







1、ORA-19706
[oracle@testos:/home/oracle]$ oerr ora 19706
19706, 00000, "invalid SCN"
// *Cause: The input SCN is either not a positive integer or too large.
// *Action: Check the input SCN and make sure it is a valid SCN.
[oracle@testos:/home/oracle]$
目前有数据库A,数据库B,数据库A通过DBlink连接数据库B报错ORA-19706: Invalid SCN.数据库A版本是10G,数据库B是11.2.0.4。
在两个库通过db link进行分布式事务时,假设A库的SCN值要高于B库的SCN,因此A库的SCN增同步到B库,如果A库的SCN过高,同步到B库之后,使得B库面临Headroom过小的风险,那么B库会拒绝同步SCN,这个时候就会报ORA-19706: Invalid SCN错误
SCN相关概念
| 相关概念 | 说明 |
|---|---|
| Max SCN | 允许最大SCN |
| Maximum Reasonable SCN | 当前时间点,允许SCN最大值 |
| SCN Headroom | SCN Headroom=(Maximum Reasonable SCN) - (当前SCN值) |
| _external_scn_rejection_threshold_hours | 允许外部SCN和SCN Headroom之间的差距 |
| _max_reasonable_scn_rate | SCN增长频率 |
相关参数
| PARAMETER | VALUE | DESCRIPTION |
|---|---|---|
| _broadcast_scn_wait_timeout | 10 | broadcast-on-commit scn wait timeout in centiseconds |
| _disable_latch_free_SCN_writes_via_32cas | FALSE | disable latch-free SCN writes using 32-bit compare & swap |
| _disable_latch_free_SCN_writes_via_64cas | FALSE | disable latch-free SCN writes using 64-bit compare & swap |
| _dump_scn_increment_stack | Dumps scn increment stack per session | |
| _enable_cscn_caching | FALSE | enable commit SCN caching for all transactions |
| _enable_minscn_cr | TRUE | enable/disable minscn optimization for CR |
| _enable_scn_wait_interface | TRUE | use this to turn off scn wait interface in kta |
| _external_scn_logging_threshold_seconds | 86400 | High delta SCN threshold in seconds |
| _external_scn_rejection_delta_threshold_minutes | 0 | external SCN rejection delta threshold in minutes |
| _external_scn_rejection_threshold_hours | 24 | Lag in hours between max allowed SCN and an external SCN |
| _fbda_global_bscn_lag | 0 | flashback archiver global barrier scn lag |
| _gc_check_bscn | TRUE | if TRUE, check for stale blocks |
| _gc_global_checkpoint_scn | TRUE | if TRUE, enable global checkpoint scn |
| _kdli_recent_scn | FALSE | use recent (not dependent) scns for block format/allocation |
| _max_pending_scn_bcasts | 8 | maximum number of pending SCN broadcasts |
| _max_reasonable_scn_rate | 32768 | Max reasonable SCN rate |
| _scn_wait_interface_max_backoff_time_secs | 600 | max exponential backoff time for scn wait interface in kta |
| _scn_wait_interface_max_timeout_secs | 2147483647 | max timeout for scn wait interface in kta |
| db_unrecoverable_scn_tracking | TRUE | Track nologging SCN in controlfile |
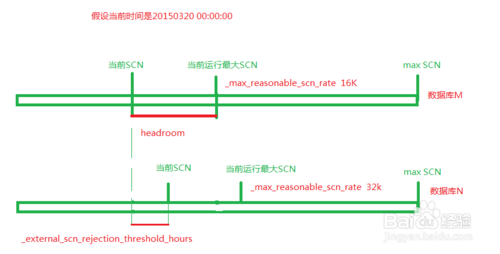
相关概念关系
- 从刚开始安装oracle数据库后,其就有一个SCN值,SCN值呈递增方式,最大值为 max SCN(SCN最大值)
- 为了保证数据库可在长时间内可用,设置了 maximum reasonable SCN(当前SCN允许最大值)
- 为了保证当前SCN 不会增长至maximum reasonable SCN,设置了 headroom(当前SCN允许最大值和当前SCN差值) 差值适当大的话,数据库宕机几率越小
- 为了保证headroom 过小(也就是当前SCN过大),设置了_external_scn_rejection_threshold_hours(允许外部SCN和headroom 之间的差值)差值适当大,数据库宕机几率越小
- 11.2.0.2以后增加_max_reasonable_scn_rate ,将原来的16K增加到32K,也就是说maximum reasonable SCN 值更大了,会导致低版本数据库与高版本数据库DBlink连接的可能性降低了!
解决方案尝试
- 打补丁包,目标端和源端都需要,注意11.2.0.4已经包含相关补丁包,不需要再打了
- 如果是高版本(SCN增长率32K)连接到低版本(SCN增长率16K),可以调整
_max_reasonable_scn_rate值 - 如果是相同增长率的数据库,可以减小
_external_scn_rejection_threshold_hours
注意:11.2.0.4 _max_reasonable_scn_rate 为32K,_external_scn_rejection_threshold_hours为24小时
故障解决经历
厂家C通过DBlink连接到厂家A 11.2.0.4版本数据库,开始一段时间内使用正常,后来报错ORA-19706: Invalid SCN错误,查看alert日志,只是相关警告信息:Rejected the attempt to advance SCN over limit by 6 hours worth,通过协调,厂家C最终通过升级数据的方式,之后连接正常,后来由于厂家A数据库存储问题,进行了一次全面数据库还原与恢复后,又报ORA-19706: Invalid SCN错误,最后通过将厂家A和厂家C的_external_scn_rejection_threshold_hours逐渐减小,至于减小值至最终值根据alert日志警告设置
由于通过database link进行远程数据库的数据读取时,会自动同步当前库和远程库的SCN,而对于实际环境中,SCN的增加可能是几倍、几十倍甚至是上百倍,从而引发一些其他的bug
下面就来看一个问题。该错误会在应用了2012年1月份CPU的Oracle数据库中出现,而在原始版本中,比如10.2.0.5.0之中不会出现此错误。
-- 通过dblink进行简单的查询报ORA-19706错误
SQL> SELECT sysdate FROM dual@AIX12;
SELECT sysdate FROM dual@AIX12
ORA-19706: invalid SCN
-- 登录远程库,检查SCN,很大的一个数字
SQL> SELECT current_scn FROM v$database;
CURRENT_SCN
-----------
12763142641
-- 而当前库,由于新创建,所以SCN并不大,与远程库想比相差几个数量级
SQL> SELECT current_scn FROM v$database;
CURRENT_SCN
-----------
5017684
看一下ORA-19706错误的解释。可以看到too large是产生该问题的原因之一。
[oracle@testos:/home/oracle]$ oerr ora 19706
19706, 00000, "invalid SCN"
// *Cause: The input SCN is either not a positive integer or too large.
// *Action: Check the input SCN and make sure it is a valid SCN.
[oracle@testos:/home/oracle]$
SCN是一个可以容纳很长时间的数字,为什么会出现too large的情况呢?这是由于SCN有headroom限制的原因,headroom是一个固定值,从1988年开始计算,以每秒16K的速度递增。当突然请求的SCN超过跟SCN headroom之间允许的差值时,则会出现ORA-19706错误。
详细的解释可以参看MOS Note – System Change Number (SCN), Headroom, Security and Patch Information [ID 1376995.1]。
解决方法:
-
设置隐含参数
_external_scn_rejection_threshold_hours,具体解释可以参看:MOS Note – Installing, Executing and Interpreting output from the “scnhealthcheck.sql” script [ID 1393363.1]。
该参数在10.2.0.5中默认是744,设置为24通常可以解决问题(表示允许跟headroom之间的差距相差24小时)。
SQL> ALTER system SET "_external_scn_rejection_threshold_hours"=24 scope=spfile;也就是如果远端数据库的SCN由于某些bug导致异常增长,那么这个SCN跟headroom之间的差距将会低于默认值744小时(31天),当本地数据库(打了2012年1月份CPU补丁后的)通过dblink查询远端数据,由于SCN同步机制,本地数据库尝试将SCN同步为跟远端一样大小,但是这个值超过了跟SCN headroom之间允许的差值,因此报错。
实际上具体设置的值应该根据上面MOS文档中scnhealthcheck.sql的结果,该SQL应该在远端数据库中运行(或者说在具有最大的SCN的数据库中运行),假设运行结果显示:
SCN Headroom: 14.55那么则表示目前SCN距离headroom只有14.55天的空间,此时我们将_external_scn_rejection_threshold_hours参数设置为13*24=312,即可解决问题。但是要注意,远端数据库SCN仍在不停异常增长,等到某一天远端数据库的SCN Headroom降低为小于13天的时候,ORA-19706错误又会再次出现。
-
回滚打上的2012年1月份CPU。当然这并不是推荐的方法
-
最终极的解决方案,将环境中所有通过dblink互相连接的数据库全部打上最新的PSU,比如目前10205的最新PSU是10.2.0.5.7,这将会解决所有SCN异常增长的问题,只要数据库每秒增长的SCN不会超过16K,那么就会离headroom越来越远。
2、ORA-01882
[oracle@testos:/home/oracle]$ oerr ora 01882
01882, 00000, "timezone region not found"
// *Cause: The specified region name was not found.
// *Action: Contact Oracle Support Services.
[oracle@testos:/home/oracle]$
查看时区
cat /etc/sysconfig/clock
sys@testdb(761)> select dbtimezone from dual;
DBTIME
------
+00:00
参考资料
JDBC连接Oracle报错 ORA-01882: timezone region not found
https://blog.csdn.net/Hehuyi_In/article/details/110938646
document ID 1068063.1
参考资料
http://blog.itpub.net/29313086/viewspace-1708857
http://blog.itpub.net/26655292/viewspace-2086023
https://blog.51cto.com/u_15127599/2898513
https://mp.weixin.qq.com/s/l1f7YhipsWNfaGv33rCqqg















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









