







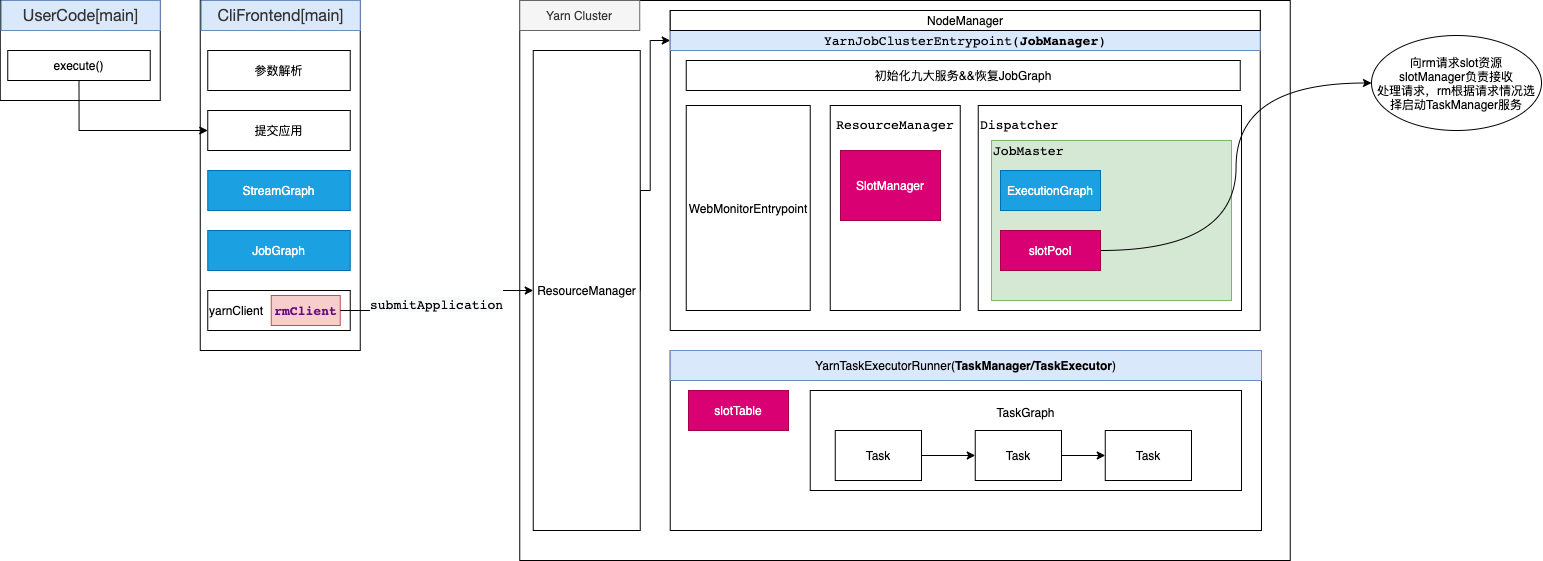
深入学习Apache Flink提交流程的源码对于理解和优化Flink应用程序至关重要。源码阅读将揭示Flink运行时系统的内部工作原理,包括作业提交、调度、任务执行等关键流程。通过深入源码,你将更好地理解Flink的执行模型、任务调度策略和容错机制。这种深度理解有助于解决性能问题、调优应用程序,并在特定场景下优化资源利用率。此外,学习Flink提交流程的源码还有助于扩展Flink,定制化特定功能,以满足个性化需求。总的来说,源码学习是成为Flink高级用户和贡献者的关键一步,为构建高效、稳定的流处理应用奠定基础。本文Flink源码分析基于软件版本flink-1.16.0。
-
Flink源码分析让我们从flink per job启动脚本开始,如下:
./bin/flink run \ -t yarn-per-job \ --detached ./examples/streaming/WorldCount.jar根据启动任务,首先会进入shell脚本./bin/flink中执行;
-
让我们跟踪调用过程:
...... # get flink config . "$bin"/config.sh ...... # Add HADOOP_CLASSPATH to allow the usage of Hadoop file systems exec "${JAVA_RUN}" ...... org.apache.flink.client.cli.CliFrontend "$@" ......根据shell脚本内容可知,紧接着调用了org.apache.flink.client.cli.CliFrontend.main执行flink任务,同时将shell参数原样传递给Flink程序;
-
下面让我们一起看看org.apache.flink.client.cli.CliFrontend:
...... // 1. find the configuration directory,发现配置目录 final String configurationDirecto
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 412
412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











