







 在尝试在App中接入其他企业微信客服时,遇到deeplinkcustomerservicenopermission错误。问题根源可能是企业ID、客服URL和APPID未统一对应。解决方案包括核实和统一这三个标识,并在第三方接入的情况下,确保在微信开放平台正确配置第三方的企业ID和客服URL。
在尝试在App中接入其他企业微信客服时,遇到deeplinkcustomerservicenopermission错误。问题根源可能是企业ID、客服URL和APPID未统一对应。解决方案包括核实和统一这三个标识,并在第三方接入的情况下,确保在微信开放平台正确配置第三方的企业ID和客服URL。
APP拉起微信客服报错
deeplink customerservice no permission我这边的需求是 在App里接入其他企业的微信客服。按照指引 进入界面微信客服 微信客服
开发配置-->在App里接入其他企业的微信客服-->进入管理-->关联APP
关联成功后 测试 报错了,然后发现在下图这个位置腾讯的显示把企业ID显示为APPID(已经给腾讯反馈了)
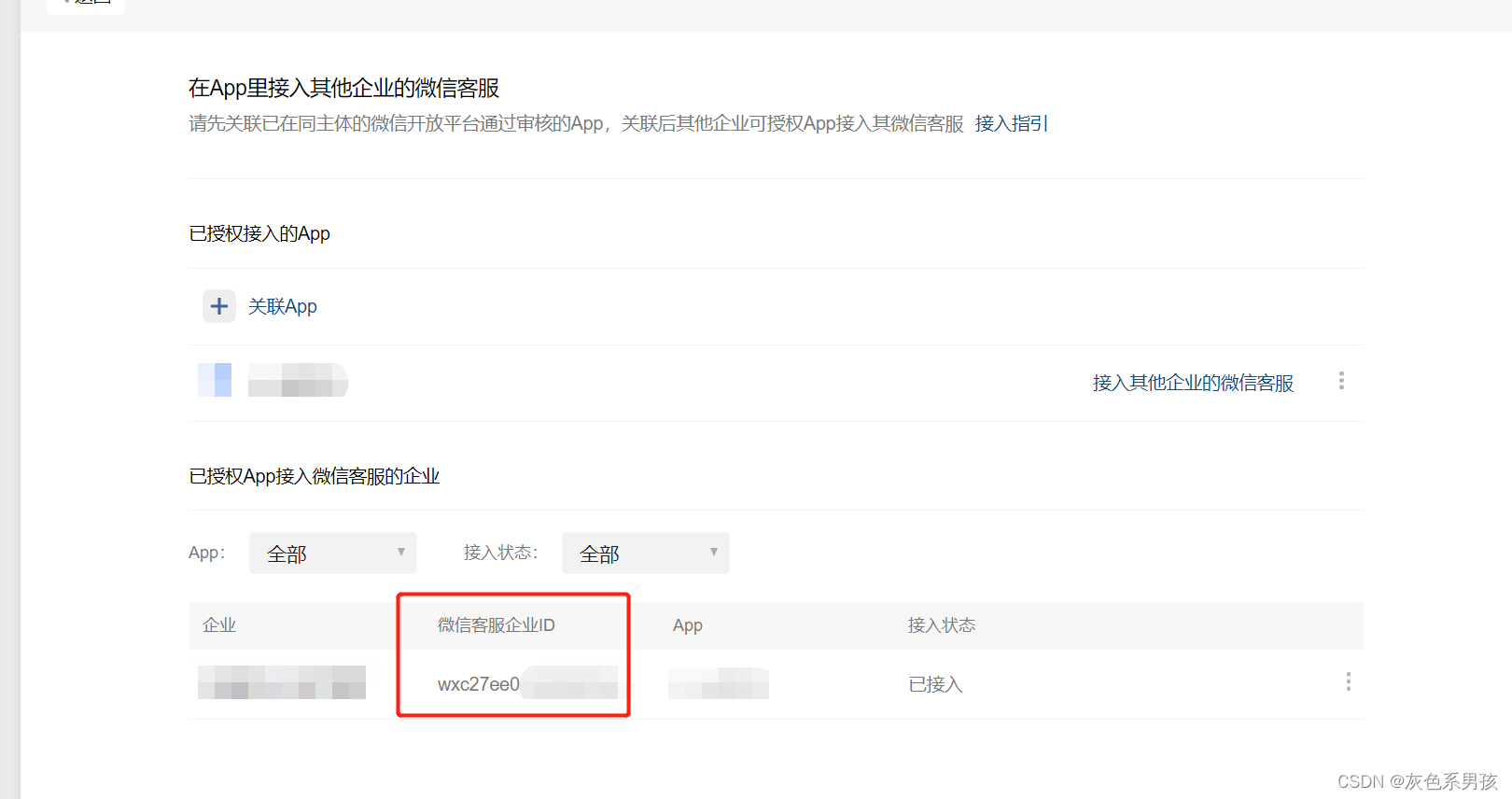
代码同步修改后正常。
后记:出现这个错误的原因,一般是 企业ID,客服URL ,APPID 三者没有统一对应起来。
对于只有一个企业ID的账号来说简单核实下就行。但是对于处理第三方的客服接入业务,需要同时更换企业ID和客服URL,第三方企业ID可以微信开放平台去找到对应的APP,然后找到拉起客服的选项,如果前面接入了第三方并且第三方授权了,那么一般就会有第三方的企业ID。

















 1571
1571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









