phead, pre)->data = x;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









