







Flink CDC
阿里云Flink CDC 2.0 详细介绍-阿里云开发者社区 (aliyun.com)
一 概述
Change Data Capture 捕获数据变更技术(主要面向数据库的变更)
1. 应用场景
- **数据同步:**用于备份,容灾;
- **数据分发:**一个数据源分发给多个下游系统;
- **数据采集:**面向数据仓库 / 数据湖的 ETL 数据集成,是非常重要的数据源。
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
-
基于查询的 CDC:
-
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟。
-
基于日志的 CDC:
-
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
对比常见的开源 CDC 方案,我们可以发现:

-
对比增量同步能力,
-
- 基于日志的方式,可以很好的做到增量同步;
- 而基于查询的方式是很难做到增量同步的。
-
对比全量同步能力,基于查询或者日志的 CDC 方案基本都支持,除了 Canal。
-
而对比全量 + 增量同步的能力,只有 Flink CDC、Debezium、Oracle Goldengate 支持较好。
-
从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
-
在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
-
- 在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
- 但是像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
-
另外,在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
二 项目
1. Dynamic Table & ChangeLog Stream
大家都知道 Flink 有两个基础概念:Dynamic Table 和 Changelog Stream。
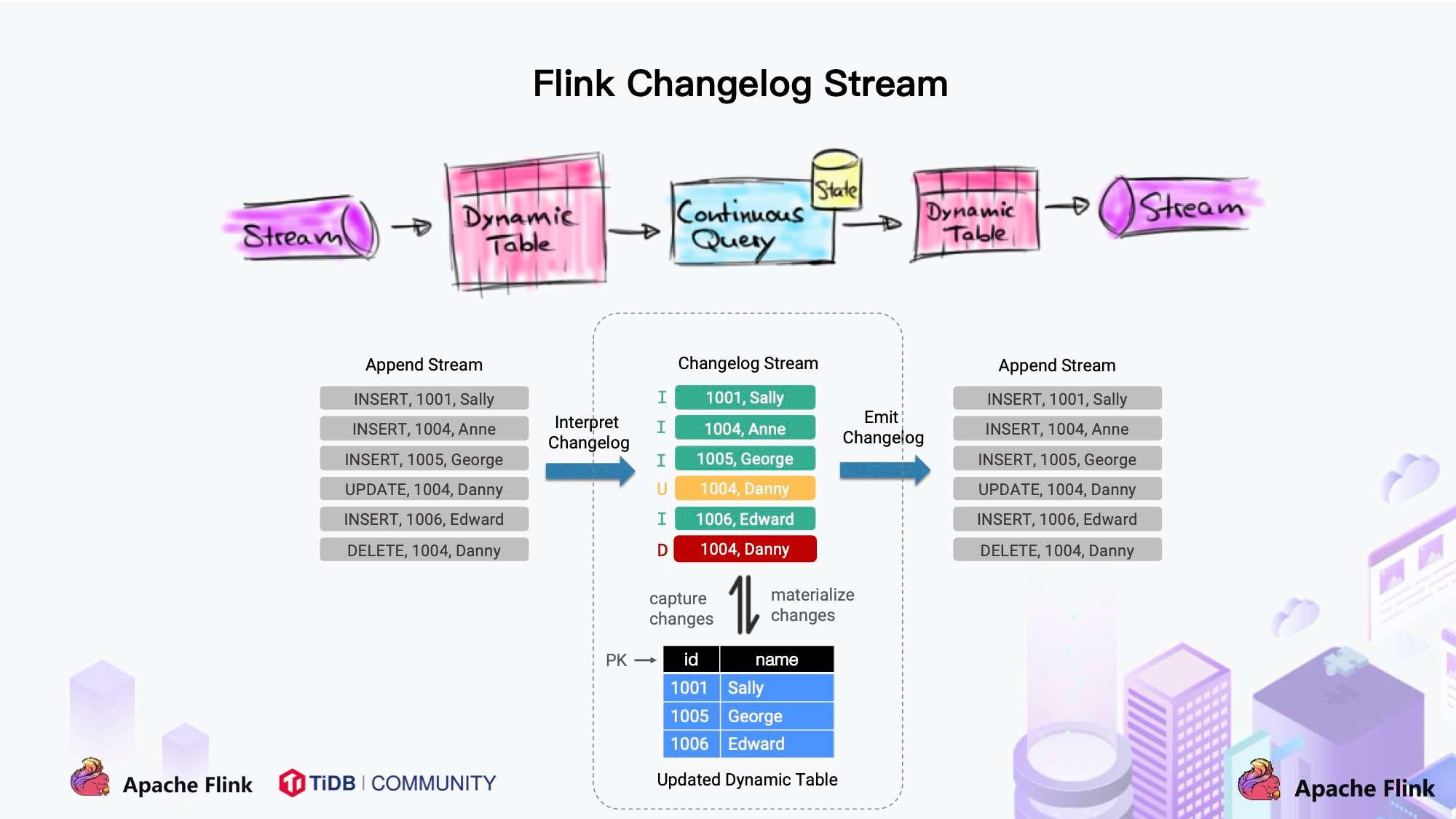
- Dynamic Table 就是 Flink SQL 定义的动态表,动态表和流的概念是对等的。参照上图,流可以转换成动态表,动态表也可以转换成流。
- 在 Flink SQL中,数据在从一个算子流向另外一个算子时都是以 Changelog Stream 的形式,任意时刻的 Changelog Stream 可以翻译为一个表,也可以翻译为一个流。
联想下 MySQL 中的表和 binlog 日志,就会发现:MySQL 数据库的一张表所有的变更都记录在 binlog 日志中,如果一直对表进行更新,binlog 日志流也一直会追加,数据库中的表就相当于 binlog 日志流在某个时刻点物化的结果;日志流就是将表的变更数据持续捕获的结果。这说明 Flink SQL 的 Dynamic Table 是可以非常自然地表示一张不断变化的 MySQL 数据库表。

在此基础上,我们调研了一些 CDC 技术,最终选择了 Debezium 作为 Flink CDC 的底层采集工具。Debezium 支持全量同步,也支持增量同步,也支持全量 + 增量的同步,非常灵活,同时基于日志的 CDC 技术使得提供 Exactly-Once 成为可能。
将 Flink SQL 的内部数据结构 RowData 和 Debezium 的数据结构进行对比,可以发现两者是非常相似的。
- 每条 RowData 都有一个元数据 RowKind,包括 4 种类型, 分别是插入 (INSERT)、更新前镜像 (UPDATE_BEFORE)、更新后镜像 (UPDATE_AFTER)、删除 (DELETE),这四种类型和数据库里面的 binlog 概念保持一致。
- 而 Debezium 的数据结构,也有一个类似的元数据 op 字段, op 字段的取值也有四种,分别是 c、u、d、r,各自对应 create、update、delete、read。对于代表更新操作的 u,其数据部分同时包含了前镜像 (before) 和后镜像 (after)。
通过分析两种数据结构,Flink 和 Debezium 两者的底层数据是可以非常方便地对接起来的,大家可以发现 Flink 做 CDC 从技术上是非常合适的。
2. 传统 CDC ETL 分析
Extract Transform Load
我们来看下传统 CDC 的 ETL 分析链路,如下图所示:
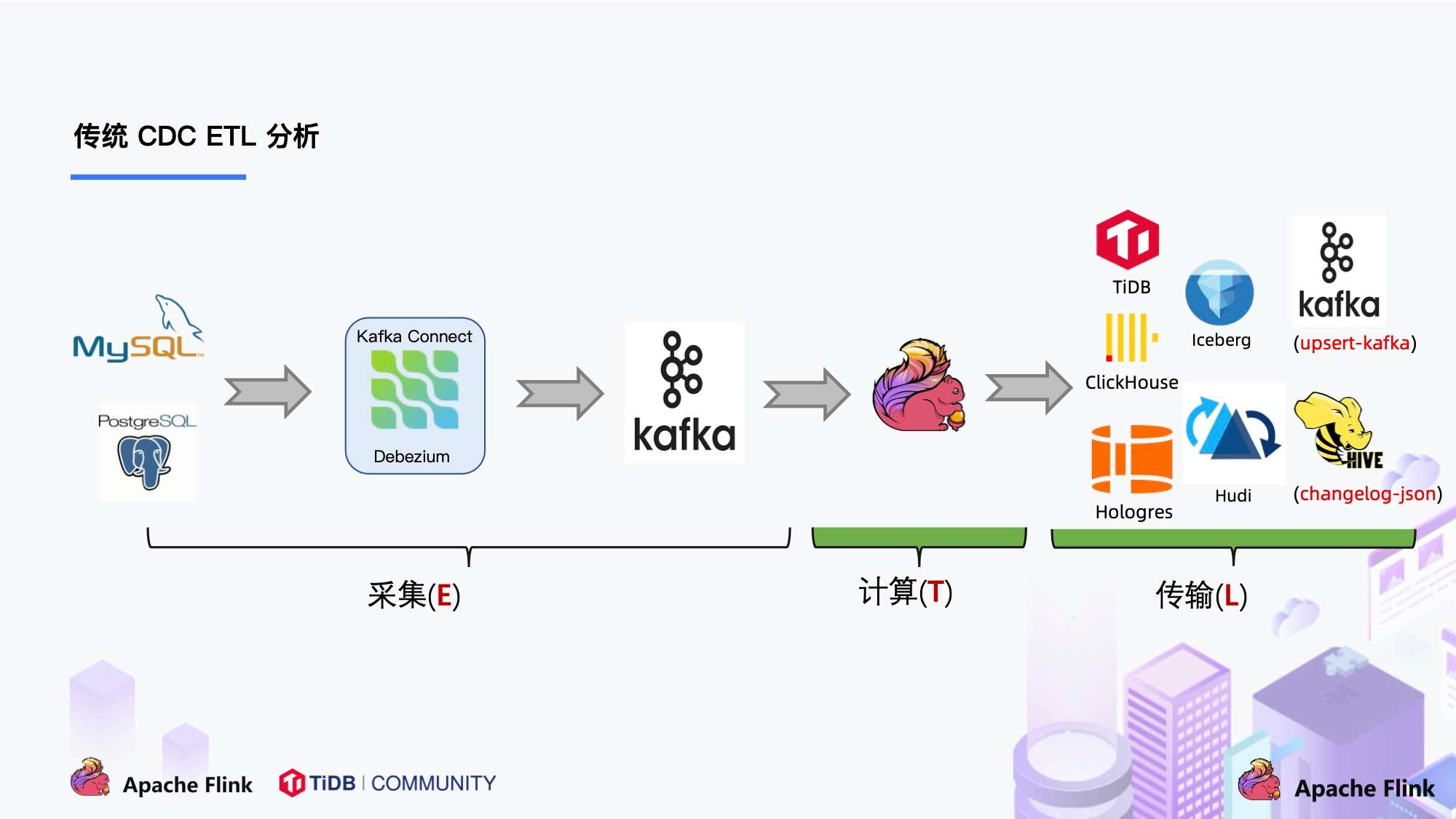
传统的基于 CDC 的 ETL 分析中,数据采集工具是必须的,国外用户常用 Debezium,国内用户常用阿里开源的 Canal,采集工具负责采集数据库的增量数据,一些采集工具也支持同步全量数据。采集到的数据一般输出到消息中间件如 Kafka,然后 Flink 计算引擎再去消费这一部分数据写入到目的端,目的端可以是各种 DB,数据湖,实时数仓和离线数仓。
注意,Flink 提供了 changelog-json format,可以将 changelog 数据写入离线数仓如 Hive / HDFS;对于实时数仓,Flink 支持将 changelog 通过 upsert-kafka connector 直接写入 Kafka。
我们一直在思考是否可以使用 Flink CDC 去替换上图中虚线框内的采集组件和消息队列,从而简化分析链路,降低维护成本。同时更少的组件也意味着数据时效性能够进一步提高。答案是可以的,于是就有了我们基于 Flink CDC 的 ETL 分析流程。
3. 基于 Flink CDC 的 ETL 分析
在使用了 Flink CDC 之后,除了组件更少,维护更方便外,另一个优势是通过 Flink SQL 极大地降低了用户使用门槛,可以看下面的例子: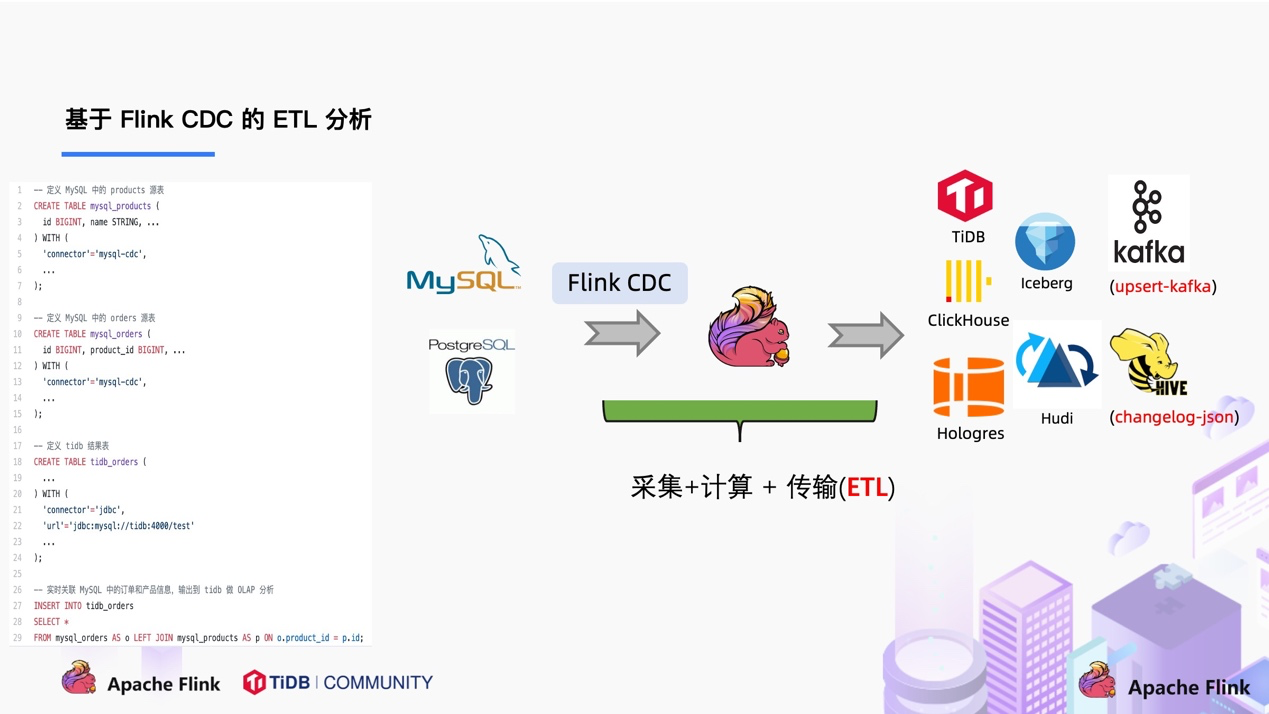
该例子是通过 Flink CDC 去同步数据库数据并写入到 TiDB,用户直接使用 Flink SQL 创建了产品和订单的 MySQL-CDC 表,然后对数据流进行 JOIN 加工,加工后直接写入到下游数据库。通过一个 Flink SQL 作业就完成了 CDC 的数据分析,加工和同步。
大家会发现这是一个纯 SQL 作业,这意味着只要会 SQL 的 BI,业务线同学都可以完成此类工作。与此同时,用户也可以利用 Flink SQL 提供的丰富语法进行数据清洗、分析、聚合。
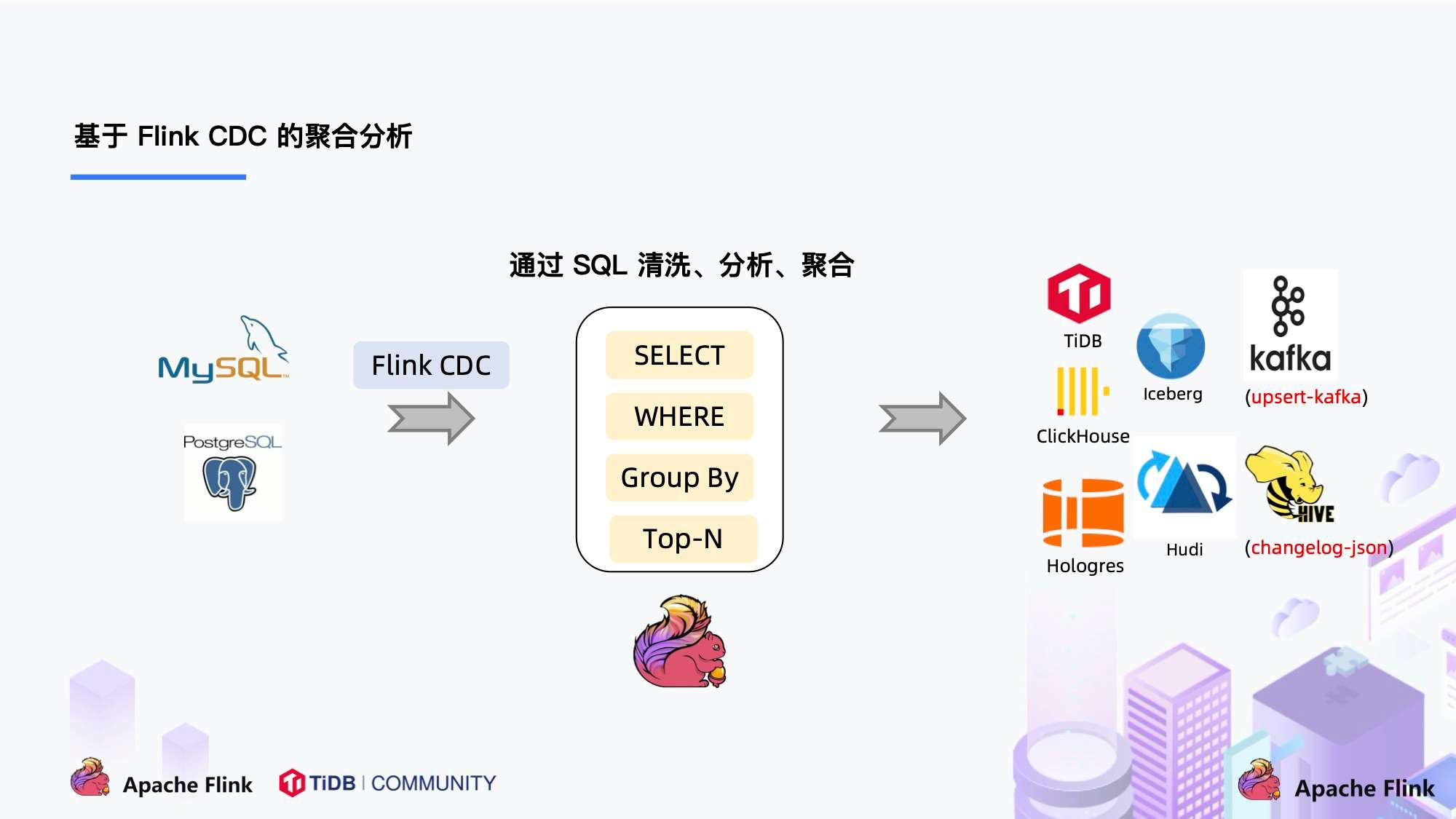
而这些能力,对于现有的 CDC 方案来说,进行数据的清洗,分析和聚合是非常困难的。
此外,利用 Flink SQL 双流 JOIN、维表 JOIN、UDTF 语法可以非常容易地完成数据打宽,以及各种业务逻辑加工。

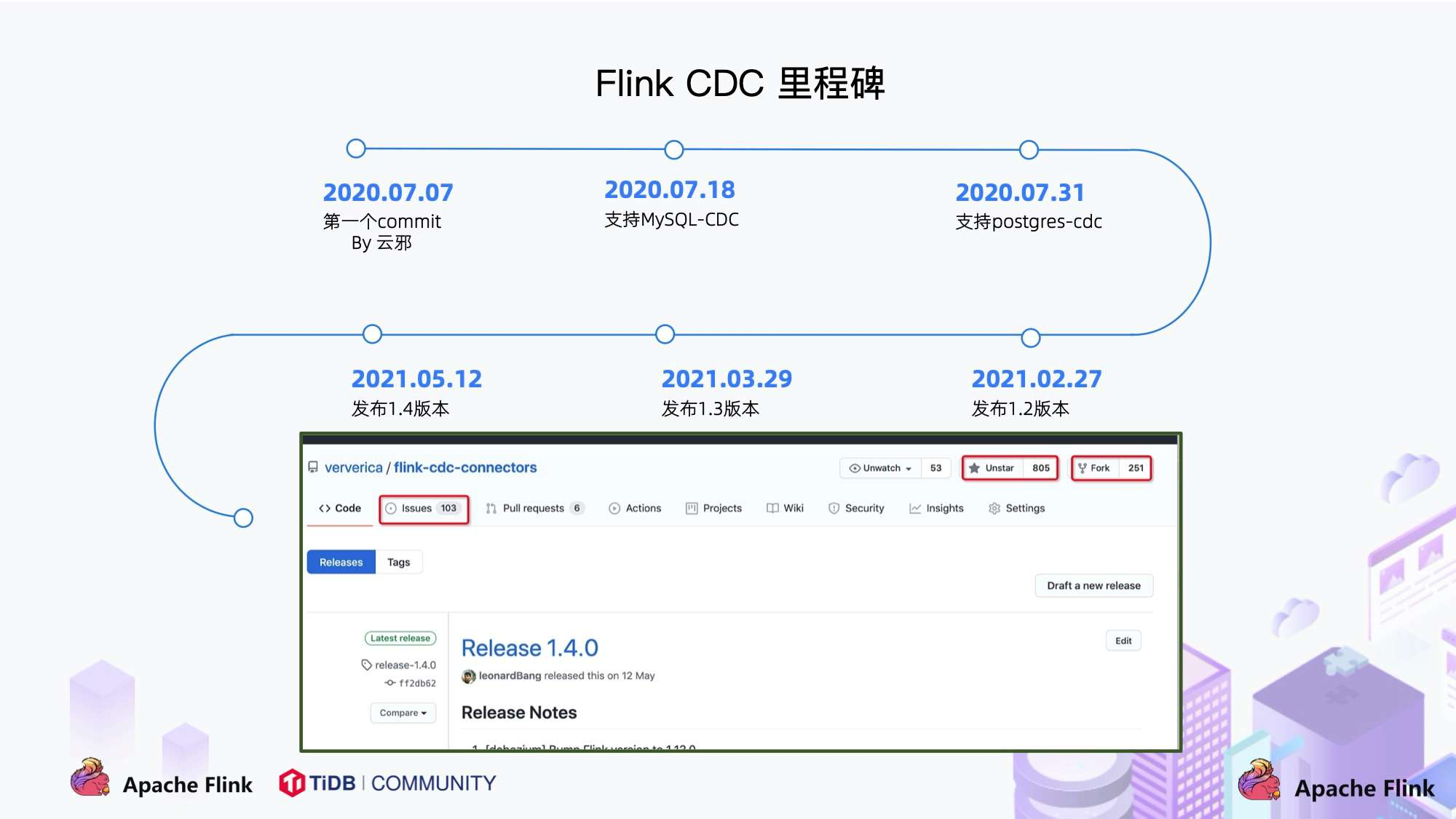
4. Flink CDC 项目发展
- 2020 年 7 月由云邪提交了第一个 commit,这是基于个人兴趣孵化的项目;
- 2020 年 7 中旬支持了 MySQL-CDC;
- 2020 年 7 月末支持了 Postgres-CDC;
- 一年的时间,该项目在 GitHub 上的 star 数已经超过 800。
三 Flink CDC 2.0 详解
。。。见原文,有点点复杂














 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









