







对全文索引的理解,主要来自《lucene原理与代码分析》,虽然全文索引有所发展,但整体思路大同小异。
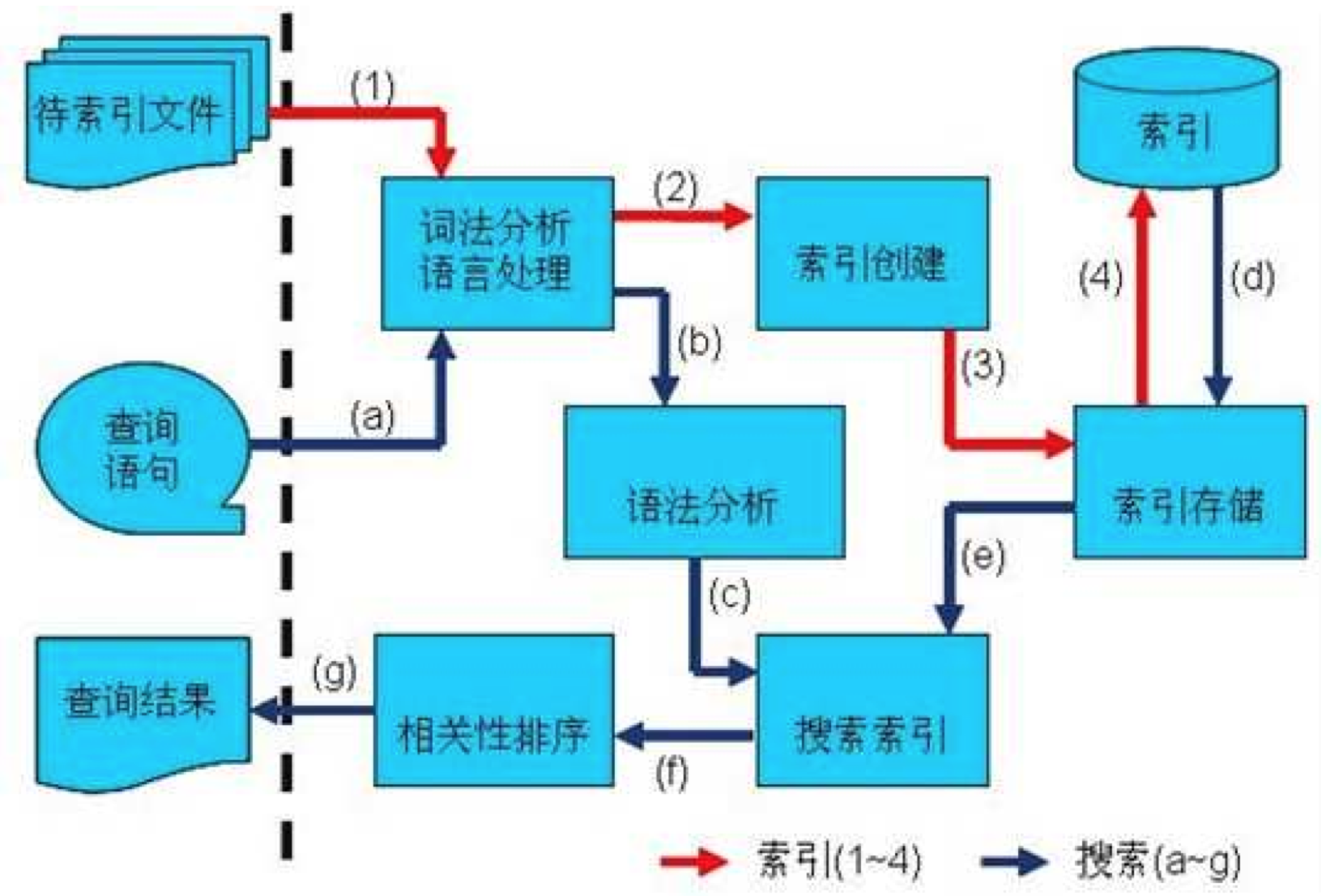
全文索引主要分为索引和搜索两个部分:
图均出自《lucene原理与代码分析》
索引:
由最基本的文档组成:document
(1)分词组件:Tokenizer —— 1.分词 2. 去标点 3. 去停用词 —— 得到词元
(2)语言处理组件:Linguistic Processor —— 1. 变为小写 2. 复数变词根(stemming)3. 过去式变词根(lemmatization)
stemming 采用缩减方式
lemmatization 采用字典方式
(3)处理后得到词(Term)
(4)对词排序,合并成文档倒排表(Posting List)
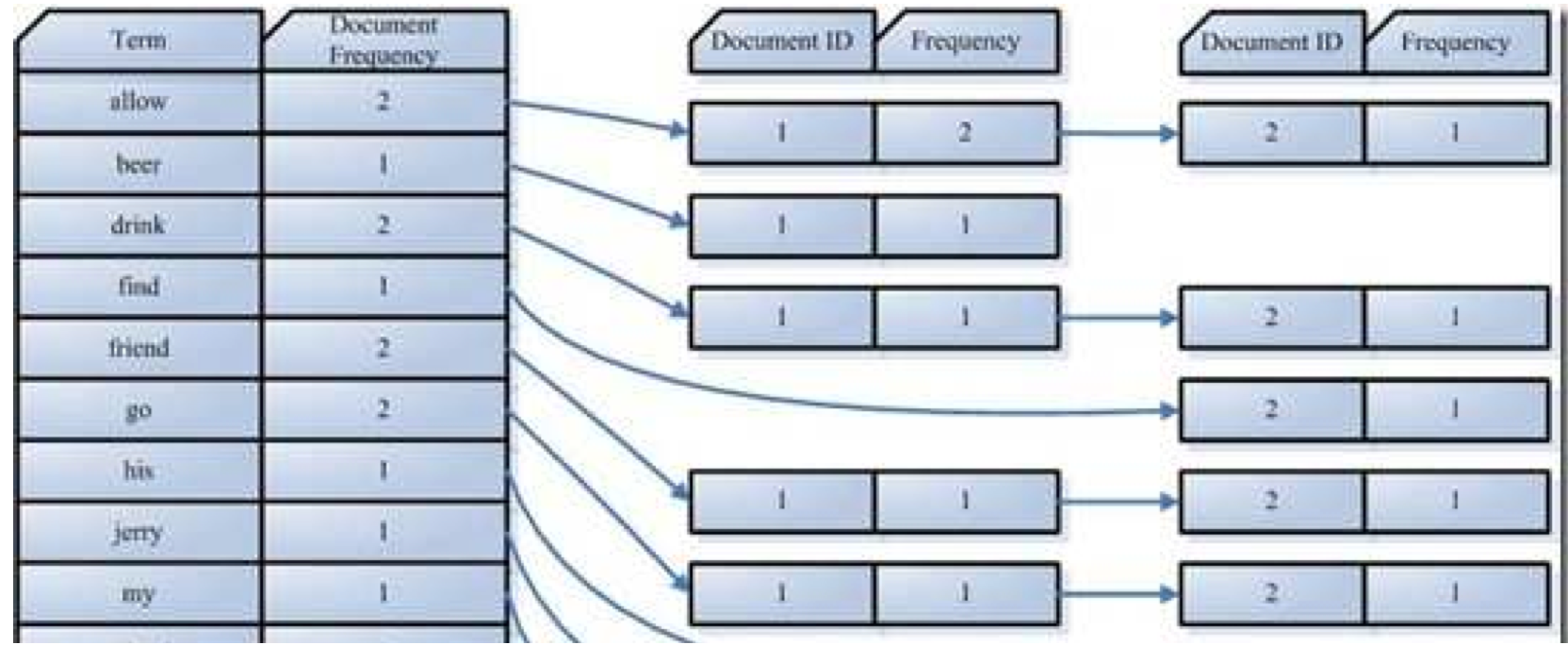
Document Frequency —— 总共多少文档出现这个词
Frequency —— 这篇文档中这个词出现了几次
搜索:
(1)语法解析器解析输入内容,筛选出语法关键词(AND,NOT等)和搜索关键词
(2)解析为语法树:

(3)语言处理(索引时的Term处理一样,单词变换等)
(4)根据语法树搜索索引:
a. 找出包含各个关键词的链表(含有lucene和learn)
b. a步骤的两个链表合并
c. 与包含hadoop的链表取差
(5)相关性排序
判断词的关系从而得到文档的相关度 —— 向量空间模型(Vector Space Model)
a. 计算权重(Term weight)众所周知的TFIDF
Term Frequency(TF) 此Term在此文档中出现了多少次。(越大越重要)
Document Frequencey(DF)即有多少文档包含此词。(越大越不重要)

b. 通过词的关系得到文档相关关系(VSM)
每个词作为一个维度
Document = {term1, term2, ......, term N}
Document Vector = {weight1, weight2, ......, weight N}
搜索的每个词也作为一个维度
Query = {term1, term2, ......, term N}
Query Vector = {weight1, weight2, ......, weight N}
然后就是一个N维的空间,计算余弦夹角
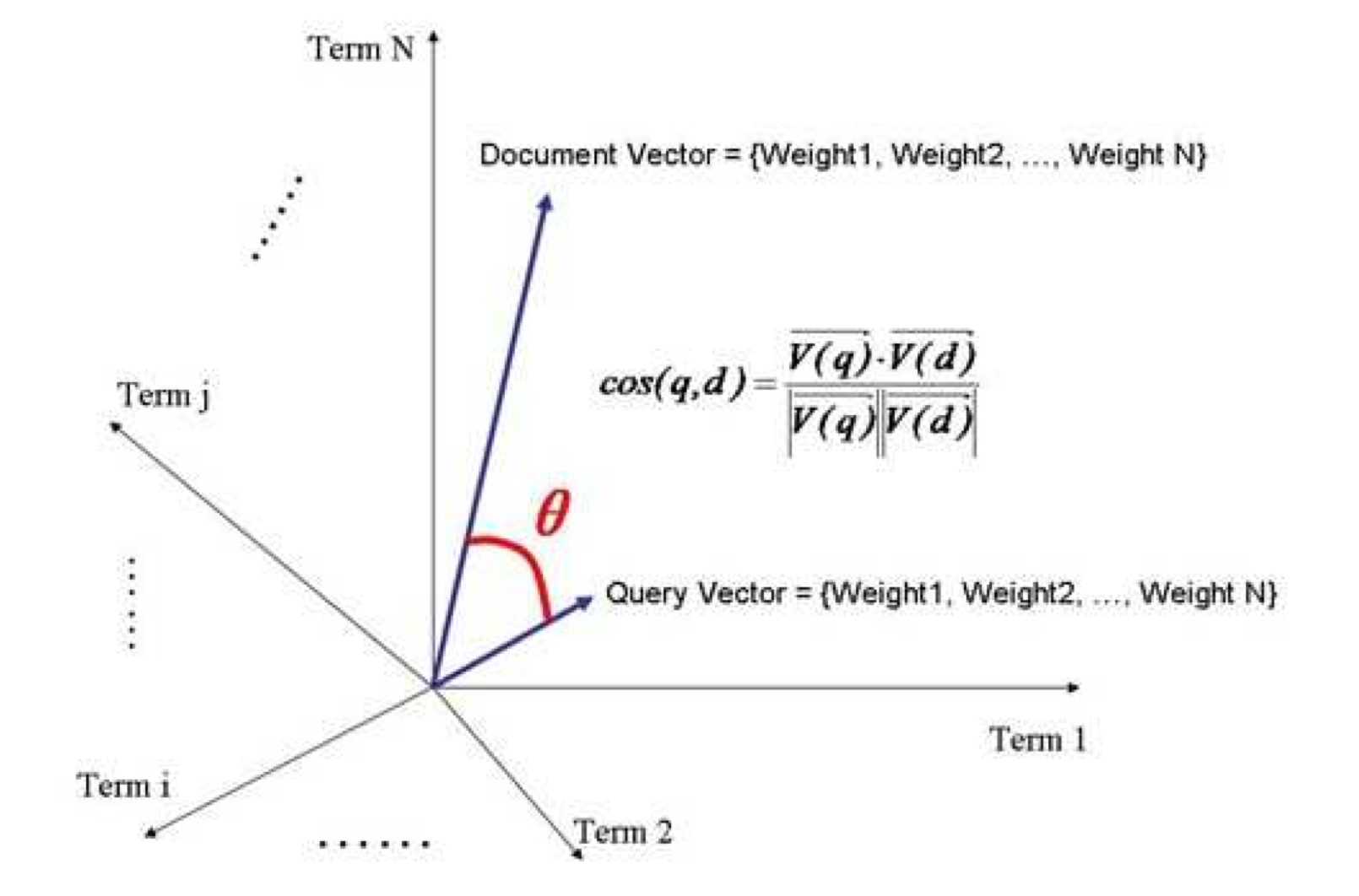
没有的词视为权重0,通过打分公式计算相关度。
以上是信息检索技术(Information retrieval)基本理论,lucene是这个理论的一个实践。
总结:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









