







什么是 Yandex?
Yandex 是一家总部位于俄罗斯的跨国公司,以其搜索引擎而闻名,该搜索引擎是俄罗斯最大的搜索引擎之一。除了搜索功能外,Yandex 还提供一系列服务。此外,Yandex 还提供 Yandex 图片搜索,允许您使用关键字查找照片。
Yandex 图片搜索的结果与 Google 和 Bing 的结果略有不同。Yandex 图片搜索还支持多种过滤器,包括大小、方向、类型、颜色、格式、最新和壁纸。
数千张照片可以被抓取用于各种目的,包括营销、品牌、研究、教学和创意。
抓取 Yandex 非常困难!
Yandex 采用了先进的反机器人措施,旨在检测和阻止自动请求。这包括实施 CAPTCHA 和严格的 IP 速率限制,这可能会阻碍抓取工作。
许多 Yandex 页面包含通过 JavaScript 加载的动态内容。这意味着简单的抓取技术可能无法捕获所有相关信息,因此需要使用更复杂的工具,例如无头浏览器。
此外,Yandex 经常更新其算法和页面结构。这种不断的发展会导致抓取脚本失效,需要定期维护和调整。
在抓取时,需要考虑法律因素,因为抓取可能违反 Yandex 的服务条款,可能会给用户带来法律后果。
Yandex 上提供的海量数据意味着高效的数据处理至关重要,这为抓取过程增加了另一层复杂性。
这些因素综合起来使抓取 Yandex 成为一项具有挑战性的工作,需要仔细的计划和执行。
为什么 Browserless 非常适合抓取 Yandex 图片搜索?
Nstbrowser 的 Browserless 是一种典型的无头 Chrome 云服务,可以在没有图形用户界面的情况下运行在线应用程序和自动化脚本。对于 Web 抓取和其他自动化操作等任务,它特别有用。
Nstbrowser 将反检测、Web 解锁和无头功能集成到 Browserless 中。 Browserless 完全免费测试。
您对 Web 抓取和 Browserless 有任何绝妙的想法或疑问吗?
让我们看看其他开发人员在 Discord 上分享了什么!
如何抓取 Yandex 图片搜索结果?
环境预设
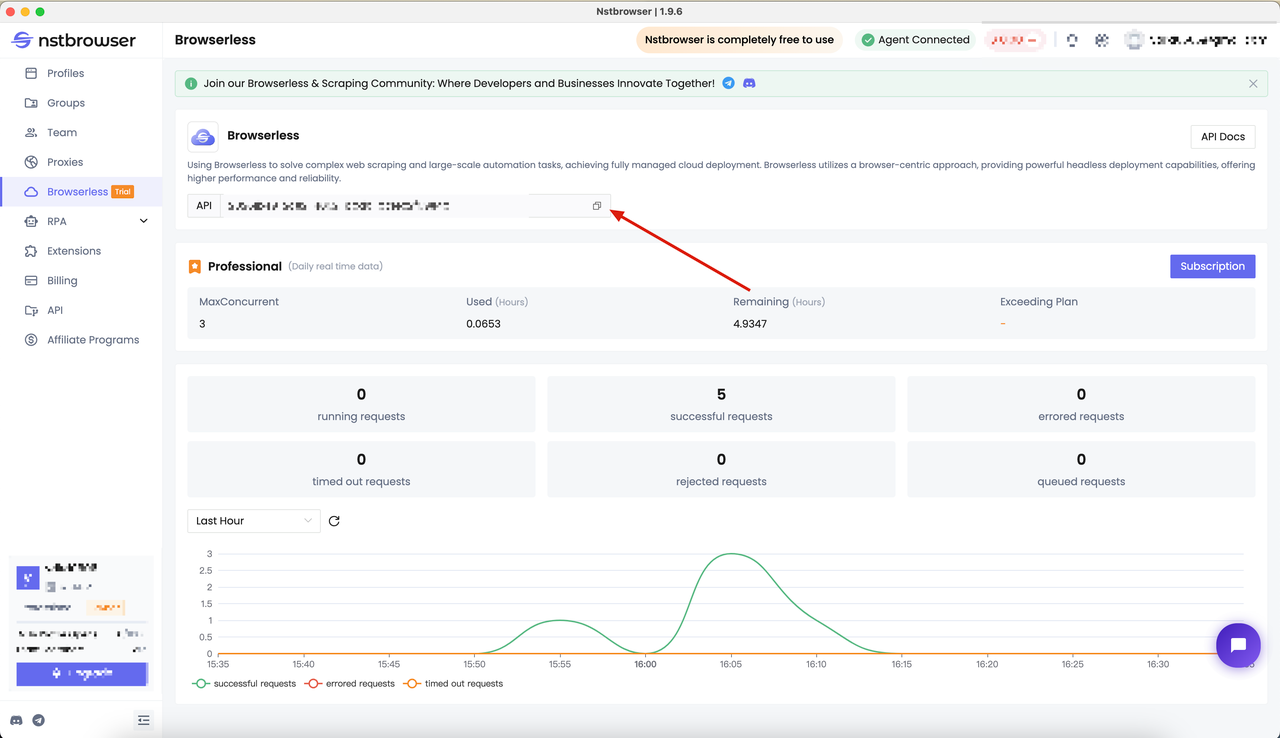
首先,我们应该准备我们的 Browserless 服务。Browserless 可以帮助解决复杂的 Web 抓取和大型自动化任务,并实现了完全托管的云部署。
- Browserless 采用浏览器为中心的解决方案,提供强大的无头部署功能,并提供更高的可靠性和速度。
- 转到 Nstbrowser 客户端的 Browserless 菜单页面以获取 API 密钥。
确定抓取目标
就像之前一样,请跟随我们首先确定抓取目标。
让我们使用 Playwright 并将其与 Nstbrowser 的 Browserless 服务结合起来,在搜索关键字“猫”时抓取顶部图像。
我们需要的数据包括:“图片地址”、“图片摘要”、“图片宽度”和“图片高度”,并将结果保存到 CSV 文件中。
使用 Nstbrowser Browserless 服务开始抓取
按照以下步骤创建项目并开始抓取:
第 1 步. 构建 main.py 文件和新的 Python 项目。
第 2 步. 使用 Nstbrowser 的 Browserless 创建浏览器实例。
from playwright.sync_api import sync_playwright
token = "You API token" # required
config = {
"proxy": "", # required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
# "platform": "windows", # support: windows, mac, linux
# "kernel": "chromium", # only support: chromium
# "kernelMilestone": "124", # support: 113, 120, 124
# "args": {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, # browser args
# "fingerprint": {
# "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36",
# },
}
query = urlencode({
"token": token,
"config": json.dumps(config)
})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"
def get_browser():
playwright = sync_playwright().start()
return playwright.chromium.connect_over_cdp(browser_ws_endpoint)第 3 步. 获取图片数据并清理数据
- 定义抓取目标网站地址:
target_website_url = "https://yandex.com/images/search?family=yes&from=tabbar&text=cats"- 在这里,Playwright 使用
page.goto方法来帮助打开目标网页。
此步骤是为了确保浏览器能够正确加载页面并等待网页的 DOM 内容完全加载。
page.goto(url, timeout=60000, wait_until="domcontentloaded")- 接下来,我们需要找到页面上所有具有
data-state属性的元素,并尝试找到目标元素(包含图像数据的元素)。
此步骤使用 query_selector_all 方法获取这些元素,并通过 get_attribute("id") 和 get_attribute("data-state") 定位包含图像信息的元素。
data_states = page.query_selector_all("[data-state]")
images_app = None
for data_state in data_states:
if "ImagesApp" in data_state.get_attribute("id"):
images_app = data_state.get_attribute("data-state")
break- 获取目标元素后,代码调用
get_image_results函数。
此函数解析目标元素 data-state 属性中的 JSON 数据,并提取图像信息。
def get_image_results(images_app):
images_app_obj = json.loads(images_app)
images_lists = images_app_obj['initialState']["serpList"]["items"]["entities"]
imgs = []
for key in images_lists:
img = images_lists[key]
imgs.append({
"url": img["url"],
"alt": img["alt"],
"width": img["width"],
"height": img["height"],
})
return imgs第 4 步. 保存抓取结果并将其导出到 CSV 文件
在保存数据之前,需要定义 CSV 文件的标题。这里定义了四个字段:URL、Alt、Width 和 Height。这些字段代表每个图像的基本属性。使用 open() 函数以写入模式 ('w') 打开名为 yandex_images.csv 的文件。同时,将编码格式指定为 UTF-8,并设置 newline='' 以避免写入时出现空行。
def save_csv(data):
try:
header = ["URL", "Alt", "Width", "Height"]
with open('yandex_images.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
for item in data:
writer.writerow(
[
item["url"],
item["alt"],
item["width"],
item["height"],
])
print("Saved to yandex_images.csv")
except Exception as e:
print(e)整段代码
import json
import csv
from urllib.parse import urlencode
from playwright.sync_api import sync_playwright
token = "" # required
config = {
"proxy": "", # required; input format: schema://user:password@host:port eg: http://user:password@localhost:8080
# "platform": "windows", # support: windows, mac, linux
# "kernel": "chromium", # only support: chromium
# "kernelMilestone": "124", # support: 113, 120, 124
# "args": {
# "--proxy-bypass-list": "detect.nstbrowser.io"
# }, # browser args
# "fingerprint": {
# "userAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.6613.85 Safari/537.36",
# },
}
query = urlencode({
"token": token,
"config": json.dumps(config)
})
browser_ws_endpoint = f"ws://less.nstbrowser.io/connect?{query}"
target_website_url = "https://yandex.com/images/search?family=yes&from=tabbar&text=cats"
def get_browser():
playwright = sync_playwright().start()
return playwright.chromium.connect_over_cdp(browser_ws_endpoint)
def get_image_results(images_app):
try:
images_app_obj = json.loads(images_app)
images_lists = images_app_obj['initialState']["serpList"]["items"]["entities"]
imgs = []
for key in images_lists:
img = images_lists[key]
imgs.append({
"url": img["url"],
"alt": img["alt"],
"width": img["width"],
"height": img["height"],
})
return imgs
except Exception as e:
print(e)
def get_tar(url, page):
try:
print("Open page: " + url)
page.goto(url, timeout=60000, wait_until="domcontentloaded")
data_states = page.query_selector_all("[data-state]")
images_app = None
results = []
for data_state in data_states:
if "ImagesApp" in data_state.get_attribute("id"):
images_app = data_state.get_attribute("data-state")
break
if images_app is None:
print("Cannot find the target element")
else:
print("Found the target element")
results = get_image_results(images_app)
return results
except Exception as e:
print(e)
def save_csv(data):
try:
header = ["URL", "Alt", "Width", "Height"]
with open('yandex_images.csv', 'w', encoding='UTF8', newline='') as f:
writer = csv.writer(f)
writer.writerow(header)
for item in data:
writer.writerow(
[
item["url"],
item["alt"],
item["width"],
item["height"],
])
print("Saved to yandex_images.csv")
except Exception as e:
print(e)
def main():
try:
with get_browser() as browser:
page = browser.new_page()
res = get_tar(target_website_url, page)
if len(res) == 0:
print("No results")
else:
save_csv(res)
browser.close()
except Exception as e:
print(e)
if __name__ == "__main__":
main()抓取结果

总结
正如大家所知,抓取 Yandex 图片搜索很困难。但是,如果您按照本文中的抓取说明并利用提供的 Python 代码,您可以轻松地抓取 Yandex 搜索结果以获得任何选定的词语,并将数据导出到 CSV 或 JSON 文件中。
您可以使用 Browserless 轻松地大规模抓取 Yandex SERP。现在,使用 Browserless 完全免费。不要错过这个绝佳的机会!

















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









