






前言
本篇文章主要带来kafka的详细介绍和环境部署
Kafka介绍
Kafka是一种高吞吐量的分布式发布订阅消息系统,可以处理大量的消息数据流。它的设计目标是提供强大的消息传递系统,同时保证高性能、高可用和可扩展性。Kafka最初由LinkedIn公司开发,现已成为Apache项目之一。
在Kafka中,消息被组织成一个或多个主题(topics),而这些主题在一个或多个Kafka节点中进行分区(partitions)和复制(replication),以确保数据的可靠性和高可用性。每个分区都有一个唯一的标识符,称为分区ID,而消息在分区内按照顺序发送和接收。消费者(consumer)可以订阅一个或多个主题,并从它们的分区中读取消息,以便进行下一步处理。
Kafka的作用和使用场景如下:
功能特点
高吞吐量:Kafka能够处理高吞吐量的数据流,适用于大规模消息处理应用。
持久性存储:Kafka将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。数据持久化到硬盘以及replication防止数据丢失。
分布式系统:Kafka是一个分布式系统,易于向外扩展,所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
使用场景
消息队列:Kafka可作为消息队列系统,用于解耦生产者和消费者的处理速度。生产者发送消息到Kafka后,消费者可以在自己的速度上消费这些消息。
实时流处理:Kafka常用于实时流处理,允许处理和分析实时数据。例如,可以实时处理用户生成的日志数据,以进行故障检测或实时分析。
日志聚合:Kafka可以作为日志聚合系统,从多个源收集日志,并使它们可用于实时流处理或批量处理。
事件驱动架构:在事件驱动架构中,Kafka可以作为事件总线,用于在微服务之间传递事件。
数据管道:Kafka可以作为数据管道,将数据从一个系统传输到另一个系统,特别是在大数据和机器学习工作流中。
环境部署
Kafka的环境部署非常简单,并且可以运行在单机或者集群模式下。下面是Kafka的环境部署步骤:
步骤1:下载和解压
在官网下载最新的---------Kafka安装包下载
并解压到任意目录下,例如:
下载文件格式:rz

解压文件格式:tar -zxvf 文件名 解压路径
tar -xzf kafka_2.11-2.4.1.tgz -C /opt/server/
创建软连接:ln -s kafka_2.11-2.4.1 kafka
创建软连接是为了后续方便进入到kafka当中修改配置
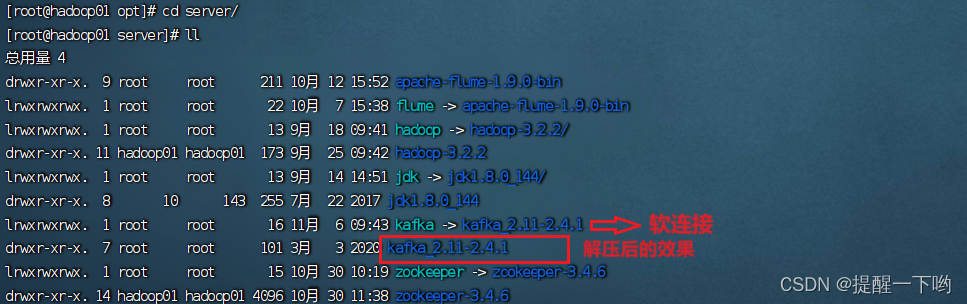
步骤2:启动ZooKeeper
Kafka依赖于ZooKeeper来进行集群管理和状态保存。因此,在启动Kafka之前,必须首先启动ZooKeeper。
启动位置:zookeeper/bin
启动zookeeper: ./zkServer.sh start
查看状态: ./zkServer.sh status
注意:要先启动和查看后两台的状态后第一台的状态才会显示
这是第一台的状态显示
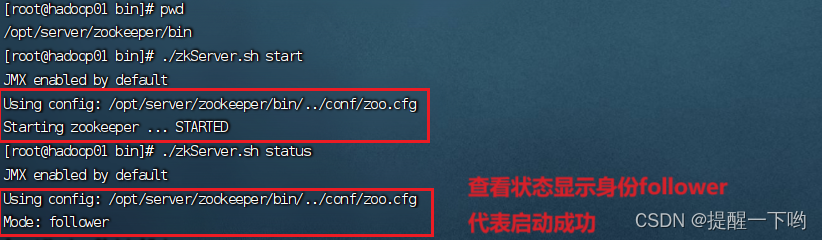
这是第二台的状态显示

这是第三台的状态显示

步骤3:修改配置文件
文件位置:kafka/config
修改文件:vi server.properties
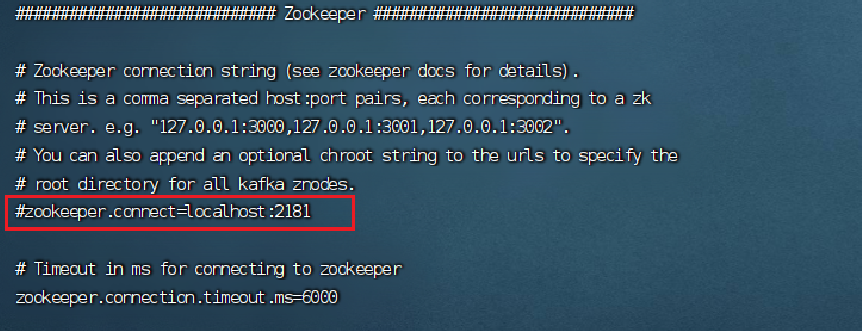
在配置Kafka时,修改broker.id、log.dirs和zookeeper.connect这几个参数是为了满足集群的环境需求、数据存储需求和连接管理需求。
(每一台都要进行修改哟,broker.id不能重复且必须是连在一起的数字)

如果没有logs文件夹可以直接去kafka路径下创建一个

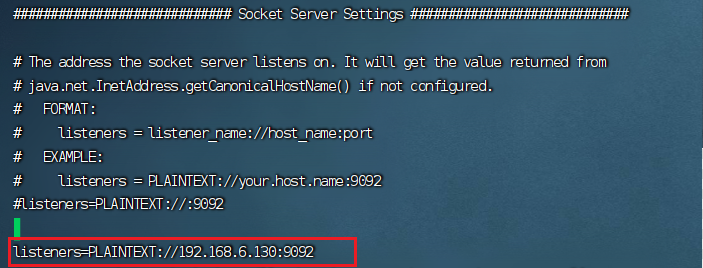
设置listeners是为了让客户端能够连接到Kafka集群并与其进行通信。
将这段话注释
步骤4:启动Kafka
接下来,需要启动一个或多个Kafka节点,可以使用以下脚本来启动:
case $1 in
"start"){
for i in hadoop01 hadoop02 hadoop03
do
echo " --------启动 $i Kafka-------"
ssh $i "source/etc/profile;/opt/server/kafka/bin/kafka-server-start.sh -daemon /opt/server/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop01 hadoop02 hadoop03
do
echo " --------停止 $i Kafka-------"
ssh $i "source/etc/profile;/opt/server/kafka/bin/kafka-server-stop.sh stop"
done
};;
esac
启动脚本:./脚本文件 start
在jps进程中出现kafka代表启动成功
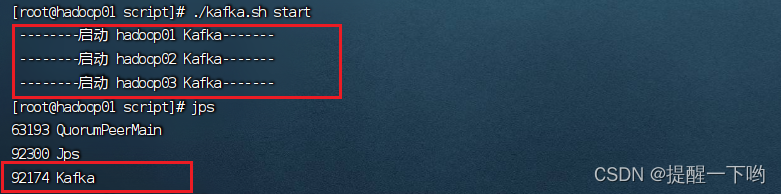
到此为止,Kafka的环境部署完成了。
总结
在实际应用中,可以根据自己的需求来配置和使用Kafka,例如设置分区数量、副本数量、数据保留策略等等。Kafka是一个非常强大和灵活的消息系统,可以用于解决各种应用场景中的大数据处理问题。希望本篇文章能够帮助到大家!















 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









