






文章目录
前言
在当今全球化的时代,翻译成为了日常生活中不可或缺的一部分。为了简化翻译的工作流,我们可以使用Selenium来实现自动化的翻译过程。本文将介绍如何使用Selenium库编写一个自动翻译脚本,以有道翻译为例,实现输入文本的自动翻译。
一、准备工作
在开始编写脚本之前,我们需要确保已经安装了Selenium库,并且下载了对应浏览器的驱动程序。这里以Chrome浏览器为例,需要下载Chrome驱动程序(chromedriver.exe),并将其存放在合适的路径下。
具体的可以看一下这篇博客Chrome驱动安装步骤:版本选择与配置全解析
二、编写自动化脚本
1. 导入必要的库和模块
我们需要导入Selenium库中的webdriver模块,以及time库用于设置停顿时间。同时,我们还需要导入Selenium的其他模块,用于定位元素和等待元素出现。
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
2. 加载浏览器驱动
通过指定Chrome驱动程序的路径,我们创建一个Chrome浏览器实例。这样,我们就可以通过脚本来控制浏览器了。
driver = webdriver.Chrome(r"C:/Program Files/Google/Chrome/Application/chromedriver.exe")
3. 获取网页地址
通过调用get方法,我们让浏览器打开有道翻译的网页。
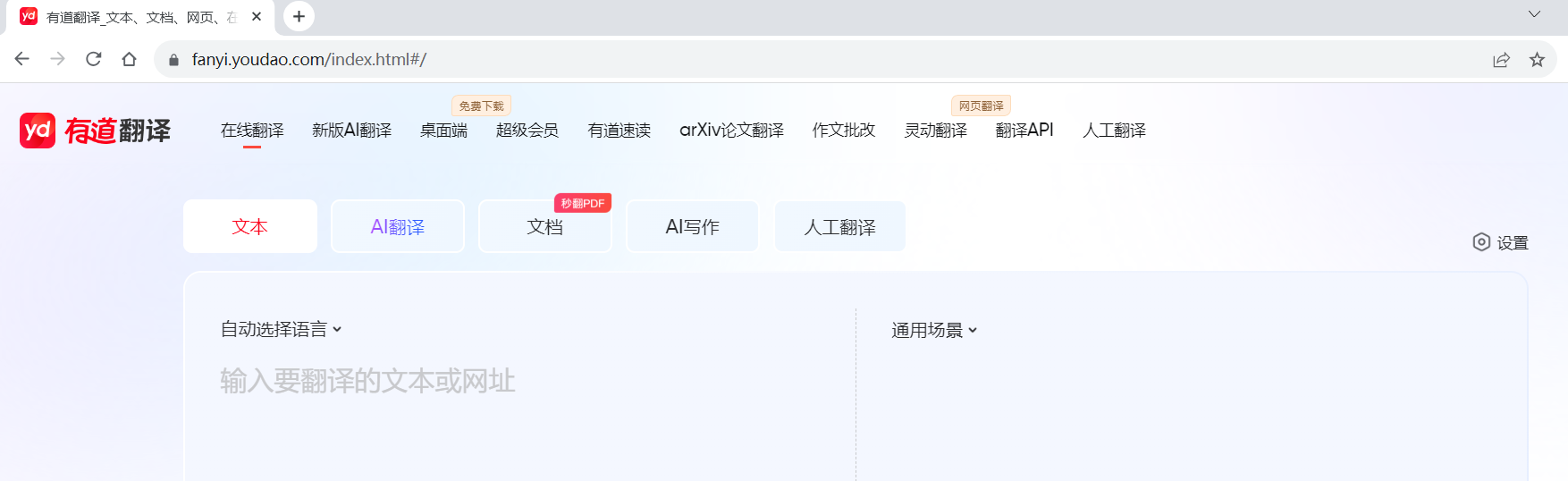
driver.get('https://fanyi.youdao.com/index.html#/')
4. 关闭弹窗框
这里通过WebDriverWait和EC模块,等待指定的元素出现,并在出现后关闭弹窗框。这样可以确保在进行后续操作前,不会受到弹窗框的干扰。
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '/html/body/div[4]/div/img[2]'))
)
element.click()
5. 定位搜索框元素并输入文本
首先,我们通过ID定位到搜索框元素。然后,使用input函数接收用户输入的文本,并将其输入到搜索框中。
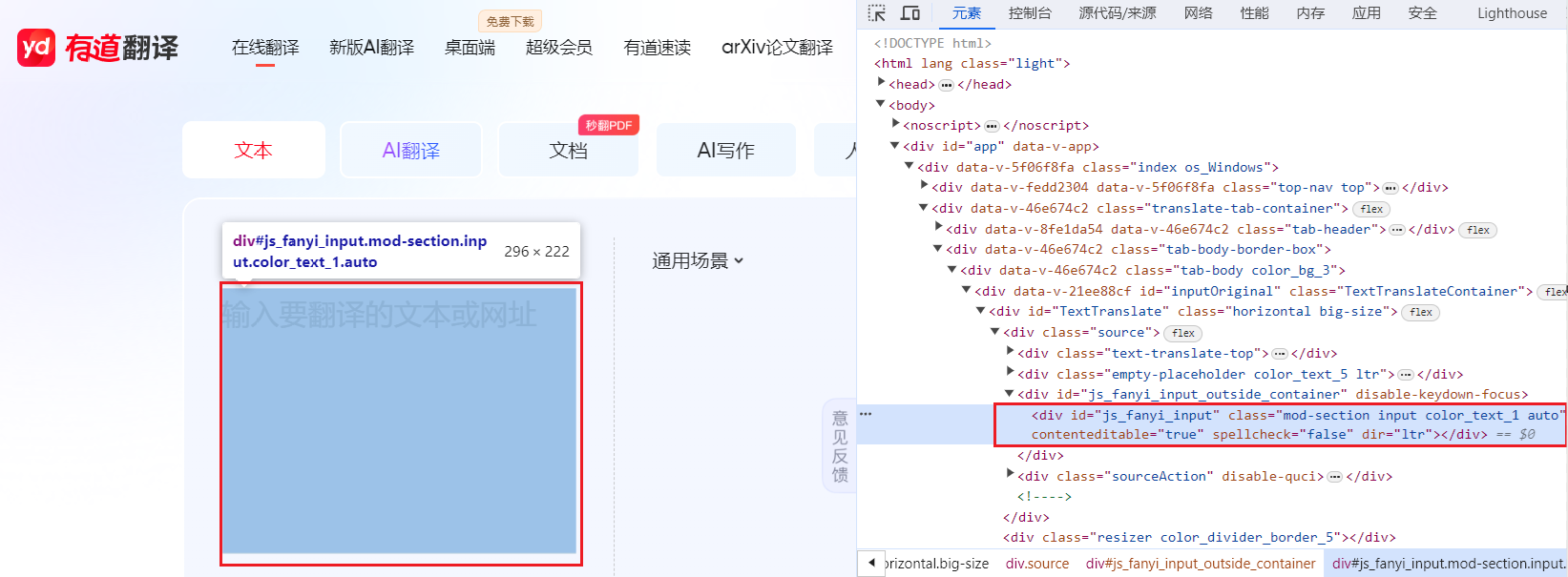
ssk = driver.find_element(By.ID,'js_fanyi_input')
translate = input('请输入翻译内容:')
ssk.send_keys(translate)
6. 获取翻译结果并打印
通过设置停顿时间,确保网页有足够的时间响应输入。然后,通过XPath定位到翻译结果的元素,并打印出翻译结果。
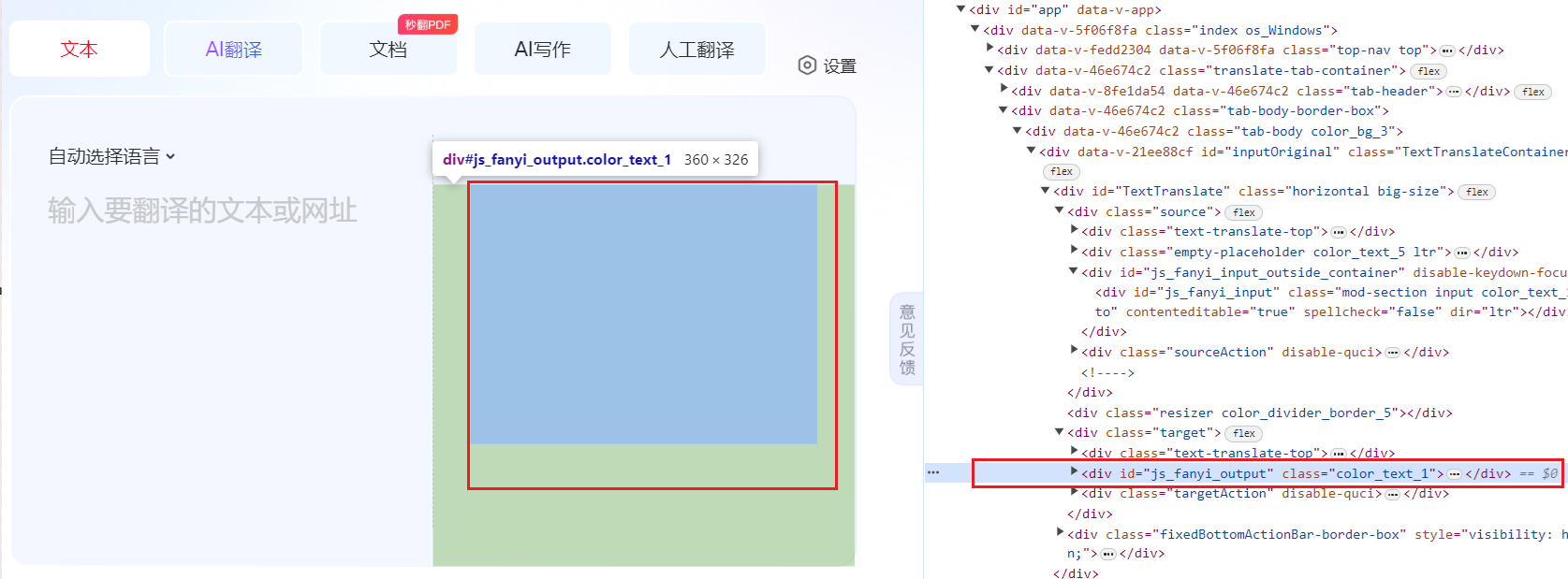
time.sleep(5)
wenben = driver.find_element(By.XPATH,'//*[@id="js_fanyi_output_resultOutput"]/p/span')
print(f'输入内容:{translate},翻译结果:',wenben.text)
7. 退出浏览器
最后,再次设置停顿时间,然后关闭浏览器,结束自动化脚本的运行。
三、总结与展望
通过以上步骤,我们成功地使用Selenium实现了一个简单的有道翻译自动化脚本。当然,这个脚本只是一个基础示例,实际应用中还可以根据需求添加更多高级功能。希望本文能为你提供一些启示和帮助,让你更深入地了解Selenium的应用。在未来的学习和探索中,你可以尝试使用Selenium实现更多有趣和实用的自动化脚本,提高你的工作效率和自动化水平。















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









