






一、实验环境
VMware、finalShell、hadoop、hive
二、问题呈现

- 小小的tips:
每一次的启动日志都是追加在日志文件之后,所以得拉到最后面看,对比下记录的时间就知道了。一般出错的提示在最后面,通常是写着 Fatal、Error、Warning 或者 Java Exception 的地方
三、错误分析
- 我是在做hadoop下载数据文本的时候出现的问题,在输入flume-ng agent -n a1 --conf-file user_behavior-men-hdfs.conf(这里是根据我的数据日志文件名命名) -Dflume.root.logger=INFO,console 显示我的datanode节点有问题,于是我查看我的进程jps,发现的确少了datanode这个节点
- 所以现在就要想办法把datanode节点恢复过来,使它可以运行,把datanode给提取出来具体查看它的问题解析,提取的指令:more hadoop-root-datanode-hadoop01.log(这里的hadoop01是我的master)
- 出现该问题的原因
多次hdfs格式化后,开始的namenode的clusterID会自动重新生成,而datanode的clusterID 则会保持不变。总结来说如果不删除数据和日志的话,重新格式化namenode会产生新的集群ID,这样会和datanode的集群ID产生冲突,导致namenode启动失败。
其次每次的namenode format都会重新创建一个namenodeId,而data目录下则包含了上次format时的id , namenode ,format。
清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败,所以要做的就是每次fotmat前,清空data下的所有目录(这是最保证的方法)
四、解决办法
- 方法一:这是在本身数据内容不多的情况下进行,数据太多的话恢复会很困难。很难确定恢复完全。!!不管是方法一还是方法二都要先关闭hadoop集群,这里我用的是法二。
- 首先停掉集群,就是先进入到我们hadoop下的sbin文件然后输入:./hadoop.sh stop
- 删除问题节点的data目录下的所有内容。即删除 hadoop 节点配置路径下的残留文件分别是core-site.xml 、hdfs-site.xml 和tmp日志。
- 然后再重新格式化namenode。重新格式化指令:hdfs namenode -format
- 重新启动hadoop指令:同样在hadoop 下的sbin输入:./hadoop.sh start】
!!!还是不懂删除日志的可以看Hadoop 重新格式化NameNode_hadoop namenode -format报错_温岚万叶的博客-CSDN博客
删除指令:rm -rf /opt/service/hadoop/etc/hadoop
- 方法二:
- 首先停掉集群,跟上述的一样指令方法
-
然后将datanode节点目录/dfs/data/current/VERSION中的修改为与namenode一致就是按照错误的提示其实把 data/current/VERSION 中的clusterID 改为和 name/current/VERSION中的clusterID一致。我的是在/opt/service/hadoop/data/dfs/data/current然后根据错误的提示复制修改集群ID就可以了
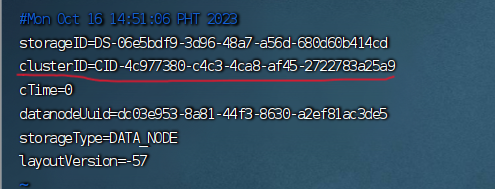
-
之后我们重新启动集群,通过 jps命令查看,结果呈现

- 此时重新扫描配置flume-ng agent -n a1 --conf-file user_behavior-men-hdfs.conf (自己的配置命名)-Dflume.root.logger=INFO,console
然后就可以查看我们浏览器数据然后下载了















 5531
5531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









